新版白话空间统计(11):ArcGIS中的PZ值标尺
Posted 虾神说D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新版白话空间统计(11):ArcGIS中的PZ值标尺相关的知识,希望对你有一定的参考价值。
CSDN的被爬虫专用声明:虾神原创,公众号\\知乎:虾神说D
转发、转载和爬虫,请主动保留此声明。
前面我为了一直省事,所以直接把P-value 和Z-scores给统称成了PZ值,实际上准确翻译应该叫做P值与Z得分,我就不一一校正了,另外,PZ的大小写在文中大家也自行忽略就好。
首先,我们来看看在ArcGIS里面做空间自相关,当我们勾选了生成分析报告之后执行:
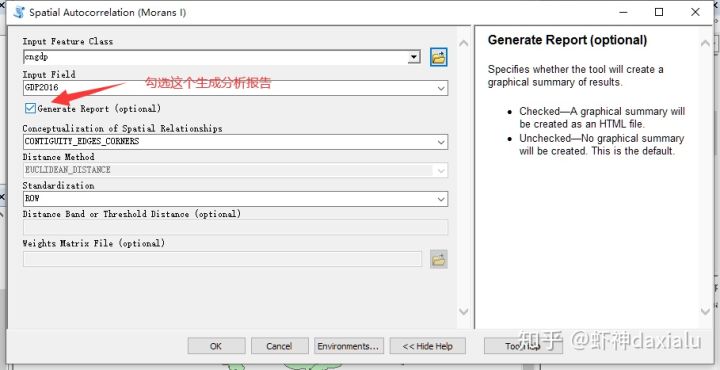
在指定的地方会生成这样一个分析报告:(注意,在这个地方,不同的版本会有一些不同,建议使用ArcGIS10.4以上版本,而且在做空间统计的时候,请把把ArcGIS设置为英文版)
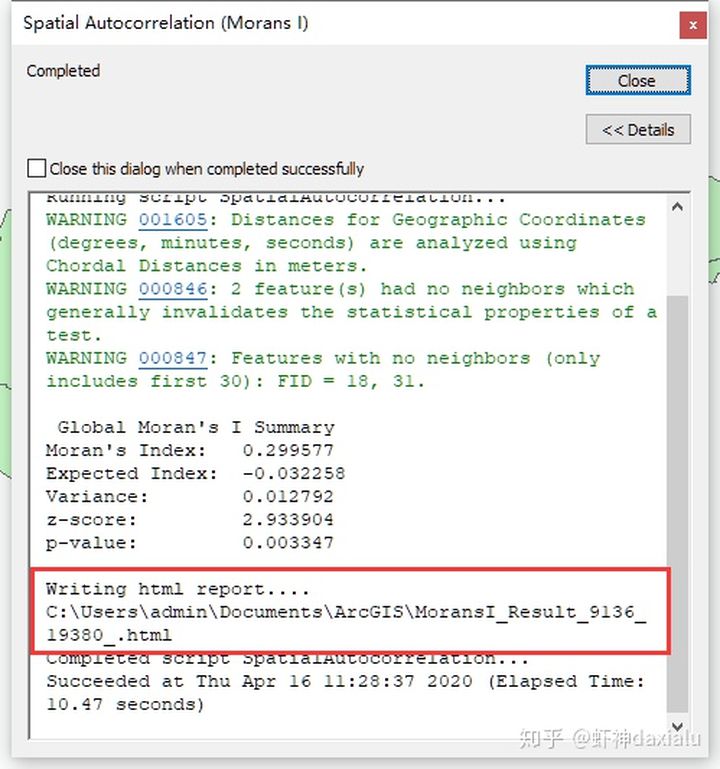
打开这个分析报告,首先映入眼帘的,是这样的一个图形:
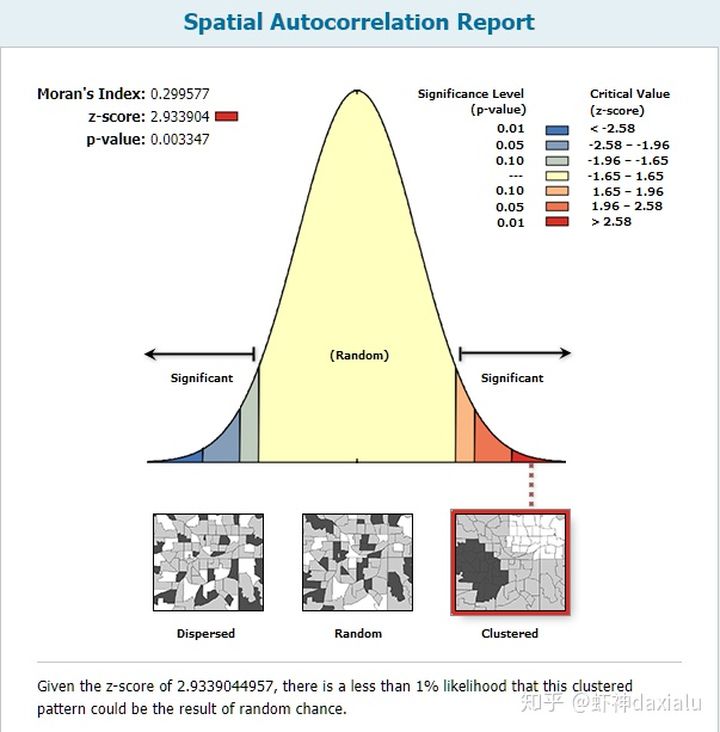
这个漂亮的正态分布曲线图,是拿来干嘛的呢?今天我们就扣着ArcGIS的这个输出报告,来聊聊ArcGIS里面的PZ值。
首先,上面这个标准的正态分布结构的图形,在ArcGIS的空间统计里面,起的作用,类似于化学分析里面的PH比色卡:
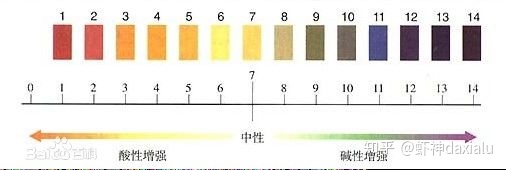
