视频异常检测综述-论文阅读Deep Video Anomaly Detection: Opportunities and Challenges
Posted 不喝可乐不快乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频异常检测综述-论文阅读Deep Video Anomaly Detection: Opportunities and Challenges相关的知识,希望对你有一定的参考价值。
来源:
Ren, Jing, et al. “Deep Video Anomaly Detection: Opportunities and Challenges.” 2021 International Conference on Data Mining Workshops (ICDMW), Dec. 2021. Crossref, https://doi.org/10.1109/icdmw53433.2021.00125.
文章连接:https://arxiv.org/abs/2110.05086
1.摘要
异常检测在各种研究环境中是一项热门而重要的任务,已经研究了几十年。为了确保人们的生命和财产安全,视频监控已广泛部署在各种公共场所,如十字路口、电梯、医院、银行,甚至在私人住宅中。深度学习在声学、图像和自然语言处理等多个领域都显示了其能力。然而,设计智能视频异常检测系统并非易事,因为在不同的应用场景中,异常之间存在显著差异。如果这种智能系统能够在我们的日常生活中实现,那么它将具有许多优势,例如在很大程度上节省人力资源,减轻政府的财政负担,以及及时准确地识别异常行为。
最近,出现了许多关于扩展深度学习模型以解决异常检测问题的研究,从而在深度视频异常检测技术方面取得了有益的进展。
本文从一个新的角度全面回顾了基于深度学习的视频异常检测方法。具体来说,我们分别总结了深度学习模型在视频异常检测任务中的机遇和挑战。我们提出了智能视频异常检测系统在各个应用领域的几个潜在的未来研究方向。此外,我们总结了当前视频异常检测深度学习方法的特点和技术问题。
2.INTRODUCTION
随着监控摄像机部署成本的降低,视频监控的应用被广泛扩展到不同场景。在过去几十年中,深度学习取得了巨大的成功,并在许多以前被认为在计算上无法实现的任务中表现出了优异的性能,例如人脸匹配[2]、推荐系统[3]和异常检测[4]。相应地,越来越多的人致力于基于深度学习模型的视频异常检测。
智能视频异常检测系统能够检测明显偏离正常的异常行为或实体,例如在视频监控的先验知识有限的情况下识别多个移动物体,或检测特定事件,例如打架、踩踏、交通事故和流浪。视频异常通常是上下文的,并根据真实场景定义。例如,在超市或演唱会中观察人群聚集是正常的,而当需要社会距离来阻止病毒传播时,观察人群聚集是异常的。在大多数视频异常检测算法中,大多数算法可以在时间和空间上定位异常。具体来说,检测过程集中于识别所有视频中包含异常的视频片段,而定位致力于确定哪一帧是异常的,并解释该帧的哪一部分是异常的。最近的相关研究可以通过提供端到端解决方案的基于深度学习的模型来处理这两个问题。
视频监控中的异常检测仍然面临一系列挑战:
- 模糊性:异常检测被广泛认为是检测在特定情况下预期不会出现的事件的过程。然而,在现实世界中,正常和异常之间的边界没有明确划分。例如,一些正常样本也会表现出异常事件所具有的奇怪特征,这阻碍了模型的检测精度。
- 依赖性:到目前为止,尽管在许多文献中都引入了对异常的统一定义。另一方面,所有这些差异都不能直接应用于特定的异常检测任务中。即使是同一事件也可能具有不同的特征,并且在不同的背景下也有很大差异。异常的上下文依赖性使检测模型无法适应。
- 稀疏性和多样性:与一般分类任务不同,在实际异常检测数据集中,正样本(即异常)远小于负样本。这种数据不平衡的特性使得监督模型难以训练。此外,现实世界中的异常行为多种多样,无法完全说明,有时甚至可能尚未发生。因此,在一个模型中考虑所有可能的异常类型是不切实际的。
- 隐私问题:在检测非视频数据集中的异常时,用户的私人信息(例如姓名)可以被随机泛化码所取代,这对最终的实验结果没有影响。而在视频监控数据中,尤其是包括面部和行为信息,如果数据是开源的,则会侵犯个人隐私。这种隐私特性导致缺少开源数据集。
- 噪音:随着视频监控的广泛覆盖,为了提高安全性,人们部署了摄像机。摄像机经常出现在电梯、十字路口、商场、餐馆甚至一些私人住宅中。虽然现有成像设备很容易支持获取视频监控数据,但手动注释这些数据是一个耗时的过程,并且容易出错。数据的噪声最终无疑会影响模型的准确性。
A. Relevant Surveys
为了应对上述挑战,人们设计了各种算法,并取得了显著的实验结果。已有相关调查介绍了视频异常检测模型。
- Kiran等人[10]回顾了无监督和半监督视频异常检测模型。
- Mabrouk和Zagrouba[11]详细介绍了智能视频异常检测系统内的过程,包括特征提取和描述。
