深入剖析 Delta Lake: schema validation
Posted scx_white
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入剖析 Delta Lake: schema validation相关的知识,希望对你有一定的参考价值。
介绍
Delta Lake是Spark的开源存储层,可提供ACID事务和其他数据管理功能,用于机器学习和其他大数据工作,其通过写和快照隔离之间的乐观并发控制,在写入数据期间提供一致性的读取,从而为构建在HDFS和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 内置数据版本控制,方便读取历史数据以及版本回滚。
Spark 的每一个 DataFrame 都包含一个 schema,用来定义数据的形态,例如数据类型、列信息以及元数据。在 Delta Lake 中,表的 schema 通过 JSON 格式存储在事务日志中,在数据湖 delta lake 中会自动对插入(更新)的数据与目标表进行 schema 约束,下面就简单介绍一下
schema validation
schema validation 使用以下规则来确定 merge 操作是否可以执行
-
对于
update和insert操作,指定的目标列必须存在于目标增量表中 -
对于
updateAll和insertAll操作 源数据集必须具有目标delta lake表的所有列,源数据集可以拥有的其它列,但是这些列在merge时会被忽略。 -
对于
update、insert、updateAll、insertAll操作,如果产生目标列的表达式生成的数据类型与delta lake表中的对应列不同,将尝试将它们强转为表中的类型
了解完 schema validation 的规则,我们来实际操作一下
schema validation作用
由于 Schema 约束是一种严格的校验,因此可以用于已清洗、转化完成的数据,保证数据不受污染。而对于一些日志数据,可能并不需要这么严格。
规则验证
首先 new 一个 sparkSession 对象和一个 keyVal 对象
sparkSession = SparkSession.builder()
.appName("delta-test")
.master("local[4]")
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension")
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
.getOrCreate();
public class KeyVal implements Serializable
private String key;
private String val;
//ignore get、 set、constructor
然后向 data/schema-table 路径插入两条数据
//table path
String tablePath = "data/schema-table";
List<KeyVal> source = new ArrayList<>();
source.add(new KeyVal("1", "1"));
source.add(new KeyVal("2", "2"));
Dataset<KeyVal> sourceSet =
sparkSession.createDataset(source, Encoders.bean(KeyVal.class));
//向table path写入delta lake格式的数据
