详谈 Delta Lake 系列技术专题 之 Streaming(流式计算)
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详谈 Delta Lake 系列技术专题 之 Streaming(流式计算)相关的知识,希望对你有一定的参考价值。
简介: 本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 的系列技术文章。众所周知,Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。本系列技术文章,将详细展开介绍 Delta Lake。
前言
本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 系列技术文章。众所周知,Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。
此外,阿里云和 Apache Spark 及 Delta Lake 的原厂 Databricks 引擎团队合作,推出了基于阿里云的企业版全托管 Spark 产品——Databricks 数据洞察,该产品原生集成企业版 Delta Engine 引擎,无需额外配置,提供高性能计算能力。有兴趣的同学可以搜索` Databricks 数据洞察`或`阿里云 Databricks `进入官网,或者直接访问 https://www.aliyun.com/product/bigdata/spark 了解详情。
译者:冯加亮(加亮),阿里云计算平台事业部大数据工程师

Delta Lake 技术系列 - 流式计算
目录
- Chapter-01 使用 Delta Lake 解决流式数据入湖的难题
- Chapter-02 使用 Delta Lake 简化股票行情数据的分析
- Chapter-03 Tilting Point 游戏公司是如何使用 Delta Lake 处理流数据
- Chapter-04 使用 Delta Lake 构建流媒体视频的解决方案
本文介绍内容
Delta Lake 系列电子书由 Databricks 出版,阿里云计算平台事业部大数据生态企业团队翻译,旨在帮助领导者和实践者了解 Delta Lake 的全部功能以及它所处的场景。在本文中,Delta Lake 系列-实时流处理场景(The Delta Lake Series Streaming),通过客户最佳实践案例,介绍使用 Delta Lake 做流式数据计算的场景。

Chapter-01 使用 Delta Lake 解决流式数据计算的难题
传统流式数据和数仓数据可分成数据湖和数据仓库两部分。
数据湖的不足
- 很难合并来自不同系统的流数据。
- 在数据湖中想要更新数据几乎是不可能的,尤其在涉及到财务对帐,数据调整,使得流式数据更新尤为重要。
- 数据湖的查询速度通常很慢。
- 优化存储非常困难,并且通常需要复杂的逻辑
数据仓库的不足
- 局限于使用 SQL 分析
- 在场景需要的情况下同时访问流数据和存储数据是非常困难的
- 数据仓库的可伸缩性不好
- 计算和存储无法分离,使得数据仓库使用起来较为昂贵
Delta Lake的优势
(Databrick 官网 Delta Lake 指南: https://docs.databricks.com/delta/index.html)
以上内容介绍了数据湖和数据仓库的局限性,那么 Delta Lake 是如何解决以上的问题呢:
- Delta Lake 中的表既可作为数据源进行大数据分析又可作为目的源表进行流式实时写入,真正实现批流一体。
- Delta 表支持增删操作
- Delta Lake 支持 ACID,使得创建兼容的数据解决方案很容易
- 具有专业的机器学习,ETL 处理,数据分析和查询简单高效
- 计算和存储分离,支持更高效的解决方案

Chapter-02 Delta Lake 在股票行情分析的应用
实时分析股票数据是一项复杂的工作,这其中有大量的流数据需要实时维护同时还要处理历史数据,事务一致性方面面临很大挑战,这些问题在 Delta Lake 架构中通过Apache Spark 的可伸缩性、流计算和灵活的数据分析的能力,以及 ACID 事务性可以轻松解决。
使用 Delta Lake 解决方案架构图
