如何使用Delta Lake构建批流一体数据仓库
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用Delta Lake构建批流一体数据仓库相关的知识,希望对你有一定的参考价值。
简介:Delta Lake是一个开源存储层,它为数据湖带来了可靠性。Delta Lake提供了ACID事务、可扩展的元数据处理,并统一了流式处理和批处理数据处理。Delta-Lake运行在现有数据湖之上,并且与Apache Spark API完全兼容。希望本篇能让大家更深入了解Delta Lake,最终可以实践到工作当中。
作者:
李元健,Deltabricks软件工程师
冯加亮,阿里云开源大数据平台技术工程师
Delta Lake是一个开源存储层,它为数据湖带来了可靠性。Delta Lake提供了ACID事务、可扩展的元数据处理,并统一了流式处理和批处理数据处理。Delta-Lake运行在现有数据湖之上,并且与Apache Spark API完全兼容。希望本篇能让大家更深入了解Delta Lake,最终可以实践到工作当中。
本篇文章将从3个部分介绍关于Delta Lake的一些特性:
- Delta Lake的项目背景以及想要解决的问题
- Delta Lake的实现原理
- Live Demo
一、Delta Lake的项目背景以及想要解决的问题
1)背景
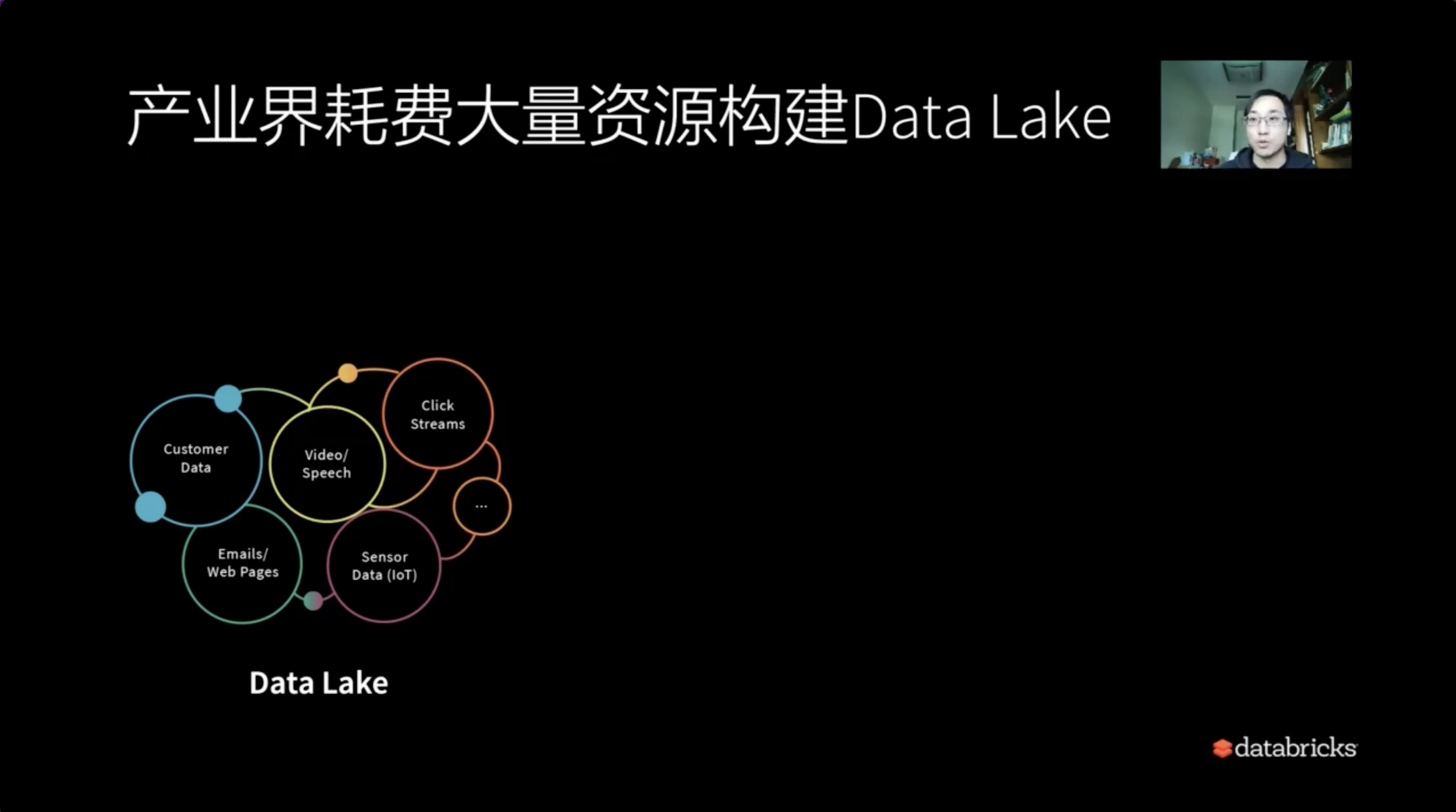
相信大家在构建数仓处理数据方面都很有经验,而产业界也耗费了大量的资源来构建相关的系统。
我们发现有半结构化数据、实时数据、批量数据,用户数据等一系列数据存储在各个地方,分别以不同的处理形式为用户提供服务。
那么我们期望的理想的系统是什么样的?
