视频去模糊论文阅读-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
Posted 金牌港C
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频去模糊论文阅读-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior相关的知识,希望对你有一定的参考价值。
代码地址:https://github.com/csbhr/CDVD-TSP
Abstract
本文提出了一种简单而有效的深度卷积神经网络(CNN)视频去模糊模型。该算法主要由中间潜在帧的光流估计和潜在帧恢复步骤组成。首先建立了一个深度CNN模型,从中间潜在帧估计光流,然后根据估计的光流恢复潜在帧。为了更好地探索视频中的时间信息,我们开发了一个temporal sharpness prior来约束深度CNN模型,以帮助潜在帧的恢复。我们开发了一种有效的级联训练方法,并以端到端的方式联合训练所提出的CNN模型。大量的实验结果表明,该算法在benchmark datasets和real-world videos上都优于当时最先进的方法。
1.Introduction
视频去模糊是视觉和图形学的一个基本问题,旨在从模糊序列中估计潜在帧。随着越来越多的视频使用手持和机载视频捕捉设备拍摄,这个问题在过去十年中得到了积极的研究。视频中的模糊通常是由相机抖动、物体运动和深度变化引起的。恢复潜在帧是高度不适定问题,因为只给出了模糊的视频。为了从模糊序列中恢复潜在帧,传统的方法通常会对运动模糊和潜在帧进行估计。在这些方法中,运动模糊通常被建模为光流[1,2,3,4]。这些方法成功的关键是在一些hand-crafted priors约束下联合估计了光流和潜在帧。然而,对运动模糊和潜在帧的估计通常会导致复杂的能量函数难以解决。深度卷积神经网络(CNN)已被开发用于解决视频去模糊问题,由于深度CNN在单图像去模糊中的成功,[5]中使用连接连续帧的方法,并开发了基于编码-解码器结构的深度CNN来直接估计潜在帧。[6]开发了一个深度循环网络,通过连接多帧特征来周期性地恢复潜在帧.为了更好地获取时间信息,[7]开发了时空3D卷积来帮助潜在帧恢复。当运动模糊不显著和输入帧间的位移较小时,这些方法表现良好。然而,它们对于包含明显模糊和位移较大的帧的情况时就不那么有效了,因为它们不考虑输入帧之间的对齐。为了解决这个问题,有几种方法估计了显式[8,9,10]或隐式[11]的连续输入帧之间的对齐,以使用端到端可训练的深度cnn来恢复潜在帧。这些算法表明,使用更好的对齐策略能够提高视频去模糊的性能。然而,这些算法的主要成功是由于大模型的使用。这些模型不能在实际情况下很好地推广出来。我们注意到在variational model-based的方法中存在大量的先验知识,并且在视频去模糊方面是有效的。一个很自然的问题是,我们是否可以利用variational model-based的方法中的先验知识,使深度CNN模型更加紧凑,从而提高视频去模糊的准确性?
为了解决这一问题,我们提出了一个简单而紧凑的深度CNN视频去模糊模型。我们的算法是将相邻帧warp到参考帧,使得连续的帧与参考帧对齐,从而产生更清晰的中间潜在帧。由于生成的中间潜在帧可能包含伪影和模糊效应,我们进一步开发了一个基于编解码器架构的深度CNN模型来去除伪影和模糊。为了更好地探索连续帧的性质,我们在约束深度CNN模型之前开发了一个temporal sharpness。然而,由于我们的算法从中间潜在帧估计光流作为运动模糊信息,它需要一个反馈回路。为了有效地训练该算法,我们开发了一种级联训练方法,并以端到端的方式联合训练所提出的模型。
本文贡献如下:
1)我们提出了一个简单而紧凑的深度CNN模型,它可以同时估计视频去模糊的光流和潜在帧。
2)为了更好地探索连续帧的性质,我们在约束深度CNN模型之前开发了一个temporal sharpness。
2.Motivation(这一段有感兴趣的话可以参考文献12)
为了更好地激励我们的工作,我们首先重新审视传统的variational model-based方法。对于视频中的模糊过程,第i个模糊图像通常被建模为:
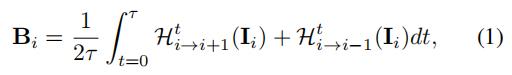
其中 表示第i个清晰图像;τ代表相对曝光时间;
