Delta Lake基础介绍(商业版)
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Delta Lake基础介绍(商业版)相关的知识,希望对你有一定的参考价值。
简介:介绍 Lakehouse 搜索引擎的设计思想,探讨其如何使用缓存,辅助数据结构,存储格式,动态文件剪枝,以及 vectorized execution 达到优越的处理性能。
作者:李洁杏,Databrick资深软件工程师
一、Lakehouse搜索引擎设计背景
1. 数据仓库和Lakehouse
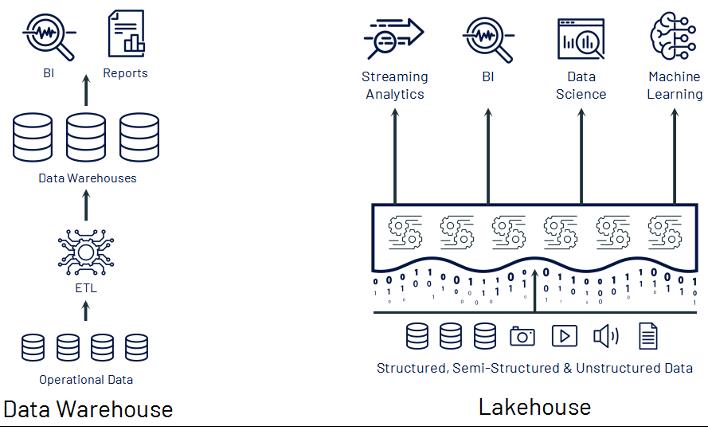
数据管理系统从早期的数据仓库(Data Warehouse),已经发展到今天的Lakehouse。Lakehouse可以同时存储结构化、半结构化和非结构化数据,并且支持流分析、BI、数据科学和机器分析的场景。
2. Lakehouse在查询性能上的挑战
数据仓库架构可以完全控制数据的存储和查询,因此可以同时设计查询系统,以及适应查询系统的数据存储结构,以达到优越的查询性能;
而在Lakehouse架构下,数据是用开放存储结构存储的,如Parquet格式,以便更多系统可以便捷的访问数据,但是开放的存储格式并不一定适合查询操作,查询系统也没有足够的统计数据来实现高效查询。
那么,Lakehouse如何以开放的存储格式达到高效的查询性能?
3. 解决方案
为解决以上的问题,Databricks Lakehouse设计了新的搜索引擎,其SQL性能在Data Lake存储系统和文件格式方面都有出色的表现。
其SQL性能优化是通过以下技术实现的:
a. 高速缓存:将热数据放入高速缓存中;
b. 建立辅助数据结构:如收集统计数据、建立索引;
c. 数据布局优化:以实现最小化I/O;
d. 动态文件剪枝:以实现最小化I/O。
二、Lakehouse中的SQL性能优化技术
1. 高速缓存
大部分的工作负载,一般都会集中访问某些“热”数据上,Data Warehouse经常使用SSD和内存作为缓存来加速热数据的查询。
Lakehouse可以使用与数据仓库相同的优化数据结构对其进行缓存,提高查询性能。
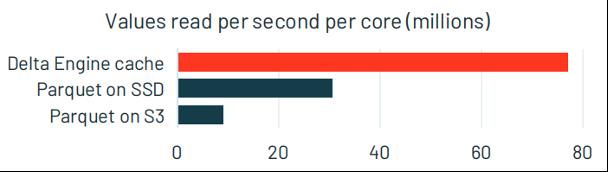
如图所示,在Databricks中用SSD作为缓存,可以将数据读取速度提高3倍以上;采用Delta引擎作为缓存,则可以将数据读取速度提高7倍以上。
2. 建立辅助数据结构
即使数据是用Parquet格式存储的,也可以建立很多额外的数据结构来加快查询,同时对这些额外的数据进行事务性的维护。
示例一:Parquet文件中的Data Skipping