- 通过此架构图,我们清晰的看到将股票价格数据和金融数据实时数据写入 Delta Lake 的两张表里面。
- 然后我们通过读取 Delta Lake 表中的数据做 ETL 数据清洗,并将清洗后的数据写入第三个 Delta Lake 表,用于下游分析
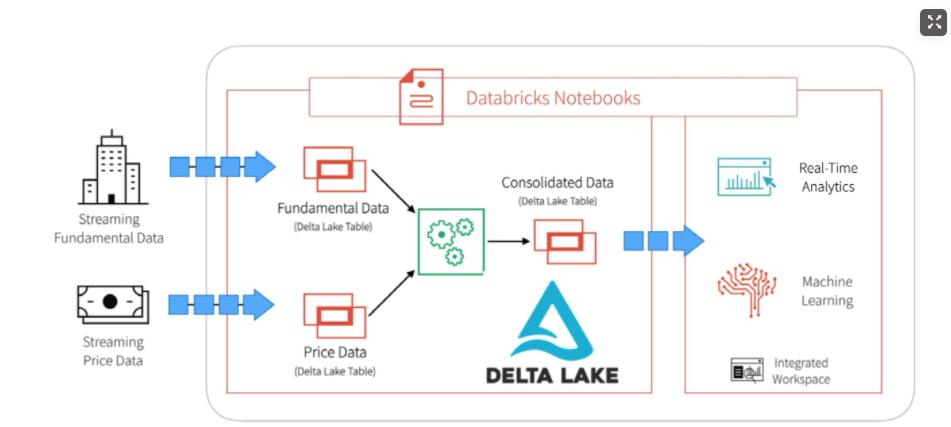
实时的流数据有两类:Fundamentals data 和 Price data,为了模拟这两种数据,我们在Delta Lake 中创建了 Delta 表,使用 .format(‘delta’)并指向 OSS 数据存储
%pyspark # Create Fundamental Data (Databricks Delta table) dfBaseFund = spark \\ .read \\ .format(‘delta’) \\ .load(‘/delta/stocksFundamentals’)
%pyspark # Create Price Data (Databricks Delta table) dfBasePrice = spark \\ .read \\ .format(‘delta’) \\ .load(‘/delta/stocksDailyPrices’)
接下来,我们通过开始和结束日期筛选出来有用的数据,然后将该日期范围的价格和基本数据合并到 OSS
%pyspark
# Determine start and end date of available data
row = dfBasePrice.agg(
func.max(dfBasePrice.price_date).alias(“maxDate”),
func.min(dfBasePrice.price_date).alias(“minDate”)
).collect()[0]
startDate = row[“minDate”]
endDate = row[“maxDate”]
# Define our date range function
def daterange(start_date, end_date):
for n in range(int ((end_date - start_date).days)):
yield start_date + datetime.timedelta(n)
# Define combinePriceAndFund information by date and
def combinePriceAndFund(theDate):
dfFund = dfBaseFund.where(dfBaseFund.price_date == theDate)
dfPrice = dfBasePrice
.where(dfBasePrice.price_date == theDate)
.drop(‘price_date’)
# Drop the updated column
dfPriceWFund = dfPrice.join(dfFund, [‘ticker’]).drop(‘updated’)
# Save data to OSS
dfPriceWFund
.write
.format(‘delta’)
.mode(‘append’)
.save(‘/delta/stocksDailyPricesWFund’)
# Loop through dates to complete fundamentals + price ETL process
for single_date in daterange(
startDate, (endDate + datetime.timedelta(days=1))
):
print ‘Starting ’ + single_date.strftime(‘%Y-%m-%d’)
start = datetime.datetime.now()
combinePriceAndFund(single_date)
end = datetime.datetime.now()
print (end - start)
现在我们有一系列价格数据写入到 oss 中的 /delta/stocksDailyPricesWFund。我们通过读取 OSS 指定路径的数据.format(“Delta”)来创建 Delta Lake 表。
