我是土堆 - Pytorch教程 知识点 学习总结笔记
Posted 耿鬼喝椰汁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我是土堆 - Pytorch教程 知识点 学习总结笔记相关的知识,希望对你有一定的参考价值。
此文章【我是土堆 - Pytorch教程】 知识点 学习总结笔记(一)包括:python学习中的2大法宝、Pycharm及Jupyter使用及对比、PyTorch加载数据初认识、Dataset类代码实战。
目录
2.3 PyCharm、PyCharm的Python控制台、Jupyter Notebook 三种运行方式的适用场景:
3.1 PyTorch 读取数据涉及两个类:Dataset & Dataloader
1.python学习中的2大法宝
package(名称为 pytorch)就像一个工具箱,有不同的分隔区,分隔区里有不同的工具
探索工具箱,两个道具:
dir() 函数:打开,看见。 (能让我们知道工具箱以及工具箱中的分隔区有什么东西)
help() 函数:说明书。 (能让我们知道每个工具是如何使用的,工具的使用方法)

dir(pytorch),就能看到输出1、2、3、4等分隔区;想继续探索第3个分隔区里有什么的话,dir(pytorch.3),输出会是a,b,c(3号分隔区里有a,b,c等工具),如何使用?
help(pytorch.3.a) 输出:将此扳手放在特定地方,然后拧动
实战操作
打开PyCharm,输入
dir(torch)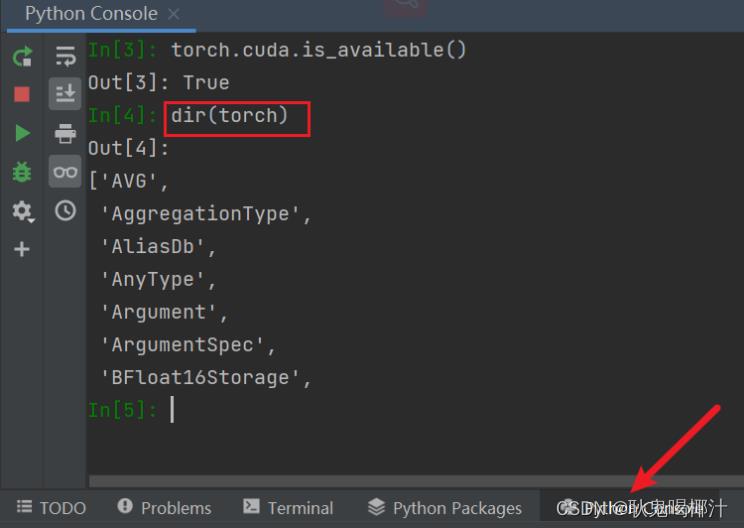
可以看到输出了大量的分隔区(或理解为更小的工具箱),ctrl+F找到cuda

看cuda分隔区里有什么,输入
dir(torch.cuda)可以看到又输出了大量的分隔区

继续输入:
dir(torch.cuda.is_available)可以看到输出的前后都带有双下划线__,这是一种规范,说明这个变量不容许篡改,即它不再是一个分隔区,而是一个确确实实的函数(相当于工具,可以用help()函数)

对工具使用 help(): (注意这里 is_available 不带括号)
help(torch.cuda.is_available)
返回一个布尔值(True或False),表明cuda是否可用
总结
- dir() 函数:打开package
- help() 函数:官方的解释文档,看函数怎么用
2.Pycharm及Jupyter使用及对比
2.1在PyCharm中新建项目
(1)新建文件夹 Learn_torch(右键:New Folder)


接下来 File —> Settings

(2)新建 Python文件,命名 first_demo

(3)运行程序:为该Python文件设置相应的Python解释器后,点击绿色的运行符号或直接右键:

or

python控制台

Python控制台(Python Console)是以每一行作为一个块进行执行。
2.2 在Jupyter中新建项目
在cmd打开anaconda的命令行或者直接在pycharm终端中,进入pytorch的conda环境,再打开Jupyter.


Jupyter以每一个块为一个运行整体。
若在这里出现问题可看以下解决文章:
【已解决】Jupyter notebook无法跳转网页的问题(亲测成功)_jupyter notebook没有跳转网页_耿鬼喝椰汁的博客-CSDN博客【已解决】jupyter notebook 运行代码无反应\\内核忙\\local host已拒绝链接的问题(亲测成功)_jupyter 拒绝了我们的连接请求_耿鬼喝椰汁的博客-CSDN博客
2.3 PyCharm、PyCharm的Python控制台、Jupyter Notebook 三种运行方式的适用场景:
1.PyCharm:代码是以块为一个整体运行的话,Python文件的块是所有行的代码,即在PyCharm运行时出现错误时,修改后要从头开始运行
2. PyCharm的Python控制台:PyCharm的Python控制台是一行一行代码运行的,即以每一行为一个块来运行的(也可以以任意行为块运行,按Shift+回车,输入下一行代码,再按回车运行)
- 优点:Python控制台可以看到每个变量的属性
- 缺点:出现错误后代码的可阅读性大大降低
- 使用时间:一般调试时使用
3.Jupyter:Jupyter以任意行为块运行,每一个块为一个运行整体。
(Python控制台和Jupyter的好处是:某一块发生错误时,修改这一块时不会影响前面已经运行的块。)
三种对比:
| PyCharm | 从头开始运行 | 通用,传播方便,适用于大型项目 | 需要从头运行 |
| PyCharm的Python控制台 | 一行一行运行(也可以以任意行) | 可以显示每个变量的属性,一般调试时使用 | 出错时会破坏整体阅读性,不利于代码阅读及修改 |
| Jupyter | 以任意行为块运行 | 代码阅读性较高,利于代码的阅读及修改 | 环境需要配置 |
3.PyTorch加载数据初认识
对于神经网络训练,要从数据海洋里找到有用的数据
3.1 PyTorch 读取数据涉及两个类:Dataset & Dataloader
Dataset:提供一种方式,获取其中需要的数据及其对应的真实的 label 值,并完成编号。主要实现以下两个功能:
1.如何获取每一个数据及其label
2.告诉我们总共有多少的数据
Dataloader:打包(batch_size),为后面的神经网络提供不同的数据形式
3.2 数据集的几种组织形式
数据集 hymenoptera_data(蚂蚁和蜜蜂的数据集,二分类)