- Pawar和Attar[12]分析了基于视频的异常活动检测的深度学习技术。姚和胡[13]介绍了基于传统和深度学习的视频暴力检测方法。
- [14]和[15]对基于深度学习的视频异常检测模型进行了全面调查,分类差异较小,而[14]还有一部分评估了模型的性能。
- 苏等人[16]总结了现有视频序列中暴力检测的最新方法。
- Roshan等人[17]回顾了暴力检测的最新趋势,并对不同的最先进的浅层和深层模型进行了比较研究。
- Ramzan等人[18]回顾了各种最先进的暴力检测技术,这些技术不仅限于深度学习模型。
- 在[19]中,作者对基于深度学习的图像和视频数据异常检测方法进行了深入分析。此外,还讨论了当前面临的挑战和未来的研究方向。
我们的工作在两个方面与之前的研究不同。一方面,本调查研究了视频异常检测系统可以应用的各种应用,这些应用不限于固定领域。另一方面,我们系统地总结了不同应用中的潜在机会,以及目前算法中仍然存在的挑战,而不是像其他调查那样比较算法背后的机制。
B. Contributions
- 对深度学习方法在视频异常检测方面的机遇和挑战进行了前瞻性总结
- 提出了智能视频异常检测系统在各个应用领域的一系列潜在研究和发展方向
- 对视频异常检测深度学习方法中的主要技术挑战进行了全面分析,从而为进一步改进模型提供了见解
3. OPPORTUNITIES
大多数现有研究致力于检测交通视频监控中的异常,而视频异常检测任务广泛存在于各种现实场景中。在本节中,我们不仅介绍了智能交通中的深度视频异常检测,还概述了其他领域的一些潜在机会,即数字教育、智能家居、公共卫生和数字孪生。
A. Intelligent Transportation
交通运输是人类社会生产、生活和经济发展的重要组成部分。当前的交通系统为人们提供了快速、舒适和安全的交通服务。然而,快速增长的人口对交通的日益增长的需求直接导致了机动车数量的爆炸性增长。因此,交通拥堵、交通事故频发等问题随之而来。为此,智能交通系统(ITS)应运而生,实践证明,智能交通系统是解决当前经济发展引起的交通问题的理想方案。
众所周知,ITS是其他视频异常检测应用中最热门的研究方向,在检测结果方面也取得了显著的改进。道路交通场景中的异常检测任务通常很广泛,重点是车辆、行人、环境等实体及其相互作用。考虑到交通监控系统的检测精度受天气和交通状况等多种因素的影响,人们致力于研究智能交通系统中检测结果的鲁棒性。
随着深度学习和无线通信技术的最近发展,开发了许多创新的交通监控系统。Li等人[30]旨在以无监督的方式检测车辆异常情况(如交通事故)。检测框架是使用Faster R-CNN[31]构建的,其采用了SENet[32]作为主干特征提取器。Aboah[33]提出了一种基于视觉的交通异常检测系统。异常检测过程由三个主要部分组成:用于提取背景特征的背景估计器、用于过滤虚假异常候选的道路掩码提取器以及用于确认和最终检测结果的决策树。尽管不断开发新的基于深度学习的模型来提高不同环境下的视频异常检测精度,但在未来的工作中仍有许多有待研究的开放机会。例如,学习算法和系统的实际部署之间仍然存在巨大差距。此外,应提高自动驾驶模拟环境的真实性,以确保模型在不稳定交通情况下的鲁棒性。
B. Online Education
由于过去十年信息和通信技术的发展,传统的离线教学和学习过程正逐渐转向在线平台。2019冠状病毒疾病的爆发加速了这一过程。由于这种流行病,在未来一段时间内,在线教育将成为知识传递的主要方式。同时,在线考试也随着时间的需要而普及。有效检测作弊行为和远程在线考试是确保考生公平的重要前提。然而,传统的作弊检测方法可能不再能够完全成功地防止考试期间的作弊。有必要设计一个人工智能系统来自动检测考试中的作弊行为。
实际上,已经开发了一系列技术并将其应用于智能监护系统,例如视线跟踪、语音检测和识别检查期间不允许存在的任何实体。这些技术在节省人力的同时,带来了公平、客观的检查监督。Atoum等人[35]提出了一种OEP系统,通过使用wearcam和网络摄像头,自动、连续地检测在线考试期间的作弊行为。尽管wearcam可以提供更广阔的视野,但在家为每个学生配备wearcam仍然不现实。Bawarith等人[36]在电子考试管理系统中提出了一种在线保护器,实现了指纹认证和眼动跟踪。此外,还可以检测到离开屏幕的学生。张和李[37]提出了一种深度学习系统,即DenseLSTM,作为行为检测代理。该方法可以提取更好的特征表示并增强网络的特征激活,这对于预测潜在的电子欺骗行为是有效的。智能监考系统的流程图如下图所示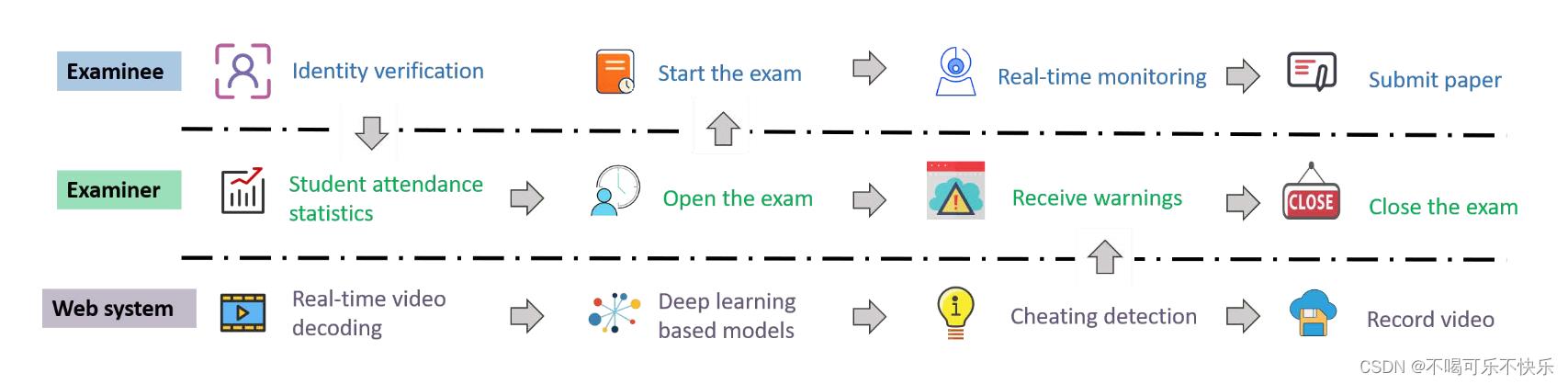
本质上,教育视频监控系统是学生学习行为的完整记录。这种视频数据比传统形式的教育数据存储保留了更多细节。例如,对于大多数教育利益相关者,包括研究人员,课程分数或学生的平均成绩(GPA)通常用于评估该学生的知识掌握情况。这种方法带来了便利,同时丢失了太多信息。随着计算能力的提高,我们能够快速处理大量数据。通过视频记录学习过程无疑为分析教学提供了很大帮助。学习过程的视频记录无疑保留了学生的整个学习过程以及考试过程。除了作弊检测之外,这还为所有与教育相关的异常分析提供了数据安全,包括课程失败分析、心理问题等