- 更一体化或更加聚焦,让更专业的人干更专业的事情
- 有同时处理流式和批量的能力
- 可以提供推荐服务
- 可以提供报警服务
- 可以帮助用户分析一系列的问题
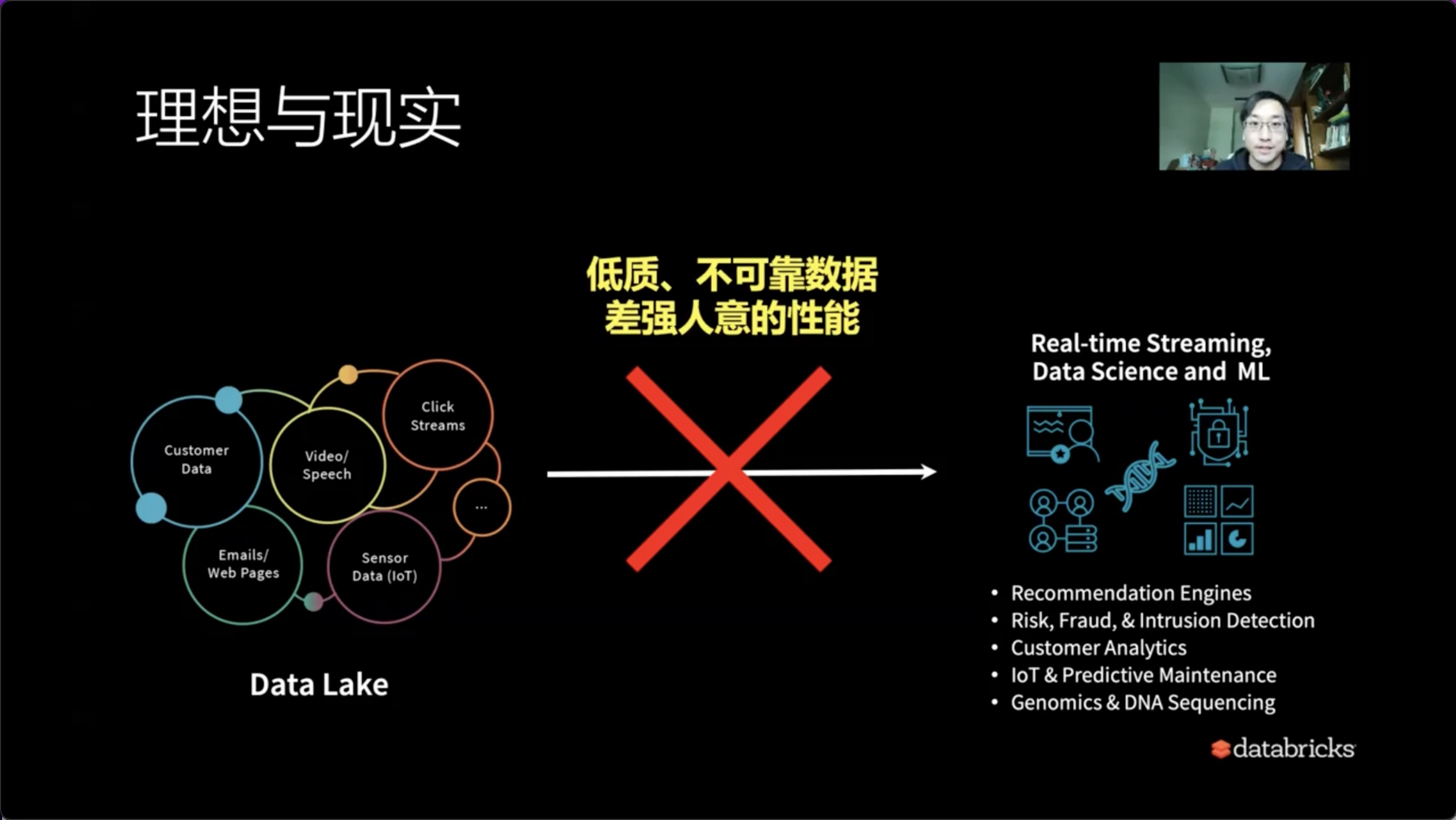
但现实情况却是:
- 低质量、不可靠的数据导致一体化行进艰难。
- 差强人意的性能不一定能达到实时的入库以及实时的查询要求。
在这样的背景下,Delta Lake应运而生。
2)想要解决的问题
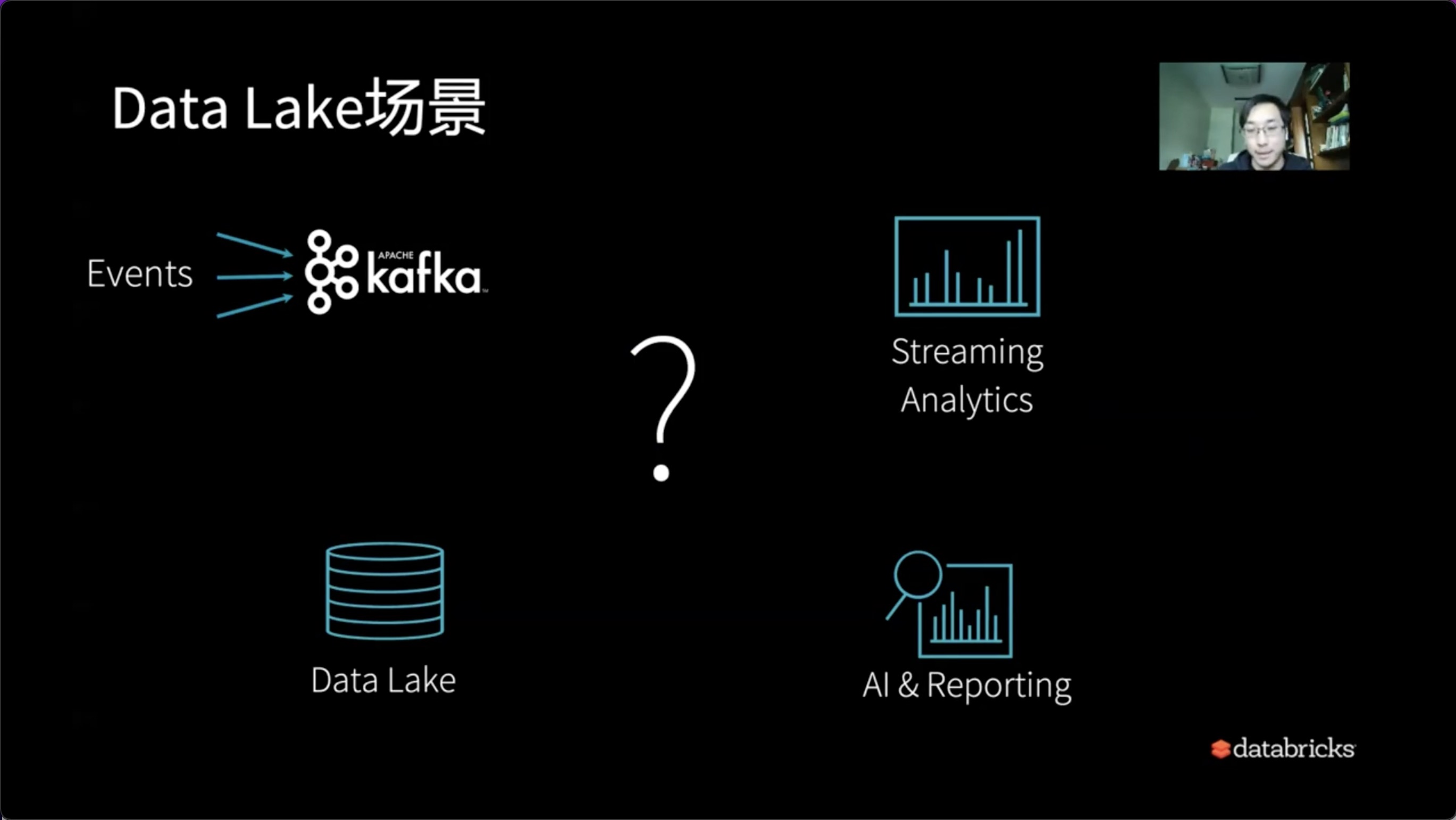
下面用一个常见的用户场景为例,如果没有Delta Lake,该如何解决这样的问题。
