机器学习初探-线性回归
Posted 凹凸实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习初探-线性回归相关的知识,希望对你有一定的参考价值。
我很早就对人工智能是非常感兴趣的。记得我大学的毕业论文,就是使用遗传算法解决了一个经典的寻路问题。我一直对人类经典的思想是非常敬畏和崇拜的,比如传统的计算机数据结构算法问题,例如经典的排序算法或者动态规划思想,把一些看似复杂的问题竟然用短短十几行甚至一个 for 循环就能解决,这令我感受到了一种美学,也同时对人类的伟大思想而赞叹。
但传统的计算机算法其实还是通过人来编写代码,人来通过完整的、解决问题的思路来解决问题。但如果机器能有自己的思想,如果它自己就能“学习”到解决问题的方法,岂不是非常 cool 的一件事。
但以我目前的认知来看,现在的人工智能是更像是一种工具,一种“数学工具”,一种“统计学工具”, 它是从大量数据里总结出了一种“规律”,用来解决实际问题。它离电脑真正有思想还相距甚远,甚至以目前来看,二者可能并不是一回事。可能让机器具有思维,还需要在其他学科上进行突破比如人的认知机制,脑科学进行突破。哈哈扯远了。
先来介绍自己的一些简单认识。
线性什么是线性?
有一类几何对象,比如直线、平面、立方体,看上去都是有棱有角的,都是“直”的,在数学中称为线性
要处理它们相关的问题就非常简单。比如在高中就学过,两根直线可以用两个线性方程来表示,想求它们交点的话:
联立出两者的方程组,求出该方程组的解就可以得到交点
为什么要研究线性
(1)我们所处的世界、宇宙太复杂了,很多现象都无法理解,更谈不上用数学去描述;
(2)有一些符合特定条件的复杂问题,可以转化为简单的线性问题。线性问题就可以完全被理解,完全可以被数学所描述
回归以我目前的认知来看,机器学习主要的任务有两类。第一就是分类任务,比如

也就是说,分类的结果是,人为预先定义的结果范围里的一种
而第二类任务就是回归任务,而它得出的结果是一个连续数字的值,而非类别。例如
这是我目前的浅显理解。机器学习目前我觉得是一种数学工具。通过喂给机器大量的学习资料,然后机器运行一个机器学习算法,训练出了一个模型。然后再向机器丢入问题,机器通过这个模型运算得出结果。
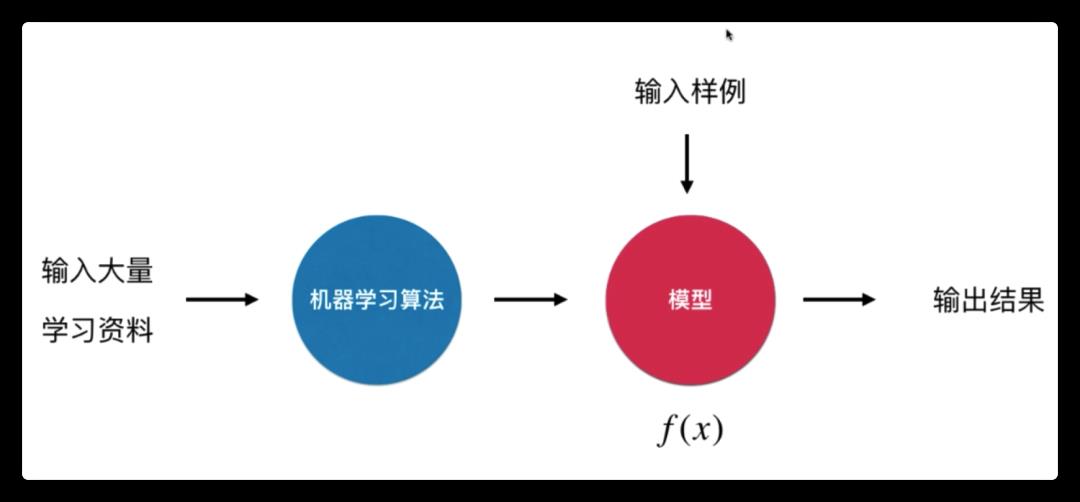
比如我收集到了有 x, y 的两组数据(比如年龄和身高),我想要知道这两组变量是否有线性关系。那么我先以一个变量为 x 轴,另一个变量为 y 轴画出这样一副散点图。
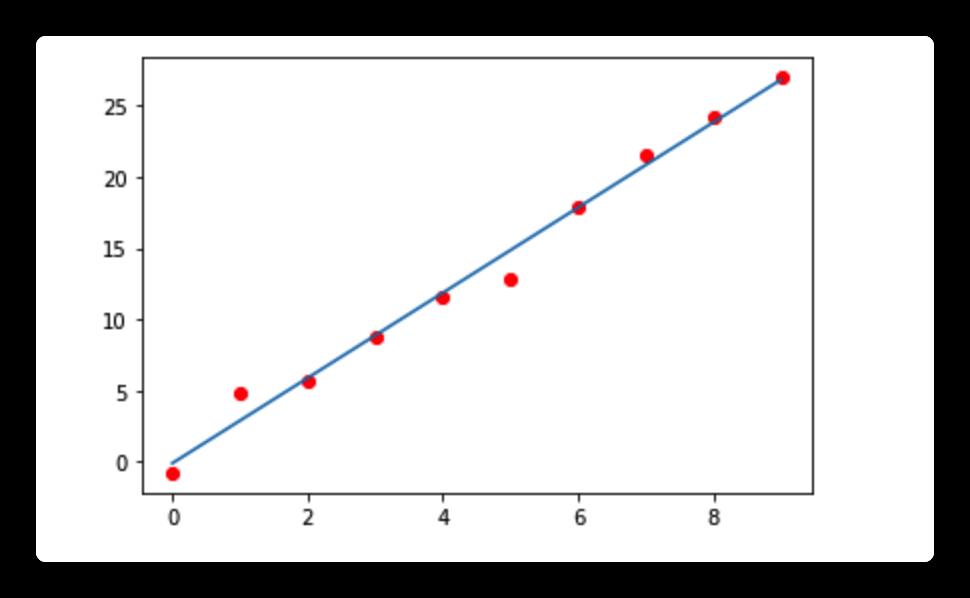