%pyspark
dfPriceWithFundamentals =
spark.readStream \\
.format(“delta”) \\
.load(“/delta/stocksDailyPricesWFund”)
// Create temporary view of the data
dfPriceWithFundamentals.createOrReplaceTempView(“priceWithFundamentals”)
创建一个视图允许我们实时计算价格/收益比率进行分析。
%sql CREATE OR REPLACE TEMPORARY VIEW viewPE AS select ticker, price_date, first(close) as price, (close/eps_basic_net) as pe from priceWithFundamentals where eps_basic_net > 0 group by ticker, price_date, pe
实时分析股票流数据
%sql select * from viewPE where ticker == “AAPL” order by price_date
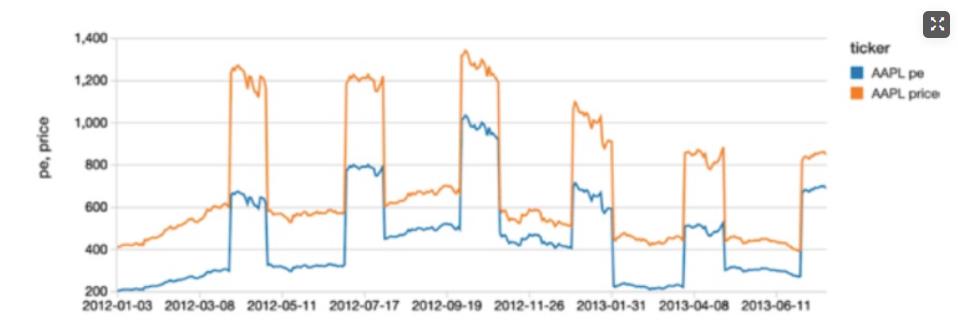
由于整合数据集源数据是 Delta Lake 表,所以这个视图不仅仅显示批处理数据,同时也要展示新的数据流。如下图所示:
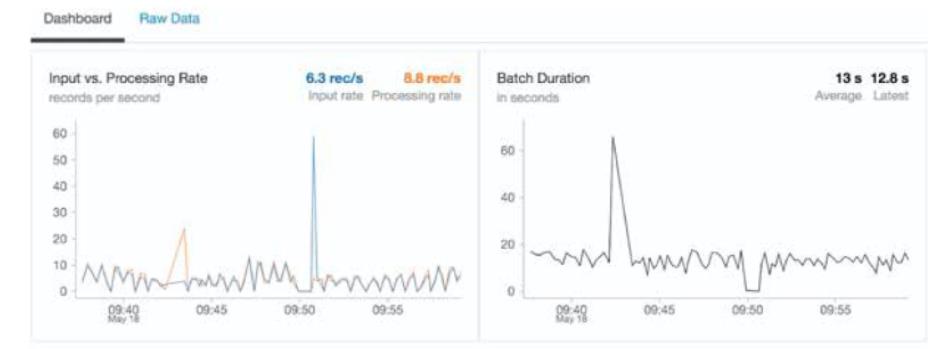
与此同时,使用 Structured Streaming 不仅仅只是实时的将数据写入 Delta Lake,同时也要保持主键的唯一性。
最后,我们演示了如何使用 Delta Lake 简化股票实时数据分析。通过 Spark Structured Streaming 和 Delta Lake,我们可以使用 Databricks 集成的 Workspace 来创建一个具有数据湖和数据仓库优点的高性能、可扩展的解决方案。
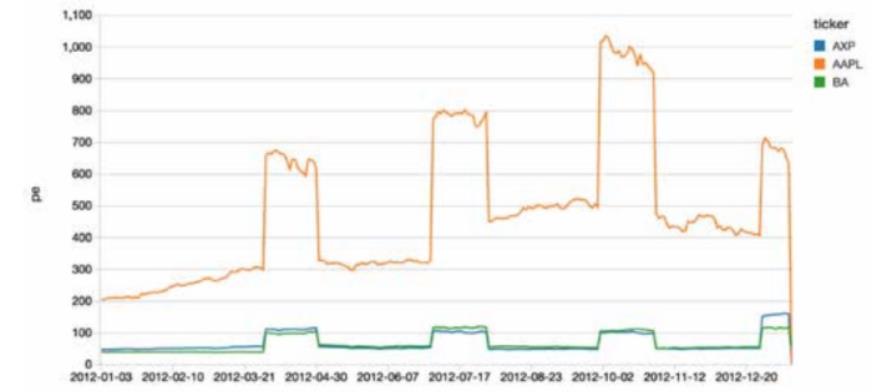
Databricks 统一数据平台消除了通常与流和事务一致性相关的数据工程,使数据工程和数据科学团队能够专注于他们的股票数据。

Chapter-03 Tilting Point 游戏公司使用 Delta Lake 处理流数据
背景
Tilting Point 新一代游戏运营商,在为顶级开发工作室提供专家资源、服务和运营支持,优化高质量的实时游戏等方面,做的都很成功。Tilting Point 通过其用户获取基金和世界级的技术平台,通过绩效营销和游戏直播,帮助开发商实现盈利。通过使用Delta Lake 架构, Tilting Point 公司可以实时的利用高质量的数据进行数据分析。
业务需求分析:
Tilting Point 的团队之前按小时进行游戏分析报告的批处理工作,由于业务需要,他们希望能够在5-10分钟内完成实时报告。
他们还希望根据玩家的实时行为做出游戏内的 LiveOps 决策,将实时数据提供给服务系统,提供关于 LiveOps 变化的实时告警,这些告警会对游戏体验产生很大的影响,我们通过采集这些实时的变化参数将游戏体验尽可能做到极致。
此外,他们必须单独存储加密的个人身份信息 (PII) 数据,以保持 GDPR 的合规。
实时处理数据流的挑战
Tilting Point 有一个专有的软件开发工具,开发人员可以与之集成,将数据从游戏服务器发送到 AWS 中托管的服务器。该服务会删除所有 PII 数据,然后将原始数据发送到 Amazon Firehose 终端。然后 Firehose 将 JSON 格式的数据持续转储到 S3
为了清洗原始数据并使其快速用于分析,团队考虑将连续数据从 Firehose 推送到消息队列(例如 Kafka, Kinesis ),然后使用 Spark 的 Structured Streaming(Databricks Structured Streaming)来连续处理数据并写入 Delta Lake 表。