这可能是一个最常见的Delta Lake场景,比如我们有一系列的流式数据,不停的从Kafka系统流入,我们期望具有实时处理的能力。与此同时,我们可以把数据周期性放在Delta Lake中。同时,我们需要整套系统的出口具有AI & Reporting能力。
1、历史查询
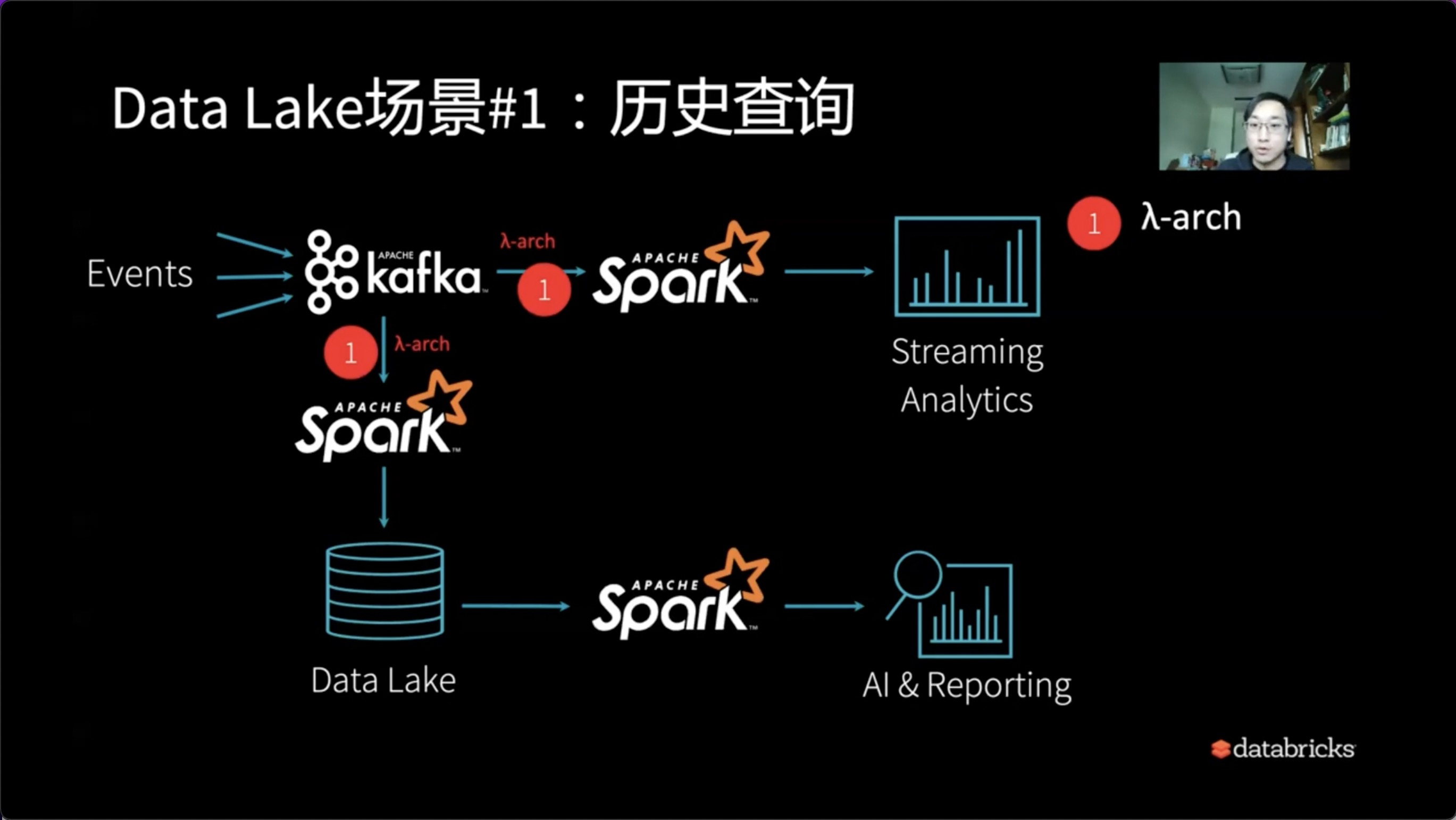
第一条处理流比较简单,比如通过Apach Spark直接使用Streaming Analytics打通实时流。
