java 集合框架-LinkedHashMap
Posted 智公博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java 集合框架-LinkedHashMap相关的知识,希望对你有一定的参考价值。
一、概述
1、继承扩展HashMap,实现Map接口,基于双向链表实现有序,支持插入有序和访问顺序
2、允许NULL元素,基本操作(add、contrains、remove)与HashMap一样有稳定性能(hash分布均匀情况下)
3、由于需要维护链表,性能较HashMap差,而迭代可能不一定,LinkedHashMap的迭代所需时间与 大小 成比例,HashMap迭代所需时间与 容量 成比例
4、初始容量和负载因子对性能有影响,这与HashMap相似,但初始容量非常大的影响比HashMap要小,因为迭代不受容量影响
5、非同步,非线程安全,可使用 Collections.synchronizedMap 封装为同步
6、迭代同样是 快速失败 机制
二、源码分析
1、变量
/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
private final boolean accessOrder;header 保持链表头的引用, accessOrder 表示改对象的有序性是访问顺序还是插入顺序,默认为false:插入顺序
2、构造函数
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the specified initial capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity, float loadFactor)
super(initialCapacity, loadFactor);
accessOrder = false;
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the specified initial capacity and a default load factor (0.75).
*
* @param initialCapacity the initial capacity
* @throws IllegalArgumentException if the initial capacity is negative
*/
public LinkedHashMap(int initialCapacity)
super(initialCapacity);
accessOrder = false;
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap()
super();
accessOrder = false;
/**
* Constructs an insertion-ordered <tt>LinkedHashMap</tt> instance with
* the same mappings as the specified map. The <tt>LinkedHashMap</tt>
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map<? extends K, ? extends V> m)
super(m);
accessOrder = false;
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder)
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
基本上与HashMap的构造函数对应上,每个构造函数都是super先构造父类,从构造函数看,只增加了一个 accessOrder 变量
3、核心实现
从构造函数看不到LinkedHashMap有啥不一样,往下看发现它重写实现了HashMap定义的许多钩子方法,如 init():
@Override
void init()
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
这个init是HashMap定义留给子类的钩子,方便子类扩展,LinkedHashMap便是利用这些扩展点;初始化中,header 指向一个空的Entry,并且头尾指针都是自身;这个初始化方法在HashMap的构造方法调用,能保证此时还没有元素插入;后面的方法有很多关于这个双向链表的指针操作,先看看这个链表Node的定义:
private static class Entry<K,V> extends HashMap.Entry<K,V>
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next)
super(hash, key, value, next);
/**
* Removes this entry from the linked list.
*/
private void remove()
before.after = after;
after.before = before;
/**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(Entry<K,V> existingEntry)
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
/**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
void recordAccess(HashMap<K,V> m)
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder)
lm.modCount++;
remove();
addBefore(lm.header);
void recordRemoval(HashMap<K,V> m)
remove();
可以看到,LinkedHashMap的Entry也是继承HashMap的Entry,并且增加了两个变量:前后指针,重写实现了HashMap定义的钩子方法:recordAccess和recordRemoval,这两个方法在HashMap.Entry定义但为空实现;recordAccess在已存在元素被get或者put的时候被调用,作用是维护元素的’访问有序’,如果变量accessOrder为true(访问顺序),那么该方法将当期访问元素移动到链表最后(header的前面)以保持访问顺序,否则不做任何操作;而recordRemoval方法在元素被移除remove时调用,这里调用了一个私有方法remove,实际是将删除的元素从双向链表移除掉;
接下来我们看看,一个元素正常put进来时的操作,LinkedHashMap并没有重写HashMap的put方法,而只是重写了addEntry和createEntry方法:
/**
* This override alters behavior of superclass put method. It causes newly
* allocated entry to get inserted at the end of the linked list and
* removes the eldest entry if appropriate.
*/
void addEntry(int hash, K key, V value, int bucketIndex)
super.addEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest))
removeEntryForKey(eldest.key);
/**
* This override differs from addEntry in that it doesn't resize the
* table or remove the eldest entry.
