人工智能算法一&线性回归
Posted 顶尖高手养成计划
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能算法一&线性回归相关的知识,希望对你有一定的参考价值。
简介
这是一个最简单的线性回归例子,图解了算法和相关代码。
详解
前提说明
参数估计中均方误差是指参数估计值与参数真值之差平方的期望值,记为MSE。
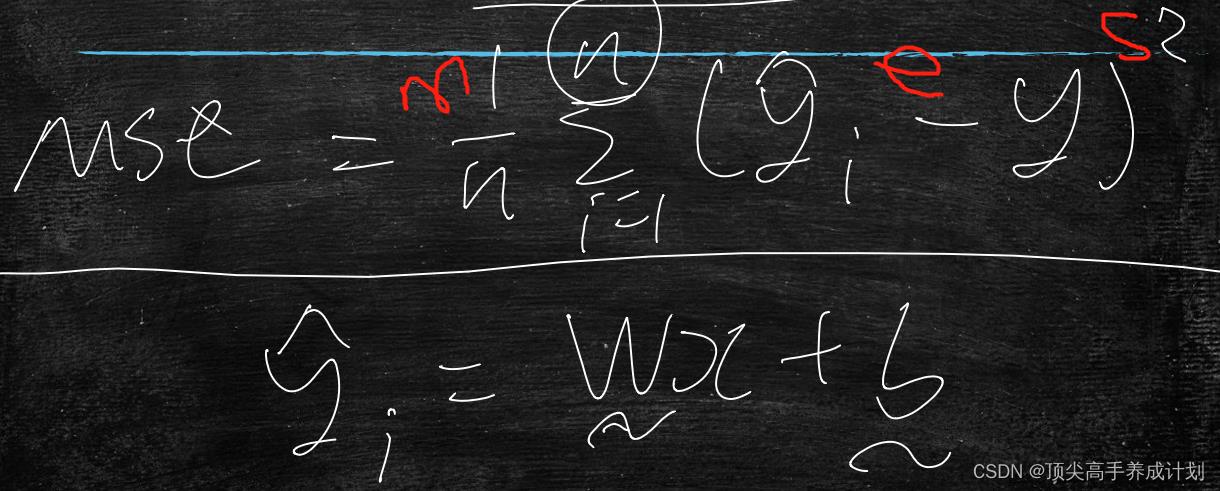
要想是预测y=wx+b中的线性回归在大量的x和y都知道的情况下预测w,b。那么对于这种无解析解,那么就需要用到机器学习推出w,b的值,那么mse越小,模型训练的就越好,w,b的值也就越准确。
反之w,b越准确,训练出来的模型也就越好,模型越好,处理的数据也就越真实。
开始训练
前提依赖
pip install sklearn训练数据
[[5.344187740028914], [30.91441332291272]]
[[4.690797837330457], [17.989132245249227]]
[[3.06514407164054], [32.67390058378043]]
[[0.29136844635404446], [-15.046942990405128]]
[[2.7042454045721764], [-4.198779971237319]]
[[9.15496044375243], [54.50659423843143]]
[[4.323588254945952], [76.06219903136115]]直接上代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import sys