我们知道,在做酸碱度测试的时候,通常通过PH试纸+比色卡,来进行判定,从中间往两边延伸,表示酸碱的强度。理论上,自然界的物质,基本上以7为中心的泊松分布,就像下面这样:
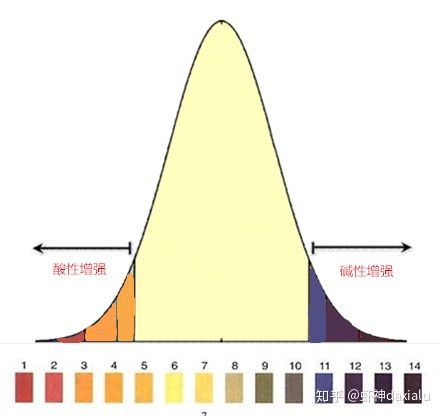
相对于极度的强酸和极度的强碱,在自然界中的含量都是比较少的,更多的都是中性或者是弱酸或者弱碱的物质。
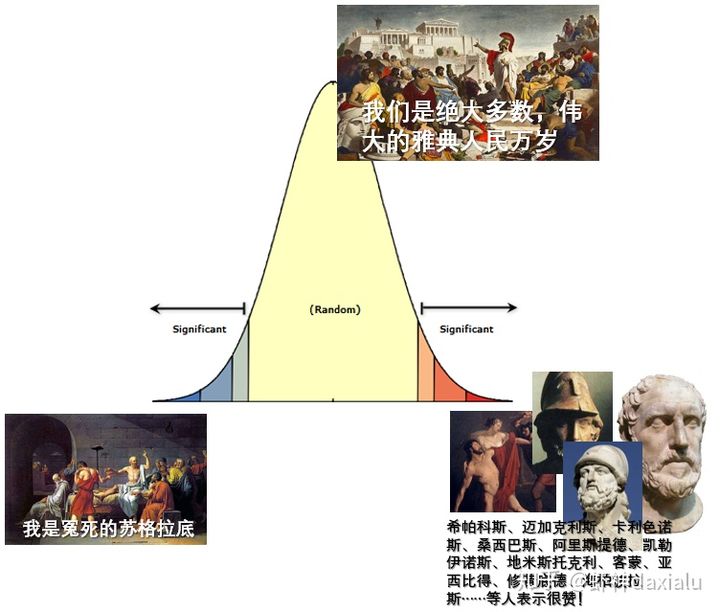
所以在ArcGIS里面,P、Z就类似于PH值这样一个概念,也是用来衡量空间分布模式,而上面给出的那个正态分布的图形,就是ArcGIS中的PZ值的比色卡。
在自然界里面,中心和弱酸、弱碱性物质是绝大多数,极度的强酸和极度的强碱在自然界里面出现的概率极低,多半是在实验室环境下用人工干预的手段才能合成出来——类比之下,数据领域,没有人工干预或者特殊条件产生的离散或者聚集,就是极少数数,所以:
了解这个标尺之后,我们继续来看PZ:
p值(P-Value,Probability,Pr),代表的是概率。它是反映某一事件发生的可能性大小。在空间相关性的分析中,所说的p 值表示所观测到的空间模式是由某一随机过程创建而成的概率。也就是说,你先假设,你手上的这份数据就是随机生成,没有任何模式,那么这个随机过程这个就是你的零假设。
那么现在就可以理解,为什么虾神在前面一直强调,P值越小越好了吧——如果你的P值等于1,就表示你的数据100%是由随机过程生成……当然,实际上是不可能有这么高的百分比……所以一直在强调,P必须要小于0.1,也就是表示你的随机可能性最多只能有10%,多一点都不行。
这个0.1又是什么鬼?