C. Smart Home
为了确保家里的安全,许多人在家里安装了视频监控系统。视频监控是家庭自动化系统的一小部分,被认为是全面的安全保障[38]。人们可以使用手机和电脑观看视频,随时随地掌握实时的家庭情况。由于一直盯着屏幕看会浪费时间和精力,因此自动识别异常行为并立即发送报警信号无疑是必要的。
Yhaya等人[40]提出了一种用于人类活动中异常恶意检测的自适应系统。这种数据驱动的系统适应人类行为常规的变化,并有能力通过嵌入遗忘机制抛弃旧的行为模式。Withange等人[41]研究了应用计算机视觉通过RGB-D成像识别坠落位置,以便于在老年人独立生活中基于机器人的坠落事故现场辅助。Markovitz等人[42]直接研究了可以从视频序列构建的人体姿势图,该图不会受到视点或照明等有害参数的影响。这种无监督的深度学习模型可以通过学习正常行为来识别异常的人类行为。类似地,Morais等人[43]还通过对其模型中耦合特征的动力学和相互作用进行建模,了解了骨骼轨迹的规律性。该模型的一个优点是,它可以解释其内部推理和相应因素的可视化。这是基于深度学习的异常检测模型的重要组成部分
现有的研究大多集中在视频监控技术上,当有人出现在网络摄像机中时,可以记录视频片段,而自动异常检测很少研究。老年抚养比的增加是全世界面临的一个常见问题,这增加了政府为养老金和医疗保健提供资金的额外负担[44]。然而,对于负担不起照顾者或喜欢独居的人,如果在家中安装了智能视频异常检测系统,老年人可以独立生活,并且可以及时检测和处理紧急情况(例如,老年人摔倒)。因此,开发智能家居中的视频异常检测系统对提高人类生活的质量和便利性具有重要意义。事实上,这种智能系统也可以安装在医院和疗养院,以减少未知事故带来的风险
D. Public Health
公共卫生是一个跨学科领域,涉及流行病学、生物统计学、社会科学等多个领域。此外,环境卫生、社区卫生、行为卫生、心理卫生和其他重要子领域也包括在公共卫生范围内。公共卫生的主要目的是通过预防和治疗疾病来提高人类生活质量。通过监测病例和健康指标,视频异常检测可以从多个角度造福于公众健康。以名为2019年冠状病毒病(COVID-19)的流行病为例,为了避免传染病的进一步传播,可以应用智能视频监控系统来检测异常行为[47]、[48]。Bhambani等人[49]提出了一种实时面罩和社交距离违规检测系统,该系统使用视频片段和图像上的YOLO对象检测。左等人[50]开发了一种基于深度学习的行人社会距离检测系统,该系统可用于分析大流行期间城市流动性的新规范。Saponara等人[51]为2019冠状病毒疾病实现了一个基于人工智能的实时系统,该系统由深度学习对象检测模型和社交距离计算算法组成。智能监控系统利用实时视频信息检测异常模式并执行预测分析。然后识别异常类型,然后启动预定义信号以执行补救措施。通过可穿戴传感器、用户特定行为模式和室内环境参数,可以监测和进一步分析居民的健康状况[52]。基于视觉的环境辅助生活,也称为AAL,旨在改善老年人和弱势群体的日常生活。与环境传感器或佩戴式传感器相比,视频异常检测技术更便宜、更有效、更易于实施。例如,基于RGB摄像机、多摄像机和深度摄像机开发了坠落检测方法[53]。患者监控系统也是视频异常检测在公共卫生领域的另一个重要应用。在医院,这种系统用于更好地定期观察患者,可以检测病房中的异常活动,包括不规则姿势、不平衡行走、爬床等[54]。Cattani等人[55]提出了一种通过从视频中提取和处理运动信号来评估病理运动周期性可能性的方法。鉴于摄像机的低成本和计算机视觉技术的成熟,公共健康中的异常检测必将得到进一步发展。基于视觉的方法可以与其他传感器数据相结合,以提高其鲁棒性和准确性。
智能监控系统利用实时视频信息检测异常模式并执行预测分析。然后识别异常类型,然后启动预定义信号以执行补救措施。通过可穿戴传感器、用户特定行为模式和室内环境参数,可以监测和进一步分析居民的健康状况[52]。基于视觉的环境辅助生活,也称为AAL,旨在改善老年人和弱势群体的日常生活。与环境传感器或佩戴式传感器相比,视频异常检测技术更便宜、更有效、更易于实施。例如,基于RGB摄像机、多摄像机和深度摄像机开发了坠落检测方法[53]。患者监控系统也是视频异常检测在公共卫生领域的另一个重要应用。在医院,这种系统用于更好地定期观察患者,可以检测病房中的异常活动,包括不规则姿势、不平衡行走、爬床等[54]。Cattani等人[55]提出了一种通过从视频中提取和处理运动信号来评估病理运动周期性可能性的方法。鉴于摄像机的低成本和计算机视觉技术的成熟,公共健康中的异常检测必将得到进一步发展。基于视觉的方法可以与其他传感器数据相结合,以提高其鲁棒性和准确性。
E. Digital Twins
在工业环境中,准确的异常检测有助于早期检测潜在故障和主动维护计划管理。为了实现高性能异常检测,近年来,在动态工业边缘/云网络中实现数字孪生技术的研究兴趣不断增长。通常,数字孪生技术用于构建虚拟环境,作为物理对象或过程的实时数字对应物。此外,数字孪生技术的进步可以帮助实现复杂机械的真实模拟,从而加快实现智能制造和工业4.0的进程。