那么我就可以找出这样的一条直线。这条直线的特征是:尽可能的离所有离散点最近,也可以表述成,每个离散点离直线距离的差值之和最小。那么我就可以很好的根据我算出的这条直线,由已知的 x 值,来预测的未知的 y 值。假如说 x, y 有线性关系的话,那么预测的效果还是很不错的。所以线性回归的主要任务是,找出这条直线。
单变量线性回归我们先从单变量线性回归开始理解,即假设 x 只有一个特征(比如一氧化氮浓度),y 是房价。根据前文提到的感性理解,我们的目标就是找到最佳的直线方程:
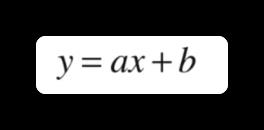
其实就是求参数 a 和 b 的过程。那其实我们的目标就是,使得根据每一个 x 点,使得
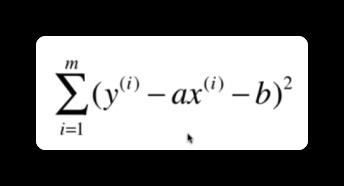
https://www.zhihu.com/question/24095027。
所以一类机器学习算法的基本思路是:通过确定问题的损失函数,然后最优化损失函数,来获得机器学习的模型。怎么求得这个损失函数的最小值,即求 a 和 b 的值。则需要对 a 和 b 分别进行求导。导数为 0 的点则为极值点。现在我们对 a 进行求导(复合函数的链式求导法则):
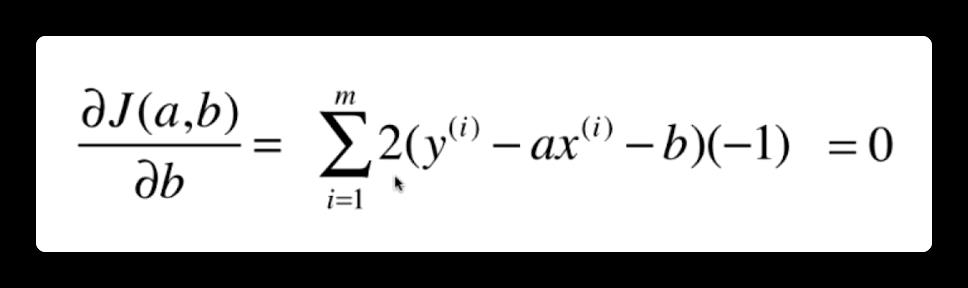
化简一下:

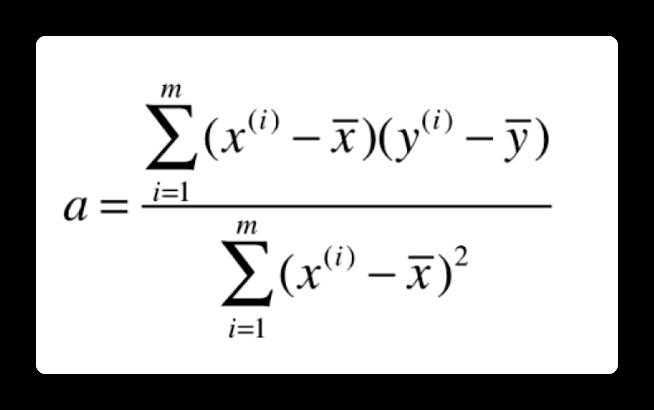
然后 python 实现一下:简单来说我需要定义两个方法。
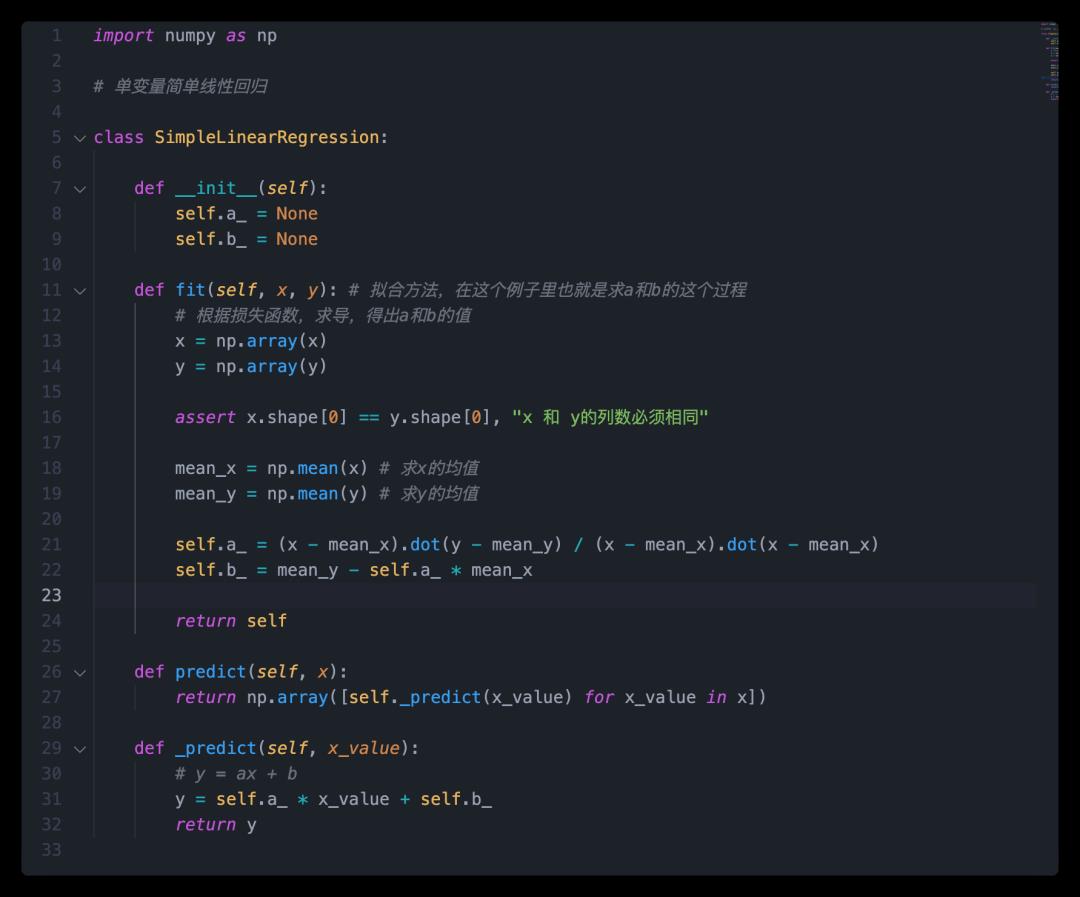
这里需要注意一下:这里采用了向量化代替了循环去求 a。我们看到,a 的分子分母实际上用循环也可以求, 但是实际上,a 的分子分母其实可以看成向量的点乘(即向量 a 里的每一个分量乘以向量 b 里的每一个分量)。这样做有两个好处:
当把这个 a 和 b 的参数求出之后,我们就得出了一个模型(在这个例子中是 y=ax+b),然后我们就可以进行预测了,把 x 带入这个方程中,就可以得出预测后的这个 y 值。
多元线性回归理解了单变量线性回归之后,我们就开始需要解决,当特征为多个的时候,怎么进行预测?也就是多元线性回归。我们可以理解一下,多元线性回归实际要求的是这样的一个方程
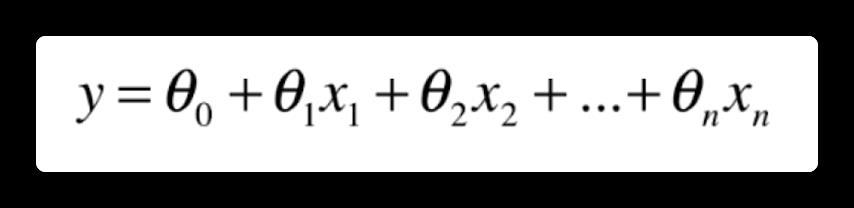
即每一个特征前面都有一个常数系数,再加一个常数(截距)。这里我们把这些系数整理成一个(列)向量
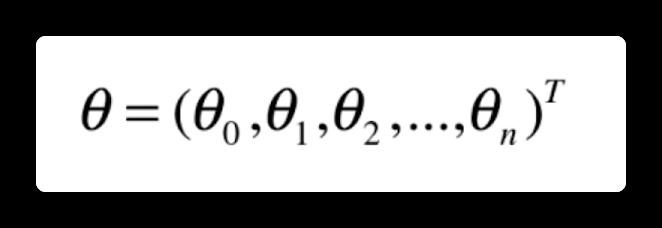
