论文精读A Survey on Deep Learning for Named Entity Recognition
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文精读A Survey on Deep Learning for Named Entity Recognition相关的知识,希望对你有一定的参考价值。
A Survey on Deep Learning for Named Entity Recognition
- 前言
- Abstract
- 1. INTRODUCTION
- 2. BACKGROUND
- 3. DEEP LEARNING TECHNIQUES FOR NER
- 4. APPLIED DEEP LEARNING FOR NER
- 5. CHALLENGES AND FUTURE DIRECTIONS
- 6. CONCLUSION
- References
前言
一篇来自2022年TKDE的有关NER综述的文章,也算是我接触NER以来的第二篇文章,其中第一篇是有关图神经网络在NER中的应用,由于没有基础知识,踩了许多坑,在汇报的时候很多概念也没能阐述清楚,这次通过阅读综述的方式,来对NER领域进行一个全面完整的认识,希望能在这篇CCF A的期刊中得到收获。
Abstract
命名实体识别(NER)的任务是从属于预定义语义类型的文本中识别出实体类型(mentions of rigid designators)。
这里的原文如下:
Named entity recognition (NER) is the task to identify mentions of rigid designators from text belonging to predefined semantic types such as person, location, organization etc.
读起来十分拗口,但确实很重要,用白话来解释就是,对于一个给定语义定义信息的文本(不是乱序无意义的文本信息),识别出其中的实体类型,如人物、位置、组织等。
意义: 总是作为预训练任务为下游fine-tuning引入先验知识。
文章结构:
- 对现有的工作系统分类:输入的分布式表示(Embedding)、文本编码、标签解码。
- 调查当前最具代表性的NER深度学习方法。
- NER当前的挑战及未来展望。
1. INTRODUCTION
NE的定义: A NE is a proper noun, serving as a name for something or someone
Rigid designator: 包括专有名称和自然术语,如生物物种和物质。
NE分类:
- Generic NEs(通用实体命名)
- Domain-specific EEs(特定领域实体命名)
Techniques in NER:
- 基于规则的方法
- 无监督学习方法
- 基于特征的监督学习方法
- 基于深度学习的方法
Motivation:
- DL在NER领域应用大获成功。
- 当前NER领域综述过少。
Contribution:
3. 以表格的形式整合NER语料库和来自工业界或学术界现成的NER系统。
4. 全面调查了DL在NER中的应用以及当前代表性方法。
5. 基于DL的NER新的分类方法:输入分布式化表示、上下文编码、标签解码。
2. BACKGROUND
2.1 What is NER?
NER is the process of locating and classifying named entities in text into predefined entity categories(将文本中的命名实体定位归类到预定义的实体类别中)。

具体来说,给定tokens:
s
=
<
w
1
,
w
2
,
.
.
.
,
w
N
>
s=<w_1,w_2,...,w_N>
s=<w1,w2,...,wN>
Output a list of tuples
<
I
s
,
I
e
,
t
>
<I_s, I_e, t>
<Is,Ie,t>,每个tuple都是一个s中的命名实体。
I
s
I_s
Is和
I
e
I_e
Ie分别是命名实体的起点和终点index,
t
t
t是实体类别。
NER任务
- 粗粒度NER(一个mention一个type)
- 细粒度NER(一个mention可能多个type)
为什么NER对下游任务重要,以搜索任务为例,71%的查询都是带有实体的,所以语义搜索可以帮助搜索引擎更好理解用户的意图,为用户提供更好的搜索结果,同时还可以进一步增强用户体验,如查询推荐,查询补齐,实体卡片。
2.2 NER Resources: Datasets and Tools
Datasets
高质量的注释对模型学习和评估都至关重要。

Tags表示实体类型的数量。
两个最近常用的数据集:
- CoNLL03:包含英语和德语的路透社新闻注释,四种实体类别:人物,地点,组织,其它实体
- OntoNotes:目标是注释大型语料库,具有结构信息(语法和谓语参数结构)和浅层语义。18个实体类别。
Tools

