pytorch土堆pytorch教程学习Transforms 的使用
Posted hzyuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch土堆pytorch教程学习Transforms 的使用相关的知识,希望对你有一定的参考价值。
transforms 在工具包 torchvision下,用来对图像进行预处理:数据中心化、数据标准化、缩放、裁剪、旋转、翻转、填充、噪声添加、灰度变换、线性变换、仿射变换、亮度/饱和度/对比度变换等。
transforms 本质就是一个python文件,相当于一个工具箱,里面包含诸如 Resize、ToTensor、Normalize 等类,这些类就是我们需要用到的图像预处理工具。
transforms 的使用无非是将图像通过工具转换成我们需要的结果。
我们需要关注两个问题:
- 该如何使用 transforms 里的工具?
- 为什么需要 Tensor 数据类型?
工具的使用方法
我们先来看下 ToTensor 和 Resize 这两个工具的源码。
# ToTensor 源码
class ToTensor:
"""Convert a PIL Image or ndarray to tensor and scale the values accordingly.
"""
def __init__(self) -> None:
_log_api_usage_once(self)
def __call__(self, pic):
"""
Args:
pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
Returns:
Tensor: Converted image.
"""
return F.to_tensor(pic)
# Resize 源码
class Resize(torch.nn.Module):
"""Resize the input image to the given size.
"""
def __init__(self, size, interpolation=InterpolationMode.BILINEAR, max_size=None, antialias="warn"):
super().__init__()
_log_api_usage_once(self)
if not isinstance(size, (int, Sequence)):
raise TypeError(f"Size should be int or sequence. Got type(size)")
if isinstance(size, Sequence) and len(size) not in (1, 2):
raise ValueError("If size is a sequence, it should have 1 or 2 values")
self.size = size
self.max_size = max_size
if isinstance(interpolation, int):
interpolation = _interpolation_modes_from_int(interpolation)
self.interpolation = interpolation
self.antialias = antialias
def forward(self, img):
"""
Args:
img (PIL Image or Tensor): Image to be scaled.
Returns:
PIL Image or Tensor: Rescaled image.
"""
return F.resize(img, self.size, self.interpolation, self.max_size, self.antialias)
一目了然,这两个工具都没有一堆乱七八糟的方法迷惑我们,其核心功能代码在 __call__ 和 forward 里,这是想让我们通过可调用对象方式来使用工具。
使用 transforms 工具大致为以下两个步骤:
- 实例化工具
tensor_trans = transforms.ToTensor()
- 传入合适的参数调用实例化对象
img_path = \'dataset/train/ants/0013035.jpg\'
img = Image.open(img_path)
# 输入什么类型的参数可以进到源码里看
tensor_img = tensor_trans(img)
补充:
我们需要关注三种图像类型还有如何得到三种图像类型,分别是 PIL.Image、numpy.ndarray 和 Tensor。
Image.open(img_path)得到PIL.Image类型cv2.imread(img_path)得到numpy.ndarray类型transforms.ToTensor()(pic)得到Tensor类型
在 transforms 中存在工具灵活地转换图像类型,如ToTensor, PILToTensor,ToPILImage。
Tensor 数据类型
from torchvision import transforms
from PIL import Image
img_path = \'dataset/train/ants/0013035.jpg\'
img = Image.open(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)
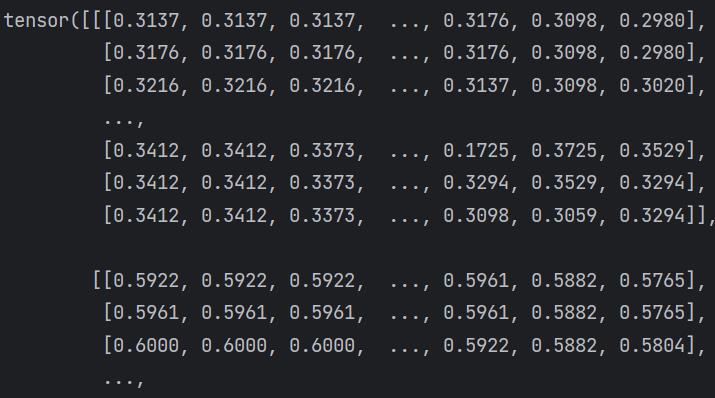
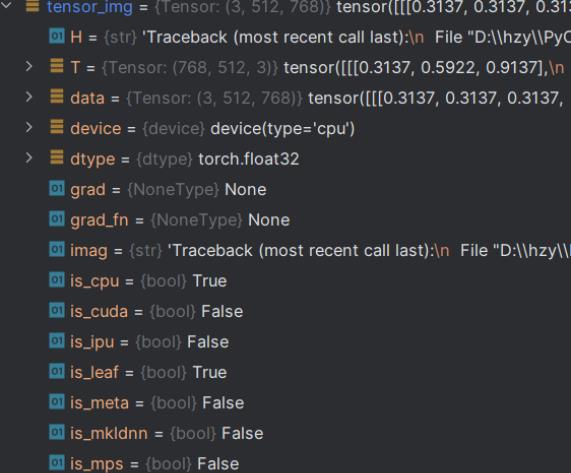
输出 Tensor 类型的数据,乍一看怎么和 numpy.ndarray 差不多。其实不然,进入断点调式里可以看到其还包装了神经网络所需要的理论基础参数,诸如grad、grad_fn、is_cpu等。这就是我们需要 Tensor 数据类型的原因,一切都是为了神经网络而服务。
常用的工具
仅仅列出几个常用的工具的一些简单用法,以进一步体会tansforms工具的用法,其他详细信息还需关注官方文档和源码。
ToTensor
将
PIL.Image或narray类型的图像转换为tensor类型并相应地缩放值。
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
Normalize
用均值和标准差标准化张量图像。
逐channel地对图像进行标准化(均值变为0,标准差变为1),可以加快模型的收敛。
n个通道,给出 平均值: (mean[1],...,mean[n]) 和 标准差: (std[1],..,std[n])
output[channel] = (input[channel] - mean[channel]) / std[channel]
trans_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_normalize = trans_normalize(img_tensor)
Resize
改变图像的大小
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
Compose
将多个变换组合在一起。
trans_compose = transforms.Compose([
transforms.Resize(512),
transforms.ToTensor()
transforms.Nomalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
img_resize = trans_compose(img)
简单理解 ToTense 和 Normalize
数值归一化处理是数据挖掘中的一项基本工作,不同的评价指标具有不同的量纲和量纲单位,如果根据原始数据进行分析的话会受到量纲的影响,为了消除指标之间的量纲影响,需要对原始数据进行标准化。
归一化也就是量纲统一化。目的就是为了把不同来源的数据统一到同一数量级(或者是一个参考坐标系)下,这样使得比较起来有意义。
归一化能提高梯度下降法求解最优解的速度。
归一化方法:
- 线性归一化,也称min-max标准化、离差标准化;是对原始数据的线性变换,使得结果值映射到 [0, 1] 之间。转换函数如下:
x\' = (x - min(x)) / (max(x) - min(x))
- 标准差归一化,,也叫Z-score标准化,这种方法给予原始数据的均值(mean,μ)和标准差(standard deviation,σ)进行数据的标准化。处理后的数据均值为0,标准差为1。转换函数如下:
x* = (x - μ) / σ
- 非线性归一化,这种方法一般使用在数据分析比较大的场景,有些数值很大,有些很小,通过一些数学函数,将原始值进行映射。一般使用的函数包括log、指数、正切等,需要根据数据分布的具体情况来决定非线性函数的曲线。
ToTensor 干了两件事:
- 把
PIL图像或numpy.narray转换成Tensor, 形状也从HWC->CHW。 - 如果
PIL图像是属于(L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)中的一种模式,或者numpy.ndarray的dtype是np.uint8,还会将数值从 [0, 255] 归一化到 [0, 1]。
Normalize 是对数据按通道进行标准化,即均值为0,标准差为1。这能加快模型的收敛速度。
计算公式:
output[channel] = (input[channel] - mean[channel]) / std[channel]
实际应用中是需要我们自己计算出每个通道的均值和标准差,然后再传入 Normalize。
\'\'\'
以 MNIST 数据集为例计算其均值和标准差
先查看 mnist 的最大值和最小值
mnist.data.float().min() # 0
mnist.data.float().max() # 255
可以看到数据范围是 [0, 255],在转成 Tensor 类型时会归一化到 [0, 1],故我们需要计算的是[0, 1]范围下的数据集的均值和标准差
\'\'\'
mean = (mnist.data.floatt()/255).mean()
std = (mnist.data.floatt()/255).std()
可能会有人疑问确定了数据集不也就确定了均值和标准差,为什么还要我们自己计算再传入呢?