sourceSet.write()
.format("delta")
.mode("append")
.save(tablePath);
//加载 table path的表
DeltaTable deltaTable = DeltaTable.forPath(tablePath);
//展示数据
deltaTable.toDF().show();
执行结果为
+---+---+
|key|val|
+---+---+
| 2| 2|
| 1| 1|
+---+---+
验证update/insert 操作
为了验证 update 、insert 操作的,我们进行了两次操作,第一次根据 update.key = target.key 来判断要插入哪些数据、更新哪些数据,插入的字段和更新的字段都是在目标 delta lake 表存在的
第二次我们打算插入 key=100、value=100 的数据,只不过插入的字段名从val 变成了 value
DeltaTable deltaTable = DeltaTable.forPath(tablePath);
System.out.println("初始数据");
deltaTable.toDF().show();
List<KeyVal> source = new ArrayList<>();
//插入key=3,val=3的数据
source.add(new KeyVal("3", "3"));
//把key=1的val更新为100
source.add(new KeyVal("1", "100"));
Dataset<Row> dataset =
sparkSession.createDataset(source, Encoders.bean(KeyVal.class)).toDF();
// update、insert 操作
deltaTable.as("target")
.merge(dataset.select("key", "val").as("update")
, "update.key = target.key")
.whenMatched()
.updateExpr(new HashMap<String, String>()
put("val", "update.val");
)
.whenNotMatched()
.insertExpr(new HashMap<String, String>()
put("key", "update.key");
put("val", "update.val");
).execute();
System.out.println("正常字段更新、插入操作");
deltaTable.toDF().show();
System.out.println("插入异常数据");
source.clear();
//创建新的数据
source.add(new KeyVal("100", "100"));
dataset =
sparkSession.createDataset(source, Encoders.bean(KeyVal.class))
.toDF();
deltaTable.as("target")
.merge(
dataset
.selectExpr("key", "val as value")
.as("update")
, "update.key = target.key")
.whenNotMatched()
.insertExpr(new HashMap<String, String>()
put("key", "update.key");
//val修改为value插入