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn import metrics
def curce_data(x,y,y_pred):
x=x.tolist()
y=y.tolist()
y_pred=y_pred.tolist()
results=zip(x,y,y_pred)
results=[",,".format(s[0][0],s[1][0],s[2][0]) for s in results ]
return results
def read_data(path):
with open(path) as f :
lines=f.readlines()
lines=[eval(line.strip()) for line in lines]
X,y=zip(*lines)
X=np.array(X)
y=np.array(y)
return X,y
#这里得到的数据情况。
#原始数据
# [[5.344187740028914], [30.91441332291272]]
# [[4.690797837330457], [17.989132245249227]]
# [[3.06514407164054], [32.67390058378043]]
# 得到的X_train:
# [[5.344187740028914],[4.690797837330457],[3.06514407164054]]
#得到的y_train
#[[30.91441332291272],[17.989132245249227],[32.67390058378043]]
X_train,y_train=read_data("train_data")
X_test,y_test=read_data("test_data")
#一个对象,它代表的线性回归模型,它的成员变量,就已经有了w,b. 刚生成w和b的时候 是随机的
model = LinearRegression()
#一调用这个函数,就会不停地找合适的w和b 直到误差最小
model.fit(X_train, y_train)
#打印W
print (model.coef_)
#打印b
print (model.intercept_)
#模型已经训练完毕,用模型看下在训练集的表现
y_pred_train = model.predict(X_train)
#sklearn 求解训练集的mse
# y_train 在训练集上 真实的y值
# y_pred_train 通过模型预测出来的y值
#计算 (y_train-y_pred_train)^2/n
train_mse=metrics.mean_squared_error(y_train, y_pred_train)
print ("训练集MSE:", train_mse)
#看下在测试集上的效果
y_pred_test = model.predict(X_test)
test_mse=metrics.mean_squared_error(y_test, y_pred_test)
print ("测试集MSE:",test_mse)
train_curve=curce_data(X_train,y_train,y_pred_train)
test_curve=curce_data(X_test,y_test,y_pred_test)
print ("推广mse差", test_mse-train_mse)
'''
with open("train_curve.csv","w") as f :