虽然这种架构听起来非常适合以秒为单位处理低延迟的数据,但实际上 Tilting Point 对它们的 pipeline 并没有这么低的延迟需求。他们希望在分钟级,就能得到可供分析的数据。因此,他们决定取消消息队列来简化架构,而是使用 S3 作为结构化流作业的数据源。使用 S3 作为连续流数据源的关键挑战是如何实时识别最近更新的文件。
每隔几分钟列出所有文件有两个主要问题
- 高延迟:列出包含大量文件的目录中的所有文件会有很高的性能开销,并增加处理时间。
- 高成本:每隔几分钟列出大量文件会迅速增加S3成本。
利用 Structured Streaming,使用 blob 作为 Delta Lake 数据存储。
为了从 S3 云 blob 存储中获取连续流数据,Tilting Point 使用了 Databricks 的“S3- sqs”数据源选项。S3- sqs 提供了从 S3 增量流数据的封装,而不需要对最近处理的文件再编写任何状态管理的代码。
以下是 Tilting Point pipeline:
- 配置 Amazon S3 事件通知,通过 SNS 向 SQS 发送新的数据。
- Tilting Point 使用 S3-SQS 方式源读取到达S3中的新数据。方式如下:
%pyspark spark.readStream \\ .format(“s3-sqs”) \\ .option(“fileFormat”, “json”) \\ .option(“queueUrl”, ...) \\ .schema(...) \\ .load()
- Tilting Point 使用 Structured Streaming 进行数据清洗和转换,基于游戏实时流数据,使用 Spark Streaming foreachBatch API,写入到30个不同的 Delta Lake 表中。
- 流作业过程中会生成大量小文件,这将影响下游消费者的性能,因此,每天都会运行一个优化作业来合并表中的小文件,以便 Delta Lake 表在读取数据时具有良好的性能。
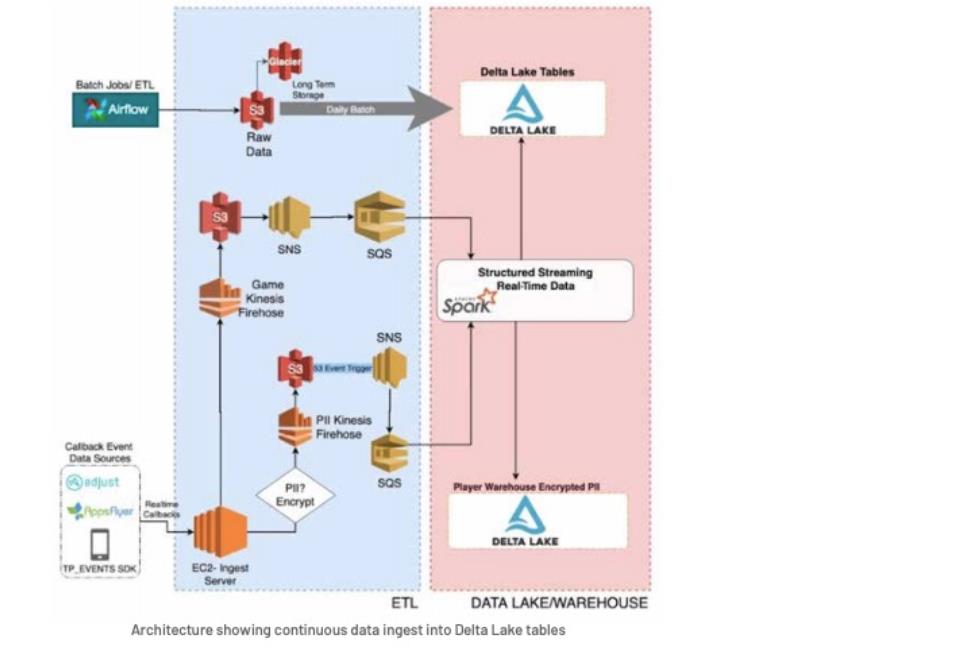
使用 Delta Lake 架构,带来的便利:
- 增加选配项“s3-sqs”,可以增量加载 S3 中的新文件,有助于快速处理新文件,而不会在列出文件时产生太多开销
- 不会显示文件状态管理:无需显示的进行文件状态管理。
- 更低的操作成本:由于我们使用 S3 作为 Firehose 和 Structured Streaming 作业之间的 checkpoint,停止和执行数据的操作负担相对较低
- 数据读写可靠:Delta Lake 提供 ACID(optimistic concurrency control)事务保证。这有助于读写更加可靠。
- 文件压缩:在流处理过程中,会产生很多临时小文件,这会影响读写性能。在 Delta 之前我们必须建立一个不同的表来编写压缩数据。在 Delta Lake 中,由于 ACID 事务,我们可以压缩文件并安全地将数据重写回相同的表中。
- 快照隔离: Delta Lake 的快照允许我们在流作业执行时,修改和压缩数据时 Delta 表也可以正常读取。
- 回滚:写入错误的情况下,Delta Lake 的 Time Travel(Time Travel) 可以帮助我们回滚到表的前一个版本。

Chapter-04 使用 Delta Lake 构建流媒体视频的解决方案
随着传统的付费电视继续停滞不前,内容所有者开始接受直接消费者( D2C )订阅和广告支持的流媒体服务,以从他们的内容库中赚钱。对于那些整个商业模式都围绕着生产优质内容,然后将其授权给分销商的公司来说,向现在玻璃体验的转变需要新的创新力,比如为向消费者提供内容建立媒体供应链,支持各种设备和操作系统的应用程序,并执行帐单和客户服务等客户关系功能。
由于大多数服务都是按月更新的,订阅服务运营商需要随时向用户证明其价值。流媒体视频的一般质量问题(包括缓冲、延迟、像素化、抖动、丢包和空白屏幕)会对业务产生重大影响,无论是增加用户流失率还是降低视频参与度。
浏览频道,点击进入和退出应用程序,从不同的设备同时登录等等。而且,由于电视的本质,最重要、最引人注目、吸引最多观众的活动往往会出问题。如果你开始在社交媒体上收到投诉,你如何判断这些投诉是某个用户独有的,还是地区性或全国性的问题?如果是全国性的,它是跨所有设备还是只跨特定类型(例如,OEM 可能更新了旧设备类型上的操作系统,最终导致与客户端的兼容性问题)?
