微软数据挖掘算法:Microsoft 线性回归分析算法(11)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微软数据挖掘算法:Microsoft 线性回归分析算法(11)相关的知识,希望对你有一定的参考价值。
前言
此篇为微软系列挖掘算法的最后一篇了,完整该篇之后,微软在商业智能这块提供的一系列挖掘算法我们就算总结完成了,在此系列中涵盖了微软在商业智能(BI)模块系统所能提供的所有挖掘算法,当然此框架完全可以自己扩充,可以自定义挖掘算法,不过目前此系列中还不涉及,只涉及微软提供的算法,当然这些算法已经基本涵盖大部分的商业数据挖掘的应用场景,也就是说熟练了这些算法大部分的应用场景都能游刃有余的解决,每篇算法总结包含:算法原理、算法特点、应用场景以及具体的操作详细步骤。为了方便阅读,我还特定整理一篇目录:大数据时代:深入浅出微软数据挖掘算法总结连载,有兴趣的可以点击参阅。
本篇介绍的为Microsoft线性回归分析算法,此算法其实原理和Microsoft神经网络分析算法一样,只是侧重点不一样,Microsoft神经网络算法是基于某种目的,利用现有数据进行“诱探”分析,侧重点是分析,而Microsoft线性回归分析算法侧重的是“预测”,也就是基于神经网络分析出来的规则,进行结果的预测。
应用场景介绍
该算法的应用场景和上一篇的Microsoft神经网络分析算法一样,不清楚的可以点击查看,可以简单列举:
- 营销和促销分析,如评估直接邮件促销或一个电台广告活动的成功情况。
-
根据历史数据预测股票升降、汇率浮动或其他频繁变动的金融信息。