f.writelines("\\n".join(train_curve))
with open("test_curve.csv","w") as f :
f.writelines("\\n".join(test_curve))
'''
下面是得到的结果

可以看到测试的MSE相对训练的MSE会大一点。

原因是:
测试集里面只有少量的包含了训练集的数据。这个时候测试集的mse就会要高一点,如果测试集在训练集里面那么可能就会低。
还有就是求mse为什么用平方:
因为尽量的放大mse,对于得到的收益也越大,预测成功的数据也会越广。
还有就是如果是常数,那么就没有办法做梯度下降算法。

梯度下降
推导
对于上面的y=x*w+b求mse公式的优化。
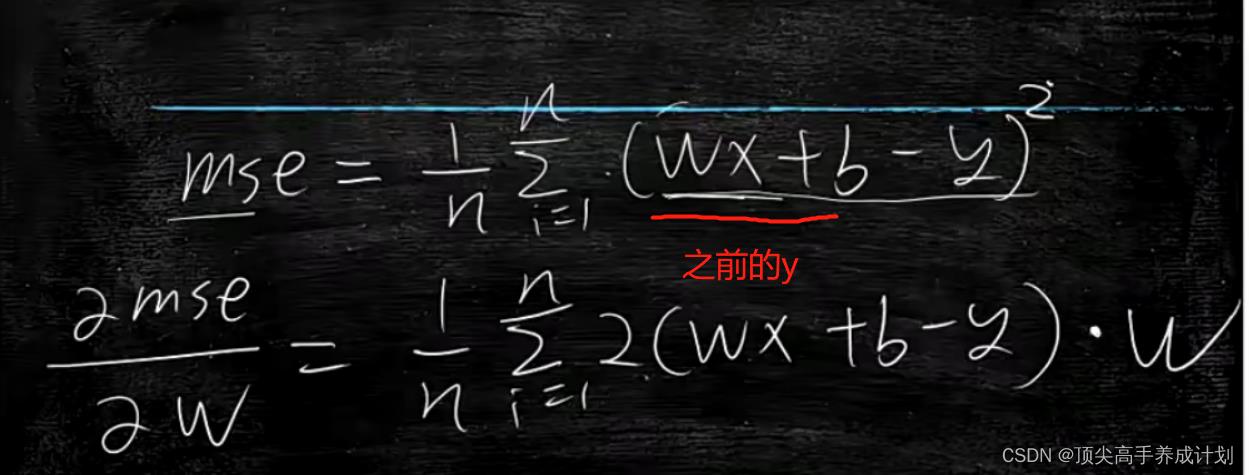
用导数求mse的最小值。关于mse的导数,也叫做梯度,&mse/&w关键在于调整w的值,然后得到mse的最小值,也就是如果&mse/&w>0,那么这是一个单调递增的,如果想找到mse的最小值,那么w就要变小。如果&mse/&w<0,那么就是单调递减。我们要找到mse的最小值,那么w就要变大。
,,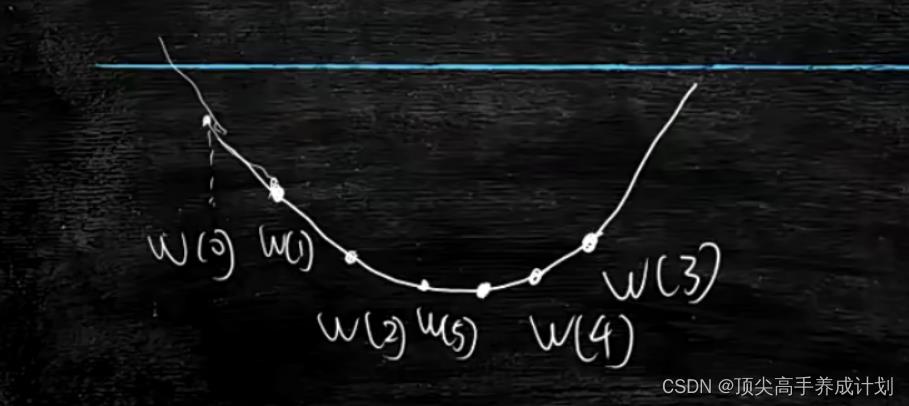
但是这里有一个问题,如果很平滑这个抛物线,那么怎么改变它的速度呢?
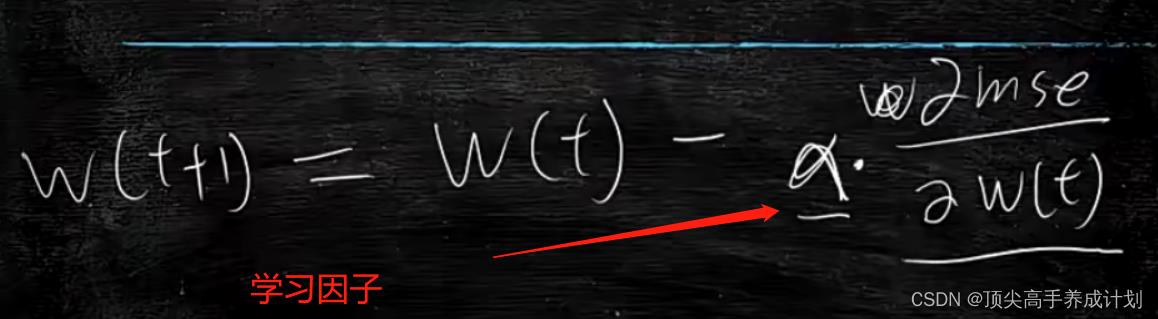
上面就是对于改变的w,增加一个学习因子,简单的理解就是步长的意思(根据经验给值) 。
结论
简单的理解就是:
如果想找到mse的最小值,那么就根据mse对于w求导数,让后启动w的值得到最少的mse,那么这个w就是要找到的训练模型的值。
训练集数量问题