如今,在异常检测任务中,学术界和工业界越来越认识到将数字孪生与深度学习相结合的重要性[58]。在[59]中,作者使用DT生成了涵盖一整年运行的正常运行数据的大型数据集。然后,以弱监督的方式将暹罗Au-toencoder(SAE)架构应用于异常检测。由于电网的临界性质,检测电网异常的能力至关重要[60]。在本文中,作者使用卷积神经网络(CNN)在电气系统自动网络保护(ANGEL)数字孪生环境中检测电力系统中的物理故障。该方法不仅可以检测电力系统中的故障,而且具有识别哪些母线包含异常的能力。Gao等人[61]使用DT收集实时数据并实现实时缺陷识别。随着新型异常的出现,传统模型被重新构建耗时且成本高昂。为了解决这个问题,他们提出了一种用于新类别识别的深度终身学习方法。
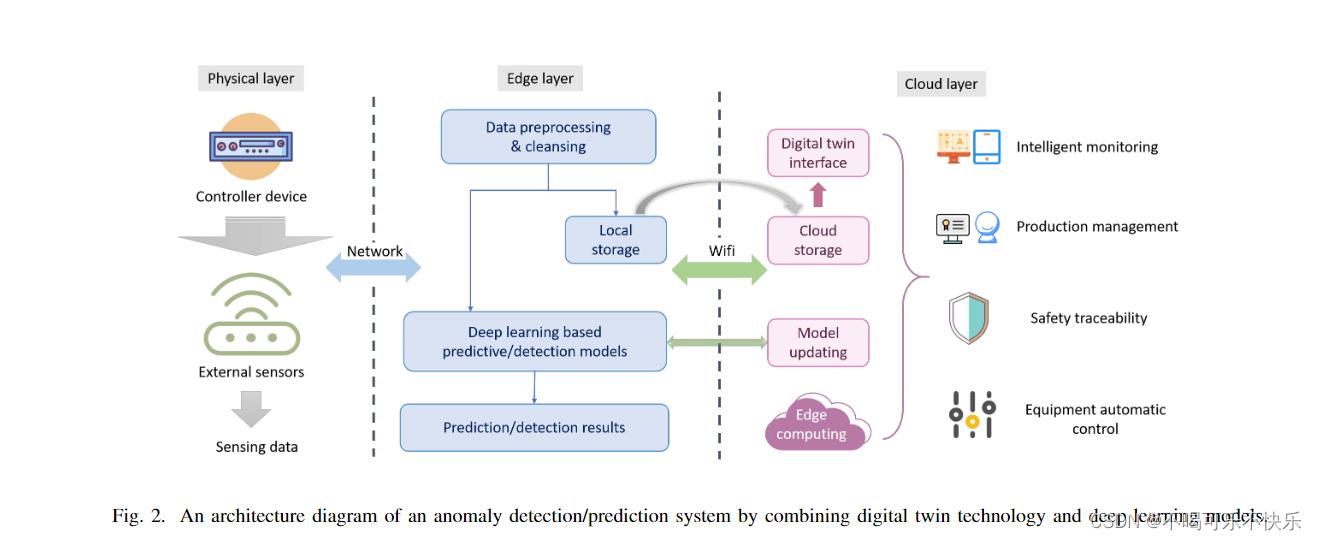
应该注意的是,上述所有DT驱动的异常检测系统不能直接应用于视频监控数据。在现代工业中,摄像机以高密度部署,以无缝监控机器的状态和工人的活动[58]。DT技术可以采用现代数据可视化方案,如虚拟现实(VR)和增强现实,以提供更具插图和用户友好的视图。因此,可以进一步利用深度学习模型和数字孪生技术的集成来解决视频异常检测任务。此外,DT技术能够生成包含不同上下文中异常的合成数据集,从而解决了缺少具有足够正样本且无噪声的数据集的问题。图2显示了结合数字孪生技术和深度学习模型的异常检测/预测系统的架构图。
III. CHALLENGES
针对各种应用中遇到的不同类型的异常和技术困难,提出了许多基于深度学习的模型和智能系统。显然,这些模型和系统可以在很大程度上帮助减少人力资源消耗,并使人们的生活更加方便。然而,视频异常检测仍然存在许多问题和挑战。
在本节中,我们根据模型结构(即基于重建的模型、预测模型、生成模型、一类分类模型和混合模型)讨论了模型中存在的技术问题和挑战。不同类别的模型之间有一些联系。例如,预测模型可以使用生成器来预测视频的下一帧,使用鉴别器来判别预测是真是假。下表总结了这些模型之间的比较。
| 类型 | Assumption | Drawback |
|---|---|---|
| 基于重建的模型 | 正常数据的重建误差值较低。相反,异常数据会获得更高的值 | 模型泛化良好时无效;难以解释 |
| 预测模型 | 正常数据可以很好地预测,即预测帧和实际帧之间的差异比异常数据更接近 | 更高的计算复杂度 |
| 生成模型 | 生成器生成鉴别器网络的不规则性,并将鉴别器训练为二进制分类器 | 训练昂贵;不稳定;再生产困难;模式崩溃 |
| 一类分类模型 | 正常数据被压缩到超平面或超球体中,任何显著偏离正常行为的行为都被称为异常 | 训练时间更长 |
| 混合模型 | 深度学习模型用作特征提取器来生成特征表示,并将特征表示输入分类算法中 | 表示学习和分类模型分离导致检测性能不理想 |
A. Reconstruction-based Models
与正常实例相比,异常实例通常很少。为了解决这个问题,基于重建的异常检测方法通常以无监督的方式学习正常行为的特征。重建模型的基本思想是在测试阶段以较低的重建误差值重建正常数据,并使其分布更接近训练数据。相应地,异常数据的重建误差预计会更高。深度自动编码器[74]是重建模型中最常用的模型,它由一个编码器Encoder和一个解码器Decoder组成,前者将输入向量压缩到低维向量中,后者将该密集向量重建回输入向量。DeepAD[75]的目标是最小化输入向量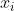 和重构向量之间的重构误差
和重构向量之间的重构误差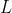 :
:

其中N是正常的训练数据,D(E(·))是DeepAD框架。在这里,编码器可以是任何类型的神经网络,例如卷积神经网络(CNN)和长短时记忆(LSTM)。尽管DeepAD及其变体很受欢迎,但龚等人[76]指出,如果自动编码器无法概括异常数据,则无法满足重建误差值较高的异常假设。换句话说,异常是使用广义模型重建的,编码器生成的表示不能保证其有效性。因此,该模型无法解释检测到的异常帧异常的原因。
B. Predictive Models
视频由一系列帧组成,这些帧可以被视为空间和时间信号的顺序。预测模型的任务是通过给出过去的p帧来预测t帧,其可以表示为:
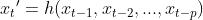
基于真实目标帧及其预测帧构建预测模型的损失函数:

其中, 是时间戳t中的真实目标帧,
是时间戳t中的真实目标帧, 是预测帧。预测模型假设可以很好地预测正常事件。因此,预测帧与其基本真值之间的差异可用于检测异常事件。虽然预测模型在视频异常检测任务中表现良好,但其计算复杂度较高。因此,预测模型更适合离线应用。
