前言
今天继续学习关于Map家族的另一个类 LinkedHashMap 。先说明一下,LinkedHashMap 是继承于 HashMap 的,所以本文只针对 LinkedHashMap 的特性学习,跟HashMap 相关的一些特性就不做进一步的解析了,大家有疑惑的可以看之前的博文。
深入解析
LinkedHashMap的基本结构
首先,看一下LinkedHashMap类的定义结构:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
它继承了 HashMap,并实现了Map接口,所以,LinkedHashMap的数据结构和HashMap非常相似,都是散列表的结构,同时继承了很多HashMap的成员变量和方法,例如加载因子,容量,桶等,但在细节上却有些许不同,比如:
- HashMap中 ‘’桶“ 的链表结点是单向的结点,而LinkedHashMap 中的链表结点多出了前后的指向属性,所以LinkedHashMap 中桶的链表是双向链表;
- HashMap中的链表只做数据存储,LinkedHashMap 的链表控制存储顺序;
- HashMap桶的链表产生是因为产生hash碰撞,所有数据形成链表 (红黑树) 存储在一个桶中,LinkedHashMap 中双向链表会串联所有的数据,也就是说有桶中的数据都是会被这个双向链表管理。
这些区别正是我们专门费劲学习LinkedHashMap 的原因,不然直接用HashMap完了,省事。
下面开始一一深入了解。
LinkedHashMap的实体类Entry
LinkedHashMap 类中有专门为双向链表的结点作为载体的实体类Entry,它继承了HashMap中的Entry,并加入了两个属性before, after ,用于指向前后结点的指针。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
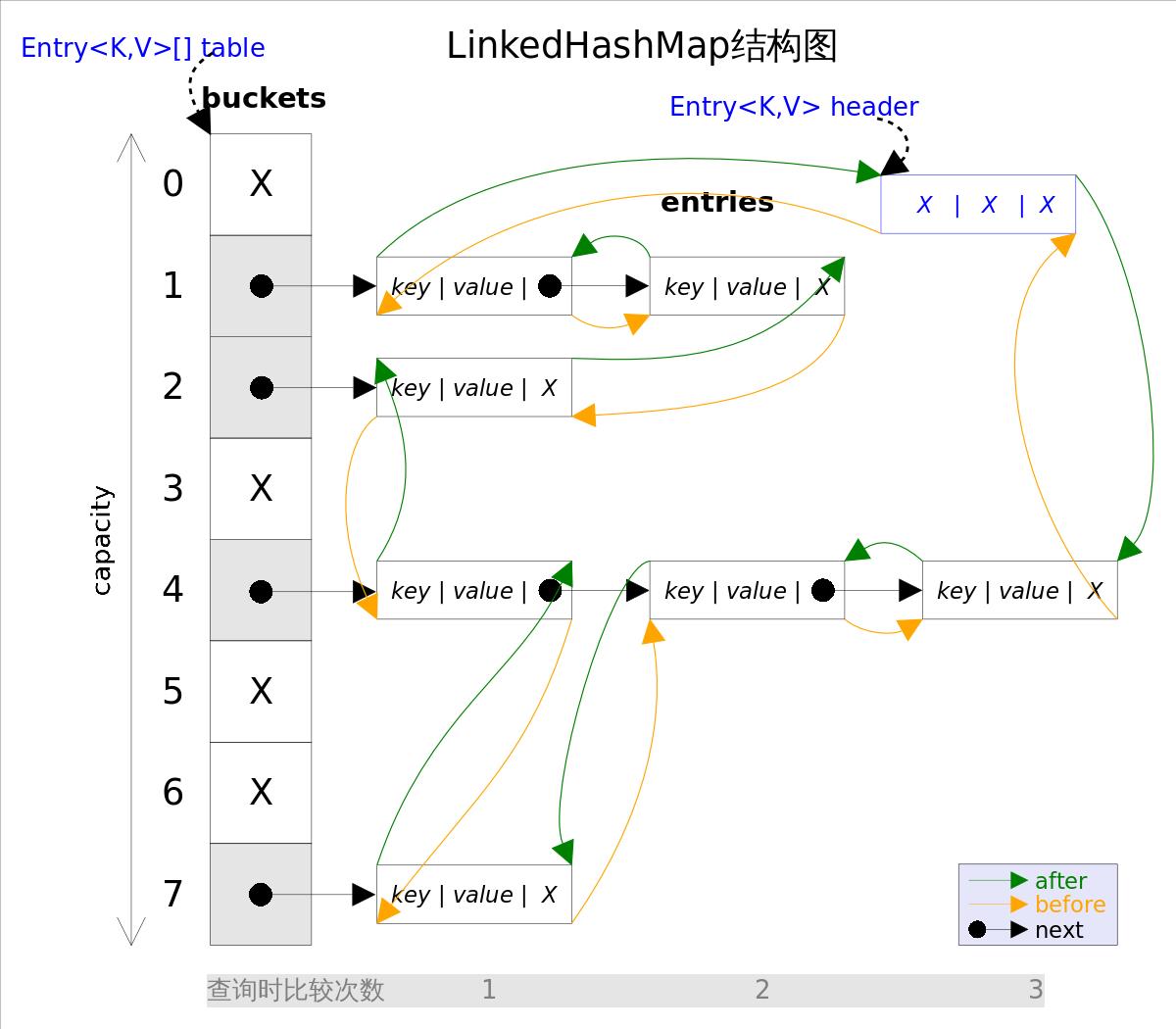
因为这两个指针,桶中的链表才能实现双向链表的功能,将所有的节点已链表的形式串联一起来 ,这是LinkedHashMap 的结构图 (摘自 Java集合之LinkedHashMap):
新的属性
LinkedHashMap继承了HashMap的所有非private属性,同时也多了几个新的属性,分别是
//双向链接的头结点,最久的
transient LinkedHashMap.Entry<K,V> head;
//双向链接的尾结点,最新的
transient LinkedHashMap.Entry<K,V> tail;
//true表示最近最少使用次序(LRU),false表示插入顺序
final boolean accessOrder;
看完三个属性后,我们再来看看默认的构造方法:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
可以看到,LinkedHashMap的构造方法都是默认调用了父类的构造方法,并且几乎都是把属性accessOrder 赋值为false,除了第五个将其作为参数初始化,也就是说,默认情况下,LinkedHashMap创建对象都是采用插入顺序的方式来维持键值对的次序的。
插入顺序解析
下面通过具体的代码来展示 LinkedHashMap 的默认插入顺序效果
public class Test {
public static void main(String[] args) {
LinkedHashMap map = new LinkedHashMap<Integer,Integer>();
for (int i = 1; i<=5;i++){
map.put(i,i);
}
System.out.println("正常输出=="+map.toString());
map.put(6,6);
System.out.println("插入元素=="+map.toString());
}
}
//结果
正常输出=={1=1, 2=2, 3=3, 4=4, 5=5}
插入元素=={1=1, 2=2, 3=3, 4=4, 5=5, 6=6}
可以看出,当插入新元素时,容器会默认把元素放到最后,这是为什么呢?