-
分析制造和工业流程。
-
文本挖掘。
-
分析多个输入和相对较少的输出之间的复杂关系的任何预测模型。
其实该算法为Microsoft神经网络分析算法的补充算法,上一篇我们已经介绍了,当我们面对一堆的数据而要基于某种目的去数据挖掘时,感觉到无从下手或者在DM中选择不到合适的算法的时候,这时候我们会应用到Microsoft神经网络分析算法,当我们用Microsoft神经网络分析算法分析出规则的时候,我们就的利用Microsoft线性回归分析算法进行结果预测了。
技术准备
(1)微软案例数据仓库(AdventureWorksDW208R2),案例数据仓库中的呼叫中心的数据表,和上一篇的Microsoft神经网络分析算法用到的是同一张事实表FactCallCenter,详细可参阅上篇。
(2)VS2008、SQL Server、 Analysis Services。
挖掘目的
上一篇我们已经利用Microsoft神经网络分析算法对微软案例数据库中的呼叫中心数据进行了简要的分析,通过分析其实我们知道了影响“挂断率”这个指标的因素最主要的是两个:第一个是应答平均时间(AverageTimePerIssue),第二个就是上班阶段(Shift),并且推断深夜上班挂断率低等规则吧,本篇我们将利用这些规则来做挖掘。
两个目标:
1、根据规则发掘出平均应答时间调整到多少最好,或者基于目标,比如要求挂断率控制在0.05以内,应答时间应该控制在多少合适。
2、如何安排岗位时间及岗位人数最佳,比如:安排几班岗位,每个岗位安排多少人,然后什么时间上班最好。
操作步骤
(1)我们这里还是利用上一期的解决方案,直接打开,看图:
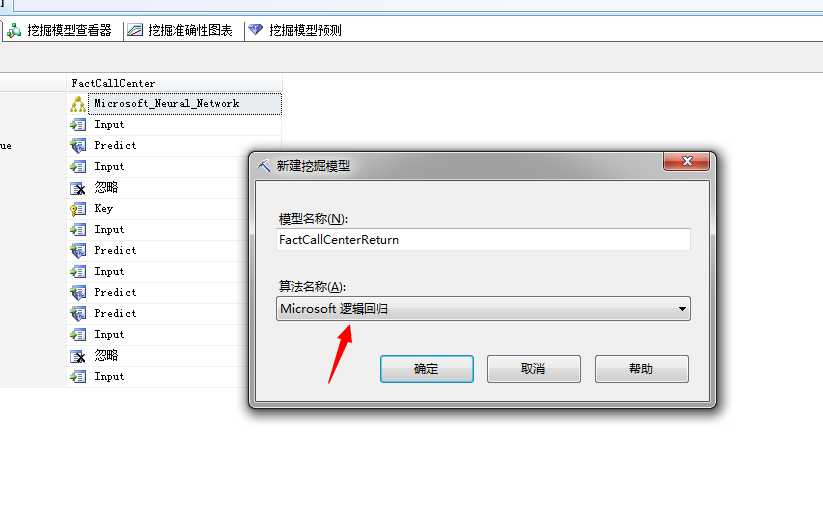
我们来新添加Microsoft路逻辑回归算法,在挖掘模型面板中,右键添加新的算法,不明白的可以参考我前几篇文章
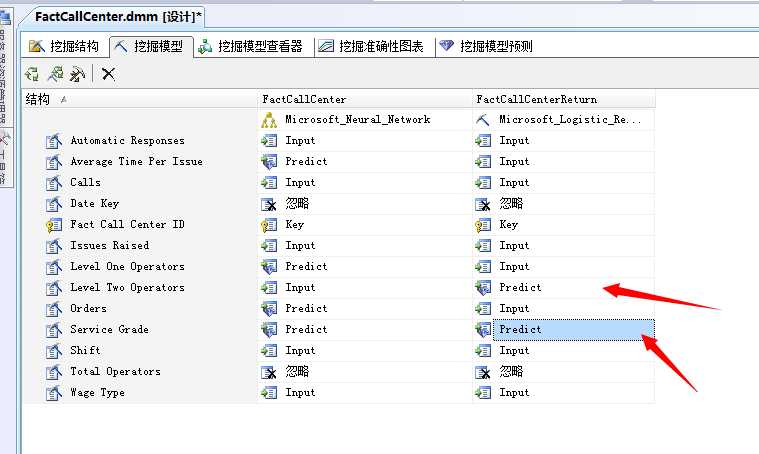
我们来设置输入和预测属性值,默认的和前面的Microsoft神经网络属性值一样,因为我们要预测“挂断率”和岗位人数,我们这里选择ServiceGrade和Level Two Operators设置为“预测”,这里VS会为这两个元数据容器创建两个单独的模型。也就是说这个算法回味每一组可预测属性创建一个单独的子树。
其它列我们都更改为“输入”。
我们来部署该挖掘模型,然后运行,下一步我们就是要浏览数据。
(2)部署程序,创建挖掘
在部署完程序后,然后点击运行按钮,这里我们可以看到“挖掘模型查看器”,该算法的浏览器展示的内容和Microsoft神经网络算法是一样的,这里就不废话介绍了,不懂的可以参考我上篇文章。
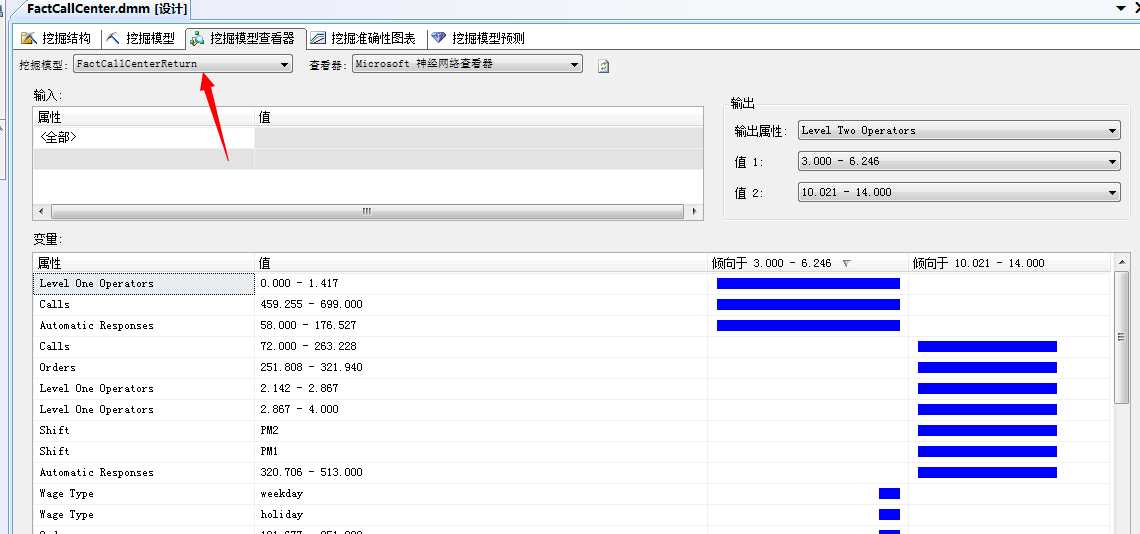
所以说该算法和Microsoft神经网络算法是一样的,这里面如果真的去对比的话,其实Microsoft逻辑回归算法是基于目的进行设计的,就是说它比起神经网络算法的话,它是带着目标去进行逻辑传递的,这一点有点像Microsoft决策树算法和贝叶斯算法的关系一样。
不废话,我们接着进行我们的挖掘
我们直接进入“挖掘模型规则”
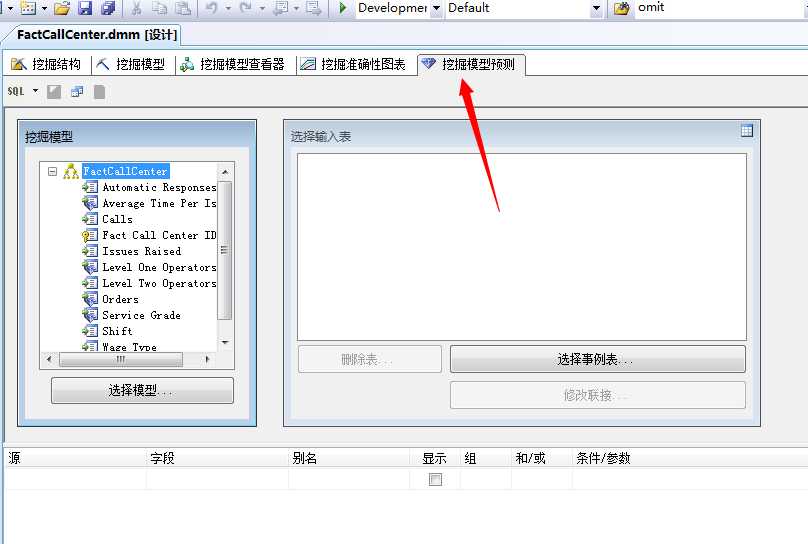