2.3 NER Evaluation Metrics
NER系统通过模型的输出和标注进行比较得到评估结果。比较的方式有:
- 精确匹配
- 宽松匹配
2.3.1 Exact-Match Evaluation
NER任务涉及识别实体边界和实体类型。精确匹配要求边界和类型都和事实相匹配时才认为命名实被正确识别。


- TP:被NER识别并且与事实匹配。
- FP:被NER识别但是与事实不匹配。
- FN:属于NE但是未被NER识别。
- Precision衡量NER系统呈现真实实体的能力。
- Recall衡量NER系统识别语料库中所有实体的能力。
大部分NER系统涉及多种实体类型,因此经常要评估所有类型的性能。
常用的方法:
- macro-averaged F-score:计算每个类别的F-score进行平均。
- micro-averaged F-score:依据每个类别的权重对F-score进行平均。
后者在语料库large classes场景下,容易受到识别质量的严重影响。
2.3.2 Relaxed-Match Evaluation
MUC-6定义了一种宽松的匹配评估:
- 实体类别识别正确,其边界与实际边界有重叠。
- 无论实体的类型分配如何,都会计入正确的边界。
ACE定义了复杂的评估procedure:
- 考虑NE子类型,解决部分匹配和错误实体类型。
- 参数固定才能评估,错误分析不直观,未被广泛使用。
2.4 Traditional Approaches to NER
传统主流NER方法:
- 基于规则
- 基于无监督学习
- 基于特征的监督学习
2.4.1 Rule-Based Approaches
基于规则的NER系统依赖于人工制定的规则。可以根据领域特定词典和语义、句法规则设计。
优点: 词典详尽时,系统运行良好。
缺点: 词典不完整,不具备迁移性。
2.4.2 Unsupervised Learning Approaches
典型的无监督方法是聚类。基于聚类的NER系统根据上下文相似性从聚类组中提取NE。
核心思想: 在大型语料库上计算的词汇资源、词汇模式和统计数据可以推断NE。
优点:没有监督标签。
缺点:模型性能不高,只能依据浅层的语义信息进行聚类。
2.4.3 Feature-Based Supervised Learning Approaches
应用监督学习方法,NER被用于token级别多分类或序列标记任务。
过程:给定标签数据,特殊设计的特征用于表示所有的样本。利用机器学习算法来学习模型来挖掘数据中的隐藏的相似模式。
特征工程在监督学习中至关重要。
- 词级特征:大小写,词法和词性标记。
- 词表特征:维基百科,DBpedia知识。
- 文档语料库特征:局部语法和多次出现。
经典模型:隐马尔可夫模型,决策树,SVM(预测时不考虑neighbor),条件随机场(是一种判别式概率模型,考虑上下文信息,广泛应用NER)。
既然条件随机场能利用上下文信息,为什么还要用DL?
CRF是线性链,只能挖掘到表层的信息,而DL的非线性特性可以挖掘深层次复杂特征。
3. DEEP LEARNING TECHNIQUES FOR NER
相比于传统机器学习方法,基于DL的NER有利于自动发现隐藏特征。
3.1 Why Deep Learning for NER?
Strength:
- NER受益于输入到输出的非线性变换。
- 节省了设计的工作量。
- 基于DL的 NER 模型可以通过梯度下降在端到端范式(输入->输出)中进行训练,可以设计复杂的模型。
Why a new taxonomy?
现有的分类基于字符级、词级编码和标签解码。词级编码器的概念是不准确的,因为词级表征(和字符级表征)用于原始特征和捕捉标签解码的上下文依赖。