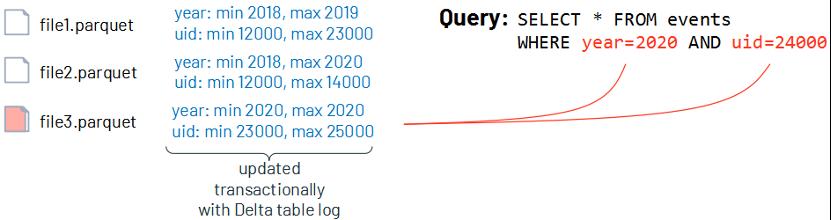
在Parquet文件中,维护表中每个数据文件的最小/最大值统计信息,有助于在查询发生时可以跳过一些无关的数据。
如下图,如果查询条件是year=2020和uid=24000,利用最小/最大统计信息,可知这个查询的信息只会存在于file3,因此可以跳过file1和file2的读取。
示例二:在Parquet文件上建立索引
如下图,如果查询条件是type=“DELETE_ACCOUT”,可以利用在type上建立的索引直接跳到对应的数据上,从而避免读取无关数据。

示例三:Parquet文件上建立Bloom Filter
可以为每一个文件建立Bloom Filter,Bloom Filter可以快速判断表文件中是否包含需要查询的数据,如果不包含则快速跳过该文件,从而减少扫描数据量,提升查询性能。

Bloom Filter原理:
Bloom Filter对每个文件中的数据记录使用1个或多个哈希表计算其哈希值,其起始值都为0,当有哈希值映射在对应的位置时则为1,这样在查询的时候,可以跳过值为0的位置;也有可能的情况是,对应的位全部都为1,这时候数据也有可能不在这个文件中(假阳性),可以通过控制使用哈希函数的个数以及Bloom Filter的大小,来控制假阳性率。
3. 数据布局
a. 小文件问题
在Delta Lake中频繁执行MERGE,UPDATE,INSERT操作,可能会产生大量的小文件。大量的小文件,一方面会降低系统读取性能,同时也会提高元数据操作的开销。
Lakehouse中使用了不同的技术来减少小文件的产生:
- 优化Delta表写入
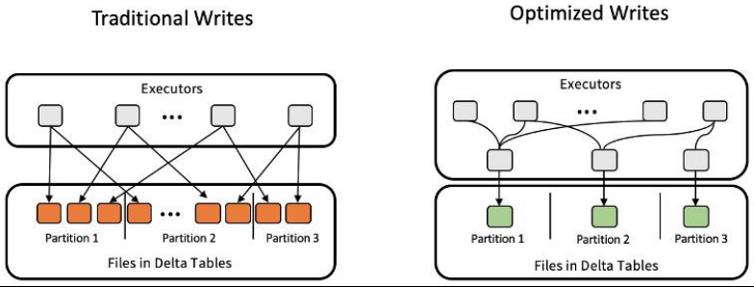
如下图所示,在开源版Spark中,每个executor向partition中写入数据时,都会创建一个表文件进行写入,最终会导致一个partition中产生很多的小文件。
Databricks对Delta表的写入过程进行了优化,对每个partition使用一个专门的executor来合并其它executor对该partition的写入,从而避免了小文件的产生。
- 自动合并小文件
在每次向Delta表中写入数据之后,会检查Delta表中的表文件数量,如果Delta表中的小文件(size < 128MB则视为小文件)数量达到阈值,则会执行一次小文件合并,将Delta表中的小文件合并为一个新的大文件。
- 手动合并小文件
除了自动合并,Databricks还提供Opitmize命令,使用户可以手动合并小文件,优化表结构,使得表文件的结构更加紧凑。
b. 查询时间问题
查询运行时间主要取决于访问的数据量,即使使用Parquet格式,也可以通过优化表内的数据布局以减少运行时间。
- 表文件数据排序