这是因为数据集一般都是很庞大的,如果交给 Normalize 计算就会影响性能了。
我是土堆 - Pytorch教程 知识点 学习总结笔记
此文章为【我是土堆 - Pytorch教程】 知识点 学习总结笔记(三)包括:torchvision中的数据集使用、DataLoader 的使用、神经网络的基本骨架 - nn.Module 的使用、土堆说卷积操作(可选看)、 神经网络 - 卷积层、神经网络 - 最大池化的使用。
学习系列笔记:
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(一)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(二)_耿鬼喝椰汁的博客-CSDN博客
目录
如何把数据集(多张图片)和 transforms 结合在一起
一、torchvision中的数据集使用
需要学习知识:
- 1. 如何把数据集(多张图片)和 transforms 结合在一起。
- 2. 标准数据集如何下载、查看、使用。
进入torchvision后左上角选择0.9.0版本,就与视频中页面一致啦!
网站地址:torchvision-0.9.0
各个模块作用
如:COCO 目标检测、语义分割;MNIST 手写文字;CIFAR 物体识别
输入输出模块,不常用
提供一些比较常见的神经网络,有的已经预训练好,比较重要,后面会使用到,如分类模型、语义分割模型、目标检测、视频分类等
torchvision提供的一些比较少见的特殊的操作,基本不常用
之前讲解过
提供一些常用的小工具,如TensorBoard
本节主要讲解torchvision.datasets,以及它如何跟transforms联合使用
CIFAR10数据集
1.数据集如何下载
#如何使用torchvision提供的标准数据集
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去。用Ctrl加P查看需要参数。
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
运行结果:

数据集下载过慢时:
获得下载链接后,把下载链接放到迅雷中,会首先下载压缩文件tar.gz,之后会对该压缩文件进行解压,里面会有相应的数据集。
采用迅雷下载完毕后,在PyCharm里新建directory,名字也叫dataset,再将下载好的压缩包复制进去,download依然为True,运行后,会自动解压该数据
2.数据集如何查看与使用
import torchvision
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0]) # 查看测试集中的第一个数据,是一个元组:(img, target)
print(test_set.classes) # 列表
img,target = test_set[0]
print(img)
print(target) # 输出:3。输出为列表第几个类别。从0开始数,这里类别为cat列表第四个
print(test_set.classes[target]) # cat
img.show()结果弹出图片
3.CIFAR10数据集 介绍
CIFAR10 数据集包含了6万张32×32像素的彩色图片,图片有10个类别,每个类别有6千张图像,其中有5万张图像为训练图片,1万张为测试图片。

如何把数据集(多张图片)和 transforms 结合在一起
CIFAR10数据集原始图片是PIL Image,如果要给pytorch使用,需要转为tensor数据类型(转成tensor后,就可以用tensorboard了)
transforms 更多地是用在 datasets 里 transform 的选项中
import torchvision