表示第i个清晰图像;τ代表相对曝光时间;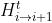 和
和 表示为warping functions,将wrap到
表示为warping functions,将wrap到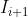 和
和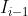 ,如果我们将
,如果我们将 和
和 表示为第i帧的双向光流,那么
表示为第i帧的双向光流,那么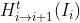 与
与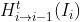 就被表示为:
就被表示为: 和
和 。基于模糊模型(公式1),去模糊的过程可以看作是下式的最小化:
。基于模糊模型(公式1),去模糊的过程可以看作是下式的最小化:

其中 和
和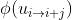 为潜在图像和光流的约束条件。在优化过程中,大多数传统的方法(如[12])通过迭代最小化来估计潜在图像和光流。
为潜在图像和光流的约束条件。在优化过程中,大多数传统的方法(如[12])通过迭代最小化来估计潜在图像和光流。
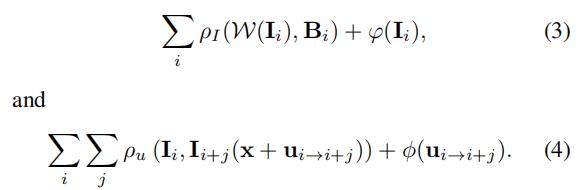
我们注意到,最小化公式3和公式4能够消除模糊 ,然而去模糊的性能主要取决于潜在图像和光流的约束条件的选择,并且确定适当的约束条件并不简单。此外,常用的约束条件通常会导致高度非凸的目标函数,难以解决。
我们进一步注意到,大多数基于CNN的深度方法直接从模糊输入中估计清晰的视频。然而,他们是从模糊的输入估计warping functions而不是使用清晰的帧,并且也没有用到一些先验知识。这对于具有显著模糊的视频去模糊效果较差。为了克服这些问题,我们开发了一种有效的算法,充分利用了variational model-based方法中的优点,并使用了先验知识,使深度cnn更紧凑的视频去模糊。
3.Proposed Algorithm
该算法包含optical flow estimation module、latent image restoration module和the temporal sharpness prior。光流估计模块提供了关于潜在图像恢复的运动信息,而潜在图像恢复模块进一步便于光流估计,从而使估计的光流更加准确。the temporal sharpness prior能够探索从相邻帧的锐度像素,从而促进更好的帧恢复。所有的模块都在一个统一的框架内进行联合训练。
3.1.Optical flow estimation
光流估计模块用于估计输入的相邻帧之间的光流,其中所估计的光流为图像恢复提供运动信息。 我们使用PWC-Net[13]作为光流估计算法。给定任意两个中间潜在帧和,我们计算光流为: ,其中,
,其中,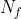 为以两张图像为输入的光流估计网络。对于任何其他两个帧,网络共享相同的网络参数。
为以两张图像为输入的光流估计网络。对于任何其他两个帧,网络共享相同的网络参数。
3.2.Latent frame restoration(其中里面的公式细节可以参考文献14)
利用估计的光流,我们可以利variational model据现有的方法[12]恢复潜在帧。然而,在求解公式3中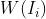 会产生很大的计算量,并且需要定义潜在帧的先验,这使得图像恢复变得更加复杂。我们注意到,即模糊过程(公式1)的效果是生成一个模糊的帧,使它尽可能地接近于观察到的输入帧
会产生很大的计算量,并且需要定义潜在帧的先验,这使得图像恢复变得更加复杂。我们注意到,即模糊过程(公式1)的效果是生成一个模糊的帧,使它尽可能地接近于观察到的输入帧 。其可以近似为:
。其可以近似为:
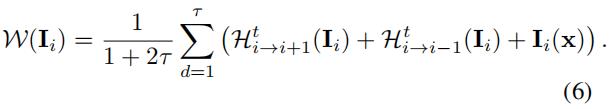
根据估计的光流和,如果我们将τ设为1,可以近似为:

相比于生成一个模糊的帧,我们更想根据估计光流 和
和 生成一个清晰的帧。因此,
生成一个清晰的帧。因此, 和
和 可以与
可以与 对齐。因此,我们可以使用以下公式来更新潜在帧:
对齐。因此,我们可以使用以下公式来更新潜在帧:

然而,直接使用公式8将会导致结果可能出现伪影,由于和
错位引起的。为了避免这个问题,并生成高质量的潜在帧,我们使用和作为指导帧,并开发了一个深度CNN模型来恢复潜在帧:
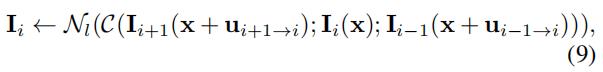
其中, 为concatenate操作,
为concatenate操作, 为恢复网络。我们使用双线性插值来计算warped frames。对于深度CNN模型,我们使用了一种基于[15]的编解码器体系结构。
为恢复网络。我们使用双线性插值来计算warped frames。对于深度CNN模型,我们使用了一种基于[15]的编解码器体系结构。
3.3.Temporal sharpness prior
如[14]所示,视频中的模糊是不规则的,因此存在一些不模糊的像素。根据传统的方法[14],我们探索这些清晰像素,以帮助视频去模糊。
如果在中的像素x是清晰的,那么这个像素值在和
应该接近。因此,我们将这个标准定义为:
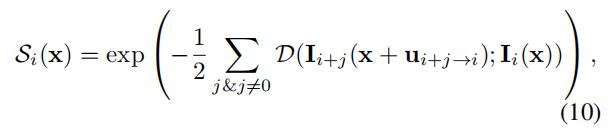
 被定义为:
被定义为: 。基于公式10,如果
。基于公式10,如果 的值接近1,那么像素x很可能是清晰的。因此我们可以使用来帮助深度神经网络区分像素是否清晰,从而帮助潜在帧的恢复。为了增加 的鲁棒性,我们将
的值接近1,那么像素x很可能是清晰的。因此我们可以使用来帮助深度神经网络区分像素是否清晰,从而帮助潜在帧的恢复。为了增加 的鲁棒性,我们将
定义为:

其中,ω(x)表示以像素x为中心的图像patch。利用temporal sharpness prior Si(x),我们对潜在帧恢复公式9进行了修改:

其中 。
。
3.4.Inference
由于该算法包含了optical flow estimation、latent frame estimation和temporal sharpness computation,因此我们以级联的方式训练该算法。
设 表示在迭代阶段t帧时的光流估计和潜在帧恢复网络的模型参数。给定2j+1个模糊帧,通过最小化代价函数来学习参数
表示在迭代阶段t帧时的光流估计和潜在帧恢复网络的模型参数。给定2j+1个模糊帧,通过最小化代价函数来学习参数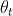 :
:
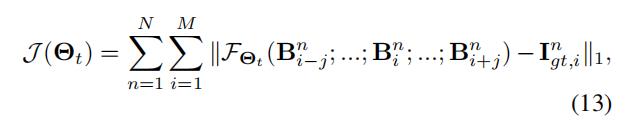
其中, 表示整个去模糊网络。算法1总结了级联训练方法的主要步骤。
表示整个去模糊网络。算法1总结了级联训练方法的主要步骤。

4.Experimental Results





5.Concluding Remarks
我们提出了一种简单而有效的CNN深度视频去模糊模型。所提出的CNN模型探索了在variational model-based的方法中使用的简单和完善的原则主要包括中间潜帧的光流估计和潜帧恢复。我们开发了一个temporal sharpness prior来帮助潜在图像恢复和一个有效的级联训练方法来训练所提出的CNN模型。通过端到端方式的训练,我们已经证明了所提出的CNN模型更紧凑和高效,并且在基准数据集和真实世界的视频上都优于最先进的方法。
6.Model Structure

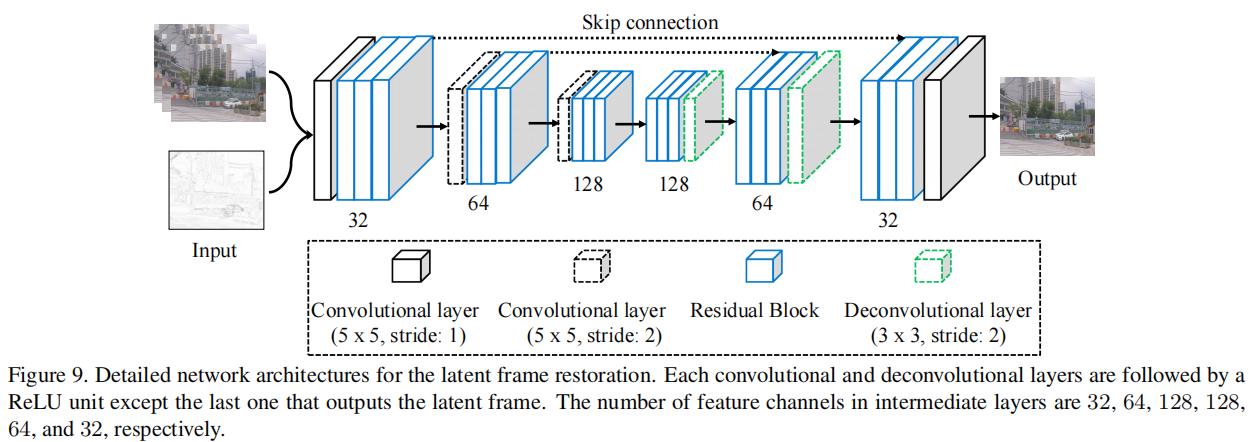
References
[1] Bar L, Berkels B, Rumpf M, et al. A variational framework for simultaneous motion estimation and restoration of motion-blurred video[C]//2007 IEEE 11th International Conference on Computer Vision. IEEE, 2007: 1-8.
[2] Dai S, Wu Y. Motion from blur[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2008: 1-8.
[3] Hyun Kim T, Mu Lee K. Generalized video deblurring for dynamic scenes[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5426-5434.