是预测帧。预测模型假设可以很好地预测正常事件。因此,预测帧与其基本真值之间的差异可用于检测异常事件。虽然预测模型在视频异常检测任务中表现良好,但其计算复杂度较高。因此,预测模型更适合离线应用。
C. Generative Models
生成模型通常包含基于高斯分布生成帧的架构,例如生成对抗网络(GAN)[77]。GAN由发生器和鉴别器组成。生成器的作用是根据真实数据的实际分布拟合新的数据分布,而鉴别器是判别向量是从真实数据中提取还是从生成的数据中提取。GAN的损耗函数表示如下:

该函数的前半部分旨在最大限度地提高识别真实数据的概率,后一部分旨在识别生成的数据。在这里,生成器和鉴别器可以是任何类型的神经网络结构,如CNN。与其他模型不同,通过同时训练生成器和鉴别器,GAN可以作为端到端模型。此外,生成器可以同时生成异常样本。因此,GAN是视频异常检测中应用最广泛的模型之一。尽管甘有其优点,但它也不可避免地存在一些缺陷,包括训练费用高、不稳定、复制困难和模式崩溃。
D. One-Class Classification Models
考虑到异常的模糊性和多样性,迫切需要开发用于检测视频异常的多类分类。在检测视频异常时,研究人员通常将任何明显偏离正常行为的行为视为异常。因此,没有异常标签的异常检测任务可以被视为一类分类(OCC)问题。这种模型在视频异常检测中的核心思想是找到一个超球,该超球包围正常数据的网络表示[78]。此超球体中未包含的任何数据点都将被视为异常。深度学习和OCC模型的组合可以训练为联合学习具有一类分类目标的密集特征表示。然而,这种模型需要花费更多训练时间。
E. Hybrid Models
在解决异常检测任务时,每种模型都有自己的目标函数和特定的优势。因此,研究人员可以考虑在一个模型中建立多个服务于不同块的模型,这可以利用不同的模型并提高检测精度。在混合模型中,从深度学习方法中学习到的代表性特征可以转移到传统算法,如支持向量机(SVM)分类器[79]。低维特征向量使混合模型更具可扩展性和计算效率,适用于解决视频异常检测任务。与其他具有自定义损失函数的模型不同,混合模型的损失函数是通用的,这意味着特征提取器对特征表示没有影响。因此,混合模型的性能次优。尽管混合模型在任务中具有出色的性能,但它们大多依赖于任务,无法在不同任务之间切换。
IV. CONCLUSION
本文介绍了深度视频异常检测模型在几种新兴的实际应用场景中的潜在机会,并讨论了文献中的技术问题。本研究在深度视频异常检测方面的新视角为对此领域感兴趣的研究人员提供了明确的指导。
动态图上的异常检测文献综述(2015)
参考技术A动态图上的异常检测任务包括:发现异常的对象、关系、时点。动态图上的异常检测与静态图上的异常检测不同的地方在于:
本文首先将异常类型分为:anomalous vertices, edges, subgraphs, and events(or change),将使用的方法分为:community detection, MDL(minimum description length) and compression, decompression, distance, probabilistic, 按每种方法使用的异常类型进行了文献学分类。各方法的主要参考文献见表1:
本文假设不同时点的节点和边都有唯一标签从而不会混淆,定义 为图序列,其中 为总时间步, , 为节点集, 为边集, 时称 为图流。本文的主要记号见表2:
给定 ,节点集 ,打分函数 ,定义异常节点集为 ,使得对于 , ,其中 为得分 的摘要式统计。
一个典型的异常节点如图1,其可由基于社区检测的方法识别,即: 其中 为节点所属的社会划分, 为异或操作。
给定 ,边集 ,打分函数 ,定义异常边集为 ,使得对于 , ,其中 为得分 的摘要式统计。
一个典型的异常边如图2,可令 ,其中 为时间步 时 的权重,可以为边的概率。
给定 ,子图集 ,打分函数 ,定义异常集为 ,使得对于 , ,其中 为得分 的摘要式统计。
两种典型的异常子图如图3,其中(a)为图的收缩,(b)为图的分裂。图的收缩可根据子图中的的数量衡量,即 ,图的分裂可由不同时间点社区的数量衡量。
与异常节点、边、子图检测不同,异常事件或异常突变检测检验的是时点。
给定 ,打分函数 ,若时点 满足: , ,则称时点 为一个事件。
给定 ,打分函数 ,若时点 满足: , ,则称时点 为一个突变。
通常的异常检测都使用两步法:第一步,基于特征的图表示;第二,基于机器学习的异常检测。
基于社区检测的方法关注的是社区和关联节点的演化过程,特征向量的生成亦基于图中的社区结构。不同社区检测方法的区别在于:(1)社区结构的领域,如社区内的连接性v.s.单个节点在每一步所属的社区;(2)社区结构的定义,如基于概率的软社区定义v.s.硬社区定义。基于社区检测的方法可用于异常定点、子图、突变的检测。
基于软社区匹配并单独考察每一个社区,我们可以在连续时间步内计算每个节点归属的平均变化,如果某个节点归属的平均变化显著异于其他节点,则称其为演化社区异常点。