*/
void createEntry(int hash, K key, V value, int bucketIndex)
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
回顾下HashMap的正常put流程(详情可看之前文章):计算hash、获取下标、查找是否已存在key-value(如是则更新后结束)、新增Entry(addEntry)、判断扩容、创建新Entry(createEntry);即 put 会调用addEntry,而addEntry会调用createEntry;LinkedHashMap 重写的createEntry方法中,实现与HashMap只多了一句逻辑:e.addBefore(header),将当期新增的元素加到链表的最后一位,这里就不需要判断或者调用recordAccess,因为无论何种排序,新增都是排最后(最新位置);
而重写的addEntry方法,调用父类的实现后,进行了一个判断:是否删除最旧的元素,这个判断方法removeEldestEntry在LinkedHashMap中直接返回false,即不删除最旧元素;那么这个设计有什么用了?我们知道LinkedHashMap支持维持访问顺序,也就是最近访问的排序在前,在此排序方式下,最老的一个元素eldest也就是最旧没有访问过的,这就非常像LRU(Least recently used)缓存了,加入新元素时,将最少使用的元素删除掉;我们只需要简单继承下LinkedHashMap,设置accessorder 为true,重写改方法:
private static final int MAX_ENTRIES = 100;
protected boolean removeEldestEntry(Map.Entry eldest)
return size() > MAX_ENTRIES;
这样就基于LinkedHashMap简单实现了一个LRU缓存;
而事实上真的是有这么实现的,或者大家都已经使用过而不知道而已,在工程代码中通过Eclipse看这个方法的继承实现:
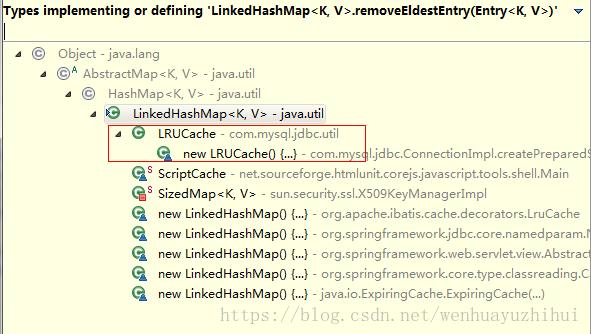
可以看到mysql jdbc里面的一个LRU缓存就是这么实现:
/**
* @author Mark Matthews
* @version $Id$
*/
public class LRUCache extends LinkedHashMap<Object, Object>
private static final long serialVersionUID = 1L;
protected int maxElements;
public LRUCache(int maxSize)
super(maxSize, 0.75F, true);
this.maxElements = maxSize;
/*
* (non-Javadoc)
*
* @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry)
*/
@Override
protected boolean removeEldestEntry(Entry<Object, Object> eldest)
return (size() > this.maxElements);
LinkedHashMap还重写了HashMap两个方法:transfer和containsValue,逻辑都是一样的,只是利用了链表来迭代提高性能:
/**
* Transfers all entries to new table array. This method is called
* by superclass resize. It is overridden for performance, as it is
* faster to iterate using our linked list.
*/
@Override
void transfer(HashMap.Entry[] newTable, boolean rehash)
int newCapacity = newTable.length;
for (Entry<K,V> e = header.after; e != header; e = e.after)
if (rehash)
e.hash = (e.key == null) ? 0 : hash(e.key);
int index = indexFor(e.hash, newCapacity);
e.next = newTable[index];
newTable[index] = e;
/**
* Returns <tt>true</tt> if this map maps one or more keys to the
* specified value.
*
* @param value value whose presence in this map is to be tested
* @return <tt>true</tt> if this map maps one or more keys to the
* specified value
*/
public boolean containsValue(Object value)
// Overridden to take advantage of faster iterator
if (value==null)
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
else
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
return false;
但是我觉得,不是说使用LinkedHashMap就性能比HashMap好,只能说这个迭地上性能稍微好一点,但是却要增加头尾指针的空间和维护双向链表的操作;
最后来看看迭代器,应该可以猜到,肯定是基于双向链表进行迭代而不再是底层table数组
private abstract class LinkedHashIterator<T> implements Iterator<T>
Entry<K,V> nextEntry = header.after;
Entry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterator
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext()
return nextEntry != header;
public void remove()
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
Entry<K,V> nextEntry()
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
其他迭代器与HashMap一样,继承父类LinkedHashIterator,重写next方法返回需要的对象
private class KeyIterator extends LinkedHashIterator<K>
public K next() return nextEntry().getKey();
private class ValueIterator extends LinkedHashIterator<V>
public V next() return nextEntry().value;
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>>
public Map.Entry<K,V> next() return nextEntry();
三、总结
有几个点是比较重要的:
1、双向链表及维护,在Entry中增加了before、after指针
2、accessorder 控制顺序方式:访问顺序、插入顺序(默认)
3、可以继承实现LRU缓存
4、迭代方式使用链表,性能有提升,增加了链表空间和维护
以上是关于java 集合框架-LinkedHashMap的主要内容,如果未能解决你的问题,请参考以下文章