与此同时,需要离线流时,历史查询可以使用Lambda架构对应的方式。Apach Spark提供了很好的抽象设计,我们可以通过一种代码或API来完成流和实时的λ架构设计。
通过历史数据的查询,我们可以进一步使用Spark进行SQL分析,以及用Spark SQL的作业的形式来产生AI技术的能力。
2、数据校验
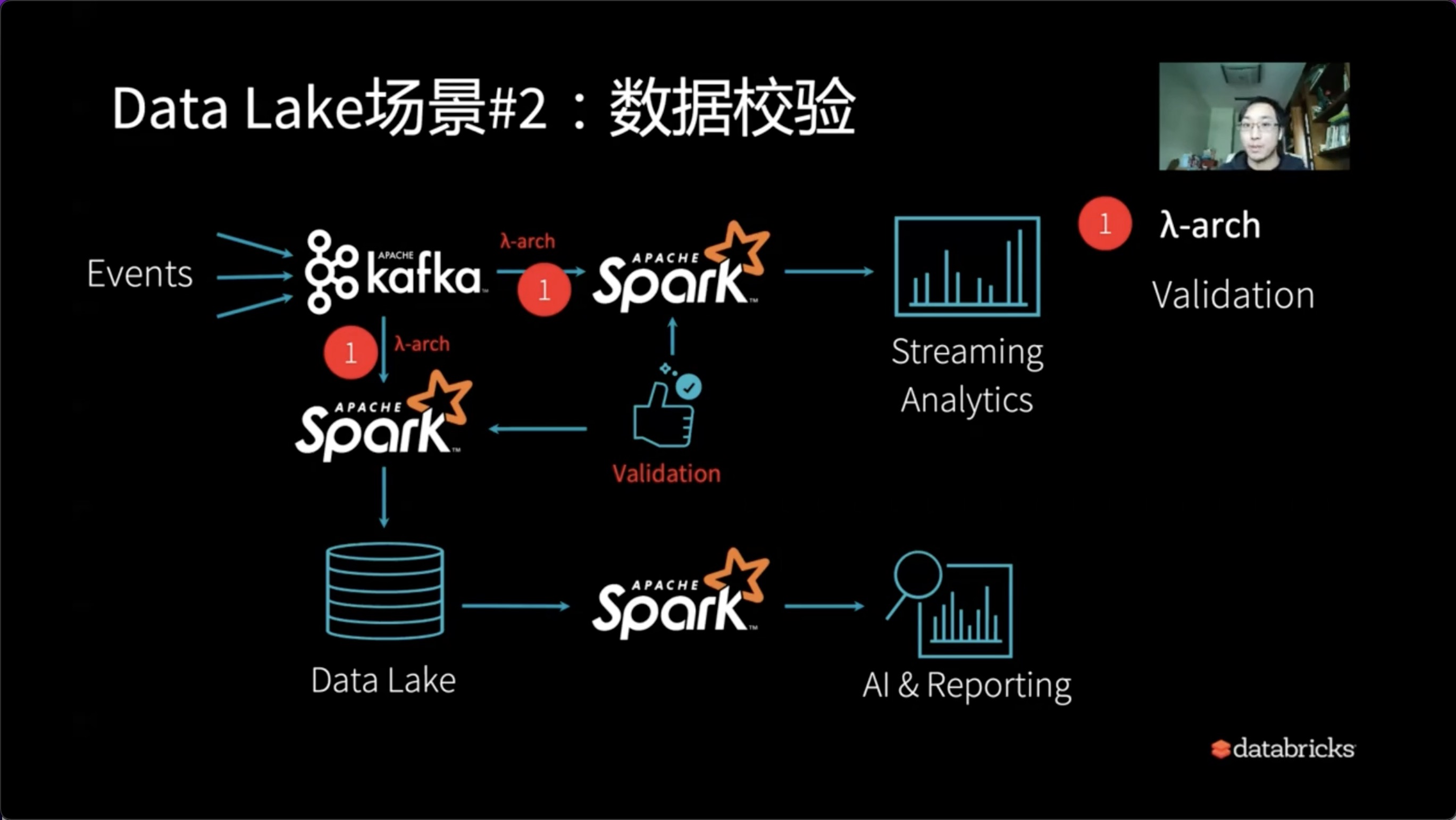
接下来我们需要面对的第一个问题就是数据的校验。
我们的流式数据和批量数据,假设以Lambda架构的形式存在时,如何确认我们在某一个时间点查出来的数据是对的?到底流式的数据和批量的数据差多少?我们的批量数据什么时候该与流式数据进行同步?