下图对应的是全部数量集,和部分数量集的相关想性。
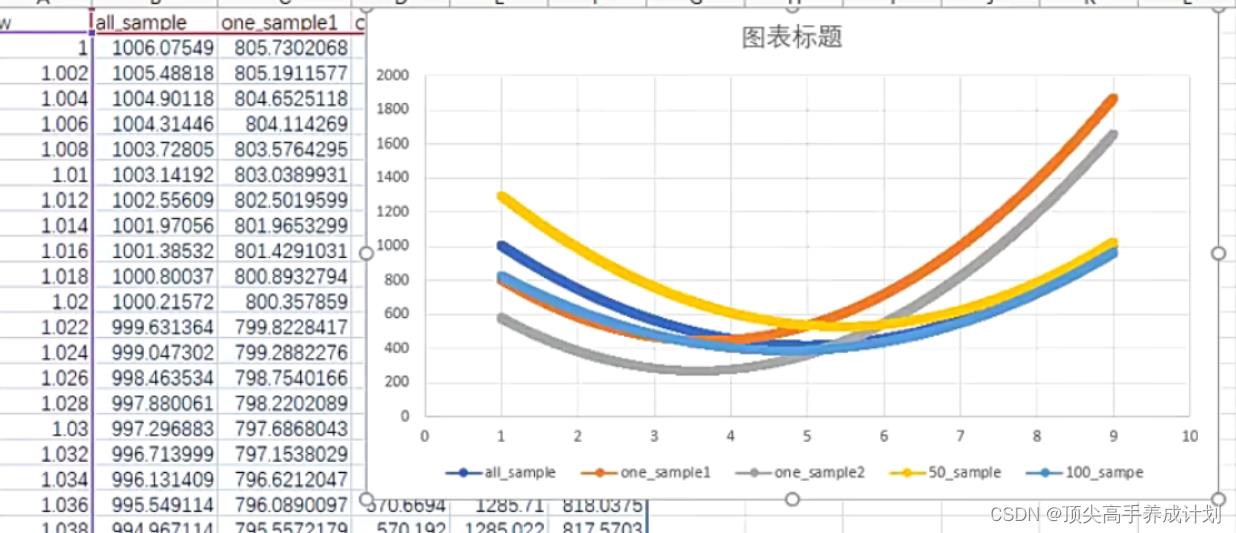
mse越小越好吗?
不是,因为会出现过拟合的情况。就是避免特例,影响大多数。

上图就是在一个合适的时候,停止学习。
怎么判断是否学过了,可以按时间分别的学习,如果mse开始变大了,那么前面的mse相对就会好一点。
多元分析mse
比如房价预测,x1地段,x2时间....,预测y最后的房价。
公式
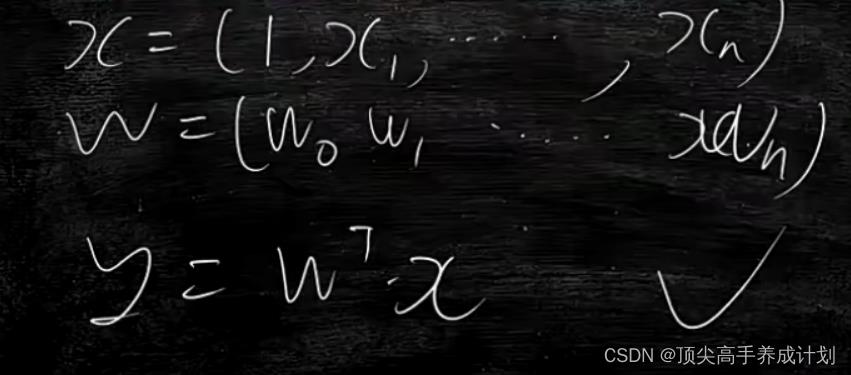
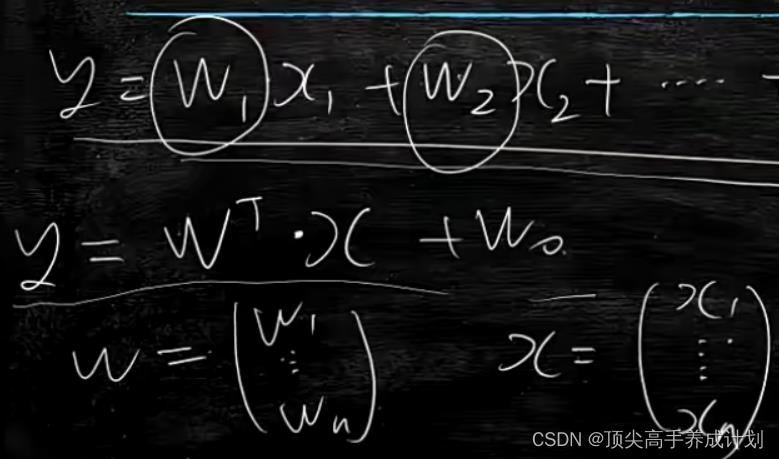
开始训练
# -*- encoding:utf-8 -*-
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_predict
from numpy import shape
from sklearn import metrics
import numpy as np
def extend_feature(x):
result=[x[0],x[0]]
result.extend(x[1:])
return result
#return [x[0],x[0]]
def read_data(path):
with open(path) as f :
lines=f.readlines()
lines=[eval(line.strip()) for line in lines]
X,y=zip(*lines)
X=[extend_feature(x) for x in X]
X=np.array(X)
y=np.array(y)
return X,y
#train_data里面的数据