from torch.utils.tensorboard import SummaryWriter
#把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set=torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True) #root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
test_set=torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
# print(test_set[0])
writer = SummaryWriter("p10")
#显示测试数据集中的前10张图片
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i) # img已经转成了tensor类型
writer.close()运行后在 terminal 里输入
tensorboard --logdir="p10"
二、DataLoader 的使用
- dataset:告诉程序中数据集的位置,数据集中索引,数据集中有多少数据(想象成一叠扑克牌)
- dataloader:加载器,将数据加载到神经网络中,每次从dataset中取数据,通过dataloader中的参数可以设置如何取数据(想象成抓的一组牌)
torch.utils.data — PyTorch 2.0 documentation
参数介绍
参数如下(大部分有默认值,实际中只需要设置少量的参数即可):
- dataset:只有dataset没有默认值,只需要将之前自定义的dataset实例化,再放到dataloader中即可
- batch_size:每次抓牌抓几张
- shuffle:打乱与否,值为True的话两次打牌时牌的顺序是不一样。默认为False,但一般用True
- num_workers:加载数据时采用单个进程还是多个进程,多进程的话速度相对较快,默认为0(主进程加载)。Windows系统下该值>0会有问题(报错提示:BrokenPipeError)
- drop_last:100张牌每次取3张,最后会余下1张,这时剩下的这张牌是舍去还是不舍去。值为True代表舍去这张牌、不取出,False代表要取出该张牌

示例
import torchvision
from torch.utils.data import DataLoader
#准备的测试数据集
test_data = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor)
test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)输出结果:
torch.Size([3, 32, 32]) #三通道,32×32大小
3 #类别为3dataset
- __getitem()__:return img,target
dataloader(batch_size=4):从dataset中取4个数据
- img0,target0 = dataset[0]
- img1,target1 = dataset[1]
- img2,target2 = dataset[2]
- img3,target3 = dataset[3]
把 img 0-3 进行打包,记为imgs;target 0-3 进行打包,记为targets;作为dataloader中的返回
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)输出:
torch.Size([4, 3, 32, 32]) #4张图片,三通道,32×32
