LinkedHashMap
LinkedHashMap 是一个链表,哈希表,线程不安全的,允许 key 和 value 为 null。
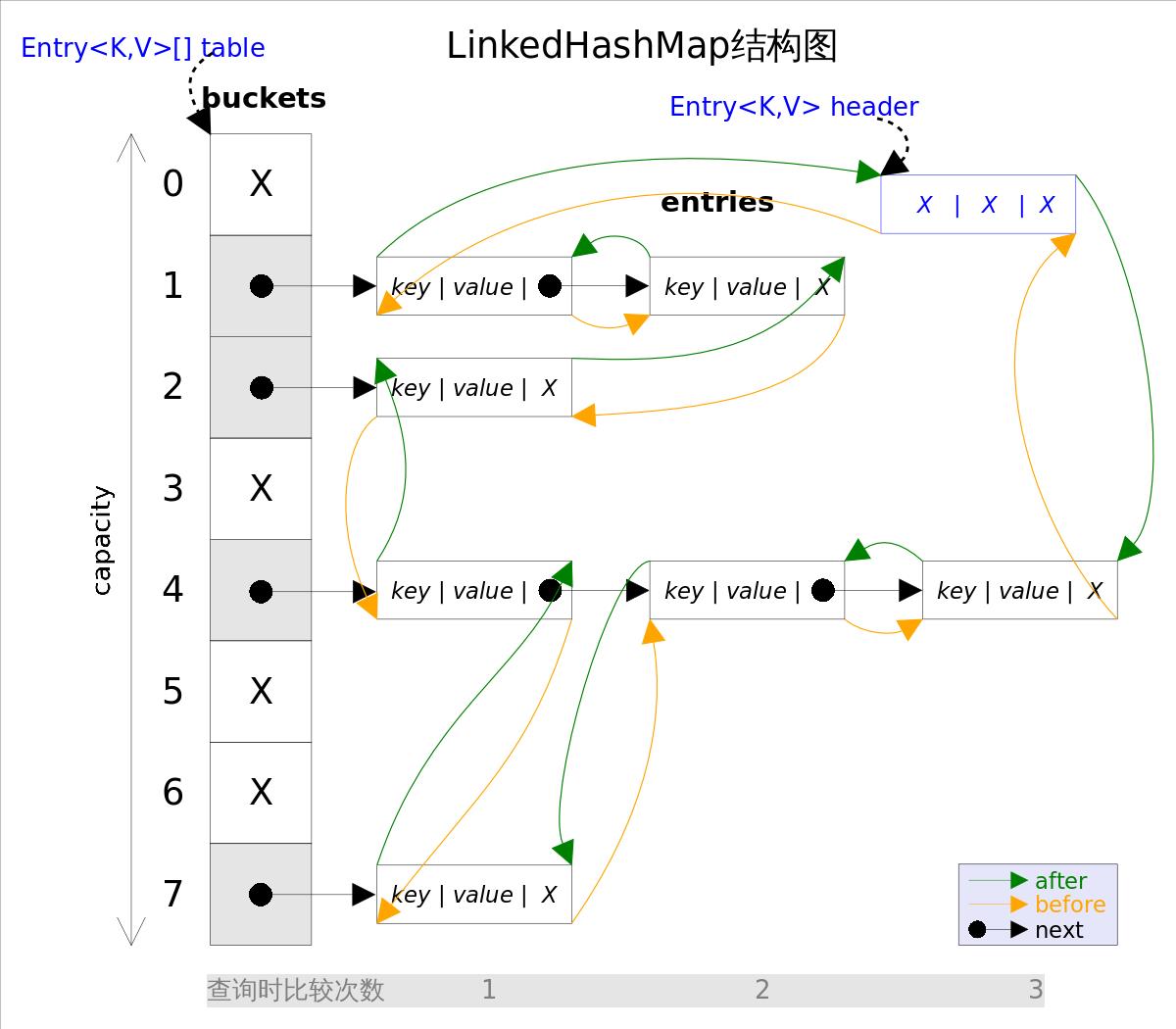
它继承自 HashMap ,实现了 Map<K,V> 接口,内部维护了一个双向链表。每次插入数据或者访问,修改数据时,会增加节点或者调整链表的节点顺序,以决定迭代输出的顺序。
默认情况,遍历顺序时按照插入节点的顺序。也可以在构造时传入 accessOrder 参数,使得其遍历顺序按照访问的顺序输出(访问后节点会被移至链表尾部)。
LinkedHashMap 继承自 HashMap,所以继承了 HashMap 的特点,比如扩容策略,哈希桶的长度是 2 的 N 次方等等。
节点
LinkedHashMap 的节点 Entry<K,V> 继承自 HashMap.Node<K,V>,在其基础上扩展可以下,改成了一个双向链表。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
同时类里有两个成员变量 head tail,分别指向内部双链表的头和尾。
//双向链表的头结点
transient LinkedHashMap.Entry<K,V> head;
//双向链表的尾节点
transient LinkedHashMap.Entry<K,V> tail;
构造函数
//默认是false,则迭代时输出的顺序是插入节点的顺序。若为true,则输出的顺序是按照访问节点的顺序
//为true时,可以在这基础之上构建一个LruCach
final boolean accessOrder;
public LinkedHashMap() {
super();
accessOrder = false;
}
构造函数和 HashMap 相比,就是增加了一个 accessOrder 参数,用于控制迭代时的节点顺序。
put 方法
LinkedHashMap 并没有重写任何 put 方法,但是重写了构建新节点的 newNode() 方法。newNode() 在每次构建新节点时,通过 linkNodeLast(p),将新节点链接在内部双向链表的尾部。
//在构建新节点时,构建的是`LinkedHashMap.Entry` 不再是`Node`.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//将新增的节点,连接在链表的尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//集合之前是空的
if (last == null)
head = p;
else {//将新节点连接在链表的尾部
p.before = last;
last.after = p;
}
}
以及 HashMap 专门预留给 LinkedHashMap 的 afterNodeAccess() afterNodeInsertion() afterNodeRemoval() 方法。
//回调函数,新节点插入之后回调 , 根据evict 和 判断是否需要删除最老插入的节点。如果实现LruCache会用到这个方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//LinkedHashMap 默认返回false 则不删除节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
//LinkedHashMap 默认返回false 则不删除节点。 返回true 代表要删除最早的节点。通常构建一个LruCache会在达到Cache的上限是返回true
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
remove 方法
LinkedHashMap 也没有重写 remove 方法,因为它的删除逻辑和 HashMap 并无区别。但是它重写了 afterNodeRemoval() 这个回调方法。是删除节点操作真正的执行者。
//在删除节点e时,同步将e从双向链表上删除
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//待删除节点 p 的前置后置节点都置空
p.before = p.after = null;
//如果前置节点是null,则现在的头结点应该是后置节点a
if (b == null)
head = a;
else//否则将前置节点b的后置节点指向a
b.after = a;
//同理如果后置节点时null ,则尾节点应是b