- train 里有两个文件夹:ants 和 bees,其中分别都是一些蚂蚁和蜜蜂的图片。
- train_images是一个文件夹,train_labels是另一个文件夹,如OCR数据集。
- label直接为图片的名称。
3.3 Dataset类
from torch.utils.data import Dataset查看Dataset类的介绍:
help(Dataset)还可以使用代码:
Dataset??Dataset 是一个抽象类,所有数据集都需要继承这个类,所有子类都需要重写 __getitem__ 的方法,这个方法主要是获取每个数据集及其对应 label,还可以重写长度类 __len__。
def __getitem__(self, index):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])4.Dataset类代码实战
4.1 读取图片
我们可以使用两种方法来读取图片,例子如下:
# 法1
from PIL import Image
img_path = "xxx"
img = Image.open(img_path)
img.show()
# 法2:利用opencv读取图片,获得numpy型图片数据
import cv2
cv_img=cv2.imread(img_path)若报错没有opencv包则安装opencv:在 PyCharm的终端里输入
pip install opencv-python之后我们就可以继续导入包:
import cv24.2 控制台读取与可视化图片
1. 数据格式1
- 绝对路径:绝对路径是指目录下的绝对位置,直接到达目标位置,通常是从盘符开始的路径。 例子:E:\\PyTorch\\Pytorch\\Learn_torch\\dataset\\train\\ants
- 相对路径:相对路径是指以当前文件资源所在的目录为参照基础,链接到目标文件资源(或文件夹)的路径。 例子:dataset/train/ants
(注意,路径引号前加 r 可以防止转义,或使用双斜杠)
在Python控制台读取数据,可以看到图片的属性(第二行通过路径显示图片):
from PIL import Image
img_path = r"E:\\PyTorch\\Pytorch\\Learn_torch\\dataset\\train\\ants\\0013035.jpg"
img = Image.open(img_path)输入 img.size 就可以返回图片属性的数值

再输入 img.show() ,显示(可视化)图片:

读数据
想要获取图片地址(通过索引),需要os库。
函数 os.listdir() :让文件夹下东西变成一个列表。 要用idx获取图片时要先获取图片的列表。
import os
dir_path = "dataset/train/ants"
img_path_list = os.listdir(dir_path) # 将文件夹下的东西变成一个列表右侧属性栏:

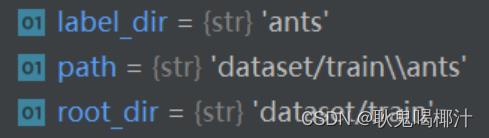
拼接路径:
import os
root_dir = "dataset/train"
label_dir = "ants"
path = os.path.join(root_dir, label_dir) # 把两个路径拼接在一起path = os.path.join(root_dir, label_dir) # 把两个路径拼接在一起
完整代码:
from torch.utils.data import Dataset
from PIL import Image #读取图片
import os #想要获得所有图片的地址,需要导入os(系统库)
#创建一个class,继承Dataset类
class MyData(Dataset):
def __init__(self,root_dir,label_dir): #创建初始化类,即根据这个类去创建一个实例时需要运行的函数
#通过索引获取图片的地址,需要先创建图片地址的list
#self可以把其指定的变量给后面的函数使用,相当于为整个class提供全局变量
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path) #获得图片下所有的地址
def __getitem__(self, idx): #idx为编号
#获取每一个图片
img_name=self.img_path[idx] #名称
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name) # 每张图片的相对路径
img=Image.open(img_item_path) #读取图片
label=self.label_dir
return img,label
def __len__(self): #数据集的长度
return len(self.img_path)
#用类创建实例
root_dir="dataset/train"
ants_label_dir="ants"
bees_label_dir="bees"
ants_dataset=MyData(root_dir,ants_label_dir)
bees_dataset=MyData(root_dir,bees_label_dir)
img, label = ants_dataset[0]
img.show() # 可视化第一张图片
#将ants(124张)和bees(121张)两个数据集进行拼接
train_dataset=ants_dataset+bees_dataset2. 数据格式2
当label比较复杂,存储数据比较多时,不可能以文件夹命名的方式,而是以每张图片对应一个txt文件,txt里存储label信息的方式.

可使用以下代码把原来的ants重命名为ants_image:
import os
root_dir=r"E:\\PyTorch\\Pytorch\\Learn_torch\\dataset\\train"
# 把原来的ants重命名为ants_image
target_dir="ants_image"
img_path=os.listdir(os.path.join(root_dir,target_dir))
label=target_dir.split('_')[0] # ants
out_dir="ants_label"
for i in img_path:
file_name=i.split('.jpg')[0]
with open(os.path.join(root_dir,out_dir,".txt".format(file_name)),'w') as f:
f.write(label)运行结果如下:

这篇课程的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连支持下
以上是关于我是土堆 - Pytorch教程 知识点 学习总结笔记的主要内容,如果未能解决你的问题,请参考以下文章