节点社区归属的变化可以构造一个时间模式,称为软时序模式。一些文献使用了最小描述长度(MDL)结合非负矩阵分解的方法来自动检测节点角色及构造转移模型。多数文献通过抽取图中不同节点的共同模式,并比较每个节点与共同模式之间的差异来定义异常节点。部分文献使用了交替迭代优化替代常用的两步法。部分文献使用了corenet的概念,该概念不同于单纯使用density,modularity,hop-distance等概念,而是使用了节点间的加权路径,即一个节点的corenet包含该节点与权重大于给定阈值的两跳邻居。假设两个强连接的节点通常属于同一社区,则如果移除一个节点的两个邻居,一个邻域具有较高的边权重,另一个具有较低的边权重,则移除较高权重邻居的影响应更大,在每一步,每个节点首先被赋予一个异常得分,该得分衡量了其corenet的变化,异常得分较高的 各节点将被视为异常节点。
文献【69】定义了六种基于社区的异常:shrink, grow, merge, split, born, and vanish。其使用图和社区代表(representatives)进行比较以减少计算量,图代表为出现在t时刻,同时还出现在t-1、t+1或t+1与t-1时刻的节点集,社区代表是出现在其他社区最少的定点集合,基于社区代表和图代表,基于规则,判断社区是否落在六种异常中。
文献【73】定义了一种基于社区的异常:comet,周期性出现或消失的社区,演化图可表示为一个张量,然后基于低秩张量分解和MDL原则进行comet检测。
文献【3】基于多种信息源构造时序复网络,识别跨时间和网络的稳定社区结构。行为相似的网络可以用聚类或前验知识分组,如何一个社区结构在组内跨时间步稳定,但在组外没有对应社区,则该社区即为异常,如何两个社区共享一定比例的定点则称为对应。
社交网络可以根据特定时间窗口内的发文量定义事件,一个经历共同事件的组即构成一个异常子图。
通过划分图流为一致的分割来检测,分割是依据划分的相似性。
通过将最新图的顶点分区与当前增长分割中的图的分区进行比较,可以在线找到这些分割。【67】基于可返回随机的相关矩阵和modularity最大化来进行定点划分,当新图的划分与当前分割的划分有很大不同时,一个新段开始,并将新图的时间点输出为检测到的突变。两个划分的相似度使用Jaccard系数定义。GraphScope思路类似,但基于MDL来指导划分和分割。
基于MDL原则和基于该原则的压缩技术利用数据中的模式和规律性实现紧凑的图表示,其主要通过将图的邻接矩阵表示为一个二进制串,如果矩阵的行和列可以重新排列使矩阵的二进制字符串表示的熵最小化,那么压缩损失(也称为编码损失)就会最小化。数据指向的特征都来自于图或其特定子结构的编码代价;因此,异常被定义为抑制可压缩性的图或子结构(如边)
对于一条边和对应子图,如果包含该边的编码损失比不包含该边的编码损失高,则称该边为异常边。
【74】使用了一种两步交替迭代法进行节点的自动划分,当节点划分的熵收敛时,根据包含和不包含该边的编码损失,该方法也给出了边的异常度得分。
突变检测的主要思路是:连续时间步间的图是相似的,因而可以分为一组,从而降低压缩比。压缩比的上升表明新一个时间步的图与已有的图差异明显,因此是一个突变。
该方法将图集合表示为一个tensor,在该tensor上进行矩阵分解或降维,基于分解或降维后的图发现其模式和规律性,该方法可以融合更多属性信息,最常用的方法是SVD和PARAFAC(广义SVD)。
矩阵分解可用于计算每个节点的活跃(activity)向量,如果某个节点的活跃向量在连续时间步间变化明显,则称为异常节点。
【87】首先抽取每个节点的边相关矩阵 ,即该节点的每个邻域都有一行一列,对于节点 的矩阵中的一个entry 代表了边 和 间加权频率的相关性,加权频率由衰减函数获得,时间越近权重越高。M的最大特征值和对应特征向量即顶点的活跃向量的summary及边的相关性。通过寻找这些值的变化而形成的时间序列用于计算每个时间步长中每个顶点的分数,得分高于阈值的顶点将被输出为异常。
基于分解的异常事件检测有两种方法:(1)先基于分解方法来近似原始数据,然后以重建损失作为近似优劣的指标。如果某个子张量、切片或元素的重建损失很高,则即可以视其与周围数据不同特征不同,将其标记为异常事件、子图或节点。(2)跟踪奇异值和向量,以及特征值和特征向量,以检测异常顶点的显著变化。
为解决 intermediate blowup 问题(即计算中输入和输出张量超过内存限制),【81】提出了momery-efficient tucker(MET)分解方法,该方法源于Tucker分解,Tucker分解将高阶tensor用一个core tensor和每个mode(维度)矩阵表示。【80】使用了Compact Matrix Decomposition(CMD),其可以用来计算给定矩阵的稀疏低秩矩阵。使用CMD对图流中的每个邻接矩阵进行分解,可得到重建值的时间序列,基于重建值序列可进程事件检测,典型应用有COLIBRI, PARCUBE,其中后者在斑点(spotting)异常中的表现更高效。