所以Lambda架构还需要引入Validation,这需要我们予以确认。尤其是像报表系统面向用户的这种精确的数据分析系统,Validation这一步骤不可或缺。
因此,也许我们需要一支旁支来解决流式和批量之间的同步问题,以及对应的验证问题。
3、数据修复
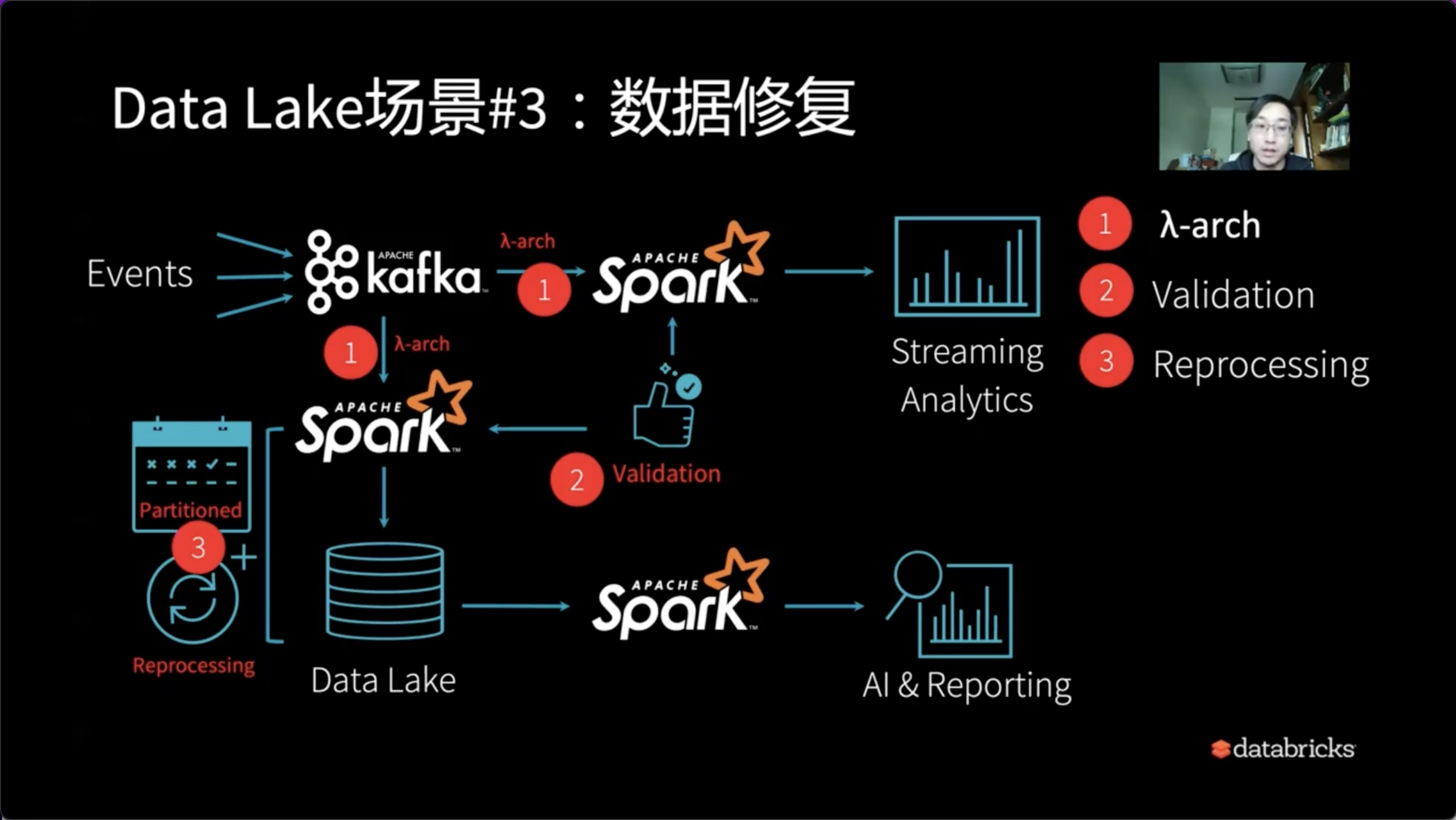
假设如上问题解得到了解决,在系统上了一段时间我们会发现,如我们对应的某个Partitioned数据出了问题,当天的脏数据在若干天之后需要修正。此时我们需要怎么办?