当考虑到用户的数量、他们正在采取的操作的数量以及体验中的切换(服务器到CDN到ISP到家庭网络到客户端)的数量时,识别、纠正和防止查看者体验质量问题成为一个大数据问题。服务质量( QoS )有助于分析这些数据流,以便您能够理解哪里出了问题、在哪里出了问题以及为什么出了问题。最终,你可以进行预测分析,了解可能出现的问题以及如何提前作出补救措施。
服务质量解决方案概述
这个解决方案的目的是为了统一改善其 QoS 系统的流媒体视频平台。它基于 AWS 实验室提供的 AWS 流媒体分析解决方案,我们随后在此基础上添加了 Databricks 作为统一数据分析平台,用于实时分析和高级分析功能。
通过使用 Databricks(Databricks cumstomers),流媒体平台可以通过始终利用由健壮和可靠的数据管道提供的最完整和最新的数据集来获得更快的见解。通过使用协作环境加速数据科学,这减少了新特性上市的时间。它为管理端到端机器学习生命周期提供支持,并通过为数据工程和数据科学提供统一的平台,降低软件开发所有周期的运营成本
视频 QoS 解决方案架构
由于低延迟的监控警报和视频流量高峰时所需的高度可伸缩的基础设施等复杂性,直接的架构选择是Delta Architecture -像Lambda和Kappa架构这样的标准大数据架构在维护多种类型管道(流和批处理)所需的操作方面都存在缺点,并且缺乏对统一的数据工程和数据科学方法的支持。
Delta 架构优势:
- 数据工程师可以经济有效的方式连续开发数据管道,而不必在批处理和流式之间进行选择,真正的批流一体。
- 数据分析师可以获得接近实时的数据分析结果,来帮助他们做 BI 查询。
- 数据科学家可以开发更好的机器学习模型,使用更可靠的数据集,支持版本回退,便于计算和查询。
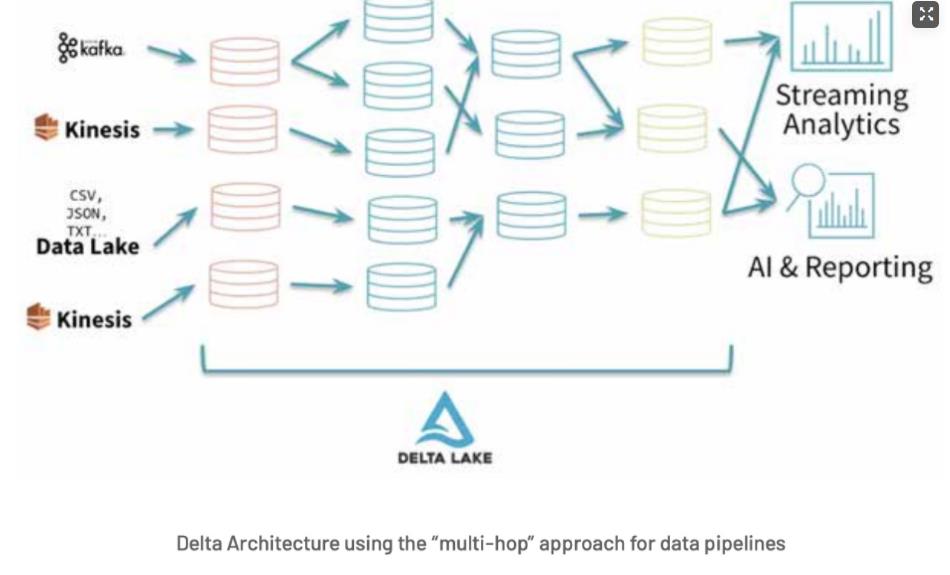
以下是 Delta Lake 经典的三级数据表架构。我们针对每一层级的数据表分别做了如下定义:
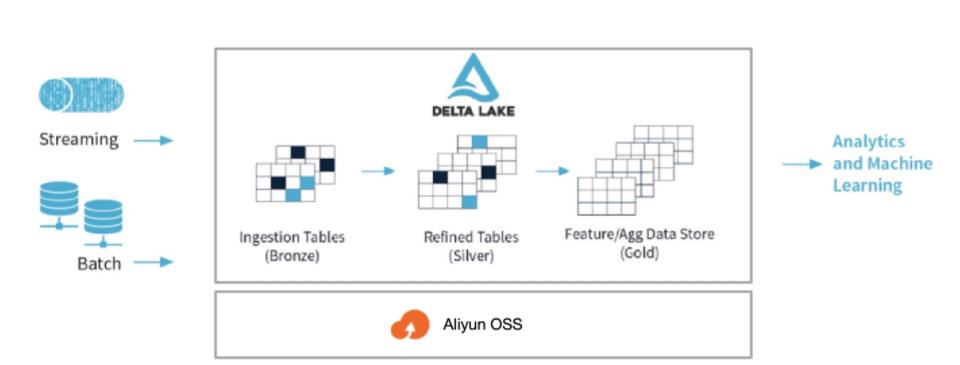
- Bronze 表:存储原生数据( Raw Data ),存放的表或摄入表通常是原生格式的原始数据集( JSON, CSV or txt )。
- Silver 表:该表是在对 Bronze 表的数据进行加工处理的基础上生成的中间表,对Bronze 表做了清洗/转换可以作为数据科学训练的数据。
- Gold 表:基于业务数据表,表数据已经高度集成,可以用于 BI 报表展示的数据。
在完全使用流数据计算的场景里,在 Delta Lake 中间表 DataFrames 的选择上是在延迟 /sla 成本之间做的权衡(例如实时监控报警和基于新内容的推荐系统更新)。
QoS 体系结构是集中在数据处理的解决方案,他不是一个完整的视频点播( VoD )解决方案,通过与一些服务主件的结合例如结合亚马逊网管服务,避免其他的运维工作为数据分析师专注于数据和分析提供保证。
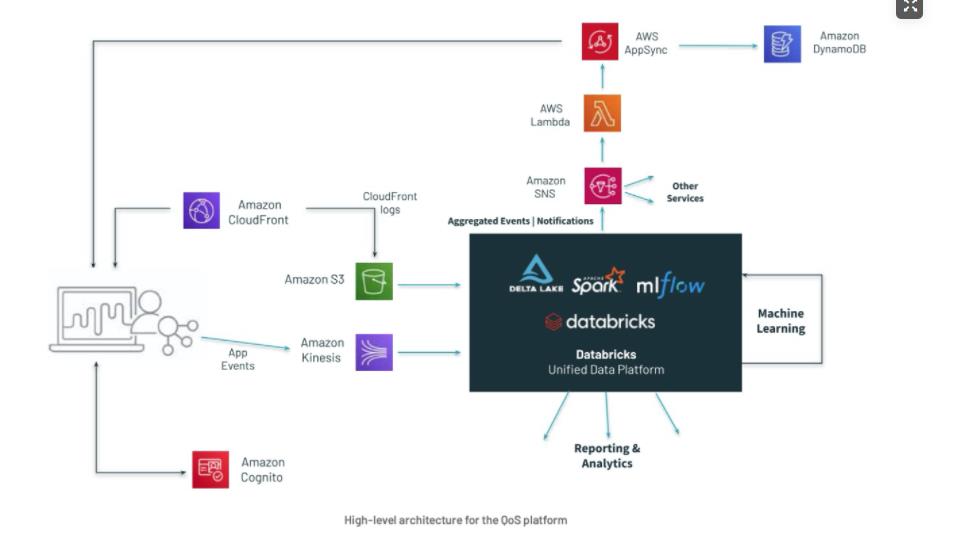
