Deep video视频理解论文串讲(上)论文精读笔记
Posted CV-杨帆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Deep video视频理解论文串讲(上)论文精读笔记相关的知识,希望对你有一定的参考价值。
b站源视频(视频理解论文串讲(上)【论文精读】):https://www.bilibili.com/video/BV1fL4y157yA/
0 前言
视频里将视频理解分四大方向:
1,hand-crafted --> cnn
2,two-stream
3,3D cnn
4,video transformer
1 DeepVideo
cvpr 14
论文pdf:Large-scale Video Classification with Convolutional Neural Networks
DeepVideo是在Alexnet出现之后,在深度学习时代,使用超大规模的数据集,使用比较深的卷积神经网络去做的视频理解(DeepVideo是处理视频理解的最早期工作之一)。
作者团队来自:Google Research、 Stanford University
该团队为视频领域作出很大的贡献,如:Sports-1M、YouTube-8M、AVA(action detection)等数据集。很大程度推动了视频领域的发展。
DeepVideo论文中的方法是比较直接的,论文中的想法就是如何将卷积神经网络从图片识别应用到视频识别中。视频与图片的不同在于,视频多了一个时间轴(有更多的视频帧)。所以论文中尝试了以下几个变体(下图后3种):
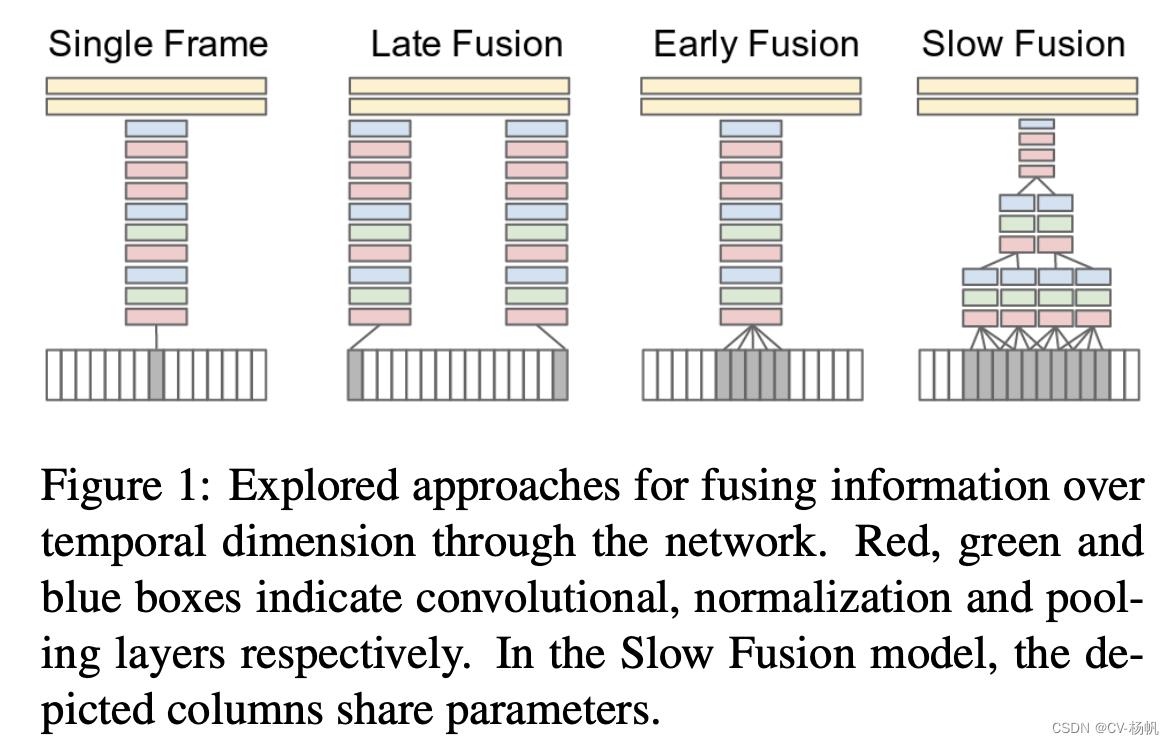
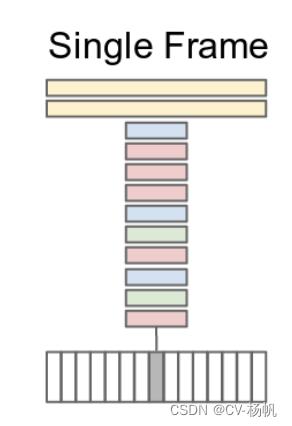
首先看下面的single frame的方式(即单帧的方式),其实就是一个图片分类的任务。在视频里任选一帧,然后把这一帧通过一个卷积神经网络,然后通过两个FC,最后得到分类结果,这个其实就是一个baseline。它完全没有时间信息,也没有视频信息在里面。
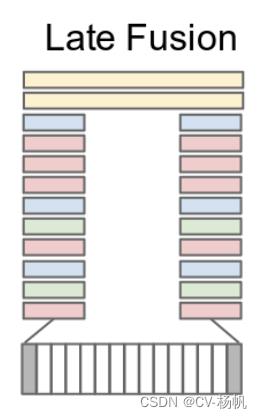
接着,作者做了Late Fusion,之所以叫Late,就是因为它在网络输出层做的一些结合。如下图,从视频中,随机选几帧,然后每一帧都单独通过一个卷积神经网络,这两个神经网络是权值共享的,将两个特征合并,再通过FC【全连接层】,最后做输出。 这样就稍微有一些时序上的信息了。