然后我们为了方便起见,设置一个 x0, x0 恒等于 1,那么我们最终就化简成了下面两个向量的点乘
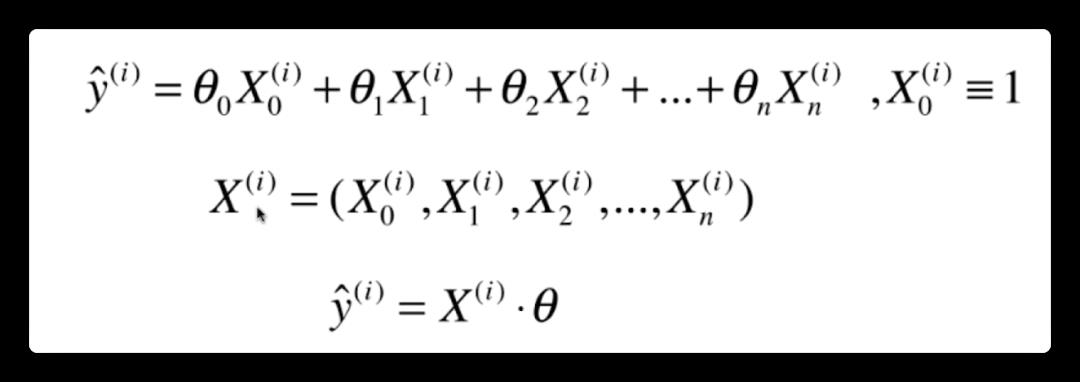
然后把所有的 x 向量(样本)组合成一个矩阵,将 theta 整理成一个列向量。那么 y(向量)就是所有 x 向量的预测值。这里用到了矩阵和向量的乘法(哈哈忘了的话得复习一下线性代数)。

那么根据最小二乘法,我们的目标就是使得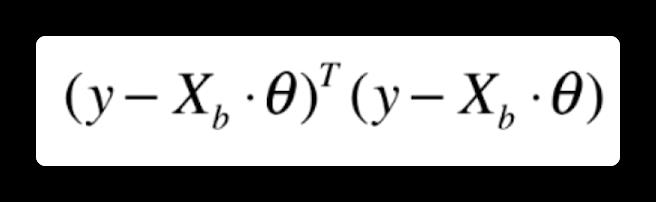
最小。也就是要对整个矩阵进行求导,具体推导过程省略,这里给出最终 theta 的解:
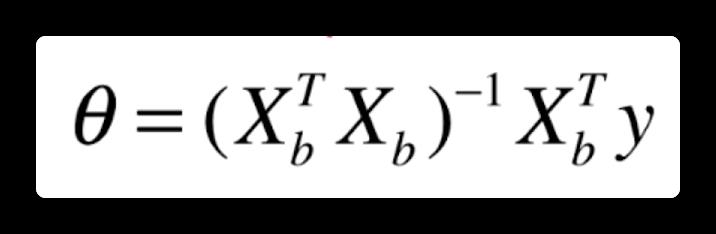
也就是我们通过数学推导,直接求出了参数的数学解,然而一般而言,能够直接得出参数数学解的机器学习方法还是比较少的,有可能还需要借助其他方法比如梯度下降才能够求出参数。
多元线性回归的实现
接下来根据这个数学解进行实现。
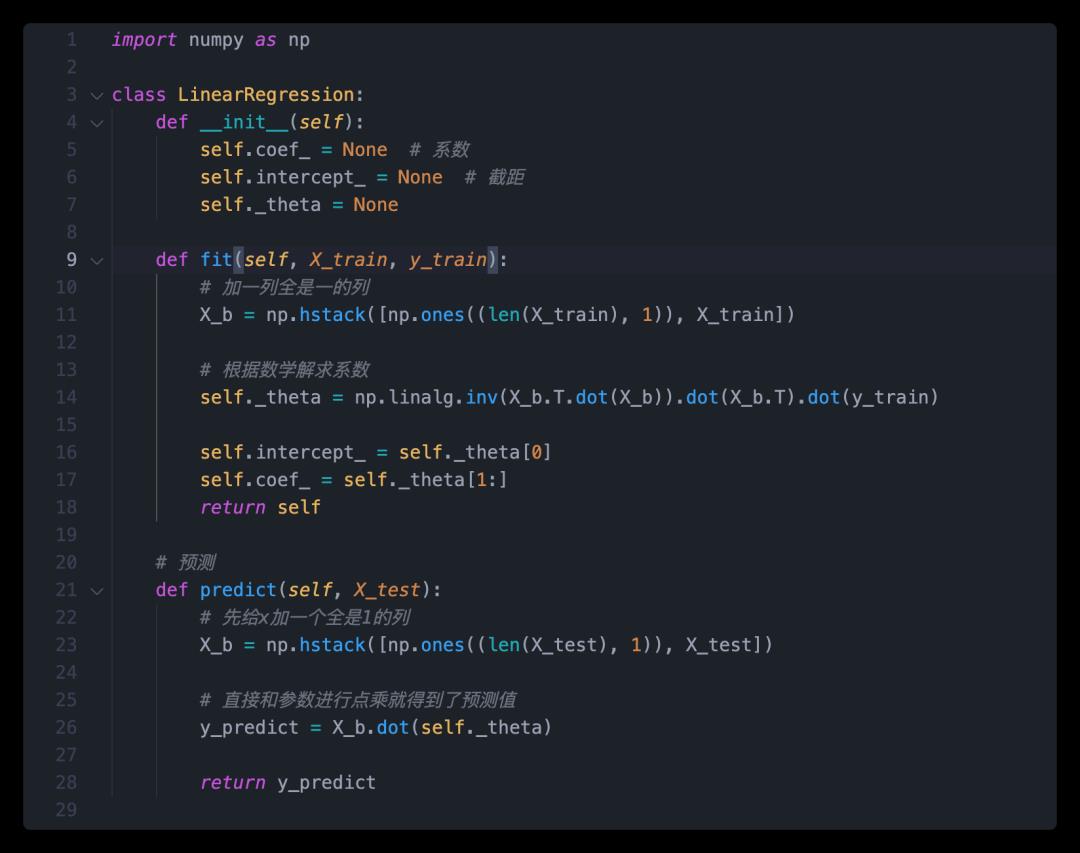
这个波士顿房价数据集是 sklearn(一个机器学习框架)自带的数据集
其实我看到这个数据集时也懵了,这个例子是带我们预测房价吗?预测明天深圳的房价?我觉得是可以这样理解,通过收集一些特征(学习资料)如下图和波士顿某些地区的平均房价(目标结论),来推测出你或者房地产商卖房子时应该怎么定价比较划算。或者说通过这个数据集来理解,哪个因素对于房价影响更大。
数据介绍
该数据集包含马萨诸塞州波士顿郊区的房屋信息数据,来自 UCI 机器学习知识库(数据集已下线),于 1978 年开始统计,包括 506 个样本,每个样本包括 12 个特征变量和该地区的平均房价。
字段含义
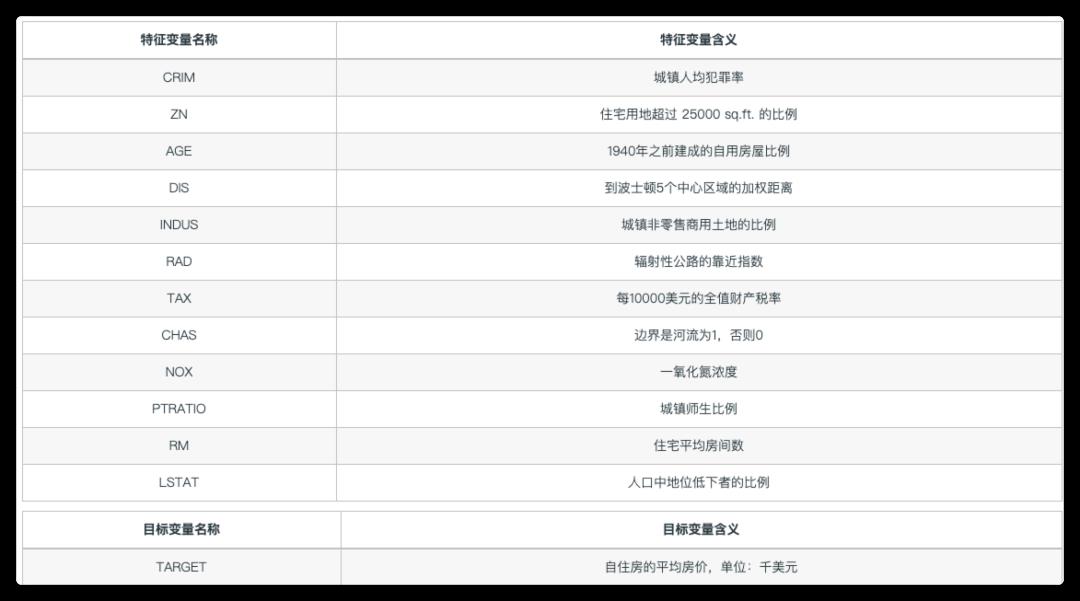
可以看到,研究者希望找出影响房价的重要因素,比如环境因素(一氧化氮浓度),位置因素(到波士顿 5 个中心区域的加权距离)等等(不过我相信影响中国房价因素要比这复杂的多)
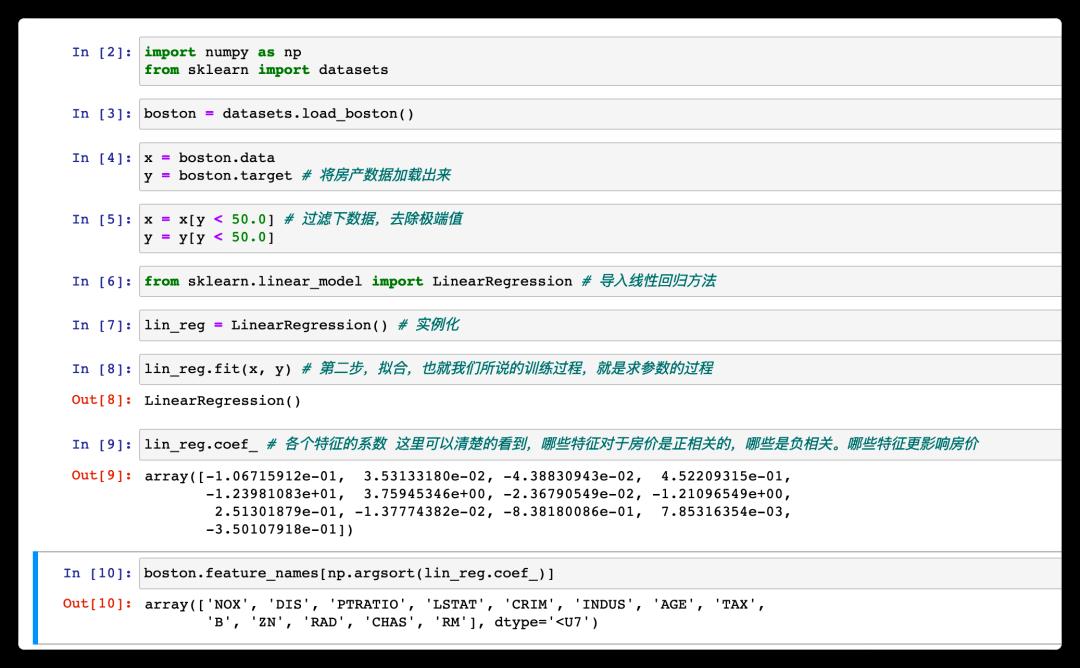
经过求解得出了(或者说学习到了)各个参数的值,然后如果地产商想要定价的话,可以收集这些特征,然后使用模型的 predict 方法可以得出一个房价的参考值。
然后我们也可以看到,哪些因素对于房价是正相关的,哪些是负相关的。然后参数越大,越影响房价,这就是线性回归法对于结果的可解释性(有些机器学习方法是不支持的)。
机器学习:线性模型学习总结:线性回归