if (a == null)
tail = b;
else//否则更新后置节点a的前置节点为b
a.before = b;
}
get 方法
LinkedHashMap 重写了 get() 和 getOrDefault() 方法:
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
对比 HashMap 中的实现,LinkedHashMap 之是增加了在成员变量 accessOrder 为 true 的情况下,要去回调 void afterNodeAcceess(Node<K,V> e) 函数,afterNodeAcceess 函数中,会将当前被访问的节点 e,移动至内部的双向链表的尾部。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;//原尾节点
//如果accessOrder 是true ,且原尾节点不等于e
if (accessOrder && (last = tail) != e) {
//节点e强转成双向链表节点p
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p现在是尾节点, 后置节点一定是null
p.after = null;
//如果p的前置节点是null,则p以前是头结点,所以更新现在的头结点是p的后置节点a
if (b == null)
head = a;
else//否则更新p的前直接点b的后置节点为 a
b.after = a;
//如果p的后置节点不是null,则更新后置节点a的前置节点为b
if (a != null)
a.before = b;
else//如果原本p的后置节点是null,则p就是尾节点。 此时 更新last的引用为 p的前置节点b
last = b;
if (last == null) //原本尾节点是null 则,链表中就一个节点
head = p;
else {//否则 更新 当前节点p的前置节点为 原尾节点last, last的后置节点是p
p.before = last;
last.after = p;
}
//尾节点的引用赋值成p
tail = p;
//修改modCount。
++modCount;
}
}
containsValue
LinkedHashMap 重写了该方法,相比于 HashMap 的实现,更为高效。
public boolean containsValue(Object value) {
//遍历一遍链表,去比较有没有value相等的节点,并返回
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
相比与 HashMap 用两个 for 循环的实现:
// 两层 for 循环,先遍历数组,然后遍历数组里面的链表
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
总结
LinkedHashMap 相比于 HashMap 的源码相对简单。它继承了 HashMap,仅重写了几个方法用来改变它的迭代遍历时的顺序。
在每次插入数据,或者访问,修改数据时,会增加节点,或者调整链表的节点顺序。以决定迭代的输出顺序。
LinkedHashMap 的存储与 HashMap 相同。还是数组加链表加红黑树。只不过元素之间会有双向指针,这个指针能决定元素的迭代和访问顺序。
经典用法
LinkedHashMap 除了可以保证迭代顺序外,还有一个非常有用的用法:可以轻松实现一个采用了 FIFO 替换策略的缓存。LinkedHashMap 有一个子类方法 protected boolean removeEldestEntry(Map.Entry<K,V> eldest),该方法的作用时告诉 Map 要删除 “最老” 的 Entry (最早插入的)。当元素个数超过一定数量时,让 removeEldestEntry() 返回 true,就能够实现一个固定大小的 FIFO 策略的缓存。
/** 一个固定大小的FIFO替换策略的缓存 */
class FIFOCache<K, V> extends LinkedHashMap<K, V>{
private final int cacheSize;
public FIFOCache(int cacheSize){
this.cacheSize = cacheSize;
}
// 当Entry个数超过cacheSize时,删除最老的Entry
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > cacheSize;
}
}