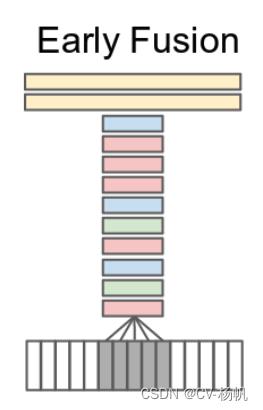
然后是Early Fusion,作者在输入层就做了融合。具体做法就是在RGB在Channel上直接合起来。
原来一张图片,有3个channel,现在有5张图片,就有3x5=15个channel。那就意味着网络结构要进行一定的改变了,尤其是第一层。
第一个卷积层接受的输入的通道数,就要由原来的3变成15,之后的网络都和之前的保持不变。
这样的做法,可以在输入层就可以感受到时序上的改变,希望能学到一些全局的运动或者时间信息。
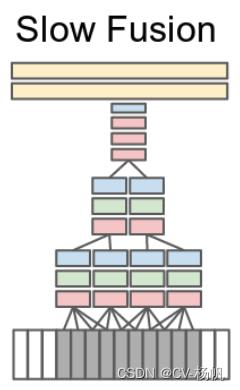
Slow Fusion是在Late Fusion 和 Early Fusion的基础上提出,Late Fusion合并太晚,Early Fusion合并太早了,Slow Fusion在特征层面做了一些融合。
具体做法就是选19个视频帧的1个小的视频片段,每4个视频帧就通过一个卷积神经网络,刚开始的层也是权值共享的,在抽出最开始的这些特征之后,由最开始的4个输入片段,慢慢合并成2个输入片段,再去做一些卷积操作,去学习更深层的特征。然后在融合2个特征,最后把学习到的特征给FC。
也就是说,整个网络都是多视频的整体的学习,作者最后实验结果,Slow Fusion结果较好(相对于前三个)。
但是从总体看来,这几种方法的差别都不大。即使在100万个视频上去做了预训练之后,在UCF101小数据集上去做迁移学习的时候,效果竟然还比不上之前的手工特征。
这就十分诡异了,所以作者就开始尝试另外一条路。
作者发现,用2D卷积神经网络去学时许特征,不好学,很难学。
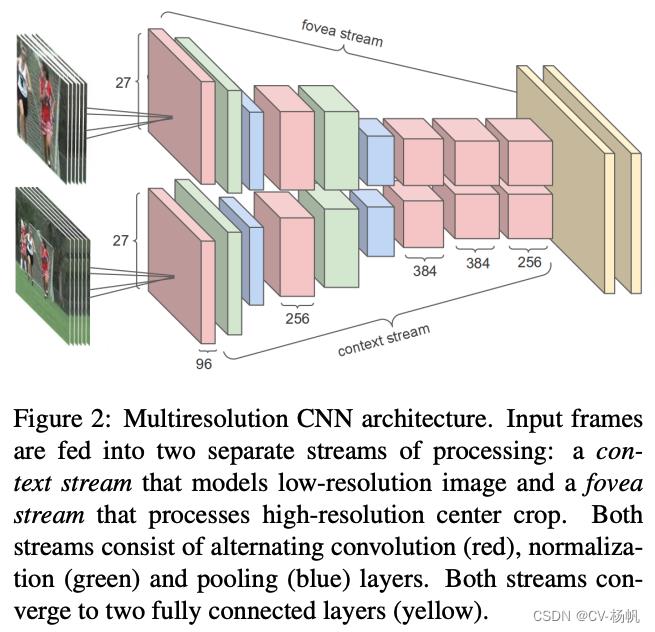
作者尝试了【多分辨率卷积网络】(Multiresolution CNN),作者将输入分成了2部分,一个是原图,另外一个是从原图的正中间抠出来的一部分。无论是对图片还是视频,最有用的物体大多会出现在图片或者视频的正中间。图中上面一条流称为fovea stream,下面一条流称为context stream。fovea是人眼视网膜最中心的凹陷地方,是对外界变化最敏感的一个区域。context就是指图片的整体信息。作者想通过这些操作让网络学习到网络中最有用的信息,又能学习到这个图片整体的理解。这个架构也算是双流结构。Multiresolution CNN中的两个网络是权值共享的。这种结构也可以理解为早期对注意力的一种使用方式。作者强制性想让这个网络去关注图片的中心区域。