我们这里选择好“挖掘模型”,然后在挖掘模型中选择“单独查询”
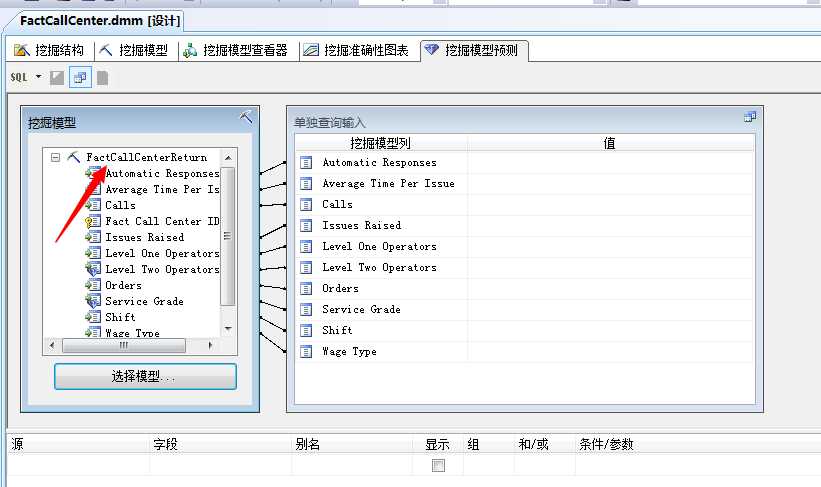
这里我们选择上一篇神经网络发现的规则,换班时间(Shift)选择:夜晚(midnight),嘿嘿...然后第二班的人数我们输入个人数,我们假定有6个人
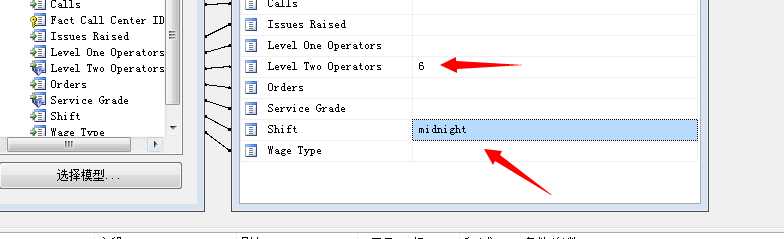
我们在“源”里选择“预测函数”,“字段”选择PredictHistogram,然后将 ServiceGrade拖入“条件/参数”

点击运行,就可以看到这种规则下的,预测的“挂断率”是多少了,6个人上夜班
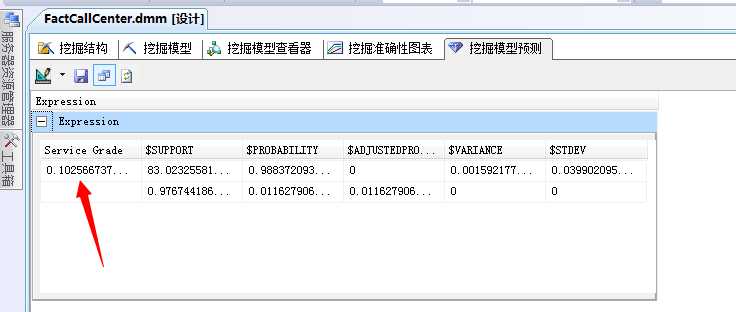
嘿嘿...结果出来了..0.102566737...结果还可以嘛...表示100人打进电话才有10个人挂断。后面的值是一些数据支撑,比如事例数,可能性等
这种预测是比较单一,我们不能一个个的人数去试验,其实基于这种模型我们还可以进行更深度的挖掘,比如当前我们的呼叫中心人数、上班的次序已经是固定的,我们可以根据这个现有数据进行预测,预测出下一步将如何调整:
我们这样干:
首先我们根据现有表中的数据建立一个可用于预测的数据行,我们按照上班轮次,是否节假日进行分组,取出每个轮次的平均人数、平均电话数等...我们可以利用这个语句:
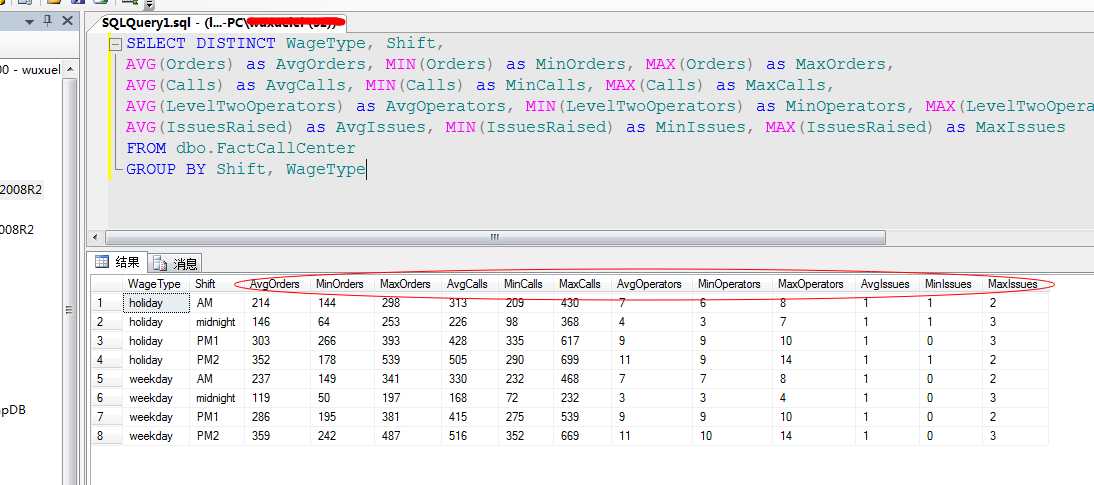
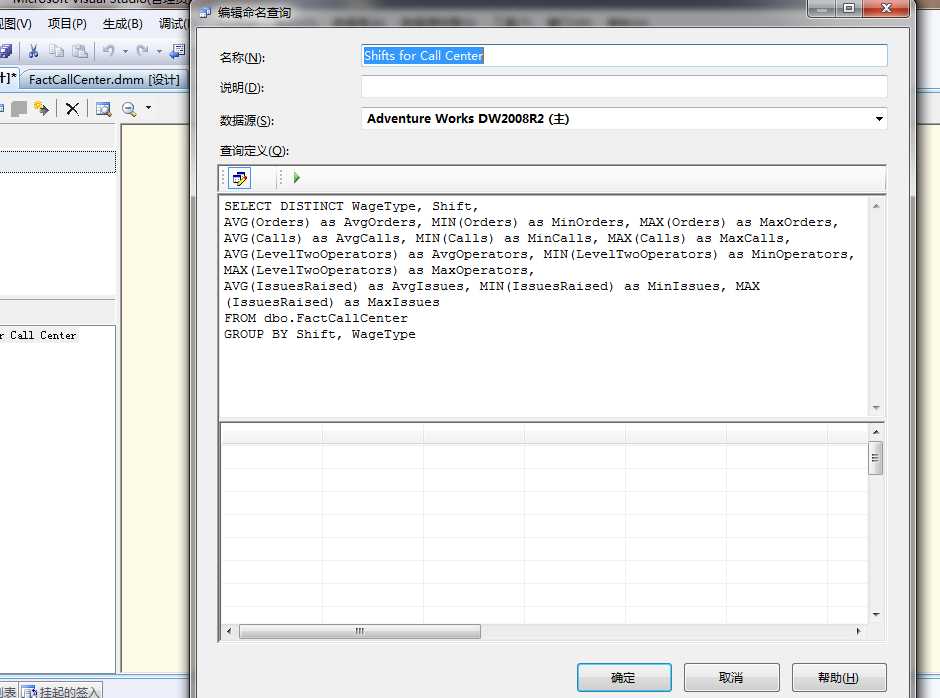
我们这里把最大值和最小值页进行筛选,以便于后续的挖掘。我们将这个语句改成VS中的数据源视图中的:命名查询