数据写入 Delta Lake
数据准备
在 QoS 解决方案中的两个数据源(应用程序事件和 CDN 日志)都使用了 JSON 格式。
为了让整个组织能够直接查询数据,Bronze to Silver Pipeline 将所有原始数据格式转换为Delta格式。
视频 APP 事件日志
基于该体系结构,视频应用程序事件被直接推送到 Kinesis Stream,然后使用模式(append)写入到 Delta Lake。
在流处理场景下会产生大量的小文件,大量小文件的存在会严重影响数据系统的读性能。Delta Lake 提供了 OPTIMIZE(optimize 性能优化)命令,可以将小文件进行合并压缩。
时间戳和消息类型都是从 JSON 事件中提取的,以便能够对数据进行分区,以及选择想要处理的事件类型。将事件的单个 Kinesis 流与 Delta Lake“events” 表结合在一起,降低操作难度。
CDN 日志
CDN 日志被传送到 S3,所以处理它们的最简单的方法是 Databricks Auto Loader,它在新数据文件到达 S3 时增量地、高效地处理它们,而不需要任何额外的设置。
%pyspark auto_loader_df = spark.readStream.format(“cloudFiles”) \\ .option(“cloudFiles.format”, “json”) \\ .option(“cloudFiles.region”, region) \\ .load(input_location) anonymized_df = auto_loader_df.select(‘*’, ip_ anonymizer(‘requestip’).alias(‘ip’))\\ .drop(‘requestip’)\\ .withColumn(“origin”, map_ip_to_location(col(‘ip’))) anonymized_df.writeStream \\ .option(‘checkpointLocation’, checkpoint_location)\\ .format(‘delta’) \\ .table(silver_database + ‘.cdn_logs’)
创建数字大屏/虚拟网络操作中心
流媒体公司需要尽可能实时地监控网络性能和用户体验,能过跟踪到个体层面,进行分类和打标签,如按照地理位置、设备、网络和历史观看等行为进行划分。这就要求采用网络运营中心 (NOC) 方式,监控流媒体体验的健康状况,并尽早对任何问题做出反应。这使得 NOC 应有一个 Dashboard(databricks dashboards),将用户当前的体验与性能基线进行比较,以便产品团队能够快速、轻松地识别和处理任何服务异常。

NOC 的聚合表基本上是我们的 Delta 体系结构的 Gold 层—— CDN 日志和应用程序事件的 join 后的宽表。支持 SQL 查询的 Dashboard 展示;
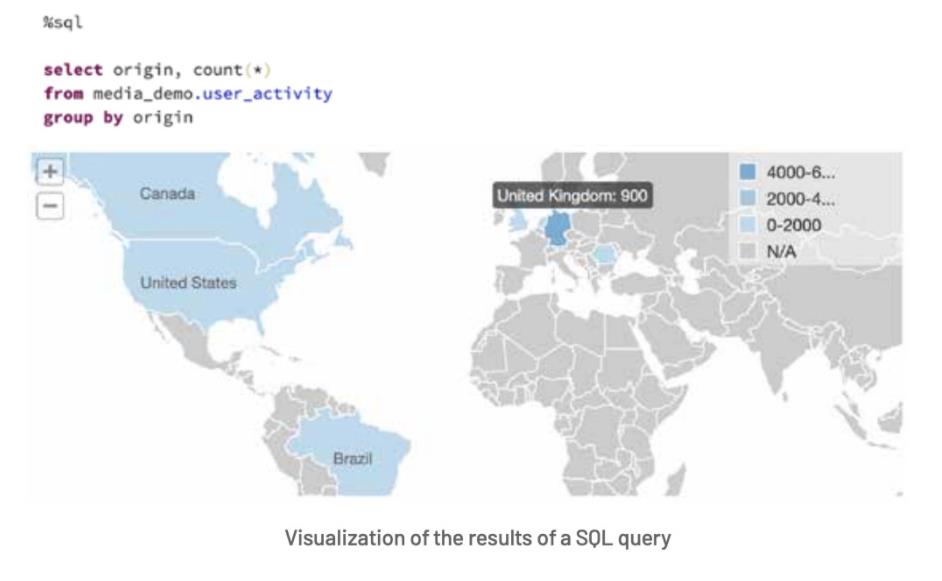