将表文件存储数据排序,在每个表文件中存储一定量的数据,如下图中file1存储uid=0...1000,file2存储uid=1001...2000,这样在查询时就可以根据需要跳过无关的表文件,减少文件扫描数量。

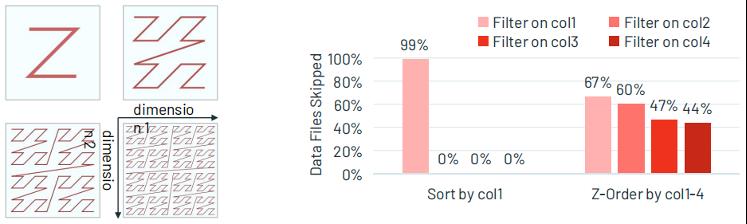
- Z-Ordering优化
在实际查询中,有些查询需要看colomn1在某个范围内的数据,有些查询需要看colomn2在某个范围内的数据,或者更多,这时候仅仅对colomn1进行排序显然是不够的。
Z-Ordering可以在多个维度上(如下图的col 1-4)将关联的信息存储到同一组文件中,来减少不必要的文件读取。
4. 动态文件剪枝(Dynamic File Pruning,DFP)
动态文件剪枝简称DFP,我们以下面一个简单的查询为例:
SELECT sum(ss_quantity) FROM store_sales JOIN item ON ss_item_sk = i_item_sk WHERE i_item_id =‘AAAAAAAAICAAAAAA'
查询说明:将store_sales与item两个表连起来,条件是当item_sk值相等且item_id等于一个固定值。
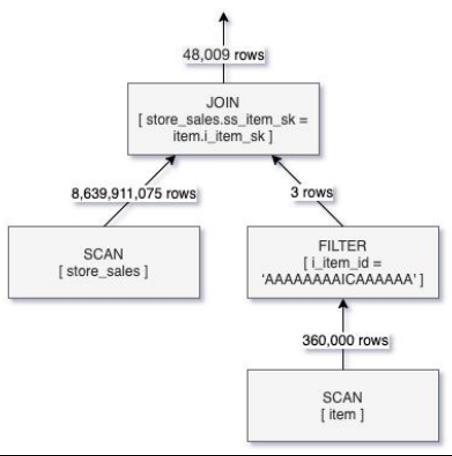
未启用DFP
如果不开启DFP,从上图可以看出,查询会先对store_sales进行全表扫描,然后再和过滤后的item表的行进行join,虽然结果仅有4.6万多条数据,但却扫描了表store_sales中的86多亿条数据。
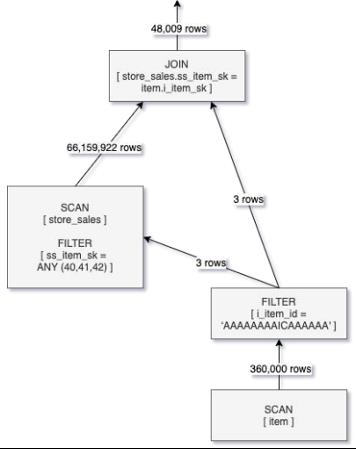
启用DFP
在启用DFP之后,会先扫描item表,查询出表item中i_item_id = ‘AAAAAAAAICAAAAAA'数据行,然后将这些数据行的i_item_sk值作为表store_sales的ss_item_sk的查询条件,在表store_sales的SCAN阶段进行过滤,跳过大量无关数据。这样仅扫描了660多万条store_sales中的数据,比未启用DFP时减少了近99%。
从结果上看,启动DFP后,该条查询实现了10倍的性能提升。
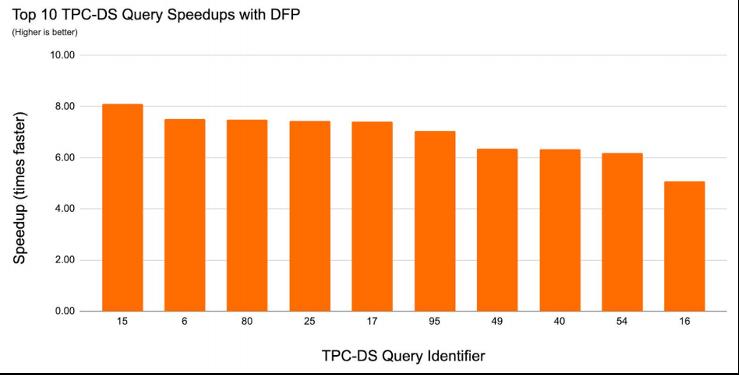
针对该特性在TPC-DS上进行测试(见下图),测试发现启用DFP后,TPC-DS的查询速度达到4.5倍到8倍的提升。
5. 优化组合
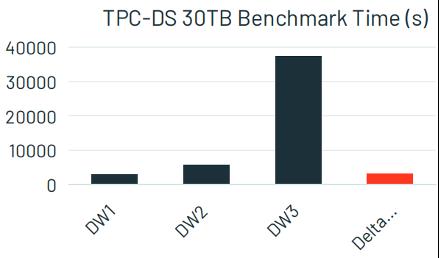
综合使用以上优化技术协同工作,让Lakehouse中的数据读取都在高速缓存中进行,并且通过数据布局优化,建立辅助数据结构减少对非缓存数据读取的I/O,实现了Lakehouse引擎可以提供与数据仓库类似的查询性能。