- 输入的分布式表示,结合预训练词向量,字符向量,词性标签,词典。
- 上下文编码通过CNN、RNN和语言模型捕获上下文的依赖关系。
- 标签解码器预测输入序列中tokens的标签(B-I-E-S-O)。
3.2 Distributed Representations for Input
对单词的直接表示的一个方法是one-hot编码,两个词表示完全不同且正交。分布式表示可以自动从文本中学习,捕捉单词语义和句法的属性,这些信息在Input阶段并不显式存在。
3.2.1 Word-Level Representation
通常采用无监督算法进行预训练
- CBOW(周围词预测中心词)
- Skip-gram(中心词预测周围词)
来得到词级表示,这为下游任务引入了先验知识。常用的词向量:
- Word2Vec
- GolVe
- fastText
3.2.2 Character-Level Representation
- 有助于利用前缀和后缀等挖掘词素级信息。
- 可以自然处理不在词表上的内容,可以推断未见词的表示,共享词素规则信息。
词素是构成词的最小、意义上不能再分的单位,如“日”、“月”包含一个词素,“汽车”、“电器”包含两个词素。
两种典型架构:

- CNN-based model
- RNN-based model:LSTM、GRU
过程: 字符序列——>CNN or RNN——>character-level representations
用法:
- 直接作为input的输入表示。
- 和word Embedding拼接在一起。
- 使用门控机制将字符表示和word Embedding结合。
 此外,使用字符级的RNN语言模型可以为具体语境的上下文生成上下文Embedding,也就是说不同语境下的同一个词根具有不同的Embedding。
此外,使用字符级的RNN语言模型可以为具体语境的上下文生成上下文Embedding,也就是说不同语境下的同一个词根具有不同的Embedding。
3.2.3 Hybrid Representation
这是一种将基于DL的表示和基于特征的表示混合的方法,附加的基于特征的信息包括:
- 词典、POS
- 词汇相似性
- 语言依赖性
- 视觉特征:word shape,包括大小写,首字母大写,包含大写字母等。
添加额外信息优势是提高模型性能,代价是可能会损害模型的通用性。
其中基于transformer的双向编码预训练语言模型BERT也被归类到输入混合表示类型中,它的输入部分由token Embedding、segment Embedding、position Embedding组成。
3.3 Context Encoder Architectures
广泛使用的上下文编码器框架:
- CNN
- RNN
- 递归神经网络
- Transformer
3.3.1 Convolutional Neural Networks
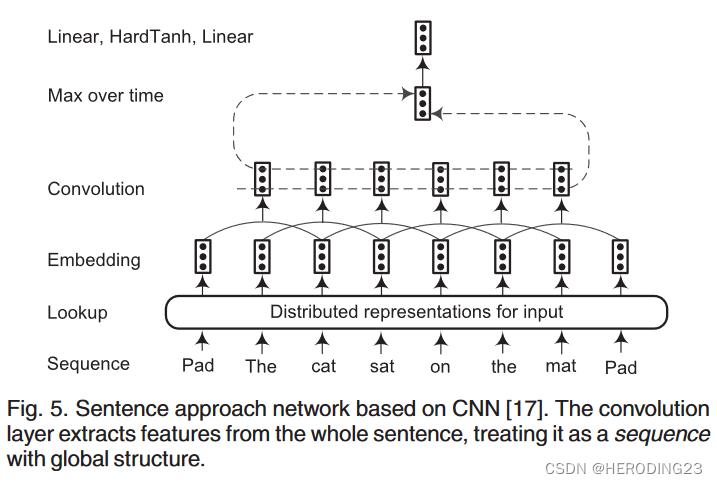
以一个sentence approach network的方法作为例子:
- 整个序列在input表示阶段获得N维Embedding;
- 将序列的Embedding输入到卷积层中抽取每个单词周围的局部特征(卷积层输出与句子长度有关);
- 通过结合局部特征向量构建全局特征向量(这里向量维度固定);
- 一般通过最大池化层进行池化操作(这里认为大部分单词对当前单词无影响);
- 最后将抽取的全局特征喂入标签解码器预测输入序列中单词的标签。

一个有趣的研究是Strubell在Fast and accurate entity recognition with iterated dilated convolutions中提出的迭代膨胀卷积神经网络,相对于传统的CNN有更好的处理大的上下文和结构预测的能力。此外ID-CNNs允许固定深度的卷积层并行运行,比Bi-LSTM-CRF在相同的accuracy下快了14-20倍。
3.3.2 Recurrent Neural Networks