这个数值涉及到了统计学历史上最著名的一个“经验公式”——提出者是号称是“以一己之力独立创建了现代统计学的天才”(丹麦统计学家,统计学史的作者安德斯·哈尔德语),被尊称为“近代统计学之父”的罗纳德·艾尔默·费希尔(Ronald Aylmer Fisher 1890~1962)爵士。

罗纳德·艾尔默·费希尔爵士
罗纳德·艾尔默·费希尔爵士
Ronald Aylmer Fisher
1890~1962
剑桥大学遗传学教授、近代统计学之父
说起来,这个经验公式的出现,还有一个比较有意思的故事:
话说,某个夏天的午后,一群剑桥的教授和他们的夫人们在喝下午茶:
这时候,一位女士坚称:把茶加进奶里,或把奶加进茶里,不同的做法,会使茶的味道品起来不同。
在场的一帮理(糙)工(汉)男(子)们,对这位女士的“胡言乱语”嗤之以鼻。这怎么可能呢?他们不能想象,仅仅因为加茶加奶的先后顺序不同,茶就会发生不同的化学反应。
然而,在座的一个身材矮小、戴着厚眼镜、下巴上蓄着的短尖髯开始变灰的先生,却不这么看,他对这个问题很感兴趣。
他兴奋地说道:“让我们来检验这个命题吧!(反正闲着也是闲着)”,并开始策划一个实验。在实验中,坚持茶有不同味道的那位女士被奉上一连串的已经调制好的茶,其中,有的是先加茶后加奶制成的,有的则是先加奶后加茶制成的。

那个留着短胡须的先生就是罗纳德·艾尔默·费歇尔,当时他只有三四十岁。后来他写了一本叫《实验设计》(The Design of Experiments)的书,在书的第 2 章就描述了他的“女士品茶”实验。
他在实验中,假设这个女士没有这个分辨能力,对于奶茶鉴别完全就是靠瞎猜……那么给她端上来一杯茶,她喝完之后随口一说:这是先加奶的……如果她说对了——是不是真的表示她我们就可以拒绝这种假设,而认为她真的具有这种辨识能力呢?
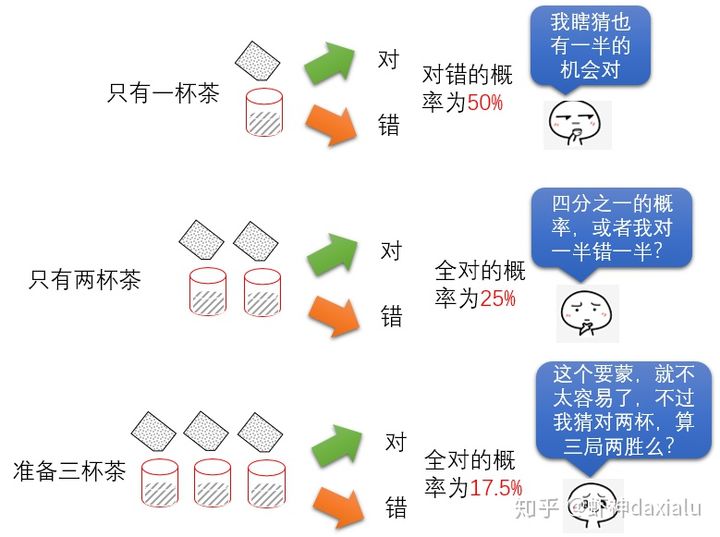
可以看见,随着送上去的奶茶越来越多,她完全靠蒙对的几率就越来越少……比如我们同时准备10杯茶,那么10杯茶全部猜对的概率只有千分之一(联合概率):
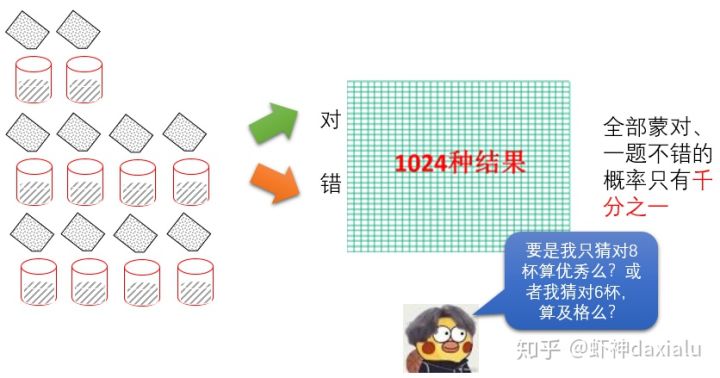
虽然10杯茶,靠瞎猜完全正确的概率只有不到千分之一,但也只有正如上上面那个小(cai)黄(xu)鸭(kun)所言:我对多少算对呢?或者我(猜)对多少,算及格?