视频加载时间过长、糟糕的视频质量体验对用户流失率有重大影响。最重要的是,广告商也不愿意在减少观众参与度的广告上花钱,这对KPI改进策略有直接影响,在这种情况下,从应用程序端收集尽可能多的信息是至关重要的,这使得分析不仅可以在视频层面上进行,还可以在浏览器甚至是应用程序的类型/版本上进行。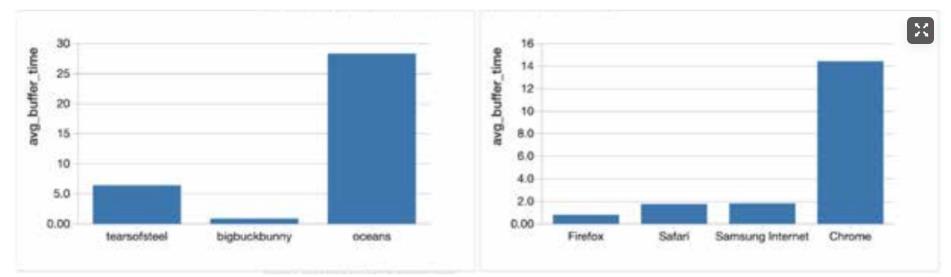
在内容方面,APP 应用程序事件可以提供关于用户行为和整体体验的数据。比如有多少人暂停了视频,实际上已经看完那一集/视频?是什么导致了中断:内容质量或交付问题?当然,进一步的分析可以通过将所有资源(用户行为、cdn / isp 的性能)联系在一起来完成,这样不仅可以创建用户档案,还可以预测用户流失。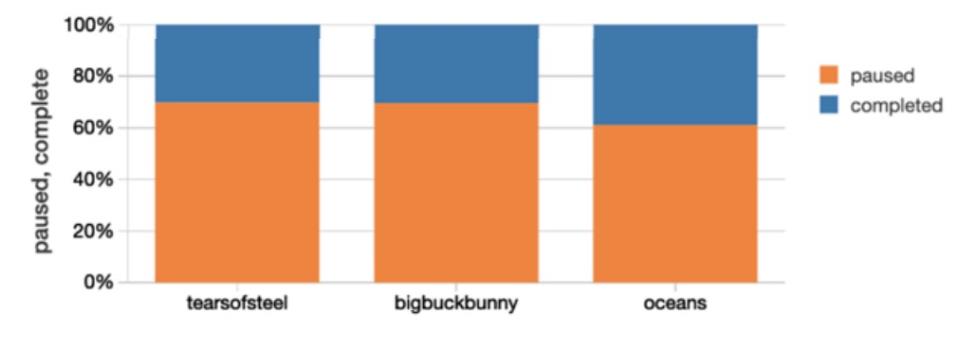
创建(近)实时告警
当处理百万并发用户视频流中产生的数据的速度、数量和多样性时,Dashboard 的复杂性可能会使 NOC 的人工操作员很难专注于当前最重要的数据并找到根源问题。通过预警机制,可以在性能超过某些阈值时设置自动警报,这些阈值可以帮助网络的人工操作员,并通过 Lambda 函数设置自动补救协议。例如:
•如果一个 CDN 的延迟比基线高得多(例如,如果它比基线平均延迟超过10%),启动自动CDN流量转移。
•如果超过[某个阈值,例如5%]的客户报告回放错误,提醒产品团队可能存在特定设备的客户问题。
•如果某个 ISP 的浏览者存在高于平均水平的缓冲和像素化问题,提醒前线的客户代表应对和解决方法。
从技术角度来看,生成实时警报需要一个能够实时处理数据的流媒体引擎和发布-订阅服务来推送通知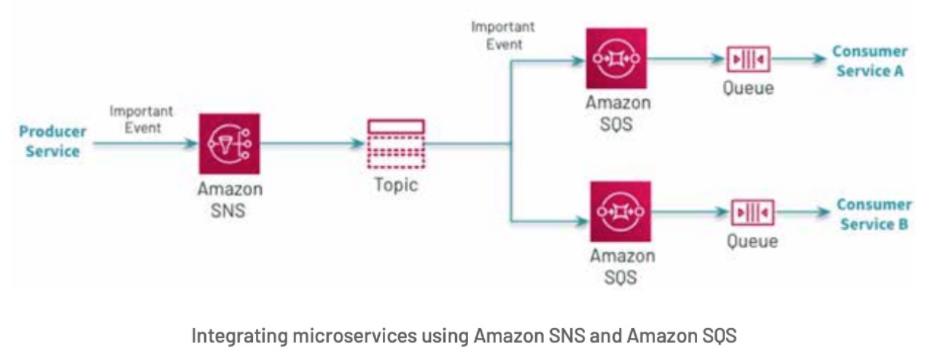
QoS 解决方案通过使用 Amazon SNS 及其与 Amazon Lambda 的集成(参见下面的 web 应用更新)或为其他消费者提供 Amazon SQS 来实现 AWS 集成微服务的最佳实践。
def send_error_notification(row):
sns_client = boto3.client(‘sns’, region)
error_message = ‘Number of errors for the App has exceeded the
threshold {}’.format(row[‘percentage’])
response = sns_client.publish(
TopicArn=,
Message= error_message,
Subject=,
MessageStructure=‘string’)
# Structured Streaming Job
getKinesisStream(“player_events”)\\
.selectExpr(“type”, “app_type”)\\
.groupBy(“app_type”)\\
.apply(calculate_error_percentage)\\