我们点开put源码进行查看,发现直接跳到了HashMap的put方法,也就是说,LinkedHashMap 类中没有对 put() 做具体的实现,直接复用了父类的方法,这是HashMap中的方法源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在HashMap的源码中,初始化容器时调用了newNode(),这个方法在 LinkedHashMap 中做了重载,也是其能实现插入顺序保证的关键,下面看具体的源码:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
//秘密是这里初始化的是自己的Entry类,然后调用linkNodeLast
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
跟踪 linkNodeLast 方法,
// link at the end of list,把节点连接到链表尾处
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
//把new的Entry给tail
tail = p;
//若没有last,说明p是第一个节点,head=p
if (last == null)
head = p;
else {
//否则把节点放到链表尾处
p.before = last;
last.after = p;
}
}
到这里就非常清晰了,LinkedHashMap 在插入元素时会调用自己重载的newNode() 方法,new一个自己的Entry方法并把节点放到链表结尾处,这也是它能实现插入元素顺序放置的原因。
LRU算法的实现
前面说到,LinkedHashMap 创建默认的实例可以实现插入顺序的保证效果,它默认初始化的成员变量 accessOrder 的值是false的,如果传入accessOrder 为true,那么就启用LRU算法,下面给个例子演示下:
import java.util.LinkedHashMap;
public class Test {
public static void main(String[] args) {
Map map = new LinkedHashMap<Integer,Integer>(20,0.75f,true);
for (int i = 1; i<=5;i++){
map.put(i,i);
}
System.out.println("正常输出=="+map.toString());
map.get(3);
System.out.println("读取元素=="+map.toString());
map.put(6,6);
System.out.println("插入元素=="+map.toString());
}
}
//输出结果
正常输出=={1=1, 2=2, 3=3, 4=4, 5=5}
读取元素=={1=1, 2=2, 4=4, 5=5, 3=3}
插入元素=={1=1, 2=2, 4=4, 5=5, 3=3, 6=6}
可以看到,当初始化的实例时传入值为 true 的 accessOrder 时,不管是插入元素还是读取元素,都是将最近用到的元素放到最后,这是因为 在put 和 get方法中都做了特定的处理。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
//为true,调用afterNodeAccess方法
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
afterNodeAccess的源码解析:
//将最近使用的Node,放在链表的最末尾
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//仅当按照LRU原则且e不在最末尾,才执行修改链表,将e移到链表最末尾的操作
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//将p的后一个结点置为null,因为执行后p在末尾,后一个结点肯定为null
p.after = null;
//p的前结点不存在,把头结点设置为a
if (b == null)
head = a;
else
//如果b不为null,那么b的后节点指向a
b.after = a;
//如果a节点不为空,a的后节点指向b
if (a != null)
a.before = b;
else
//如果a为空,那么b就是尾节点
last = b;
//尾节点为null,p直接作为头节点
if (last == null)
head = p;
else {
//否则就把p作为尾节点
p.before = last;
last.after = p;
}
//把p赋值给双向链表的尾节点
tail = p;
++modCount;
}
}
所以,当调用这个方法的时候,就会将节点设置到链表的尾节点,从而也就达到了LRU的效果。
同理,在put方法中也调用了这个方法,不过LinkedHashMap 没有自己的put方法,直接调用的是父类中的方法,在父类的方法中也调用了 afterNodeAccess() 方法。
不过,在HashMap中,afterNodeAccess方法并没有任何实现,LinkedHashMap中重载了该方法,所以,当调用put插入元素时,其实也会调用LinkedHashMap 的afterNodeAccess方法。
除此之外,LinkedHashMap还有很多重载的方法,限于篇幅就不一一介绍了。
总结
最后说明一下,LinkedHashMap是HashMap的一个子类,其特殊实现的仅仅是保存了记录的插入顺序,所以在Iterator迭代器遍历LinkedHashMap时先得到的键值是先插入的,然而,由于其存储沿用了HashMap结构外还多了一个双向顺序链表,所以在一般场景下遍历时会比HashMap慢,此外具备HashMap的所有特性和缺点。
所以,除非是对插入顺序读取比较严格的情况,否则不建议用LinkedHashMap,一般情况下,HashMap足以满足我们的日常使用。