【84】使用了随机图模型进行基于概率模型的检测,其将真实图邻接矩阵和期望图的邻接矩阵间的差异构造为残差矩阵,对残差矩阵执行SVD,再使用线性Ramp滤波器,基于top奇异值即可进行异常时间窗口检测,通过检查正确的奇异向量来确定相应的顶点。
除以上方法,我们还可以基于分解空间的显著变化来识别事件。【77】通过对数据执行PCA,计算的特征向量可以分为正常和异常两个集合,方法是检验数据中的值映射到特征向量。在每个时间步,根据特征值对特征向量进程降序排列,第一个特征向量则包含一个在其余值的3个标准差之外的投影点,此后的每个特征向量,都构成了异常集。第二步即是将数据映射到正常和异常子空间,一旦完成了这些操作,当从上一个时间步长到当前时间步异常成分的修改超过一个阈值时,即将其视为一个事件。【83】扩展了该方法,提出了联合稀疏PCA和图引导的联合稀疏PCA来定位异常和识别对应的顶点。通过为异常集使用稀疏的成分集,可以更容易识别负责的顶点。顶点根据它们在异常子空间中对应行的值得到一个异常分数,由于异常分量是稀疏的,不异常的顶点得分为0。
图的活跃向量 为主成分,左奇异向量对应最大奇异值,奇异值和奇异向量通过对加权邻接矩阵进行SVD得到。当活跃向量大幅异于“正常活跃"向量时,即定义该时点为突变点,”正常活跃“向量由前序向量得到。
正常活跃向量 ,它是对最后W时间步中活动向量形成的矩阵进行SVD得到的左奇异向量。每个时点都定义一个得分 ,其代表了当前活跃向量与正常向量的差异。异常可以使用动态阈值方案在线发现,其中得分高于阈值的时间点被输出为变化。通过计算正常向量和活动向量之间的变化比率来找到负责的顶点,与变化最大的索引所对应的顶点被标记为异常,类似的方法也可以用于节点-节点相关矩阵的活跃向量,或基于邻居相似度的节点-节点相关矩阵。
基于距离的异常检测算法的不同点在于选择用于提取和比较距离度量,以及它们用于确定异常值和相应图的方法。
如果一些边的属性演化异于正常演化,则该边就是一个异常边。
边之间的权重使用衰减函数定义,在每个时间步长中,根据相似度得分的变化之和计算每条边的异常值得分,使用阈值或简单的 作为异常值标准。
将网络视为边的流,意味着网络没有固定的拓扑,一个边的频率和持久性可以用来作为其新颖性的指标,【48】定义了集合系统不一致性指标来度量频率和持久性,当一条边到达时,计算其差异,并与活动边集的平均不一致性值进行比较,如果边的加权不一致性大于平均不一致性的阈值水平,则声明该边为异常边,基于异常边,可以进一步识别其他异常图元素(如顶点,边,子图)。
具有许多“异常”边的子图即是异常的子图。
【52】将边的权重视为异常得分,每个时间步长上的每条边都有它自己的异常分数,给定了该边权值在所有图序列的分布,该分数表示在该特定的边上看到该特定权值的概率函数。或者,为网络中的边分配异常值分数的现有方法的输出可以用作为该方法的输入。后一种方法允许应用于任何能够为边分配异常值分数的网络,一旦完成每条边的异常打分,即可发现显著异常的区域(SARs),即一个窗口内的固定子图,其类似于HDSs。【112】提出了一种迭代算法,该算法首先固定子图发现最优时间窗口,然后固定时间窗口发现最优子图。【97】拓展了该方法,允许子图渐变,即在相邻时间步间增加或移除顶点。
定义函数 为测度图距离的函数,将其应用于连续图序列,即得到距离序列,基于该距离序列应用一些启发式算法(如基于移动平均阈值的 取值)即可得到异常事件。
称每个顶点及其egonet的特征为局部特征,整张图的特征为全局特征。每个顶点的局部特征可聚合为一个向量,基于该向量的各阶矩可构造signature向量,利用signature向量间的Canberra距离(归一化的曼哈顿距离)可构造图之间的距离函数【93】。【92】利用全局特征,定义了一种基于dK-2序列的距离测度,将高于阈值的特征视为异常点。
【96】使用了顶点亲和度(即一个顶点对另一个顶点的影响,可以用于快速信念传播)得分作为signature向量,其基于连续时间步技术顶点亲和度,基于马氏距离度量两个图的相似度,亲和度得分的变化反应并适应变化的影响水平,例如桥边的移除比正常边移除的得分更高。利用单个移动范围的质量控制,可以对相似度得分的时间序列设置一个移动阈值,如指数移动平均加权。
作为特征相似度的补充,我们也可以比较两个图的结构差异来度量突变的大小,这类方法致力于发现定义距离的函数而非发现特征向量。【88】计算了异常网络的10种距离函数,使用ARMA模型构造特征值的正常模型,然后基于正常模型计算时点的残差,残差超过给定阈值的时间即可标记为异常。10种距离函数中,基于最大共有子图的方法表现最好。【90】使用了五中得分函数(顶点/边重叠,顶点排序,向量相似度,序列相似度,signature相似度)来检测三种异常(子图缺失,顶点缺失,连通性变化),表现最好的方案是抽取每个顶点和边的特征构造signature向量,使用SimHash定义距离。
我们还可以通过计算每个图的稳健性序列来检测事件,稳健性序列是图连通性的测度,具有高稳健性的图即使在去除一些顶点或边的情况下,也能保持相同的一般结构和连通性,事件检测即发现稳健性值异常变化的时点【95】。【89】使用的是图半径的变体作为稳健性指标,图半径的定义是基于所有顶点的平均离心度,而非常用的最大离心度。