tensor([0, 4, 4, 8]) #4个target进行一个打包数据是随机取的(断点debug一下,可以看到采样器sampler是随机采样的),所以两次的 target 0 并不一样
batch_size
# 用上节课torchvision提供的自定义的数据集
# CIFAR10原本是PIL Image,需要转换成tensor
import torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# 加载测试集
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
#batch_size=4,意味着每次从test_data中取4个数据进行打包
writer = SummaryWriter("dataloader")
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("test_data",imgs,step)
step=step+1
writer.close()运行后在 terminal 里输入:
tensorboard --logdir="dataloader"运行结果如图,滑动滑块即是每一次取数据时的batch_size张图片:
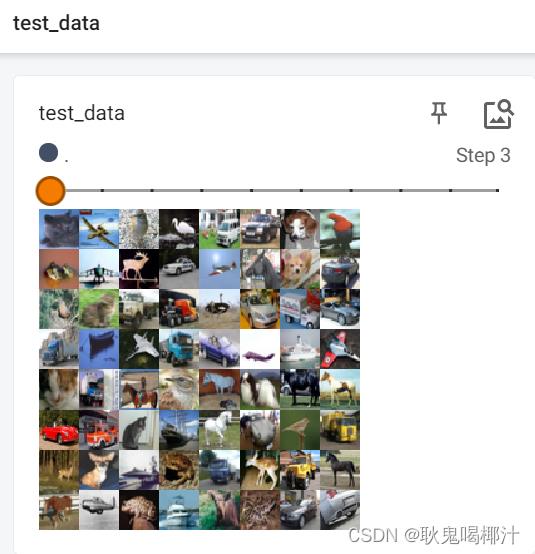
由于 drop_last 设置为 False,所以最后16张图片(没有凑齐64张)显示如下:
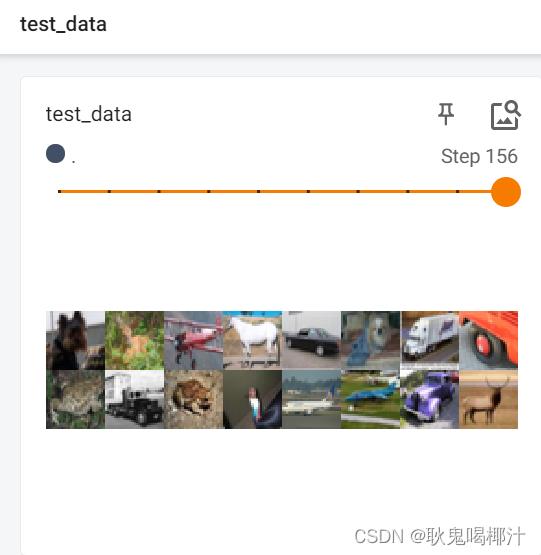
drop_last
若将 drop_last 设置为 True,最后16张图片(step 156)会被舍去,结果如图:

shuffle
一个 for data in test_loader 循环,就意味着打完一轮牌(抓完一轮数据),在下一轮再进行抓取时,第二次数据是否与第一次数据一样。值为True的话,会重新洗牌(一般都设置为True)
shuffle为False的话两轮取的图片是一样的
在外面再套一层 for epoch in range(2) 的循环
# shuffle为True
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets = data #imgs是tensor数据类型
writer.add_images("Epoch:".format(epoch),imgs,step)
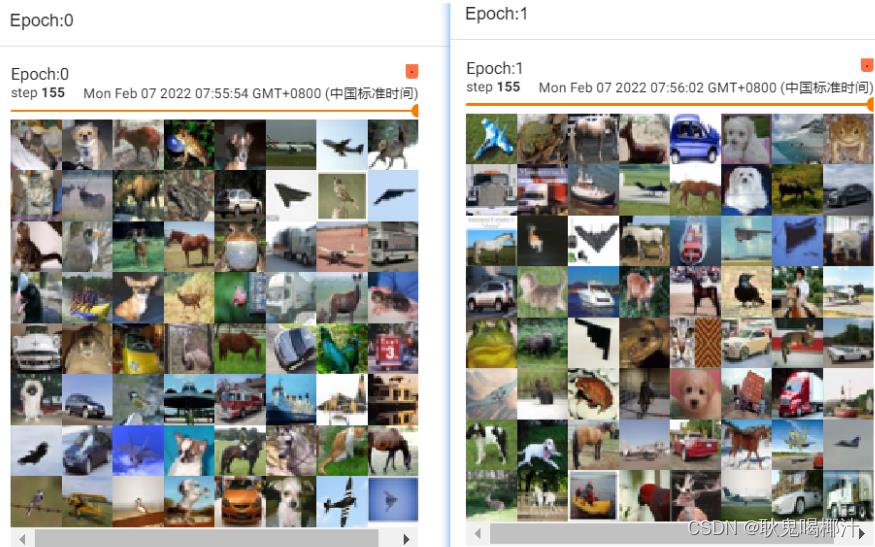
step=step+1结果如下:
可以看出两次 step 155 的图片不一样
三、神经网络的基本骨架 - nn.Module 的使用
Pytorch官网左侧:Python API(相当于package,提供了一些不同的工具)
关于神经网络的工具主要在torch.nn里
网站地址:torch.nn — PyTorch 1.8.1 documentation

Containers
Containers 包含6个模块:
- Module
- Sequential
- ModuleList
- ModuleDict
- ParameterList
- ParameterDict
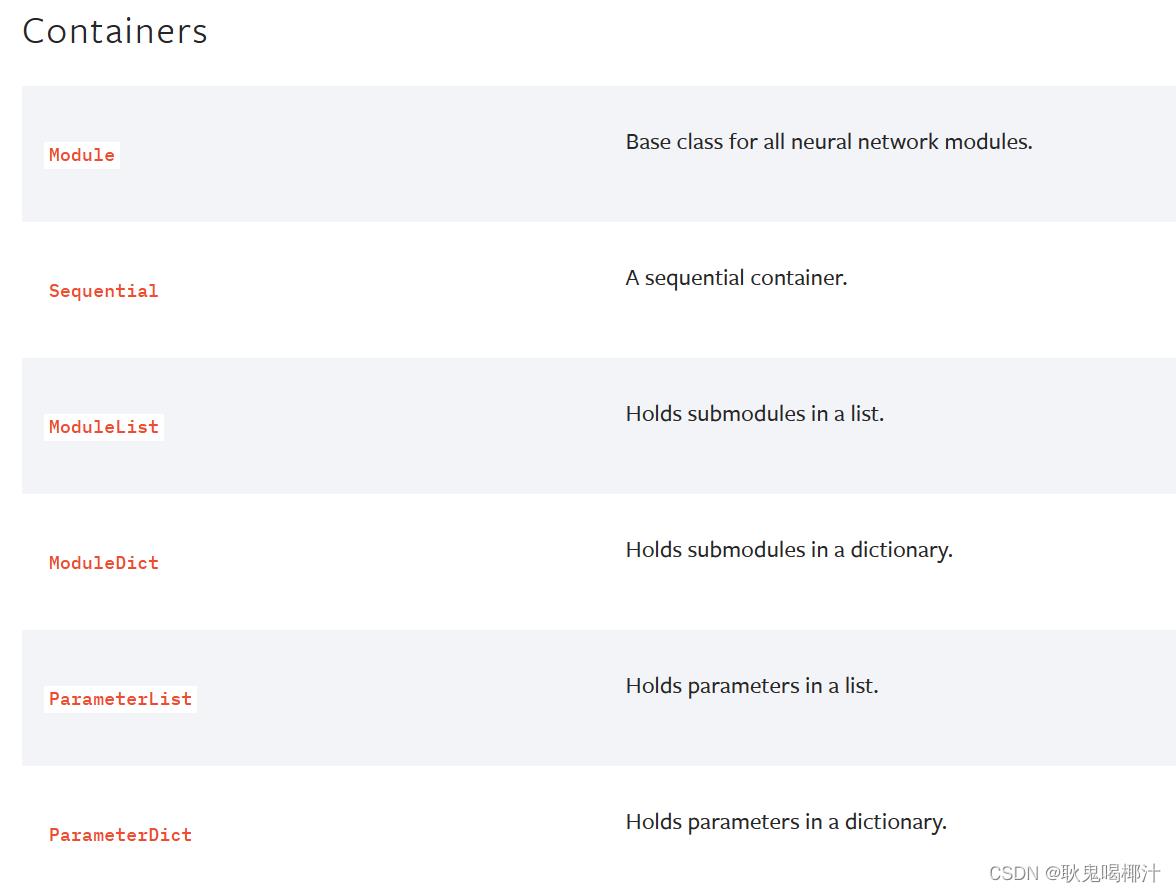
其中最常用的是 Module 模块(为所有神经网络提供基本骨架)
CLASS torch.nn.Module #搭建的 Model都必须继承该类模板:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module): #搭建的神经网络 Model继承了 Module类(父类)
def __init__(self): #初始化函数
super(Model, self).__init__() #必须要这一步,调用父类的初始化函数