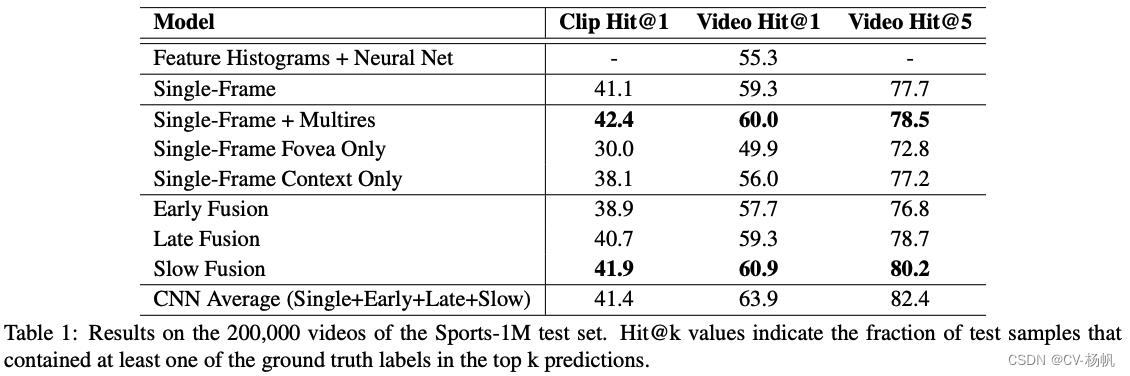
经过在Sports-1M数据上实验后发现,多分辨率卷积网络又一定提升,比如和Single-Frame(基准 Baseline)与Single-Frame Multires相比,有一定提升,但是提升相对来说比较小。Early Fusion和Late Fusion 都比Single-Frame(基准 Baseline)差。Slow Fusion经过一系列复杂操作后,也只比Single-Frame(基准 Baseline)高一点点。
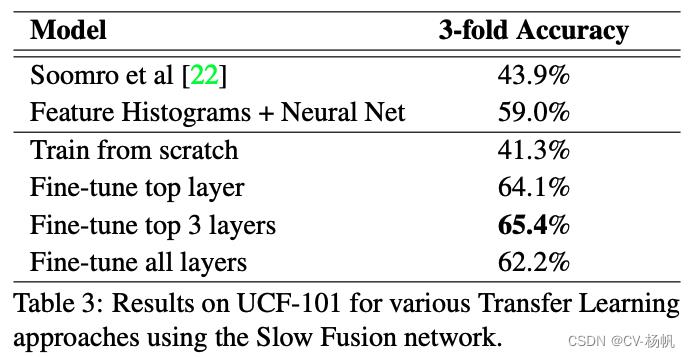
作者又在14年大家广为接受的UCF101数据集上,作者做好的变体:Fine-tune top 3 layers,也只有65.4%的准确度。而当时最好的手工方法已经可以达到87%的准确度。这样巨大的差异,让人们思考,深度学习网络在图片分类、图片检测效果都很好,为啥到了视频分类就碰壁了呢?
其实这篇文章的意义,不在于它的效果,作者不仅提出了当时最大的视频理解数据集,而且把你能想到的,最直接的方式,全都试了一遍,为后续的工作做了一个很好的铺垫。这才有了深度学习在视频领域的飞速发展。所以到了18、19年,视频理解(或者动作识别),已经是cv领域排名前5、6的关键词。
以上是关于Deep video视频理解论文串讲(上)论文精读笔记的主要内容,如果未能解决你的问题,请参考以下文章
视频去模糊论文阅读-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
Two-Stream Convolutional Networks for Action Recognition in Videos双流网络论文精读
视频异常检测综述-论文阅读Deep Video Anomaly Detection: Opportunities and Challenges
论文精读Benchmarking Deep Learning Interpretability in Time Series Predictions