基于概率理论、分布、扫描统计学等方法可以构造“正常”样本的模型,偏离该模型的样本即视为异常,这类方法的主要区别在于构造方法、建模对象、离群值定义。
主要有两种方法:一,构造扫描统计时间序列并检测离均值若干标准差的点;二,顶点分类。
扫描统计常称为滑动窗口分析,其在数据的特征区域中发现测度统计量的局部最小或最大值。对某个特定图,扫描统计量可以是图不变特征的最大值,如边的数量。
【8】使用了一个适应测度统计量的变量,即每个节点的0-2度邻居数,然后对每个顶点的局部统计量使用近期值的均值和标准差进行标准化,图的扫描统计量即最大的标准化局部统计量。标准化可以解释每个顶点的历史信息,代表每个顶点的统计量只与自己的历史信息有关而与其他顶点无关。这保证测度的最大变化与变化的绝对量无关而与比例有关。基于扫描统计量标准化时间序列,将序列均值的五个标准差作为异常值。最负责的顶点被确定为为整个图的扫描统计值所选择的顶点。
类似于使用邻居进行扫描统计,我们还可以用Markov随机场(MRF)来发现节点的状态,并通过信念传播算法推断最大似然分配,其中,每个顶点标签取决于其邻居节点。【99】通过发现二部核来检测异常点(即诈骗犯),二部核定义为诈骗犯与从犯间的交互。利用边的插入或删除只影响局部子图这一事实,它在添加新边时逐步更新模型。在传播矩阵中,一个顶点可以处于三种状态之一:欺诈者、共犯者或诚实者。
边异常检测通常使用计数过程建模,统计上显著异于该模型的边标记为异常边。
【50】用贝叶斯离散时间计数过程来建模顶点间的通信次数(边权重),并根据新图更新模型。基于学习到的计数的分布,对新观测的边进行预测 值计算,基于 值标记异常顶点对。
首先用固定的子图,多重图,累积图来构造预期行为的模型,对模型的偏离可作为子图异常检测的依据。
【104】结合扫描统计量和隐马尔可夫模型(HMM)建模边行为,其使用的局部扫描统计量是基于两种图形状:k-path图和星型图,其将滑动窗口的扫描统计数据与其过去的值进行比较,并使用在线阈值系统识别局部异常,局部异常是所有统计上显著的子图(代表k个路径或恒星)的并集。
另一个建模动态图的方法是基于多重图,其中平行边对应于两个连续时间步顶点间的通信,初始的多重图可分解为多个针对每个时间窗口的叠套子图(TSG),TSG满足两个条件:(1)对于任何两个有共同点的边,首先开始通信的边最后完成通信;(2)存在一个根顶点r,它没有传入的边,并且有一条到TSG中每个顶点的路径。出现概率低的TSG视为异常子图。【102】
累积图即为包含直到当前时点的所有边的图,边权重依据衰减函数定义,通过识别“持久模式”来定义子图的正常行为。该持久模型识别模型如下:首先构造一种图,该图每个边根据时间来加权,然后基于该图迭代抽取最重连接成分来发现。随着累积图的发展,提取的子图将被监控,并将其当前活动与基于最近行为的预期活动进行比较来进行子图异常检测。【101】
事件检测可以基于偏离图似然模型或特征值分布的偏差来进行。
【103】提出了一种新的蓄水池抽样方法来抽取图流的结构摘要,这种在线抽样方法维持多个网络划分以构造统计上显著的摘要,当一个新图进入图流,每个边都根据不同分区的边生成模型计算出一种似然性,然后以这些似然性的几何均值作为全局图似然性。
【98】使用了类似的边生成模型,每个边 的概率都存储在矩阵 中,概率基于期望最大化估计,基于所有收发对的分布,然后为每个收发对给出潜在得分,基于所有边似然得分的均值即得到每个图的得分。
【100】计算了特征值和压缩特征等式的分布(而非计算收发对的分布),基于每个顶点都存在一个顶点局部特征时间序列的假设,可在每个时间步构造一个顶点-顶点相关矩阵,通过保留最大特征值和一组低维矩阵(每个顶点对应一个矩阵),可对相关矩阵的特征方程进行压缩,通过学习特征值和矩阵的分布,即可发现异常顶点和事件。当特征值偏离期望分布时,即认为发生了事件,当顶点的矩阵偏离矩阵分布时,可认为该顶点为异常顶点。
以上是关于视频异常检测综述-论文阅读Deep Video Anomaly Detection: Opportunities and Challenges的主要内容,如果未能解决你的问题,请参考以下文章
视频去模糊论文阅读-Cascaded Deep Video Deblurring Using Temporal Sharpness Prior
论文阅读2022年最新迁移学习综述笔注(Transferability in Deep Learning: A Survey)
论文阅读2022年最新迁移学习综述笔注(Transferability in Deep Learning: A Survey)
论文阅读2022年最新迁移学习综述笔注(Transferability in Deep Learning: A Survey)
论文阅读 (75):Video Anomaly Detection with Spatio-temporal Dissociation (2022)