如下图所示,Delta Engine的查询性能与DW1类似,并且超过了DW2和DW3。
三、Delta Clones
Delta Clones是Lakehouse的一项非常重要的技术,可以对大型数据集进行高效拷贝,支持测试、分享和机器学习的不同需求。
1. 什么是克隆?
克隆也叫拷贝,是原始数据在给定时间点的副本;
它具有与源表相同的元数据:相同表结构,约束,列描述,统计信息和分区;
两种克隆方式:shallow(浅克隆),deep(深克隆)。
2. 深克隆
深克隆会完整复制源表的元数据和数据文件,并生成一个全新的独立的表。
a. 深克隆语句
在SQL中运行CREATE TABLE语句;在Python和Scala语句中运行DeltaTable语句。
# SQL CREATE TABLE delta.`path/to/copy` CLONE customers
# Python and Scala
DeltaTable
.forName("park", "customers")
.clone("path/to/copy")
b. 深克隆的特性
- 与源表相比,克隆表有独立的历史记录;
- 在克隆过程中、或之后发生的对源表的任何更改,都不会反映在克隆表中;
3. 浅克隆
浅克隆仅复制需要克隆的表的元数据,表本身的数据文件不会被复制。
a. 浅克隆语句
与深克隆语句类似,只是在SQL中加入SHALLOW CLONE语句;在Python和Scala中加入isShallow=true。
# SQL CREATE TABLE delta.`path/to/copy` SHALLOW CLONE customers
# Python and Scala
DeltaTable
.forName("spark", "customers")
.clone("path/to/copy", isShallow=true)
b. 浅克隆的特性
- 浅克隆不是自包含的,即自身不是数据源,如果源文件数据被删除,则浅克隆数据可能会不可用;
- 浅克隆不复制流事务或COPY INTO相关的元数据;
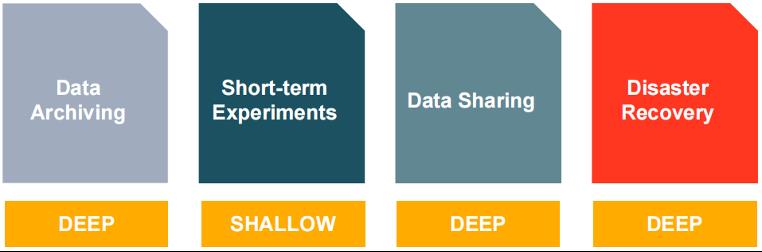
4. 克隆的适用场景
克隆的适用场景有很多,比如:数据存储、短期实验、数据分享和灾难恢复,其中除了短期实验使用浅克隆,其它场景都需要使用深克隆。
本文为阿里云原创内容,未经允许不得转载。
以上是关于Delta Lake基础介绍(商业版)的主要内容,如果未能解决你的问题,请参考以下文章
数据架构 - 完整的 Azure Stack 与集成的 Delta Lake
详谈 Delta Lake 系列技术专题 之 特性(Features)