递归神经网络是非线性自适应模型,通过按照拓扑顺序遍历给定结构来学习深度结构化信息。具有树状结构。
为什么要使用递归神经网络?
典型的顺序标记法很少考虑句子的短语结构。
双向递归:
- 自下而上递归计算每个节点的子树的语义组成。
- 自上而下递归将包含子树的语言结构传播到该节点。
PS:虽然从理论上看递归神经网络很有道理,但是从实验来看结果并不好。
3.3.4 Neural Language Models语言模式是描述序列生成的一系列模型。
给定token序列
(
t
1
,
t
2
,
.
.
.
,
t
N
)
(t_1,t_2,...,t_N)
(t1,t2,...,tN),前向语言模型通过给定历史记录
(
t
1
,
.
.
.
,
t
k
−
1
)
(t_1,...,t_k-1)
(t1,...,tk−1)给当前token
t
k
t_k
tk建模计算序列的概率。
p
(
t
1
,
t
2
,
.
.
.
,
t
N
)
=
∏
k
=
1
N
p
(
t
k
∣
t
1
,
t
2
,
.
.
.
,
t
k
−
1
)
p(t_1,t_2,...,t_N)=\\prod^N_k=1p(t_k|t_1,t_2,...,t_k-1)
p(t1,t2,...,tN)=k=1∏Np(tk∣t1,t2,...,tk−1)
反向语言模型与前向语言模型类似,除了以相反的顺序遍历序列,根据其未来上下文预测先前的token:
p
(
t
1
,
t
2
,
.
.
.
,
t
N
)
=
∏
k
=
1
N
p
(
t
k
∣
t
k
+
1
,
t
t
+
2
,
.
.
.
,
t
N
)
p(t_1,t_2,...,t_N)=\\prod^N_k=1p(t_k|t_k+1,t_t+2,...,t_N)
p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,tt+2,...,tN)
上述过程实际上就是RNN的双向过程,将前向后向的上下文表示组合起来作为token
t
k
t_k
tk在语言模型的最终Embedding。
多目标语言模型
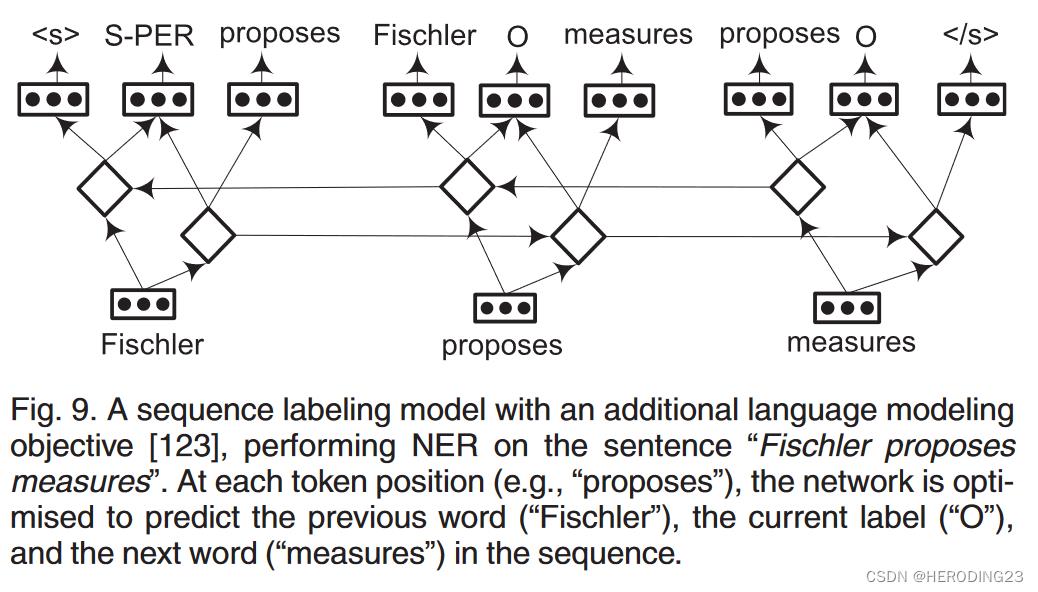 Rei等人提出的多任务学习框架,任务是预测[previous token, the current tag, the next token],这种添加学习任务的模型鼓励系统学习更丰富的特征表示,然后将其重新用于序列标记。
Rei等人提出的多任务学习框架,任务是预测[previous token, the current tag, the next token],这种添加学习任务的模型鼓励系统学习更丰富的特征表示,然后将其重新用于序列标记。
LMLSTM-CRF