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x): #前向传播(为输入和输出中间的处理过程),x为输入
x = F.relu(self.conv1(x)) #conv为卷积,relu为非线性处理
return F.relu(self.conv2(x))代码中比较重要:
前向传播 forward(在所有子类中进行重写)
反向传播 backward
实战
先介绍pycharm的实用工具
使用 Code —> Generate —> Override Methods 可以自动补全代码
例子:
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super().__init__()
# def __init__(self):
# super(Tudui, self).__init__()
def forward(self,input):
output = input + 1
return output
tudui = Tudui() #拿Tudui模板创建出的神经网络
x = torch.tensor(1.0) #将1.0这个数转换成tensor类型
output = tudui(x)
print(output)结果如下:

debug看流程
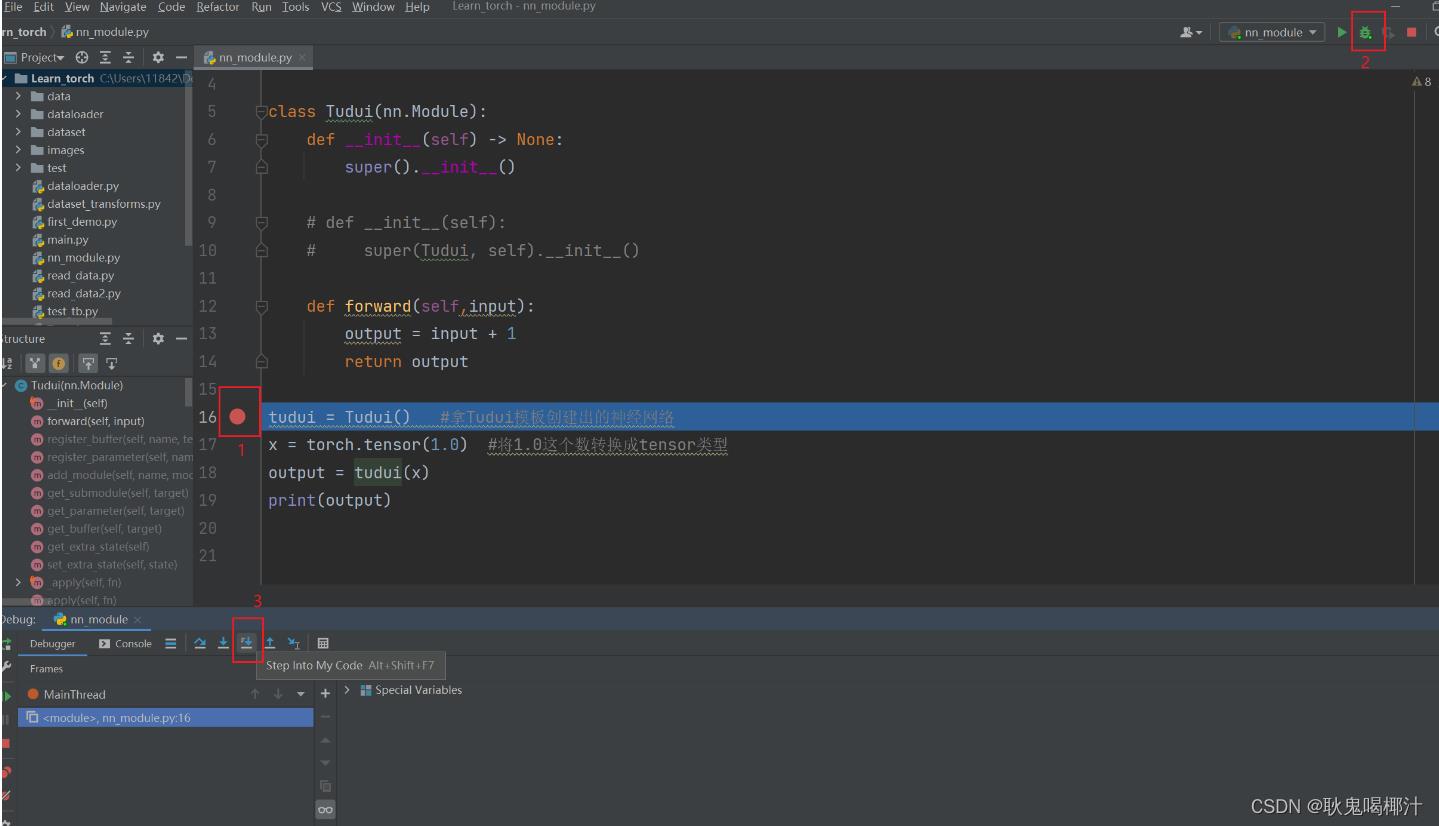
在下列语句前打断点:
tudui = Tudui() #整个程序的开始然后点击蜘蛛,点击 Step into My Code,可以看到代码每一步的执行过程
四. 土堆说卷积操作(可选看)
这节来讲解卷积层 :Convolution Layers
先进入pytorch官方网站地址:torch.nn — PyTorch 1.8.1 documentation
主要讲解 nn.Conve2d ,pytorch官方网站地址:Conv2d — PyTorch 1.8.1 documentation
torch.nn 和 torch.nn.functional 的区别:前者是后者的封装,更利于使用
点击 torch.nn.functional - Convolution functions - conv2d 查看参数

stride(步进)
可以是单个数,或元组(sH,sW) — 控制横向步进和纵向步进
卷积操作
卷积操作介绍
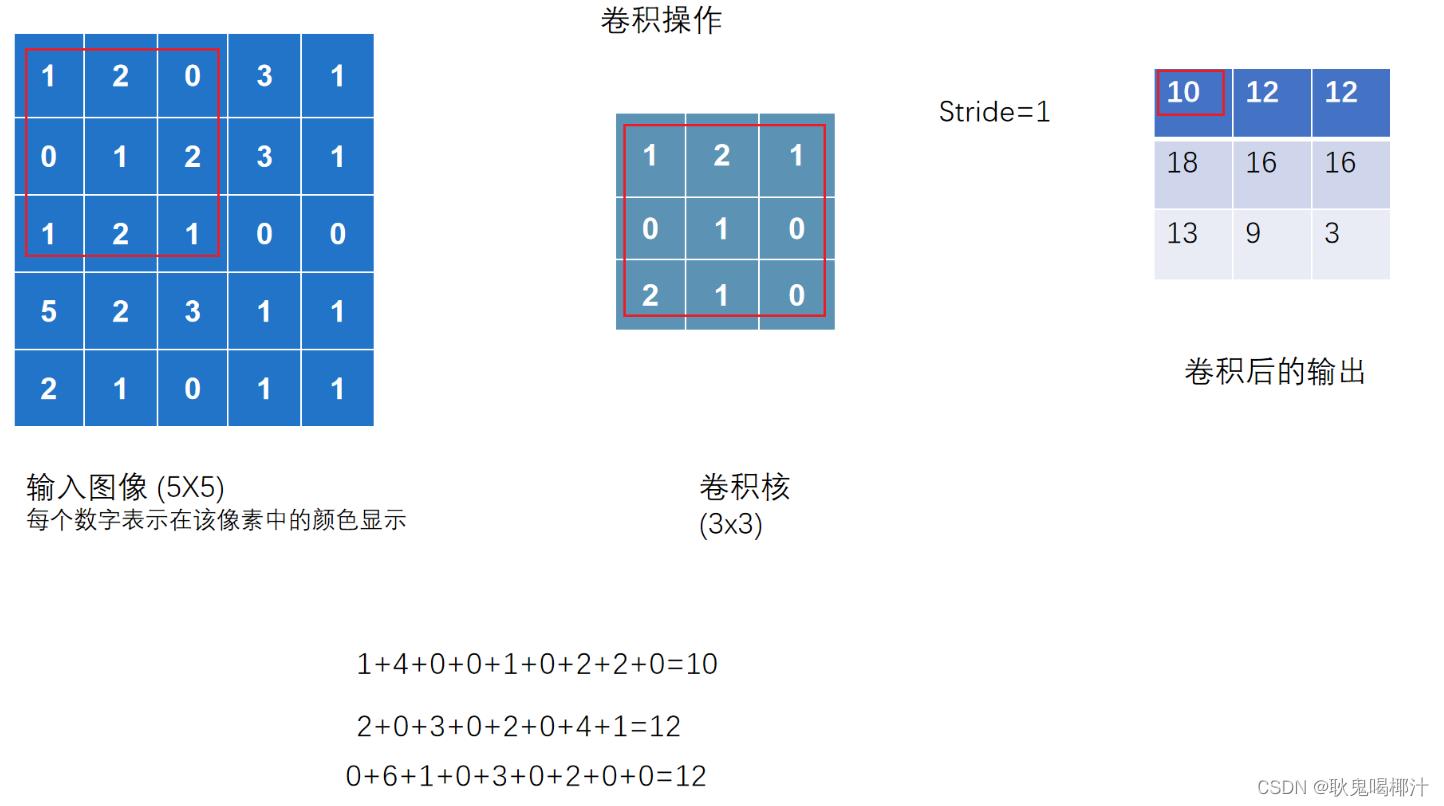
当 stride = 2 时,横向和纵向都是2,输出是一个2×2的矩阵
卷积操作实战
要求输入的维度 & reshape函数
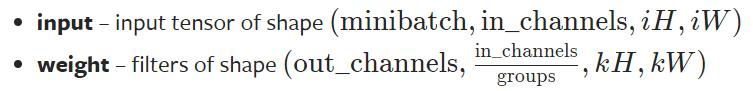
- input:尺寸要求是batch,几个通道,高,宽(4个参数)
- weight:尺寸要求是输出,in_channels(groups一般为1),高,宽(4个参数)
使用 torch.reshape 函数,将输入改变为要求输入的维度
实现上图代码
import torch
import torch.nn.functional as F
input =torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]) #将二维矩阵转为tensor数据类型
# 卷积核kernel
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
# 尺寸只有高和宽,不符合要求
print(input.shape) #5×5
print(kernel.shape) #3×3
# 尺寸变换为四个数字
input = torch.reshape(input,(1,1,5,5)) #通道数为1,batch大小为1
kernel = torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1) # .conv2d(input:Tensor, weight:Tensor, stride)