或者我们继续加大样本……

比如,加大到15杯,根据联合概率,如果15杯全部猜中的概率,只有十万分之三……
但是,不管我们给这位女士准备多少杯茶,也没有办法真正的把瞎猜这种概率降低到0……那么也就是,我们无法(完全)拒绝零假设?
统计学当然不是非黑即白的二元论,而是概率论——根据费舍尔爵士的说法:我们并不需要把概率降低到0,才表示拒绝零假设,而是降低到一定的程度就可以了,比如0.1或者0.05——这就是90%以及95%这个所谓的经验公式的来源。
之后在各行各业、各种实验、研究、论文里面,一直延续了费舍尔这个只要P值小于0.1或者0.05就拒绝了零假设这一说法,使之成为了最著名的一个经验公式。
当然,近几年,也有很多统计学家发文批判这个一刀切的0.1或者0.05
不过总体而言,要批判容易(键盘侠谁不会当),但是要提出一个能够取代它、而且还能够被广大研究者认可的概念,就不是那么容易了,所以到今天为止,大部分论文期刊,还是会接受P值的解释,并且还要求做P值相关的检验。
看完了P值,下面我们顺便看看与P值息息相关另外一个概念——Z得分。
Z得分的官方描述是:也叫标准分数(standard score),是一个分数与平均数的差再除以标准差的过程。
那么“标准差”是什么捏?在官方的解释是:“总体各单位标准值与其平均数离差平方的算术平均数的平方根”,好吧,我知道这个概念有点绕口,你就知道记住“标准差能反映一个数据集的离散程度”,就可以了。
所以,在我们的衡量标尺上面,P值和Z得分一般都是成对出现——
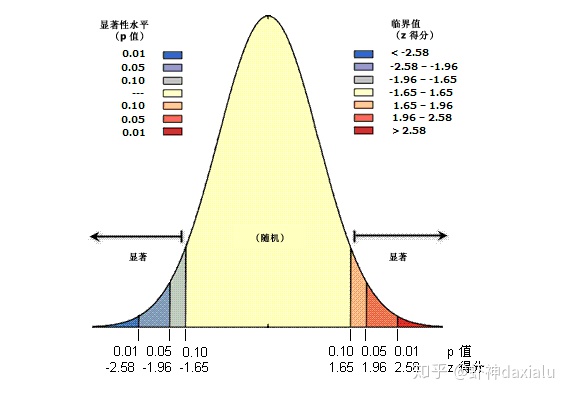
所以从衡量标尺上面可以看出,聚集和离散,分别位于分布的两个极端——也就是假设这份数据就是随机的,而如果你计算出来不是随机,则表示发生了小概率事件,我们拒绝了这个零假设。
一般来说,要进行数据分析,我们首先就要设立一个置信度,也就是说,你要设定你的数据,起码要有多大的可能性,被落在你期望的区间内。
所以一拿到数据,我们最先就要想,这份数据起码应该有绝大部分的值,不是随机的(也就说,是应该有规律的),这个绝大部分到底应该被量化为多少呢?这就是费舍尔当年提出来的经验公式:建议选择90%,或者95%或者99%。那么99%是最极端的情况,表示你能够完全的确认,这份数据没有任何的随机可能(只有1%的可能是随机创建的),完全的拒绝了零假设。
下表显示了不同置信度下未经校正的临界 p 值和临界 z 得分。
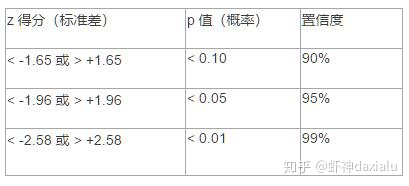
针对这个所谓的未经校正,当然就还有一个“错误发现率 (FDR)”工具,可以对p 值的临界点进行校正。这些校正后临界值会等于或小于上面的表所示的值。
这里的一个关键概念是,标尺所表示的正态分布中间位置的值(例如,类似 0.19 或 -1.2 的 z 得分)代表的是我们预期的结果(零假设)。但在 z 得分的绝对值很大而P值很小时(即出现在正态分布的两端),那么我们自然会去查看其中存在的不寻常现象——这也是我们需要研究的内容,为什么会出现这种极端情况?

那么实际应用中,P值和Z得分如何来应用和解读呢?聚集、离散和随机又有些什么意义呢?请听下回分解。
CSDN的被爬虫专用声明:虾神原创,公众号\\知乎:虾神说D
转发、转载和爬虫,请主动保留此声明。
以上是关于新版白话空间统计(11):ArcGIS中的PZ值标尺的主要内容,如果未能解决你的问题,请参考以下文章