#[[3.69311, 0.0, 18.1, 0.0, 0.713, 6.376, 88.4, 2.5671, 24.0, 666.0, 20.2, 391.43, 14.65], 17.7]
#[[0.06211, 40.0, 1.25, 0.0, 0.429, 6.49, 44.4, 8.7921, 1.0, 335.0, 19.7, 396.9, 5.98], 22.9]
#这里就是得到了x的数组,和对应y的数组
#x[[3.69311, 0.0, 18.1, 0.0, 0.713, 6.376, 88.4, 2.5671, 24.0, 666.0, 20.2, 391.43, 14.65],[0.06211, 40.0, 1.25, 0.0, 0.429, 6.49, 44.4, 8.7921, 1.0, 335.0, 19.7, 396.9, 5.98]]
#y[17.7,22.9]
X_train,y_train=read_data("train_data")
X_test,y_test=read_data("test_data")
model = LinearRegression()
#对于得到的x,y分别的数组进行训练
model.fit(X_train, y_train)
#得到对应的w,b
print (model.coef_)#打印w
print (model.intercept_)#打印b
#根据得到的模型,输入x,得到y
y_pred = model.predict(X_train)
#根据预测的数值和真实的数值求mse,mse越小的,模型训练的也就越好。w,b也就越准确
print ("MSE:", metrics.mean_squared_error(y_train, y_pred))