基于周志华老师的《机器学习》、上一篇学习笔记以及网络的其他资料,对线性模型的这一部分内容进行一个总结。
学习时间:2022.04.17~2022.04.18
文章目录
0. 数据预处理
尝试构建了一个可以通用处理的数据预处理函数(不能处理文本和时间数据,因为要具体情况具体分析)。
column_lists = list(df) # 获取所有的列名
bool_cos = [] # 获取所有的布尔类型列
classify_cos = [] # 获取所有的分类数据列
number_cos = [] # 获取所有的数据类型列
date_cos = [] # 获取所有的时间类型列
for i in column_lists:
if df[i].dtypes == 'bool':
bool_cos.append(i)
elif df[i].dtypes == 'object':
classify_cos.append(i)
elif str(df[i].dtypes) == 'datetime':
date_cos.append(i)
else:
number_cos.append(i)
# 缺失值添加是否缺失的特征列
for i in column_lists:
if df[i].isnull().any(): # 判断是否有缺失值
# 或者用if np.any(df[i].isnull()):
new_column = str(i + '_ifNaN') # 设置新列名
df[new_column] = df.apply(lambda df: 1 if df[i] == np.NaN else 0, axis=1)
# 对于分类型数据,使用众数填充
for i in classify_cos:
df[i] = df[i].fillna(df[i].mode()[0])
# 对于数值型数据,使用均值填充,并进行标准化(归一化的应用场景有限,可能会将数据的间距缩小)
for i in number_cos:
df[i].fillna(df[i].mean(), inplace=True)
def stand_sca(data):
data_standard = (data-data.mean())/data.std()
return data_standard
df[i] = stand_sca(df[i])
# 对于bool类型数据,使用众数填充,并转换成0和1
for i in bool_cos:
df[i].fillna(df[i].mode(), inplace=True)
df[i] = df[i].astype('int')