put("value", "update.value");
).execute();
执行结果如下
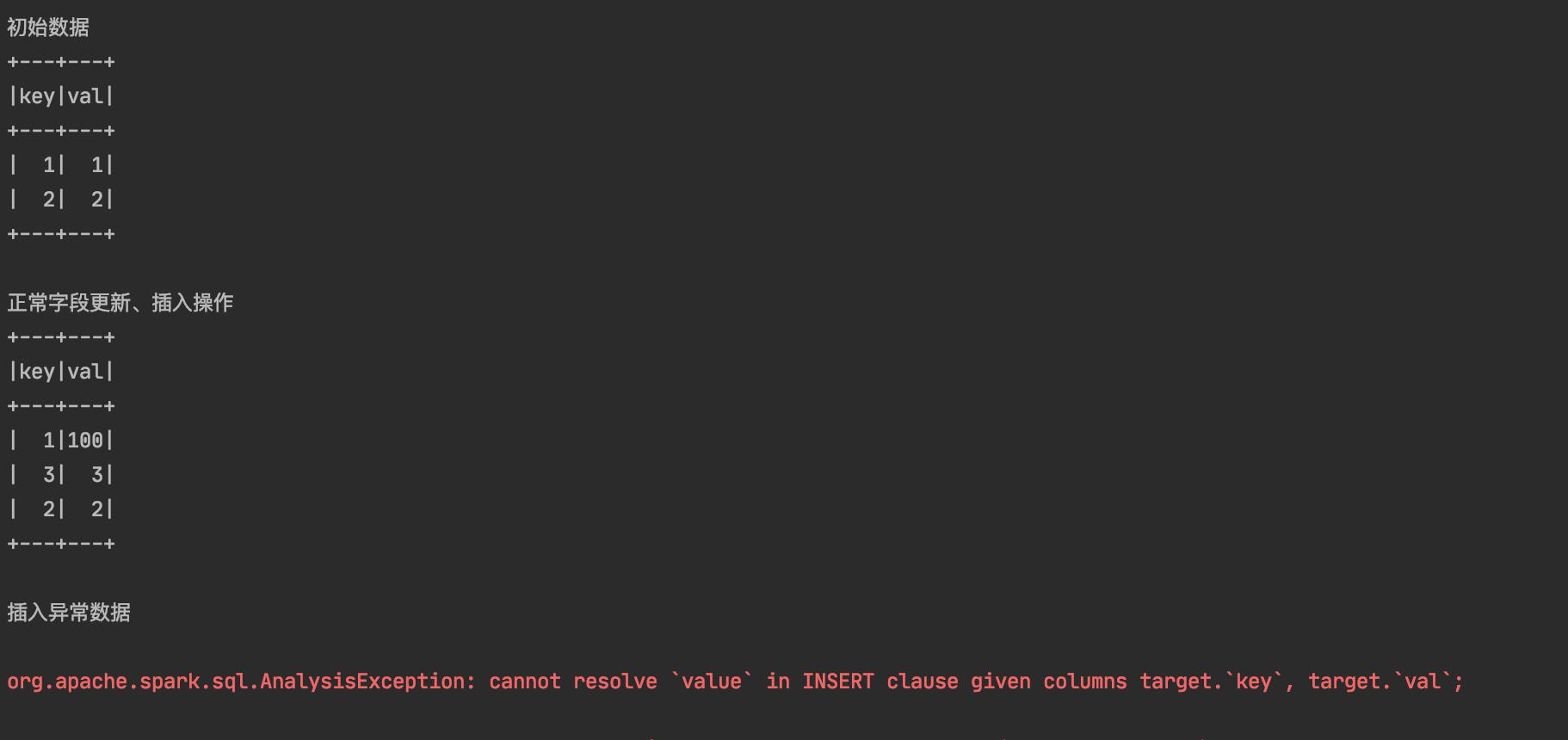
验证字段多余和类型不匹配
在这里新建了一个 KeyVal2 对象,该对象相比较 KeyVal 多了一个 id 字段,在这里我打算把 key=1 的 val 更新为1000,插入一条 key=3,val=3 的数据。
请注意这句代码:dataset.selectExpr("id", "key", "cast(val as long)").as("update") 这句代码包含了此次的验证,新增了 id 字段,并且把 val 的 string 类型强转为了 long 类型
DeltaTable deltaTable = DeltaTable.forPath(tablePath);
System.out.println("初始数据");
deltaTable.toDF().show();
List<KeyVal2> source = new ArrayList<>();
source.add(new KeyVal2(1, "1", "1000"));
source.add(new KeyVal2(3, "3", "3"));
Dataset<Row> dataset =
sparkSession.createDataset(source, Encoders.bean(KeyVal2.class)).toDF();
// updateAll、insertAll 操作
deltaTable.as("target")
.merge(
dataset.selectExpr("id", "key", "cast(val as long)").as("update")
, "update.key = target.key")
.whenMatched()
.updateAll()
.whenNotMatched()
.insertAll()
.execute();
System.out.println("更新结果");
deltaTable.toDF().show();
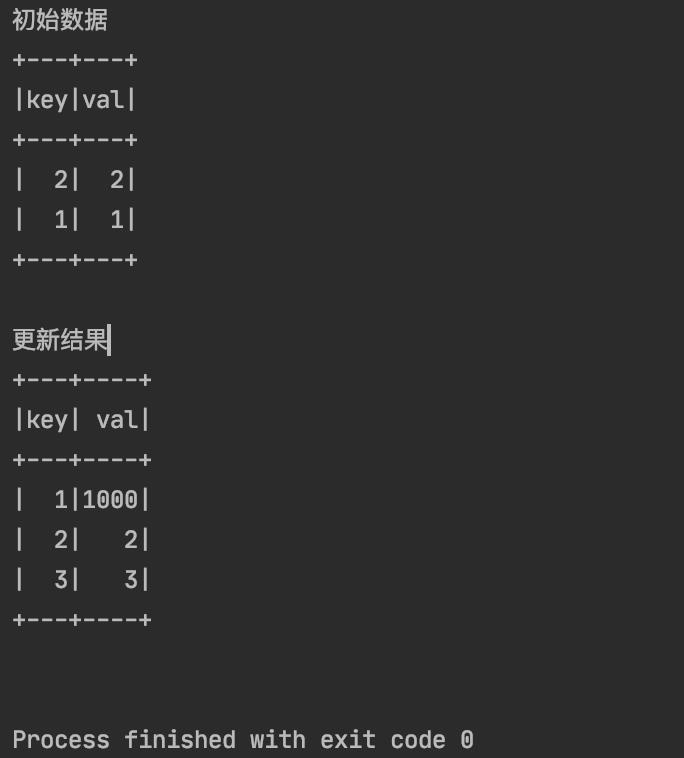
从结果中可以看到,程序正常执行了,并且把 key=1 的 val 更新为1000,插入了一条 key=3,val=3 的数据。而我们 KeyVal2 的 id 字段被忽略更新
验证updateAll、inesrtAll
为了验证updateAll、inesrtAll操作中 delta lake 表中的字段不存在于目标集合,我把验证多字段的例子中dataset.selectExpr("id", "key", "cast(val as long)").as("update")代码改为了dataset.selectExpr("key","val as value").as("update") ,也就是说把 val 字段替换为 value 字段
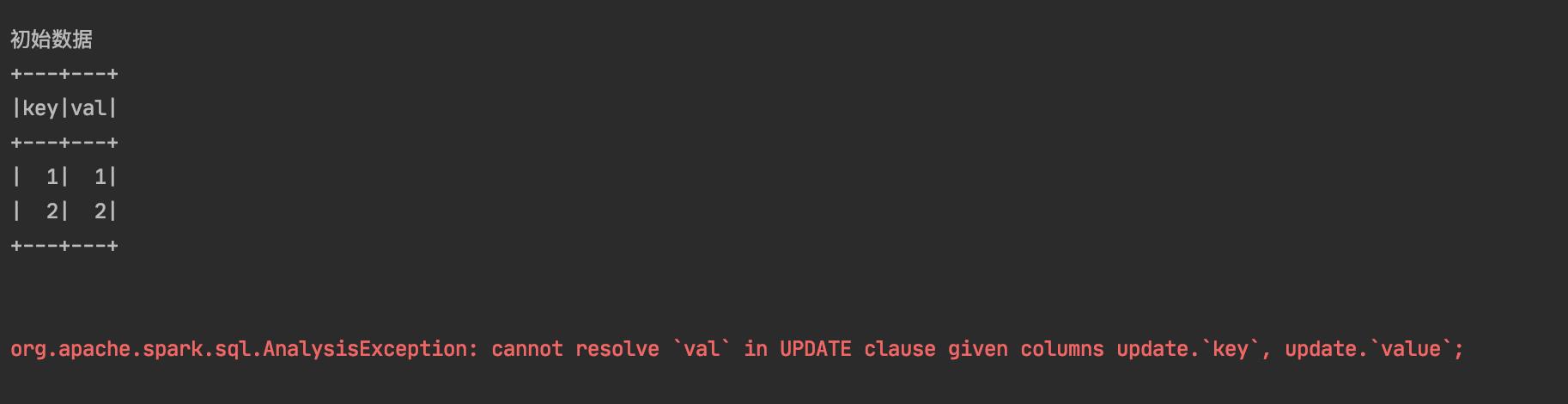
从异常中可以发现,报错内容是目标表中的 val 字段在源数据集 update 中不存在
看完这些有些同学该问了,如果我想通过源数据集的字段,自动向 delta lake 表中新增字段怎么办?当然也是可以的,delte lake 允许用户能够方便地修改表的当前 schema,来适应不断变化的数据。篇幅有限,下篇文章会介绍下 Automatic schema evolution
以上是关于深入剖析 Delta Lake: schema validation的主要内容,如果未能解决你的问题,请参考以下文章