print(output)输出结果为:

当将步进 stride 改为 2 时:
output2 = F.conv2d(input,kernel,stride=2)
print(output2)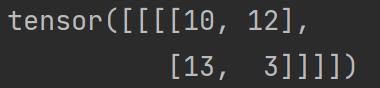
padding(填充)
在输入图像左右两边进行填充,决定填充有多大。可以为一个数或一个元组(分别指定高和宽,即纵向和横向每次填充的大小)。默认情况下不进行填充
padding=1:将输入图像左右上下两边都拓展一个像素,空的地方默认为0
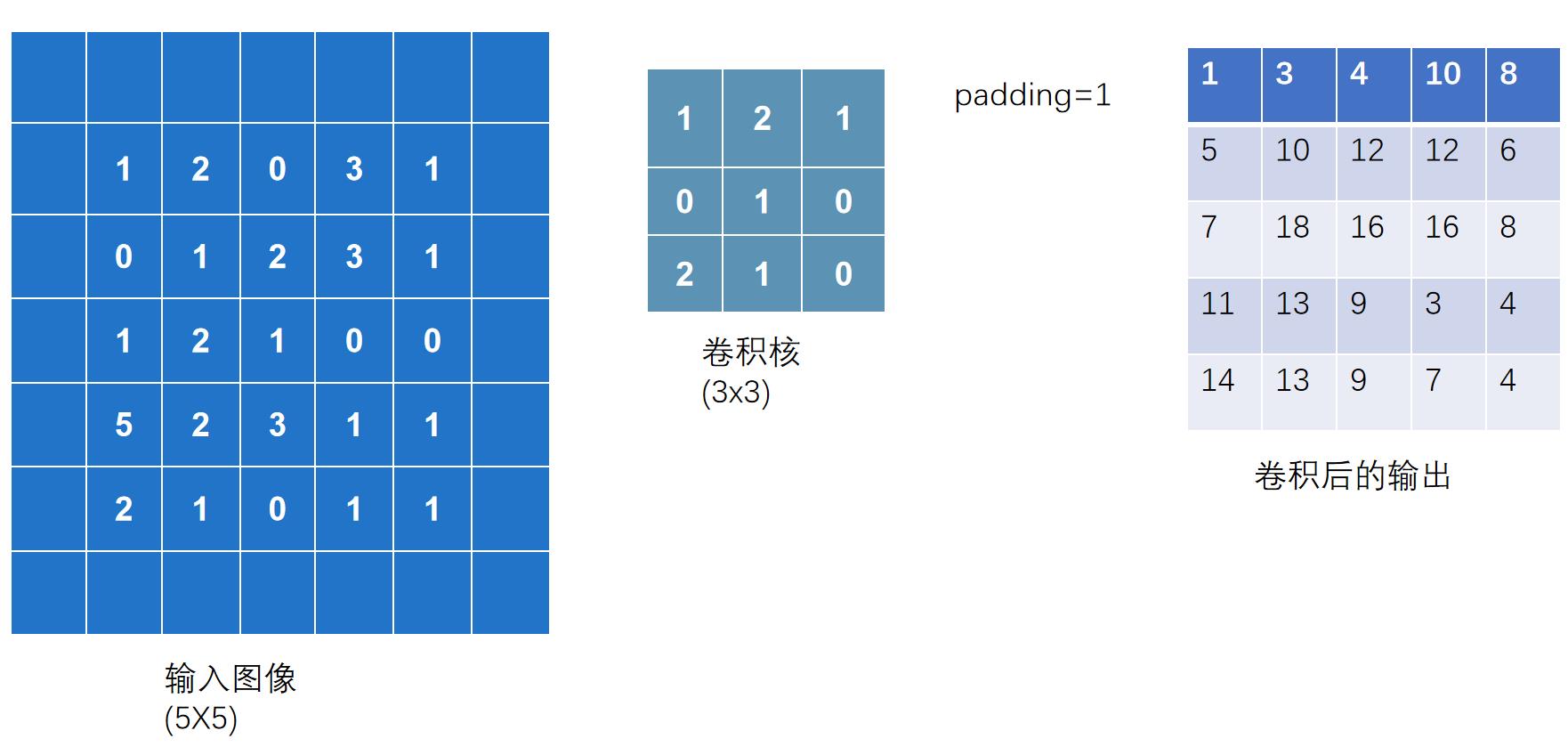
代码实现:
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print(output3)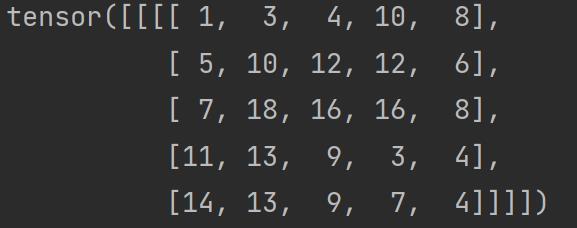
五、 神经网络 - 卷积层
pytorch官网网站卷积层(Convolution Layers):Convolution Layers
| 一维卷积 | Applies a 1D convolution over an input signal composed of several input planes. |
| 二维卷积 | Applies a 2D convolution over an input signal composed of several input planes. |
| 三维卷积 | Applies a 3D convolution over an input signal composed of several input planes. |
图像为二维矩阵,所以讲解 nn.Conv2d:
Conv2d — PyTorch 1.10 documentation

CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
# in_channels 输入通道数
# out_channels 输出通道数
# kernel_size 卷积核大小
#以上参数需要设置
#以下参数提供了默认值
# stride=1 卷积过程中的步进大小
# padding=0 卷积过程中对原始图像进行padding的选项
# dilation=1 每一个卷积核对应位的距离
# groups=1 一般设置为1,很少改动,改动的话为分组卷积
# bias=True 通常为True,对卷积后的结果是否加减一个常数的偏置
# padding_mode='zeros' 选择padding填充的模式参数含义:

( dilation 叫空洞卷积)
动图(演示地址): conv_arithmetic/README.md at master · vdumoulin/conv_arithmetic · GitHub

kernel_size
定义了一个卷积核的大小,若为3则生成一个3×3的卷积核
- 卷积核的参数是从一些分布中进行采样得到的
- 实际训练过程中,卷积核中的值会不断进行调整
in_channels & out_channels
- in_channels:输入图片的channel数(彩色图像 in_channels 值为3)
- out_channels:输出图片的channel数
in_channels 和 out_channels 都为 1 时,拿一个卷积核在输入图像中进行卷积
out_channels 为 2 时,卷积层会生成两个卷积核(不一定一样),得到两个输出,叠加后作为最后输出
CIFAR10数据集实例