df = pd.get_dummies(df)
1. 用SK-Learn做线性回归模型
1.1 线性回归
sklearn.linear_model.LinearRegression
1.2 随机梯度下降执行线性回归
sklearn.linear_model.SGDRegressor
可能需要调整的参数:
-
loss损失函数:要使用的损失函数。loss=“squared_error”:平方误差损失函数,普通最小二乘;“loss=huber”:增强平方误差损失函数对离群点的鲁棒性;“loss=epsilon_insensitive”:标准SVR的损失函数,是L1损耗;“loss=squared_epsilon_insensitive”:epsilon_insensitive的平方,是L2损耗。
-
penalty正则化方法:默认为“ l 2 l2 l2”。- 有’ l 2 l2 l2’, ‘ l 1 l1 l1’, ' e l a s t i c n e t elasticnet elasticnet'三种,分别对应岭回归、Lasso回归、弹性回归。
-
alpha:使正则化项相乘的常量,值越高,正则化越强(仅针对’ l 2 l2 l2’, ‘ l 1 l1 l1’)。默认值为 0.0001。 -
l1_ratio:弹性回归参数,[0,1]。确定’ l 2 l2 l2'和 ' l 1 l1 l1'的比率r,仅当是“弹性网”时才使用。默认0.15。 -
max_iter最大迭代次数:默认=1000。 -
tol停止的容差标准:如果不是None,则在连续的epoch (loss > best_loss - tol)时停止训练。默认=1e-3。 -
epsilon敏感阈值:仅当为’ huber ‘、’ epsilon_insensitive ‘或’ squared_epsilon_insensitive '时。它决定了一个阈值,如果当前预测和正确标签之间的任何差异小于此阈值,则忽略它们。默认为0.1。 -
learning_rate:学习率模式:默认default=‘invsscaleing’。‘constant’: 常量。eta = eta0‘optimal':最优。eta = 1.0 / (alpha * (t + t0))‘invscaling’:内扩。eta = eta0 / pow(t, power_t)power_t默认=0.1。
‘adaptive’:自适应。eta = eta0,但每次连续的 epoch 无法按tol减少训练损失或未能按 tol 提高验证分数 early_stopping时,当前学习速率除以 5。