通常,我们需要停掉线上的查询后再修复数据,修复完数据后重新恢复线上的任务。如此折腾的过程,实际无形的给系统架构又增加了一个修复以及过去版本回复的能力。因此,Reprocessing诞生了。
4、数据更新

假设解决完了Reprocessing问题,我们在AI和Reporting最终的出口端,可以看到有新的一系列的需求。比如有一天业务部门或者上级部门、合作部门提出能否Schema Change,因为越来越多的人用数据,想把UserID这个维度加进去,此时该怎么处理?导到Delta Lake去加Schema、停留、对应的数据重新处理等一系列折腾。
所以大家可以看到解决了一个问题又会有新的问题。如果case by case的去解决会导致系统不停的往上打补丁。一个原本简单或者一体化的需求会变得越来越冗余和复杂。
5、理想中的Delta Lake
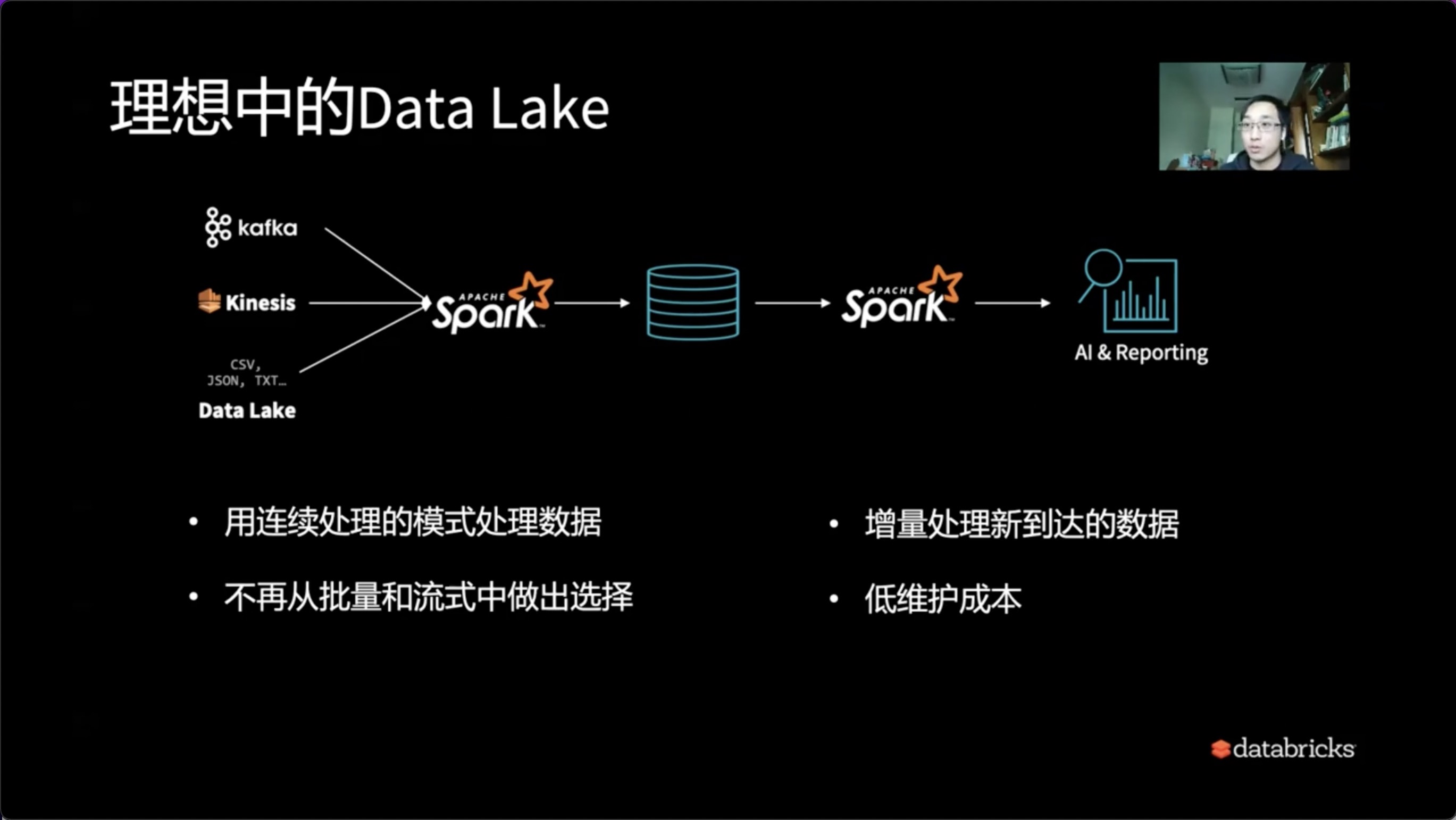
所以理想当中的Delta Lake应该长什么样?