[4] Wulff J, Black M J. Modeling blurred video with layers[C]//European Conference on Computer Vision. Springer, Cham, 2014: 236-252.
[5] Su S, Delbracio M, Wang J, et al. Deep video deblurring for hand-held cameras[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1279-1288.
[6] Hyun Kim T, Mu Lee K, Scholkopf B, et al. Online video deblurring via dynamic temporal blending network[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 4038-4047.
[7] Zhang K, Luo W, Zhong Y, et al. Adversarial spatio-temporal learning for video deblurring[J]. IEEE Transactions on Image Processing, 2018, 28(1): 291-301.
[8] Kim T H, Sajjadi M S M, Hirsch M, et al. Spatio-temporal transformer network for video restoration[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 106-122.
[9] Chen H, Gu J, Gallo O, et al. Reblur2deblur: Deblurring videos via self-supervised learning[C]//2018 IEEE International Conference on Computational Photography (ICCP). IEEE, 2018: 1-9.
[10] Wang X, Chan K C K, Yu K, et al. Edvr: Video restoration with enhanced deformable convolutional networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2019: 0-0.
[11] Zhou S, Zhang J, Pan J, et al. Spatio-temporal filter adaptive network for video deblurring[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 2482-2491.
[12] Hyun Kim T, Mu Lee K. Generalized video deblurring for dynamic scenes[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5426-5434.
[13] Sun D, Yang X, Liu M Y, et al. Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8934-8943.
[14] Cho S, Wang J, Lee S. Video deblurring for hand-held cameras using patch-based synthesis[J]. ACM Transactions on Graphics (TOG), 2012, 31(4): 1-9.
[15] Tao X, Gao H, Shen X, et al. Scale-recurrent network for deep image deblurring[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8174-8182.