-
eta0初始学习率。默认eta0=0.01。 -
early_stopping:当验证分数没有提高时,是否使用提前停止来终止训练。默认值 = False。validation_fraction:要留出的训练数据的比例,用于早期停止的验证集。默认值 = 0.1。
创建模板:
from sklearn.linear_model import SGDRegressor
# 实例化模型
SGDRegressor = SGDRegressor(loss='squared_error', penalty='l2', alpha=0.0001, max_iter=1000, tol=1e-3, eta0=0.01)
# 训练模型
SGDRegressor.fit(train_x, train_y)
# 模型预测
train_result = SGDRegressor.predict(train_x)
1.3 多项式回归
sklearn.preprocessing.PolynomialFeatures
可能需要调整的参数:
degree:如果给定一个整数,它指定多项式特征的最大度。如果传递了一个元组(min_degree, max_degree),则min_degree是生成的特征的最小多项式度,max_degree是最大多项式度。注意min_degree=0和min_degree=1是等价的,因为输出的0度项是由include_bias决定的。默认default=2。
在使用PolynomialFeatures()函数后,再使用线性回归,即是多项式回归,PolynomialFeatures()只是一个数据预处理过程。
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(6).reshape(3, 2)
print(X)
'''
array([[0, 1],
[2, 3],
[4, 5]])
'''
poly = PolynomialFeatures(2)
print(poly.fit_transform(X))
'''
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
'''
poly = PolynomialFeatures(interaction_only=True)
print(poly.fit_transform(X))
'''
array([[ 1., 0., 1., 0.],
[ 1., 2., 3., 6.],
[ 1., 4., 5., 20.]])