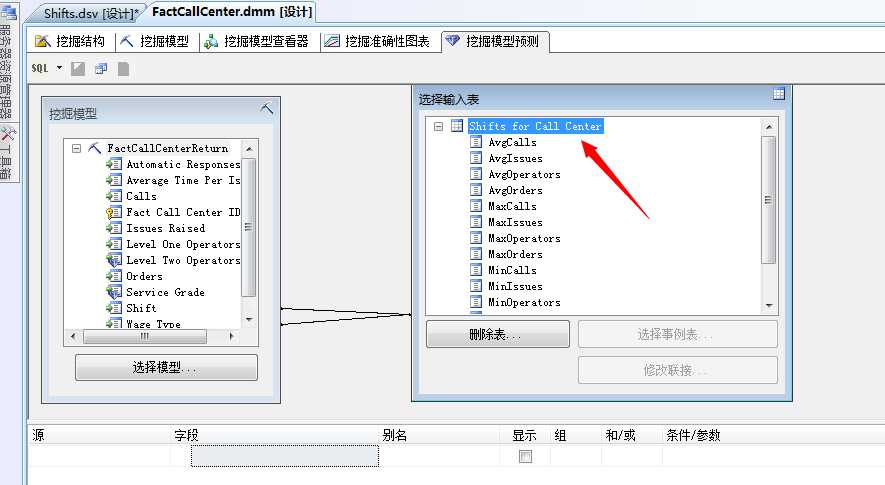
我们进去到挖掘面板中,选择该事例表
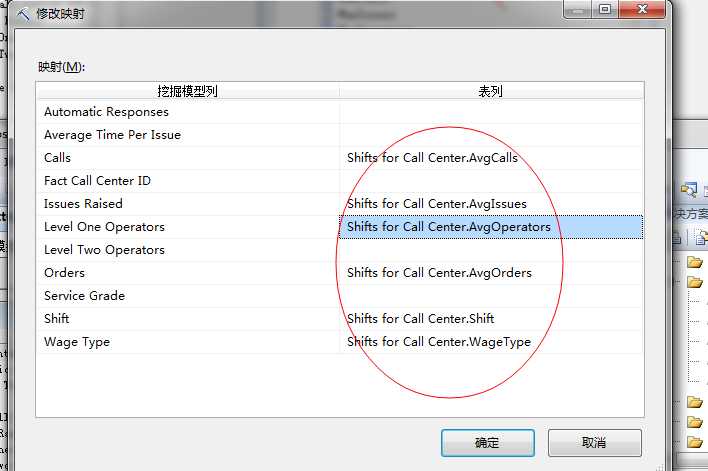
然后编辑好管理关系,将包含 Calls 列、Orders 列、Issues 列和 LvlTwoOperators 列映射到平均值。
我们设计一下预测函数
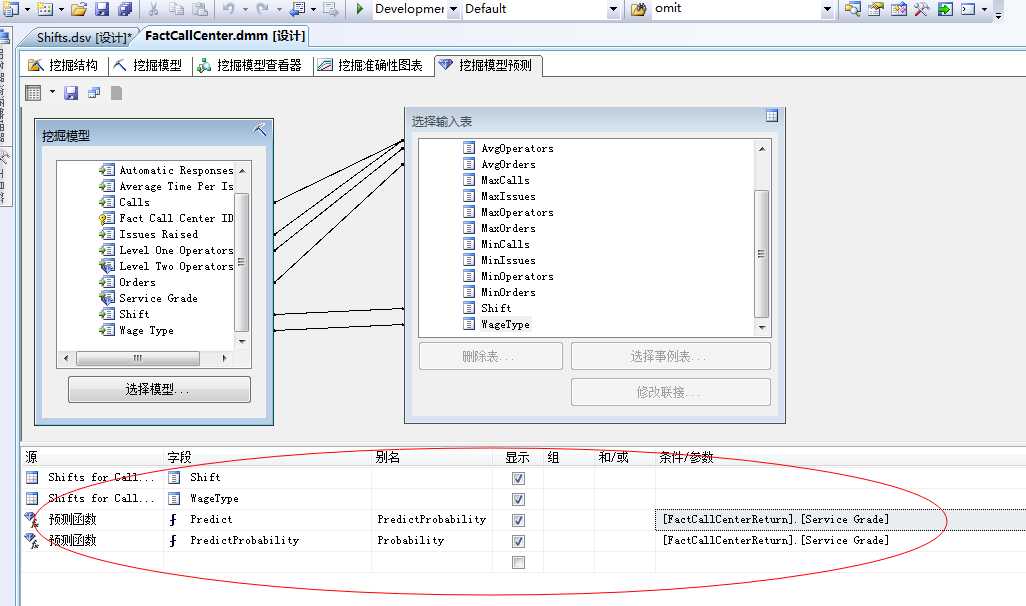
点击运行,我们可以看到预测的明细结果:
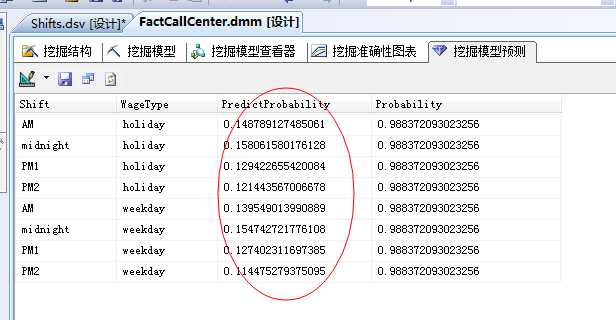
上面的分析结果可以看到,在holiday(节假日)的midnight(晚间)的挂断率是最高的:0.158,而在PM2(下午第二档)的weekday(工作日)日的挂断率是最低的:0.1144
但是这些值或许还不是我们所期望的,比如老总发话了,要将挂断率保持在0.1以下,该如何调整呢,其实基于上一篇我们神经网络算法已经分析出来,平均应答率这个因素对于挂断率这个指标影响是非常大的,我们可以通过调整这个值来减小挂断率这个值的大小,提高服务水平,比如我们可以减少%90或者80%的平均应答时间,我们来预测以下这样产生的挂断率的值为多少。
我们调整上面的数据源视图的语句,增加两项:
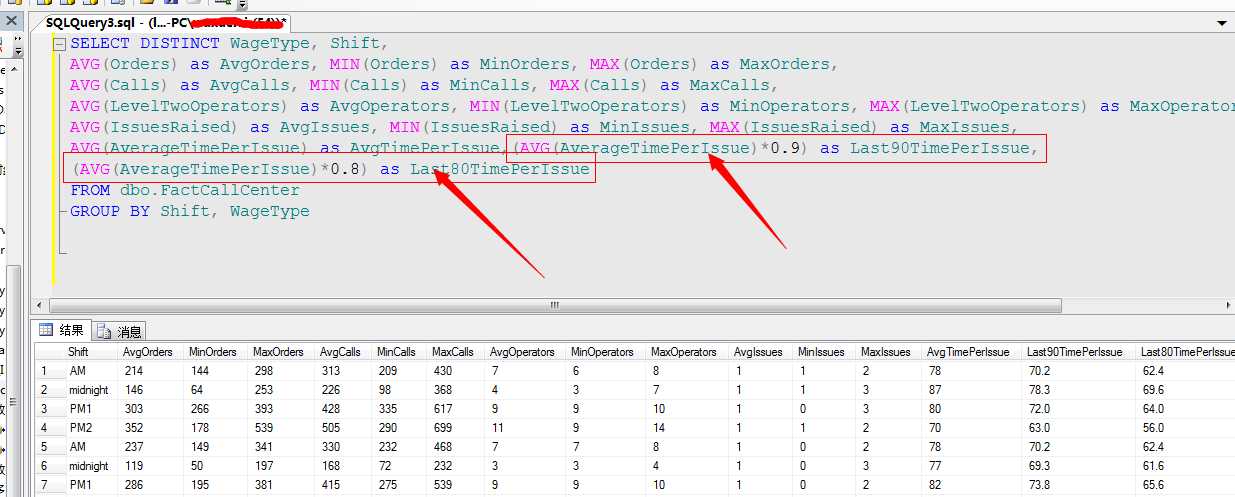
然后将这个语句调整值数据源视图中,利用上述方法来预测下减少到90%的平均应答时间,它的挂断率是多少,我们直接写DMX语句进行查询:

SELECT
