白话空间统计之四:P值和Z值(中)
Posted 虾神说D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了白话空间统计之四:P值和Z值(中)相关的知识,希望对你有一定的参考价值。
要说P、Z之前(本文的P、Z写法,请忽略大小写),我们先看看一个中学化学的概念:PH值。
另外,还要纠正一个说法,p 是一个值(p value),而z是一个得分(z scores),上篇文章中,称谓出错了。
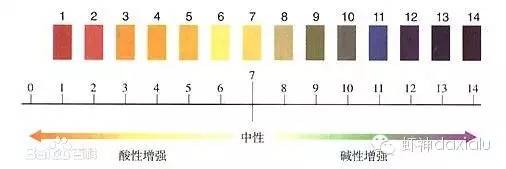
就像上面那个PH试纸的标尺,从中间往两边延伸,表示酸碱的强度。理论上,自然界的物质,基本上以7为中心的泊松分布,就像下面这样:
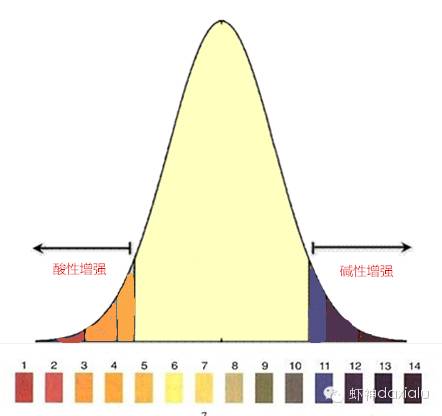
相对于极度的强酸和极度的强碱,在自然界中的含量都是比较少的,更多的都是中性或者是弱酸或者弱碱的物质。
PH值就是用来度量酸碱度的东东,那么我们今天要说的P、Z就类似于PH值这样一个概念,也是用来衡量空间分布模式,而且最关键的,它的值也有一个和PH试纸一样的参考标尺。
首先看看,空间分布的模式,一般来说,有三种,分别是离散的、随机的、和聚合的。
离散的概念就是指观测的每个数据之间的差异程度,离散程度越大,差异性就越大。
聚合与离散正好相反,表示在一定区域内的相关程度,就是聚合程度越大,相关性就越大。
随机就不用说了,纯粹的无模式,你既不能从随机数据中获取结论,也发现不了规律和模式。
拿到数据之后,我们都要进行零假设,然后验证这份数据是不是具有随机模式,如果有很大的概率是随机模式,那么这份数据的可分析性,基本上就微乎其微了(比如布朗运动的运动规律,估计没有哪个人会无聊的去做研究,一方面根本就研究不出什么结果来嘛,另一方面是随机结果的分析也不具有可重现性)。
P值和Z得分分别表什么呢?
p值(P-Value,Probability,Pr),代表的是概率。它是反映某一事件发生的可能性大小。在空间相关性的分析中,p 值表示所观测到的空间模式是由某一随机过程创建而成的概率。比如我说,你计算出来的p值是1,那就表示你用于计算的这份数据,100%是随机生成的了(当然,不可能是1的,0.5以上就也不得了)。如果是0.1,就表示只有10%的可能性是随机生成的结果。
这样看来,p值是越小越好,但是小到什么样的程度才会最好呢?后面我们会就这个问题继续讨论。
z得分(Z scores)表示标准差的倍数(standard deviations)。
先看看“标准差”是什么,在官方的解释是:“总体各单位标准值与其平均数离差平方的算术平均数的平方根”,好吧,我知道这个概念有点绕口,你就知道记住“标准差能反映一个数据集的离散程度”,就可以了。
那么z得分,就是标准差的倍数(有正负之分),比如z得分是+2.5,就表示你的数据计算出来,得到的结果是标准差的正2.5倍,那么就表示数据已经高度聚集了。反之,如果你算出来的是-2.5,那么就表示你的结果是标准差的负2.5倍,就是高度离散的数据了。