y_pred = model.predict(X_test)
print ("MSE:", metrics.mean_squared_error(y_test, y_pred))
得到的结果

线性回归花式玩法
处理多元数据有随机数的情况
在多元处理模型的时候,如果有些数太乱,也就是错误数据,比如下面的x4是随机的,那么求出来的w4接近于零。也就是对于最后的运算结果影响不会太大,但是会消耗计算机的计算能力。

处理x数据有重复的情况(分析维度冗余)
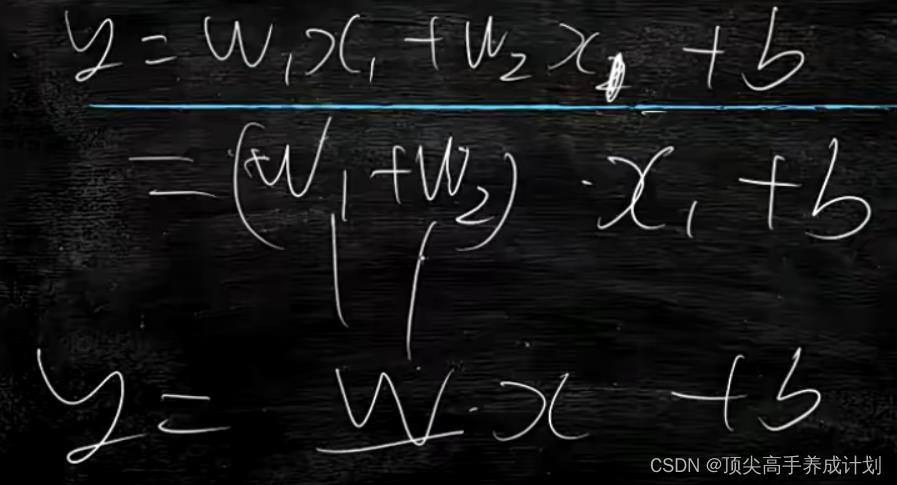
模型结果有相同的情况
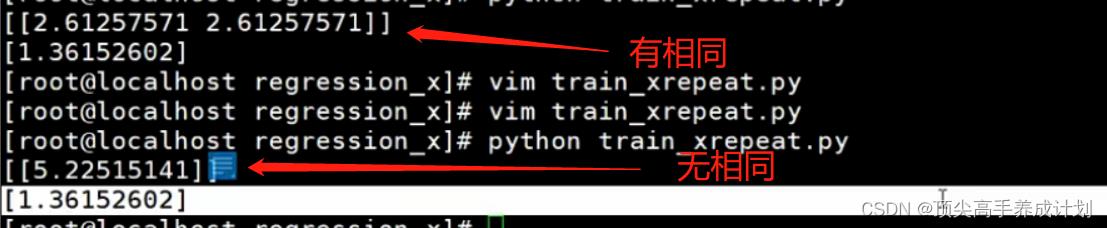
结论
线性回归最好数据在一条直线上。
如果x的比比较大就会形成抛物线,如下图。
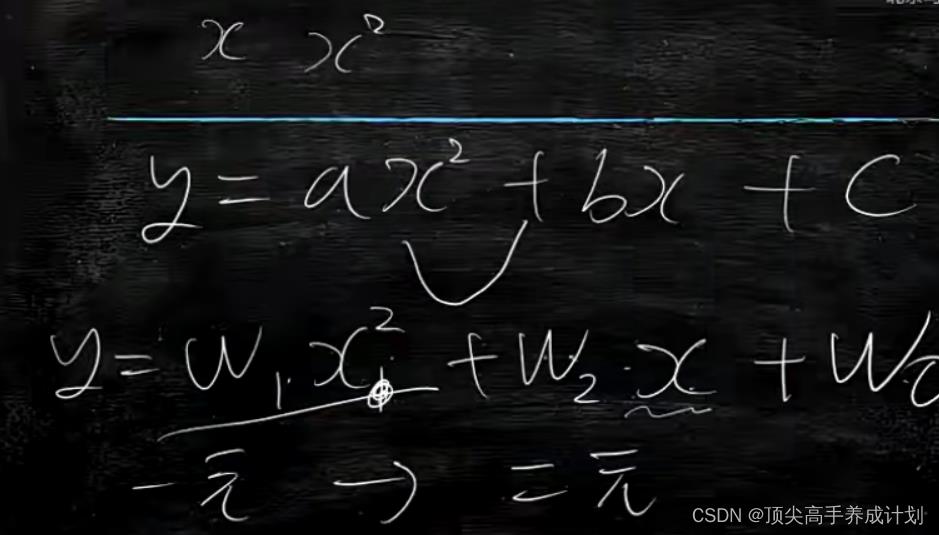
训练出来大概的模型是。
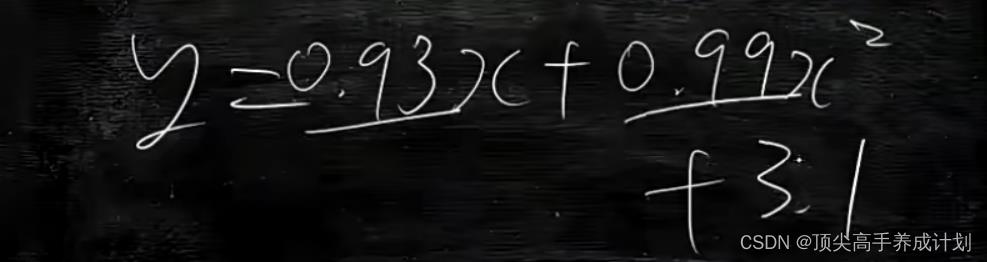
得到的结果图
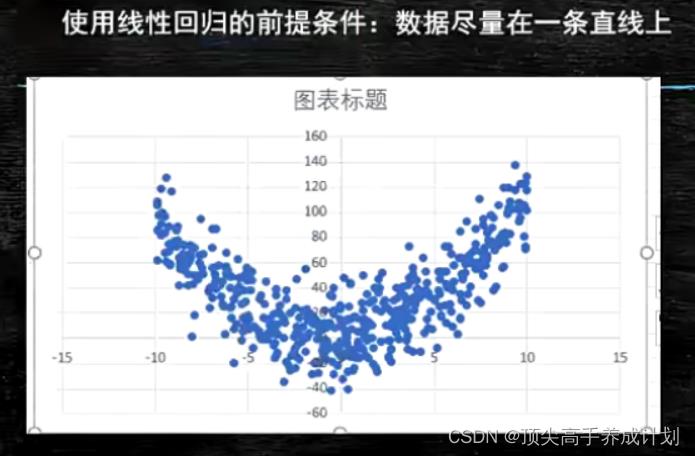
数据一定尽量真实才能通过训练出来的模型,更具x得到y。

也就是说,线性回归在多个维度,只要数据足够的真实都能够得到对应的模型,预测y的值。
还有就是维度不是越多越好,如果维度太多,模型过于拟和,对于后面的预测不准确
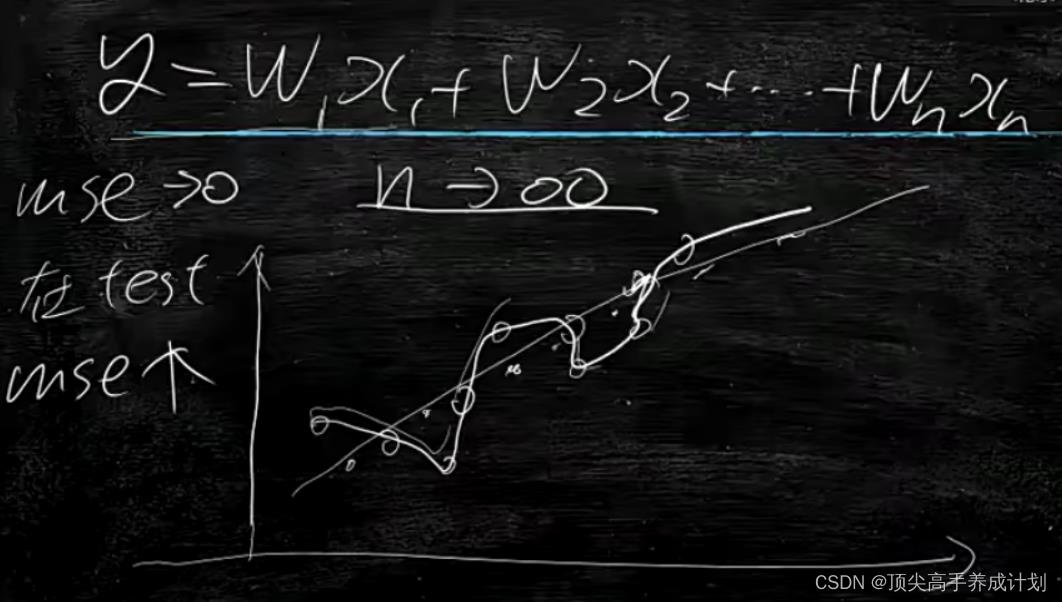 总之使用 线性回归的时候,取的维度适中,不能过拟合,数据也要足够的真实。
总之使用 线性回归的时候,取的维度适中,不能过拟合,数据也要足够的真实。
以上是关于人工智能算法一&线性回归的主要内容,如果未能解决你的问题,请参考以下文章