t.[Shift],
t.[WageType],
Predict([FactCallCenterReturn].[Service Grade]),
PredictProbability([FactCallCenterReturn].[Service Grade])
From
[FactCallCenterReturn]
PREDICTION JOIN
OPENQUERY([Adventure Works DW2008R2],
‘SELECT
[Shift],
[WageType],
[AvgCalls],
[AvgIssues],
[AvgOperators],
[AvgOrders],
[Last90TimePerIssue]
FROM
(SELECT DISTINCT WageType, Shift,
AVG(Orders) as AvgOrders, MIN(Orders) as MinOrders, MAX(Orders) as MaxOrders,
AVG(Calls) as AvgCalls, MIN(Calls) as MinCalls, MAX(Calls) as MaxCalls,
AVG(LevelTwoOperators) as AvgOperators, MIN(LevelTwoOperators) as MinOperators, MAX(LevelTwoOperators) as MaxOperators,
AVG(IssuesRaised) as AvgIssues, MIN(IssuesRaised) as MinIssues, MAX(IssuesRaised) as MaxIssues,
AVG(AverageTimePerIssue) as AvgTimePerIssue,(AVG(AverageTimePerIssue)*0.9) as Last90TimePerIssue,
(AVG(AverageTimePerIssue)*0.8) as Last80TimePerIssue
FROM dbo.FactCallCenter
GROUP BY Shift, WageType) as [Shifts for Call Center]
‘) AS t
ON
[FactCallCenterReturn].[Wage Type] = t.[WageType] AND
[FactCallCenterReturn].[Shift] = t.[Shift] AND
[FactCallCenterReturn].[Calls] = t.[AvgCalls] AND
[FactCallCenterReturn].[Issues Raised] = t.[AvgIssues] AND
[FactCallCenterReturn].[Level One Operators] = t.[AvgOperators] AND
[FactCallCenterReturn].[Orders] = t.[AvgOrders] AND
[FactCallCenterReturn].[Average Time Per Issue] = t.[Last90TimePerIssue]
来看一下结果: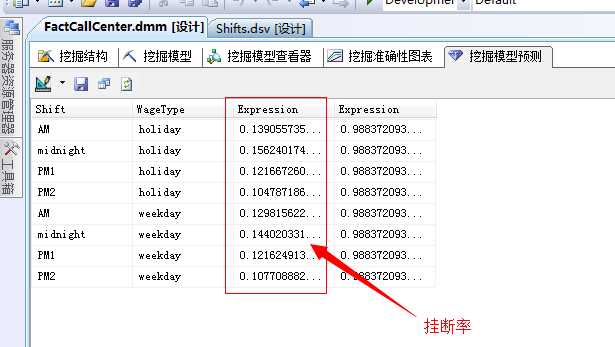