是入口、出口对应的系统干对应的事情。唯一的核心就是Delta Lake层,即对应的数据处理以及数据入仓的整个过程可以做到:
- 用连续处理的模式处理数据
- 增量的数据也可以增量Streaming的方式去处理新到达的数据
- 不需要再从批量和流式中做出选择。或者说批量和流式互相之间做出退让,在流式的时候需要考虑批量,在批量的时候要考虑流式的作用,不应该这样by design。
- 如果我们可以一体化整个Delta Lake架构,自然而然就能降低维护成本。
二、Delta Lake的实现原理
1)Delta Lake具备的能力
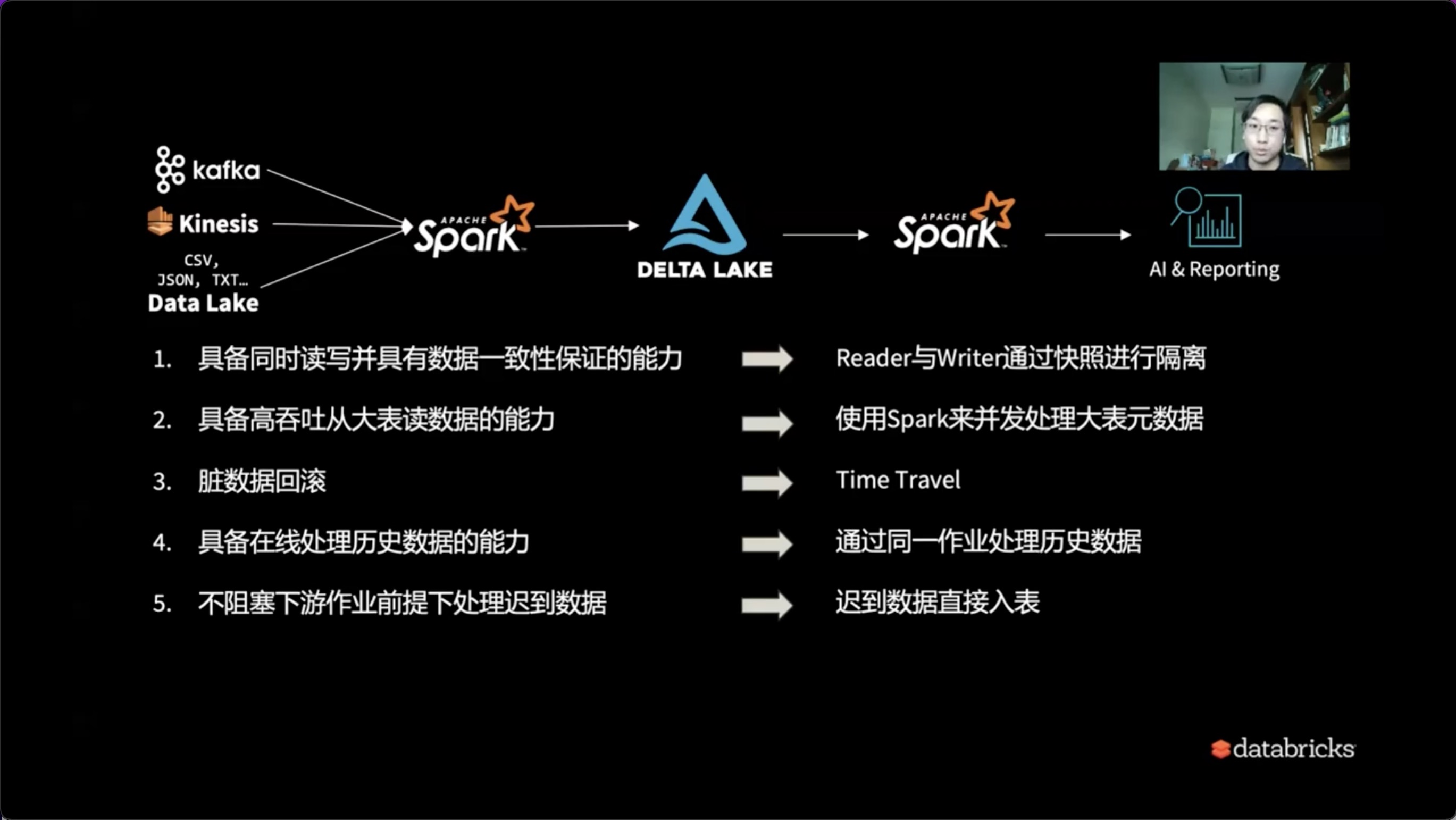
下面我们看一下这一系列的问题是如何在Deltalake当中去解决的。
- 具备同时读写并且有数据一致性保证的能力。在Deltalake当中,Reader和Writer是通过快照机制来进行隔离,也就是说Reader和Writer可以以乐观锁的形式各自写入和读出,互不影响。
- 具备高吞吐从大表读元数据的能力。我们可以想象,当一个表变大之后,它本身的元数据、快照、Checkpoint版本以及变更Schema一系列所有的元数据操作本身就会变成一个大数据的问题。Delta Lake当中设计非常棒的一点就是本身将Meta Delta也视为大数据问题,通过Spark框架自身处理大表的元数据问题。所以在Delta中,不必担心会出现单点处理Meta Delta焊死的情况。
- 历史数据以及脏数据的回滚。我们需要有Time Travel的能力来回溯到某一个时间点进行数据清洗。