两个模型: 语言模型和序列标注模型,分别作序列预测和词性标注任务。两个模型共享字符层信息。
过程: 字符级Embedding、预训练词级Embedding、语言模型Embedding拼接起来喂入词级LSTM中。
多任务学习是引导语言模型学习特定任务知识的有效手段。
3.3.5 Deep Transformer
Transformer采用了堆叠的自注意力机制、全连接层为编码器和解码器构造基本块。

GPT
Transformer的decoder结构,基于mask-attention,每个输入只能看到前面输入的词。two-stage训练过程。
- 使用Transformer对无标签数据建模得到初始的参数(无监督预训练)。
- 使用有监督的目标对这些参数进行微调,适应于目标任务,从而对预训练的模型产生最小的变化。
BERT
Transformer的encoder结构,和GPT不同,是双向编码器,每层输入都能够学习到整个输入的信息。
以上使用Transformer进行预训练的语言模型正成为NER的新范式。
优势:
- Embedding基于上下文,可以代替传统的Embedding如Word2vec、GloVe。
- 语言模型Embeddings只用加一个输出层就能够做许多微调任务,包括NER。
3.4 Tag Decoder Architectures
标签解码以上下文相关的表示作为输入,并生成与输入序列相对应的标签序列。

四种架构:
- MLP+Softmax
- CRF
- RNN
- Pointer Network
3.4.1 Multi-Layer Perceptron + Softmax
MLP+Softmax将序列标注任务转化为多分类任务。每个词语都是独立预测,不考虑其邻居。
3.4.2 Conditional Random Fields
CRF广泛应用于基于特征的监督学习方法,主流的NER模型中,CRF是标签解码器最常见的选择,并且在CoNLL03和OntoNotes5.0两个数据集上达到了SOTA。



Why CRF?
由于CRF是机器学习上的概念,所以这里必须要对其进行一下表述,便于理解encoder层的输出在CRF中具体经过了怎样的映射得到了最终的标记结果。这里以BiLSTM-CRF模型为例进行阐述。
- 首先将input阶段得到的Embedding输入到BiLSTM中,输出句子x中的单词的预测标签。
- 然后将BiLSTM层预测的分数输入到CRF层中,在CRF层选择得分最高的标签序列最为最佳答案。
那么就有问题了,既然BiLSTM已经输出每个标签的得分了,就按照得分最大的选择呗。那么来看第二张图,显然这次的输出结果是无效的。这就是CRF层的作用,从训练数据中学到约束确保输出是有效的。
这样的约束条件包括:
- 句子中的第一个单词标签应该以B或O开头,不可能是I。
- OI是无效的,实体的第一个标签是B。
How to work?
两种类型得分:
- Emission得分:BiLSTM层输出得分, x i , j x_i,j xi,j表示word i预测为label jEmission得分。
- Transition得分:存储所有标签之间的得分,如图三。
Transition矩阵是学习得到的,初始时随机生成,通过CRF损失函数学习,CRF损失函数由真实路径得分和所有可能路径的总得分组成。在所有可能的路径中,真实路径的得分应该是最高的。
缺点: CRF不能完全利用段级信息(一般人工切分),因为段的内部属性不能用词级表示完全编码。
解决方法: 采用段而不是词作为特征提取的最基本单位,词级标签用于提取segment分数,同时利用词级信息和段级信息来计算segment的得分。
Segment-level又是一个新的概念,Segment-Level Sequence Modeling using Gated Recursive Semi-Markov Conditional Random Fields将其理解为连续的word组成的集合,也就是一句话或者短语。那么如何得到segment呢,可以不同的句子构成segment的集合,但是不同的句子长度可能不同,要加padding,也可以固定切分,但是会损失segment中的信息。
3.4.3 Recurrent Neural Networks
优势:
- RNN标签解码优于CRF。
- 实体类型较多时训练速度更快。
当前隐向量=当前输入+前一个输出+隐向量
缺点: 贪婪编码,当前解码只有在上一个解码完成时才能开始,不能并行计算。
3.4.4 Pointer Networks
指针网络应用RNN模型学习输出序列的条件概率。它通过使用softmax的概率分布作为指针来表示可变长度字典。
它是先将序列分成块(即实体范围)作为NER任务,然后再进行分类,做的是Sequence tags。通常是Seq2seq架构。
3.5 Summary of DL-Based NER