# CIFAR10数据集
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train=False,transform=torchvision.transforms.ToTensor(),download=True) # 这里用测试数据集,因为训练数据集太大了
dataloader = DataLoader(dataset,batch_size=64)
# 搭建神经网络Tudui
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 因为是彩色图片,所以in_channels=3
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0) #卷积层conv1
def forward(self,x): #输出为x
x = self.conv1(x)
return x
tudui = Tudui() # 初始化网络
# 打印一下网络结构
print(tudui) #Tudui((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)))
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs,targets = data #经过ToTensor转换,成为tensor数据类型,可以直接送到网络中
output = tudui(imgs)
print(imgs.shape) #输入大小 torch.Size([64, 3, 32, 32]) batch_size=64,in_channels=3(彩色图像),每张图片是32×32的
print(output.shape) #经过卷积后的输出大小 torch.Size([64, 6, 30, 30]) 卷积后变成6个channels,但原始图像减小,所以是30×30的
writer.add_images("input",imgs,step)
# 6个channel无法显示。torch.Size([64, 6, 30, 30]) ——> [xxx,3,30,30] 第一个值不知道为多少时写-1,会根据后面值的大小进行计算
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step = step + 1运行后(如果没启用环境),在 Terminal 里启动 pytorch 环境:
conda activate pytorch打开 tensorboard:
tensorboard --logdir=logs打开网址(卷积后得到的输出)
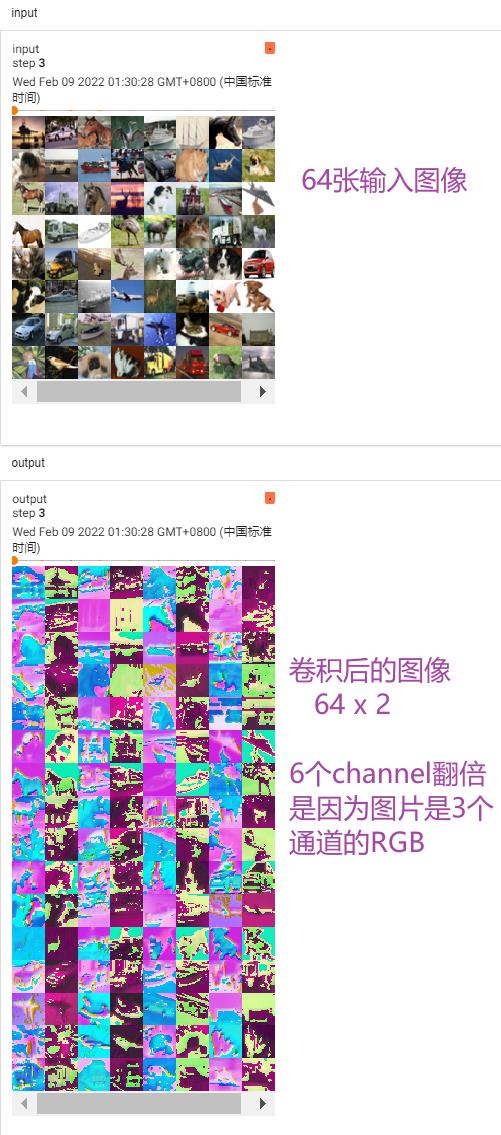
卷积层 vgg16
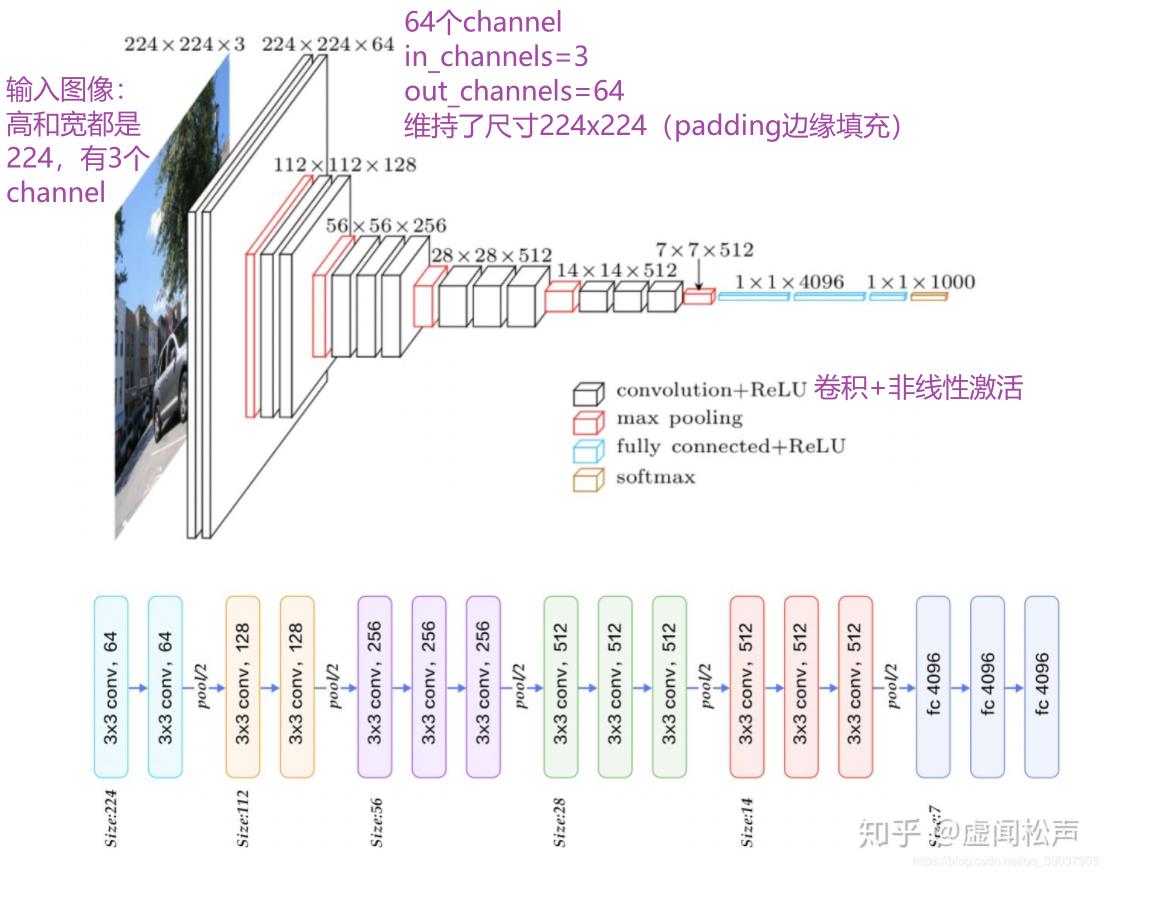
卷积前后维度计算公式

六、神经网络 - 最大池化的使用
池化层网站地址:torch.nn — PyTorch 1.8.1 documentation
- MaxPool:最大池化(下采样)
- MaxUnpool:上采样
- AvgPool:平均池化
- AdaptiveMaxPool2d:自适应最大池化
最常用:MaxPool2d — PyTorch 1.8.1 documentation
参数
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
# kernel_size 池化核
( 注意,卷积中stride默认为1,而池化中stride默认为kernel_size )

ceil_mode参数
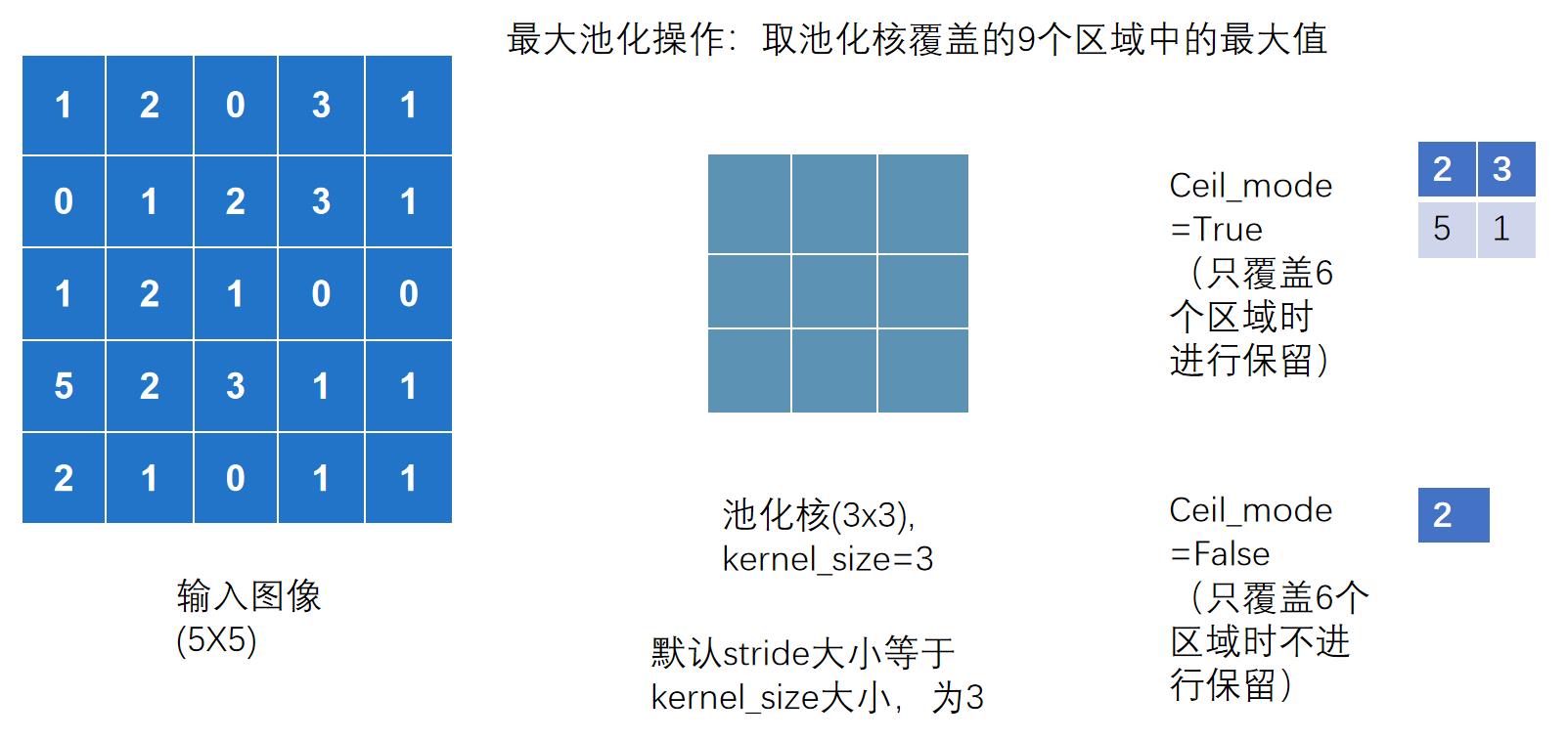
Ceil_mode 默认情况下为 False,对于最大池化一般只需设置 kernel_size 即可
输入输出维度计算公式

代码实现
上述图用代码实现:(以 Ceil_mode = True 为例)