- 具备在线处理历史数据的能力。在历史数据回填中,我们依然可以实时处理当前流入的新数据,无需停留,也无需考虑哪些是实时,哪些是离线。
- 可以在不阻断下游作业的前提下处理迟到的数据,可以直接入表。
以上5点完全解决之后,我们就可以用Delta Lake来替代Lambda架构,或者说我们一系列批流分制的架构设计可以使用Delta Lake架构。
2)基于Delta Lake的架构设计
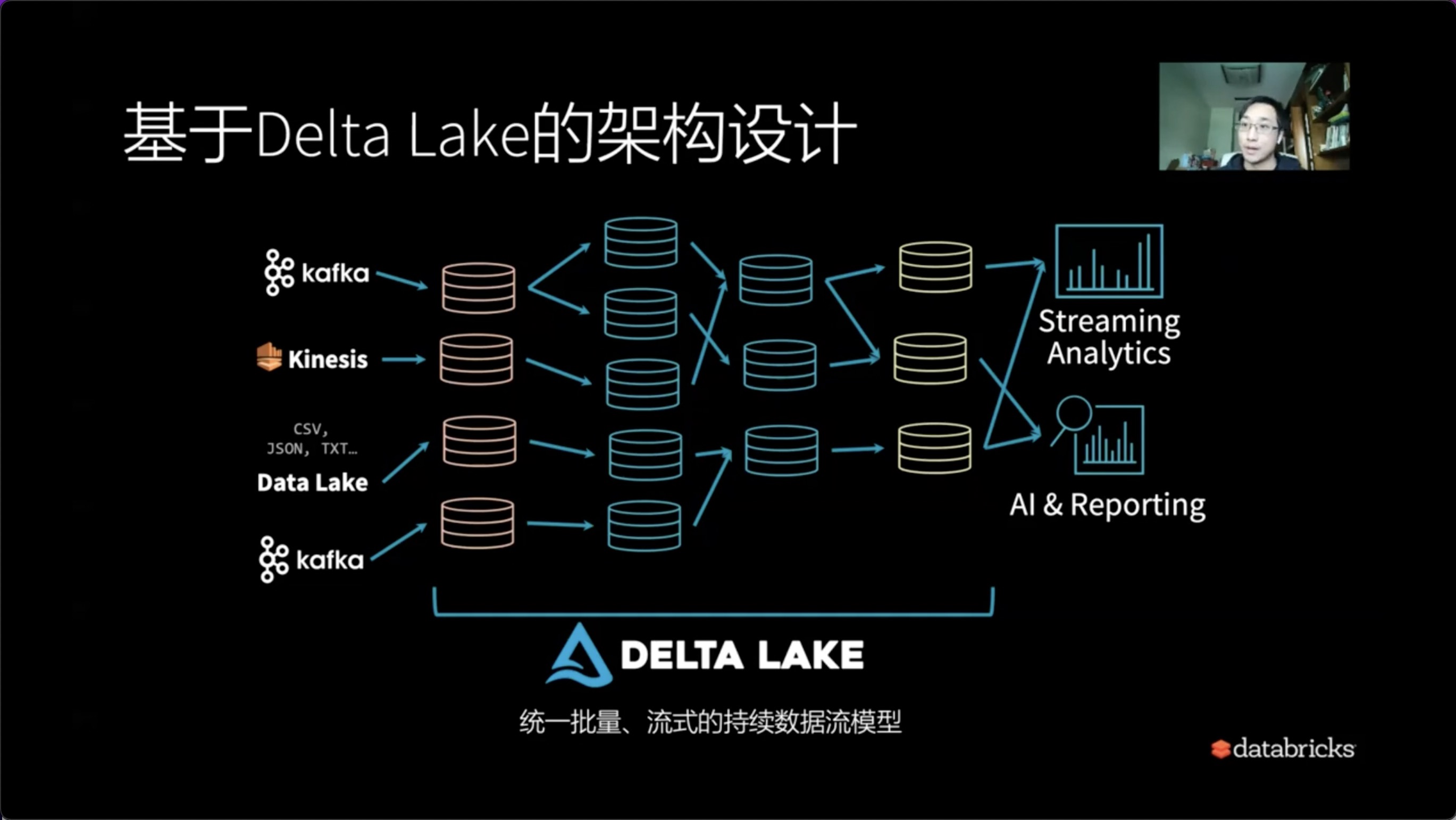
什么是基于Delat Lake的架构设计?
Delat Lake的架构设计中一系列的元数据或者最低的级别就是表。可以将我们的数据一层一层的分成基础数据表,中间数据表以及最终的高质量数据表。所有的一切只需要关注的就是表的上游和下游,它们之间的依赖关系是不是变得更加的简单和干净。我们只需要关注业务层面的数据组织,所以Delat Lake是统一批量、流式的持续数据流的模型。
三、Demo
以下通过Demo的形式演示如何在Databricks数据洞察里搭建批流一体数据仓库的操作,解决生产环境的问题。
Demo演示视频:如何使用Delta Lake构建批流一体数据仓库【Databricks 数据洞察公开课】-云视频-阿里云开发者社区
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于如何使用Delta Lake构建批流一体数据仓库的主要内容,如果未能解决你的问题,请参考以下文章
详谈 Delta Lake 系列技术专题 之 湖仓一体( Lakehouse )