'''
1.4 逻辑回归
用于分类:sklearn.linear_model.LogisticRegression
penalty正则化方法:默认为“ l 2 l2 l2”。- 有’ l 2 l2 l2’, ‘ l 1 l1 l1’, ' e l a s t i c n e t elasticnet elasticnet'三种,分别对应岭回归、Lasso回归、弹性回归。
l1_ratio:弹性回归参数,[0,1]。确定’ l 2 l2 l2'和 ' l 1 l1 l1'的比率r,仅当是“弹性网”时才使用。默认=None。tol停止的容差标准:如果不是None,则在连续的epoch (loss > best_loss - tol)时停止训练。默认=1e-4。C正则强度的倒数:与支持向量机一样,较小的值指定更强的正则化。default=1.0。solver:用于优化问题的算法。‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’, 默认=’lbfgs’。‘newton-cg’:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。‘lbfgs’:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。‘liblinear’:不支持设置penalty='none';L1正则化,多用于二分类。‘sag’:要求数据进行缩放处理。支持L2正则化。随机平均梯度下降,是梯度下降法的变种。- ⭐
‘saga’:要求数据进行缩放处理。支持L1、L2和弹性正则化。
max_iter:最大迭代次数,默认=100。multi_class:分类法类型,默认default=’auto’。‘auto’:自动判断。‘ovr’:每个标签都看做二分类问题。‘multinomial’:Softmax算法,多分类,即使数据是二分类的,损失最小是多项式损失拟合整个概率分布。(当solver =‘liblinear’ 时, ‘multinomial’ 不可用)。
可见:机器学习:线性模型学习总结(2)。
2. 用SK-Learn评价回归模型
2.1 回归模型的评价指标
没有交叉验证的评价指标输出函数:
MSE = mean_squared_error(true_value, pred_value)
print("均方误差MSE:", MSE, end=';\\t')
RMSE = np.sqrt(mean_squared_error(true_value, pred_value))
print("均方根误差RMSE:", RMSE, end=';\\t')
MAE = mean_absolute_error(true_value, pred_value)
print("平均绝对误差MAE:", MAE, end=';\\t')
R2 = r2_score(true_value, pred_value)
print("决定系数R-Square:", R2, end=';\\t')
MAPE = mean_absolute_percentage_error(true_value, pred_value)
print("平均绝对百分比误差MAPE:", MAPE, end=';\\t')
EVS = explained_variance_score(true_value, pred_value)
print("可解释方差:", EVS, end='。')
2.2 交叉验证的评价指标
sklearn.model_selection.cross_val_score
需要定义的参数:
-
estimator:需要使用交叉验证的算法,即传入自己定义的模型。 -
X:传入数据集。 -
y:传入标签。 -
scoring:选择评价指标。回归模型默认R2,分类模型默认accuracy。default=None。- 其他支持的评分指标如下:
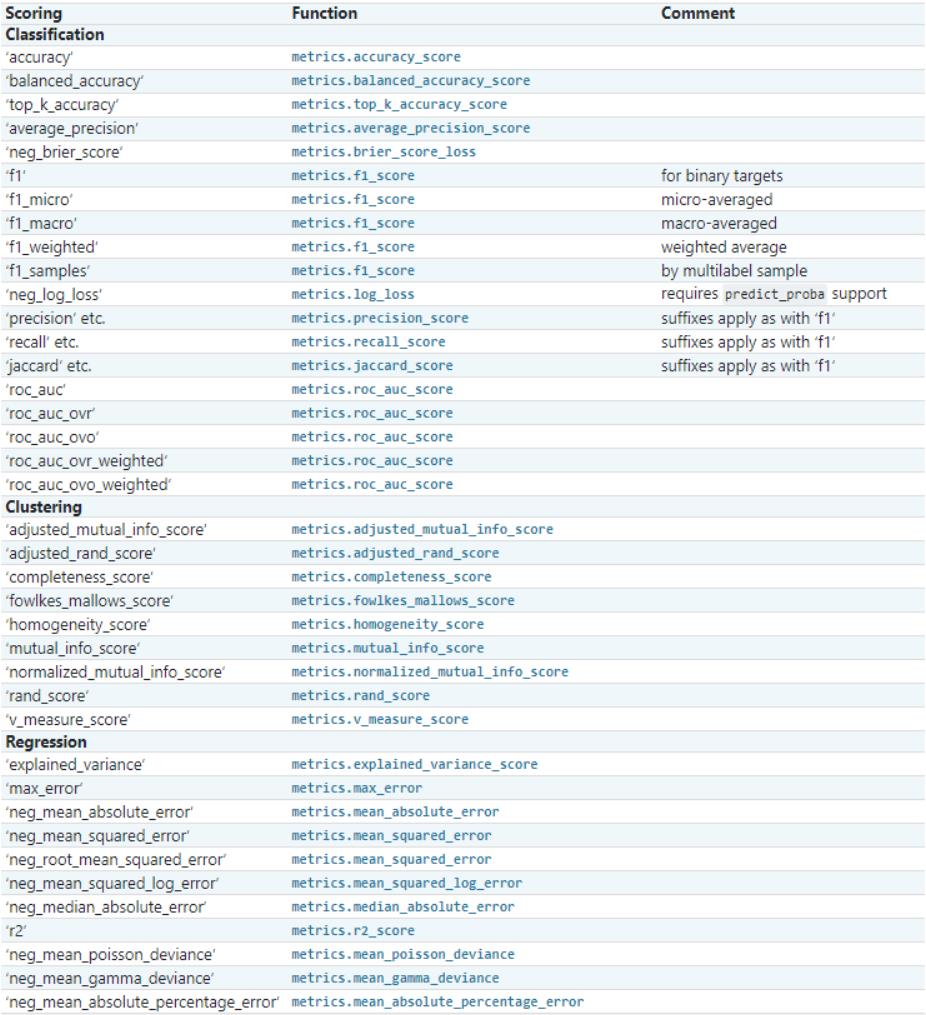
-
cv:交叉验证折数或可迭代的次数。default=None。None:使用默认的5倍交叉验证;int:指定(Stratified)KFold中的折叠次数;- An iterable that generates (train, test) splits as arrays of indices.