Deep Knowledge Tracing with Transformers论文阅读
- In book: Artificial Intelligence in Education (pp.252-256)
- 2020年6月
- 代码https://github.com/scott-pu-pennstate/dktt_light
- 论文地址(PDF) Deep Knowledge Tracing with Transformers (researchgate.net)
文章创新点:改进了transformer模型1)问题的结构和2)问题步骤之间经过的时间。问题结构的使用允许模型利用问题之间的关系。包含经过的时间为解决遗忘问题提供了机会。在公共数据集上,我们的方法在AUC方面比SAKT方法高出大约10%。
摘要
贝叶斯知识追踪(BKT)是智能教学系统中追踪学生技能获取的传统方法。近年来,深度学习方法的快速发展促使研究人员将递归神经网络(RNN)应用于智能教学和计算机支持的学习领域。因此,深度学习模型显示出优于BKT等传统模型的性能。然而,当应用于具有扩展模式的长序列时间序列数据时,神经网络的效率较低,而扩展模式是学习系统的典型模式。在这项工作中,我们提出了一个基于Transformer的模型来追踪学生的知识。我们修改了Transformer结构,以说明1)问题的结构和2)问题步骤之间经过的时间。问题结构的使用允许模型利用问题之间的关系。包含经过的时间为解决遗忘问题提供了机会。在频繁使用的公共数据集上,我们的方法在AUC方面比文献中最先进的方法高出大约10%。
模型
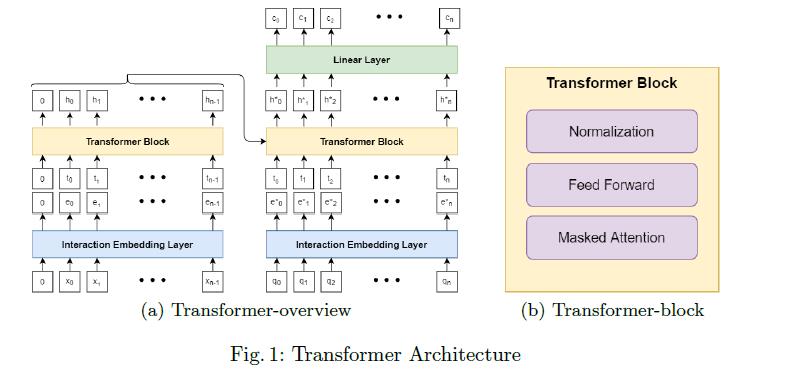
DKT专注于学习学生互动的表现形式。在Transformer模型中,交互嵌入层负责学习每个交互xi的静态表示。Transformer块负责学习每个交互的上下文相关表示。互动的背景,xi有两个部分:1)所有以前的互动 和2)它们各自的时间戳
和2)它们各自的时间戳
图1(a)显示了带有1层transformers模块的transformers模型的简化版本。Transformer遵循编码器-解码器结构(左边部分是编码器,右边部分是解码器),学生的交互序列 首先通过交互嵌入层嵌入为
首先通过交互嵌入层嵌入为 ,
,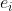 序列和交互时间序列ti被一堆Transformers联合处理,以学习隐藏的呈现序列
序列和交互时间序列ti被一堆Transformers联合处理,以学习隐藏的呈现序列 在解码器侧,来自编码器的hi序列、嵌入的问题序列
在解码器侧,来自编码器的hi序列、嵌入的问题序列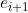 和问题时间序列由另一堆栈
和问题时间序列由另一堆栈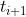 ,生成解码器隐藏表示的变换块: 。最终解码器输出通过线性层以生成预测的正确可能性序列,并与观察到的目标正确进行比较以计算损失值。
,生成解码器隐藏表示的变换块: 。最终解码器输出通过线性层以生成预测的正确可能性序列,并与观察到的目标正确进行比较以计算损失值。
3.2 交互嵌入:将交互和问题映射到向量
交互映射层将学生交互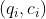 或问题
或问题 映射到其静态表示:高维向量。该层首先创建交互技能映射矩阵W和技能嵌入矩阵S,然后计算交互xi的嵌入,如下所示:
映射到其静态表示:高维向量。该层首先创建交互技能映射矩阵W和技能嵌入矩阵S,然后计算交互xi的嵌入,如下所示:
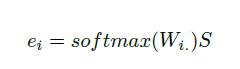
 是W的第I行,代表与xi互动的所有潜在技能相关的权重。softmax函数标准化这些权重。S的每一列都是潜在技能的向量表示。因此,互动xi的静态表现是所有潜在技能的加权总和。
是W的第I行,代表与xi互动的所有潜在技能相关的权重。softmax函数标准化这些权重。S的每一列都是潜在技能的向量表示。因此,互动xi的静态表现是所有潜在技能的加权总和。
Transformer模型的体系结构将学习权重的责任分配给W矩阵,将学习技能表示的责任分配给S矩阵。这种设计有两个好处。首先,它允许我们利用智能教学系统中常见的专家标记的交互技能结构。为了利用专家标记的问题项-技能映射,我们使用专家标记初始化映射矩阵W。例如,如果qi在数据中被标记为sj,我们会将(qi,0)和(sj,0)之间的映射值初始化为 ,其他技能为
,其他技能为 。平滑和温度是控制传递到softmax层的logits的平滑度的两个超参数。其次,它足够灵活,如果有一个以上的潜在技能与交互相关联,该层可以从数据中学习这种关联。
。平滑和温度是控制传递到softmax层的logits的平滑度的两个超参数。其次,它足够灵活,如果有一个以上的潜在技能与交互相关联,该层可以从数据中学习这种关联。
3.3 masked attention:学习情境化的交互嵌入

在等式(2)中,masked attention注意力层通过将静态表示ej与三个可训练矩阵:Q、K和V相乘来提取查询qj、键kj和值vj。键和查询可以被解释为与交互ej相关联的潜在技能,值是与ej相关联的潜在技能(或知识状态)的状态。
等式(3)计算分配给过去交互ei的注意力Aij。它有两个组成部分:1) qjki,即ej和ei之间的键值协议,可以解释为交互ej和ei之间潜在技能重叠的程度;2)调节注意力的时间间隙偏差。交互ej和ei之间的时间间隔权重。分母dk用于归一化注意力大小。详见附录。理论上,如果两个问题项在潜在技能上有很大的重叠,一个紧接着另一个,这两个交互之间的注意力就会很高。同时,当两种互动在潜在技能上几乎没有重叠或相距太远时,注意力权重值就会很低。
等式(4)将上下文化表示hj计算为过去值表示的加权和。权重与注意力权重成正比,由softmax函数归一化。请注意,由于任务是预测下一个问题cj+1的正确性,因此注意力值上强制有一个掩码,以便只有i ≤ j的Aij用于计算hj。换句话说,softmax(Akj) = 0,∀k > j。
4 实验
为了评估我们的Transformer方法的性能,我们在文献中经常使用的三个数据集上进行了5倍的学生验证交叉验证。表1列出了数据集的描述性统计数据。
、
ASSISTments 2017。该数据追踪了中学生和高中生对在线辅导系统的使用情况。它包括1,709名学生、942,816次互动、4,117个问题和102项标记技能。
STAT F2011。该数据跟踪学生在大学水平的工程静力学课程中的成绩。数据包含333名学生、189,620次互动、1,224个问题和81个标记的知识成分。我们遵循[16]使用的预处理策略,1)将问题名称和步骤名称连接成一个问题,2)只保留每个问题的最终尝试。
KDD。该数据是来自KDD 2010年教育数据挖掘挑战的挑战集A-代数I 2008-2009数据集。它最初包含3310名学生和942666个步骤。我们只保留有知识成分的步骤。
要批量运行学生序列,所有序列必须具有相同的长度maxlen。我们遵循了Pandey和Karypis[6]的策略: 于比maxlen短的序列,我们在左边添加了一个特殊的填充标记,2)对于比maxlen长的序列,我们将序列折叠成长度为maxlen的片段,并用左边的填充标记填充剩余部分。像其他深度学习模型一样,Transformer的性能取决于最优超参数的选择。表2展示了我们实验中调整的所有超参数。