根据表三,获得如下的信息:
- BiLSTM-CRF架构是基于DL的NER任务中最常用的架构
- 基于填词任务的双向Transformer模型在CoNLL03达到了SOTA,基于BERT的模型在OntoNotes5.0达到了SOTA。
性能比较:
- NER系统的成功很大程度依赖于其输入表示。整合或微调预训练语言模型的Embedding对模型性能有显著提升。
- NER系统在干净的数据集上表现很好(CoNLL03、OntoNotes5.0),但是在有噪声的数据集中面临挑战(W-NUT17)。
架构比较(从input、编码器、解码器):
- 引入外部的先验知识可以提高模型性能,但是获取知识是劳动密集型或者高计算代价,不利于端到端的学习,对模型的泛化能力有损害。
- 在大规模语料上预训练的Transformer编码比LSTM更高效,反之则不然。当序列长度比representation的维度小时,Transformer的速度会比递归神经网络更快。self-attention复杂度O( n2×d ) 和recurrent O( n×d2 )。
- RNN和指针网络无法并行化,CRF是标签解码器最常用选择。但是实体类型数目多时计算开销大并且当使用如BERT和ELMo等语言模型时,它的性能不如softmax。
- 对于用户来说,使用何种架构是基于数据和特定领域任务的。数据量丰富,用RNN重头训练+微调;数据稀疏,采用现成的预训练好的语言模型,如果特定领域,利用特定领域数据微调语言模型。
- 此外还有其他的语言任务以及跨语言任务。
4. APPLIED DEEP LEARNING FOR NER
本节调查了最近应用在NER中的深度学习技术。
4.1 Deep Multi-Task Learning for NER
迁移学习旨在利用从源域中学到的知识在目标域上执行机器学习任务。
- 传统的迁移学习通过引导算法。
- 现在已经有针对低资源、跨领域的NER任务的方法出现。
Why And How?
- 相关的命名实体通常共享词汇和上下文信息。
- 在迁移学习的设置中,不同的模型通常在源任务和目标任务之间共享模型参数的不同部分。
- 迁移学习非常适合将源域的知识引入到低资源场景目标域中,可以达到很好效果。
以Transfer learning for sequence tagging with hierarchical recurrent networks提出的方法为例,研究步骤如下:
- 不同层表示的可转移性。
- 提出三种不同的模型共享架构:跨领域、跨语言、跨应用。
- 如果两个任务有可映射的标签集,则有一个共享的 CRF 层,否则,每个任务学习一个单独的 CRF 层。
- 实验结果表明,在低资源条件下,各种数据集都有显着改进。
4.3 Deep Active Learning for NER

主动学习背后的关键思想是,如果允许机器学习算法选择从中学习的数据,那么它可以用更少的训练数据表现得更好。所以主动学习可以降低数据标注的成本。
- 传统的主动学习代价高昂。每轮训练后,都需要新注释样本对模型进行再训练。
- 现有方法将新样本和原始样本混合,在小数量epoch更新网络权重。
- 99%的效果在24.9%的英文数据集上和30.1%的中文数据集上。
4.4 Deep Reinforcement Learning for NER
强化学习 (RL) 是受行为主义心理学启发的机器学习的一个分支,它关注软件代理如何在环境中采取行动以最大
以上是关于论文精读A Survey on Deep Learning for Named Entity Recognition的主要内容,如果未能解决你的问题,请参考以下文章