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32) #最大池化无法对long数据类型进行实现,将input变成浮点数的tensor数据类型
input = torch.reshape(input,(-1,1,5,5)) #-1表示torch计算batch_size
print(input.shape)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
# 创建神经网络
tudui = Tudui()
output = tudui(input)
print(output)运行结果如下:
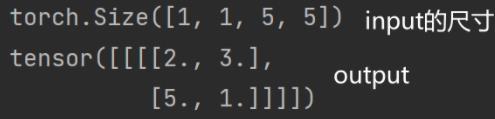
Ceil_mode = False 为例运行输出:(运行结果如下:)
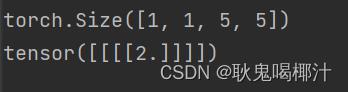
为什么要进行最大池化?最大池化的作用是什么?
最大池化的目的是保留输入的特征,同时把数据量减小(数据维度变小),对于整个网络来说,进行计算的参数变少,会训练地更快,(池化最大的作用是增大感受野,让后面的卷积看到更全局的内容。)
- 如上面案例中输入是5x5的,但输出是3x3的,甚至可以是1x1的
- 类比:1080p的视频为输入图像,经过池化可以得到720p,也能满足绝大多数需求,传达视频内容的同时,文件尺寸会大大缩小
池化一般跟在卷积后,卷积层是用来提取特征的,一般有相应特征的位置是比较大的数字,最大池化可以提取出这一部分有相应特征的信息
池化不影响通道数
池化后一般再进行非线性激活
用数据集 CIFAR10 实现最大池化
代码如下:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../data",train=False,download=True,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
# 搭建神经网络
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
# 创建神经网络
tudui = Tudui()
writer = SummaryWriter("../logs_maxpool")
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images("input",imgs,step)
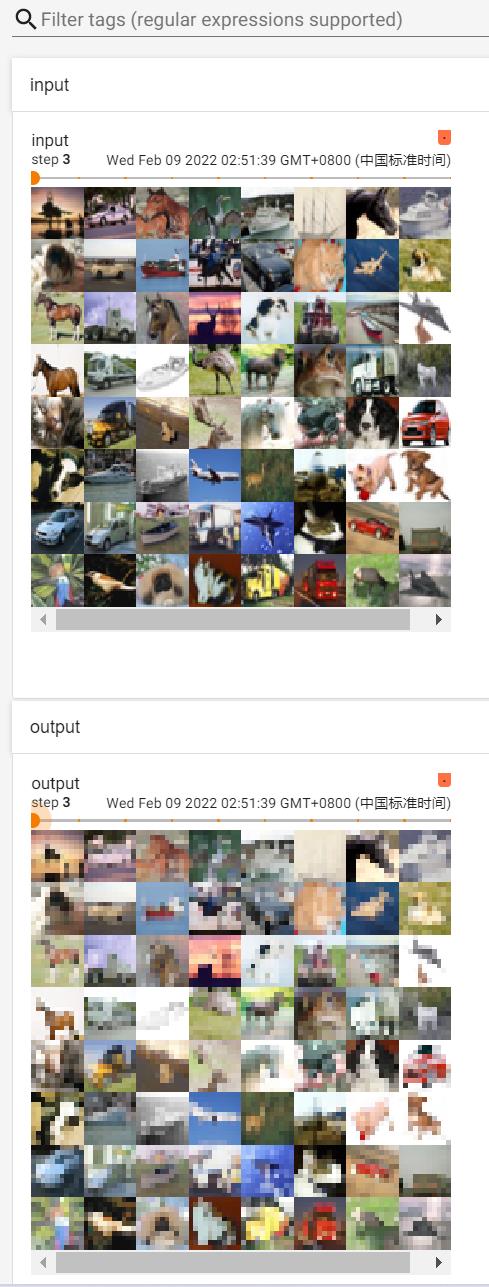
output = tudui(imgs) #output尺寸池化后不会有多个channel,原来是3维的图片,经过最大池化后还是3维的,不需要像卷积一样还要reshape操作(影响通道数的是卷积核个数)
writer.add_images("output",output,step)
step = step + 1
writer.close()运行后在 terminal 里输入(注意是在pytorch环境下):
tensorboard --logdir=logs_maxpool打开网址:
这篇课程的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连+关注支持下~
学习系列笔记:
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(一)_耿鬼喝椰汁的博客-CSDN博客
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(二)_耿鬼喝椰汁的博客-CSDN博客
以上是关于pytorch土堆pytorch教程学习Transforms 的使用的主要内容,如果未能解决你的问题,请参考以下文章