.where(“percentage > {}”.format(threshold)) \\
.writeStream\\
.foreach(send_error_notification)\\
.start()
在基本的电子邮件用例之上,演示播放器包括三个使用 AWS AppSync 实时更新的小部件:活跃用户数量、最受欢迎的视频和同时观看视频的用户数量。
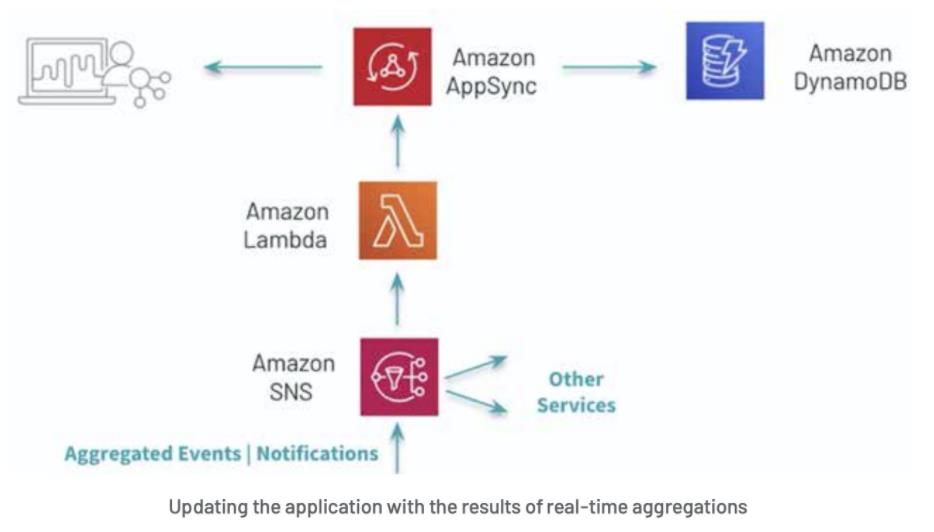
QoS 解决方案采用了类似的方法——结构化流媒体和亚马逊 SNS ——来更新所有的值,允许使用 AWS SQS 插入额外的消费者。当需要对大量事件进行增强和分析时,这是一种常见的模式;一次性预聚合数据,允许每个服务(消费者)在下游做出自己的决定。
未来的展望
机器学习
如果我们想要在未来能够自动做出决策,我们必须整合机器学习算法。作为一个统一的数据平台,Databricks 使数据科学家能够使用内置支持 Hyperopt / Horvod / AutoML 的机器学习运行时或与 MLflow 集成等功能来构建更好的数据科学产品,我们已经在我们的客户基础上探索了一些重要的用例重点关注对 QoS 解决方案的可能扩展。
故障点预测和补救
随着 D2C 流媒体的用户越来越多,即使暂时没有服务,带来的影响也很大。ML 可以帮助运营商从报告转向预防,通过预测可能出现的问题,并在出现问题之前进行补救(例如,并发观看者的激增导致自动切换到一个容量更大的 cdn)。
增加用户流量数
不断增长的订阅服务的关键是保持你拥有的订阅者。通过理解个人级别的服务质量,您可以将 QoS 作为流失和客户生命周期价值模型中的一个变量添加。此外,你还可以为那些存在视频质量问题的用户创建群组,以便测试主动发送信息和保存优惠。
快速入门Databricks在流视频 QoS 解决方案
我们已经寻求为大多数流媒体视频平台环境创建一个快速开始,以嵌入这种 QoS 实时流媒体分析解决方案的方式,有了这个方案,使客户在流媒体视频中有个好的体验,以保持变化无常的观众在你的平台上有足够的娱乐选择。
- 可扩展到任何用户规模。
- 快速预警质量性能问题。
- 足够灵活和模块化,可以轻松地针对您的受众和您的需求进行定制,如创建新的自动警报或使数据科学预测分析和机器学习。
首先,下载 Databricks 的流视频 QoS 解决方案的笔记本。 有关如何将批处理和流数据统一到单个系统中的更多细节指导,请查看 Delta Architecture webinar。

后续
您已经了解了 Delta Lake 及其特性,以及如何进行性能优化,本系列还包括其他内容:
- Delta Lake 技术系列-基础和性能
- Delta Lake 技术系列-特性
- Delta Lake 技术系列-湖仓一体
- Delta Lake 技术系列-客户用例(Use Case)
本文为阿里云原创内容,未经允许不得转载。
以上是关于详谈 Delta Lake 系列技术专题 之 Streaming(流式计算)的主要内容,如果未能解决你的问题,请参考以下文章