P值和Z得分,一般都是一起出现的,如下图所示:
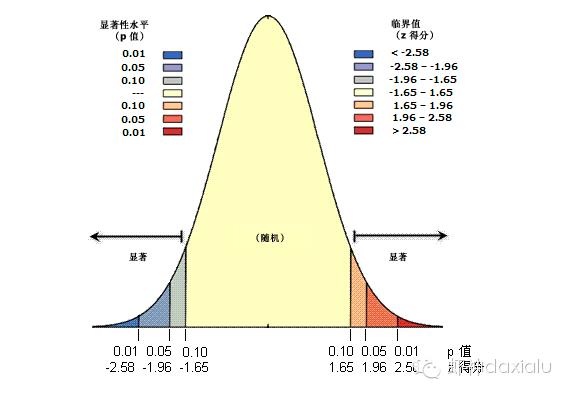
可以看见,p值与z值是有相关性的。上面这个标尺就是p值和z得分的"PH试纸标准比色卡"。
按照这个分布趋势,我们可以看出,数据高度聚集和高度离散,都是小概率的事件。如果你计算出来的p值和z得分,被分布在了两端,就说明你的数据出现随机模式的概率非常低了。
一般来说,要进行数据分析,我们首先就要设立一个置信度,也就是说,你要设定你的数据,起码要有多大的可能性,被落在你期望的区间内。
如,一拿到数据,我们最先就要想,这份数据起码应该有绝大部分的值,不是随机的(也就说,是应该有规律的),这个绝大部分到底应该被量化为多少呢?一般来说,我们会选择90%,或者95%或者99%。那么99%是最极端的情况,表示你能够完全的确认,这份数据没有任何的随机可能(只有1%的可能是随机创建的),完全的接受了零假设。
下表显示了不同置信度下未经校正的临界 p 值和临界 z 得分。
z 得分(标准差) | p 值(概率) | 置信度 |
< -1.65 或 > +1.65 | < 0.10 | 90% |
< -1.96 或 > +1.96 | < 0.05 | 95% |
< -2.58 或 > +2.58 | < 0.01 | 99% |
“未经校正”就所谓的“经验参数”,当然还有一个“错误发现率 (FDR)”工具,可以对p 值的临界点进行校正。这些校正后临界值会等于或小于上面的表所示的值。
对于这个FDR工具,先挖个坑,以后填。
最后,我们最后来解读一份数据
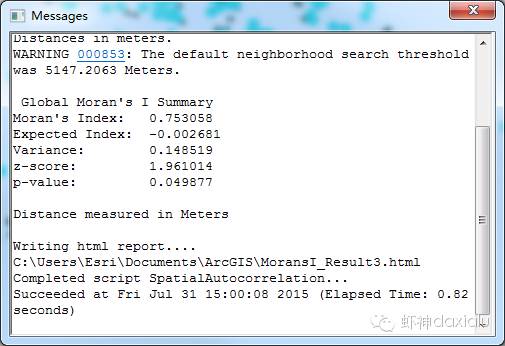
这个是通过ArcMap的全局莫兰指数计算出来的结果,我们暂时跳过期望指数和方差,直接看我们这几天讲的内容。
莫兰指数是大于0.7,z得分是大于1.96,p值为大于0.04小于0.05,对照上面那个对比标尺,所以就能得出以下的结果:
1、莫兰指数是正数,而且大于0.7,就表示这份数据具有空间正相关性,数据集的用于分析的值与空间聚集度成正比。
2、p值小于0.05,所以本数据是随机生成的概率只有5%(95%的置信度)。
3、z得分大于1.96,说明这份数据的呈现了明显的聚类特征。
那么总体说,p值代表数据来源的可靠性,z得分和莫兰指数都表示此数据有明显的规律。
最后来看看,这是一份什么数据:
这是北京市2013年9月的房价数据(友情感谢小强同学提供)。这份数据是通过爬虫从网络上扒下来的,自然不会是随机生成,而且房价的数据确实是明显有聚集特性和空间正相关的。
这样,通过计算,验证了我们的猜测和观点。
关于P值和Z得分的内容,后面还有,未完待续。
前面的文章,可以先关注虾神的公众号,然后查看历史信息就行。或者点击原文链接,去看虾神我的博客。
以上是关于白话空间统计之四:P值和Z值(中)的主要内容,如果未能解决你的问题,请参考以下文章