挂断率相比平均值有所减小,但是还没有满足BOSS的要求,在0.1以下,我们继续减小平均应答率看看,减少到80%
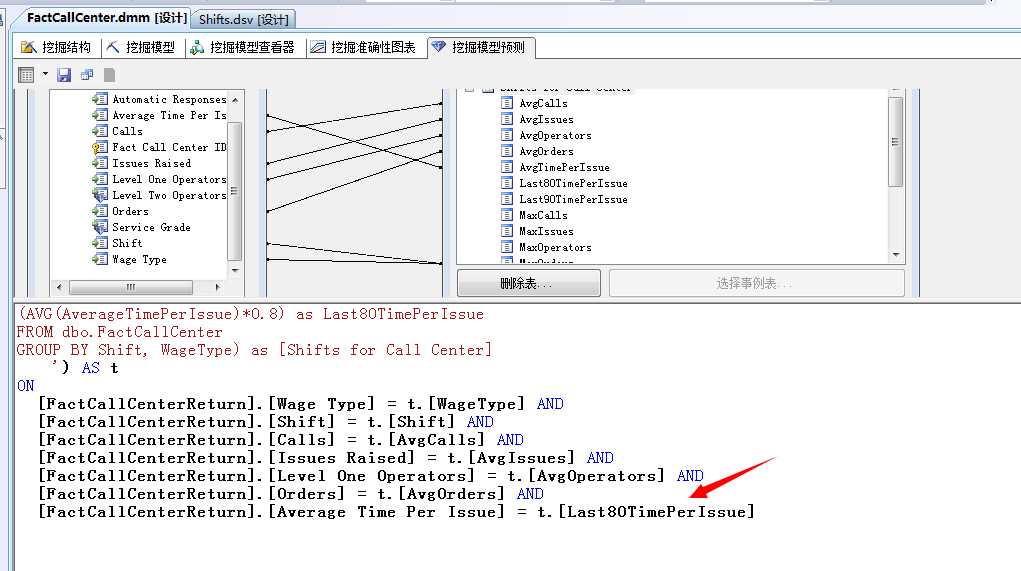
我们再来看一下预测结果:
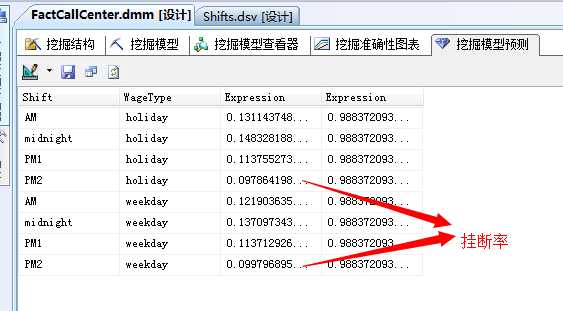
嘿嘿,已经出现0.1以下的应答率了,看样子按照这个规则进行调整,基本是能满足BOSS的要求了,将平均应答率减少至80%。
有兴趣的童鞋,可以按照此规律进行分析挖掘,来正确的调整每个岗位的人数以及上班轮次的调整等。
结语
本篇文章到此结束了...本篇和上一篇的Microsoft神经网络分析算法是相关联的,不清楚的可以参照,其实关于Microsoft神经网络算法和Microsft逻辑回归的应用场景非常的广泛,熟悉好这两种算法很关键。
本篇作为该系列的最后一篇,其实关于数据挖掘这块在微软这边能做到的基本都涵盖到了,虽然当前SQL Server版本已经到了2012..2014版本貌似也问世了,但是这一系列的版本中,关于商业智能BI这块它其实是没有实质性的提高的,其关键技术还是于SQL Server2005上出现的,所有本系列算法总结基于SQL Server2008版本,所应用到的范围是基本能涵盖全的。
原文地址:(原创)大数据时代:基于微软案例数据库数据挖掘知识点总结(Microsoft 线性回归分析算法)
以上是关于微软数据挖掘算法:Microsoft 线性回归分析算法(11)的主要内容,如果未能解决你的问题,请参考以下文章
微软数据挖掘算法:Microsoft 神经网络分析算法原理篇