-
n_jobs:同时工作的cpu个数(-1代表全部)。default=None。 -
pre_dispatch:控制并行执行期间调度的作业数量。减少这个数量对于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。default=’2*n_jobs’。该参数可以是:None:在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟;- An
int:一个int,给出所产生的总工作的确切数量; - A
str:给出一个表达式作为n_jobs的函数,如’2 * n_jobs。
# 计算交叉验证的MSE
MSE = cross_val_score(model, test_x, test_y, scoring='neg_mean_squared_error', cv=10)
print('均方误差MSE:', -MSE)
# 计算交叉验证的RMSE
RMSE = np.mean(np.sqrt(np.abs(MSE)))
# 计算交叉验证的R2
R2 = cross_val_score(model, test_x, test_y, scoring='r2', cv=10)
print("决定系数R-Square:", R2)
print('平均MSE:', np.mean(MSE), "; 平均RMSE:", RMSE, "; 平均R2:", np.mean(R2))
2.3 过拟合与欠拟合
如果模型在训练数据上表现良好,但根据交叉验证的指标泛化较差,则你的模型过拟合。
- 在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值。
- 选取合适的停止训练标准,使对机器的训练在合适的程度;
- 保留验证数据集,对训练成果进行验证;
- 获取额外数据进行交叉验证;
- 正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
如果两者的表现均不理想,则说明欠拟合。
- 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间;
- 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强;
- 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数;
- 使用非线性模型,比如核SVM 、决策树、深度学习等模型;
- 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力;
- 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging。
3. 用Sklearn进行网格搜索
sklearn.model_selection.GridSearchCV
可能需要的参数:
estimator:参数针对的搜索对象,即要调参的模型。param_grid:超参的集合,本质上是一个列表,每个元素代表一组搜索(是一个字典),每个字典中的key是本次一次性要搜索的超参名字,对应的value是一个列表,描述搜索范围,其每个元素是相应的搜索取值。scoring:用于评估测试集上交叉验证模型性能的策略。可接受的评价指标可见上图。一个指标即传入字符串;多个指标传入列表。默认是None。refit:在多个score的情况下,模型在进行选择的时候,需要明确的scoring依据。
n_jobs:与并行运行相关,即可以提高搜索速度,取值为整数,默认为1,大于1的整数表示运行核数(但不能超过运行主机有的核数),取-1代表使用主机所有的核数。默认是None。cv:交叉验证的折数。默认是None,即5折。return_train_score:应该是控制是否返回得分。默认是False。
使用:
.fit:进行具体的搜索,且会返回搜索器实例本身信息;.best_estimator_:可以查看带有最优超参的搜索器的相关信息;.best_score_:可以查看当前最优超参情况下的得分;.best_params_:可以输出当前由最优的超参及其取值组成的字典。
# 引入网格搜索,找到最优模型
from sklearn.model_selection import GridSearchCV
SGDReg = SGDRegressor()
params = [
'loss': ['squared_error'], 'penalty': ['l1', 'l2'], 'max_iter': [1000, 10000, 30000], # 第一组参数及其可选择的值
'loss': ['epsilon_insensitive'], 'penalty': ['l1', 'l2'], 'max_iter': [1000, 10000, 30000] # 第二组参数及其可选择的值
] # 根据所要搜索的模型,调整需要搜索的参数
scores = ['r2', 'neg_mean_squared_error']
best_SGDReg = GridSearchCV(SGDReg, param_grid=params, n_jobs=-1, scoring=scores, refit='neg_mean_squared_error')
best_SGDReg.fit(train_x, train_y)
4. 完整代码
完整代码如下:
import pandas as pd
from Data_processing_by_Pandas import mango_processing
from Regression_Model_evaluation import regression_evaluation_without_cross
from Regression_Model_evaluation import regression_evaluation_with_cross
# 读取数据
train = pd.read_csv('train.csv', nrows=50000)
print(train.describe())
train_target = train['fare_amount']
train_feature_before = train.drop(['key', 'fare_amount', 'pickup_datetime'], axis=1)
# 进行数据处理
train_feature = mango_processing(train_feature_before)
# 划分训练集与测试集
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(train_feature, train_target, test_size=0.2, random_state=42)
# 引入网格搜索,找到最优模型
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import SGDRegressor
SGDReg = SGDRegressor()
params = [
'loss': ['squared_error'], 'penalty': ['l1', 'l2'], 'max_iter': [1000, 10000, 30000], # 第一组参数及其可选择的值
'loss': ['epsilon_insensitive'], 'penalty': ['l1', 'l2'], 'max_iter': [1000, 10000, 30000] # 第二组参数及其可选择的值
] # 根据所要搜索的模型,调整需要搜索的参数
scores = ['r2', 'neg_mean_squared_error']
best_SGDReg = GridSearchCV(SGDReg, param_grid=params, n_jobs=-1, scoring=scores, refit='neg_mean_squared_error')
# 进行网格搜索
best_SGDReg.fit(train_x, train_y)
# 得到相关参数:
print(best_SGDReg.best_score_)
print(best_SGDReg.best_params_)
# 模型训练及预测:
# 将最优模型传入fare_SGD
fare_SGD = best_SGDReg.best_estimator_
fare_SGD.fit(train_x, train_y)
# 模型预测
train_result = fare_SGD.predict(train_x)
# 训练集预测结果评价(个人构建的模型,见上)
regression_evaluation_without_cross(train_y, train_result)
# 测试集交叉验证评价(个人构建的模型,见上)
regression_evaluation_with_cross(fare_SGD, train_x, train_y)
以上是关于机器学习初探-线性回归的主要内容,如果未能解决你的问题,请参考以下文章