 结果
结果
表3总结了我们的发现,并将其与文献中最先进的Transformer结果以及贝叶斯知识追踪(BKT)模型进行了比较。我们报告的主要指标是AUC,因为它是文献中经常使用的标准,但我们也报告了Transformer模型和BKT模型的均方根误差(RMSE)和精度。
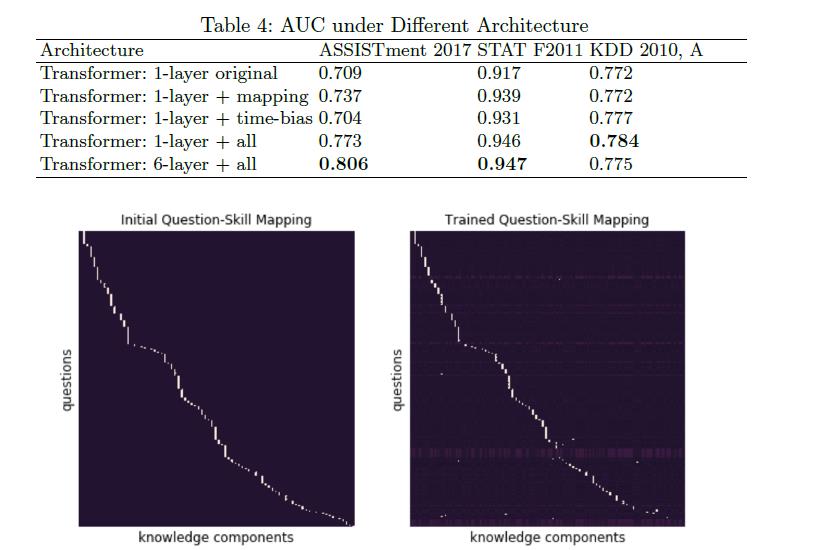
修改后的Transformer模型在所有指标上都优于BKT,而且有很大的优势。最值得注意的是,在ASSISTments 2017和STAT F2011数据集上,它的性能分别比文献中最先进的Transformer模型高出9.81%和11.02%。显著的增益不是由于原始transformers模型的结构。Pandey和Karypis [6]的自我关注模型大致相当于一个具有学习位置编码的1层Transformer。尽管他们的工作在多个基准数据集上产生了最先进的性能,但他们在ASSISTments 2017和STAT F2011上报告的AUC分数比我们改进的Transformer差了约10%。为了进一步说明这一点,我们在有/没有修改组件的原始transformers上重复实验,如表4所示.最初的transformers未能在2017年达到国家或最先进的援助结果.然而,通过在其结构中加入交互技能映射和时间偏差,该模型获得了明显的性能提升。
图2比较了初始专家标记的交互技能映射和学习项目技能映射。在这里,我们展示了STAT F2011数据集的交互-技能映射,其中我们只包括用技能标记的行。大约85.5 %的交互在训练后保持其初始映射为主导映射,而剩余的14.5%发生了变化。这表明专家标记和灵活的映射对于模型的性能都很重要。
图3显示了在STAT F2011数据上训练的模型中的注意力权重。我们从两个专家标记的技能中采样了64个交互作用的伪序列:a)用力和力偶代替一般载荷,b)找到线性分布的净力位置。查询交互,x63,属于前潜伏技能(a)。
在图中,每一列代表一对交互之间的注意力。最左边的一列代表x0和x63之间的交互关注。最右边的一栏代表x62和x63之间的交互关注。第一行表示综合注意力。第二行关注时间偏差。第三行可视化了查询键协议。正如我们预期的那样,时间偏差(一般来说)给较近的交互(最右边的列)分配的值高于给较远的交互(最左边的列)分配的值。此外,对于类似的技能交互,查询键协议将具有更高的值(标有A的列)。此外,时间偏差会调整注意力,因此距离较远的相同技能事件(左侧的A)被分配的注意力低于距离较近的相同技能事件(右侧的A)
结论
在本文中,我们提出了一种基于Transformer的学生学习建模方法。我们修改了最初的Transformer架构,以便它知道交互的结构以及它们之间的时间。我们通过使用真实数据集将其与已知替代方案进行比较来验证该模型。结果表明,改进的transformers优于文献中发现的最先进的transformers模型的结果约10%。
对于未来的工作,我们打算探索如何有效地将更多的特性信息合并到Transformer架构中。例如,张和他的同事[16]表明,增加工程特性可以提高车型的性能。此外,我们的交互技能映射不能利用关于潜在技能的复杂结构信息,例如,当潜在技能来自诸如技能分类的层次结构时。我们打算继续探索如何将这种结构灵活地表示为Transformer体系结构的一部分。

以上是关于视频去模糊论文阅读-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior的主要内容,如果未能解决你的问题,请参考以下文章