详谈 Delta Lake 系列技术专题 之 特性(Features)
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详谈 Delta Lake 系列技术专题 之 特性(Features)相关的知识,希望对你有一定的参考价值。
简介: 本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 的系列技术文章。众所周知,Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。本系列技术文章,将详细展开介绍 Delta Lake。
前言
本文翻译自大数据技术公司 Databricks 针对数据湖 Delta Lake 系列技术文章。众所周知,Databricks 主导着开源大数据社区 Apache Spark、Delta Lake 以及 ML Flow 等众多热门技术,而 Delta Lake 作为数据湖核心存储引擎方案给企业带来诸多的优势。
此外,阿里云和 Apache Spark 及 Delta Lake 的原厂 Databricks 引擎团队合作,推出了基于阿里云的企业版全托管 Spark 产品——Databricks 数据洞察,该产品原生集成企业版 Delta Engine 引擎,无需额外配置,提供高性能计算能力。有兴趣的同学可以搜索` Databricks 数据洞察`或`阿里云 Databricks `进入官网,或者直接访问https://www.aliyun.com/product/bigdata/spark 了解详情。
译者:张鹏(卓昇),阿里云计算平台事业部技术专家

Delta Lake 技术系列 - 特性(Features)
——使用 Delta Lake 稳定的特性来可靠的管理您的数据

目录
- Chapter-01 为什么使用 Delta Lake 的 MERGE 功能?
- Chapter-02 使用 Python API 在 Delta Lake 数据表上进行简单,可靠的更新和删除操作
- Chapter-03 大型数据湖的 Time Travel 功能
- Chapter-04 轻松克隆您的 Delta Lake 以方便测试,数据共享以及进行重复的机器学习
- Chapter-05 在 Apache Spark 上的 Delta Lake 中启用 Spark SQL 的 DDL 和 DML 语句
本文介绍内容
Delta Lake 系列电子书由 Databricks 出版,阿里云计算平台事业部大数据生态企业团队翻译,旨在帮助领导者和实践者了解 Delta Lake 的全部功能以及它所处的场景。在本文 Delta Lake 系列 - 特性( Features )中,重点介绍 Delta Lake 的特性。
后续
读完本文后,您不仅可以了解 Delta Lake 提供了那些特性,还可以理解这些的特性是如何带来实质性的性能改进的。

什么是 Delta Lake?
Delta Lake 是一个统一的数据管理系统,为云上数据湖带来数据可靠性和快速分析。Delta Lake 运行在现有数据湖之上,并且与 Apache Spark 的 API 完全兼容。
在 Databricks 中,我们看到了 Delta Lake 如何为数据湖带来可靠性、高性能和生命周期管理。我们的客户已经验证,Delta Lake 解决了以下挑战:从复杂的数据格式中提取数据、很难删除符合要求的数据、以及为了进行数据捕获从而修改数据所带来的问题。
通过使用 Delta Lake,您可以加快高质量数据导入数据湖的速度,团队也可以在安全且可扩展云服务上快速使用这些数据。

Chapter-01 为什么使用 Delta Lake 的 MERGE 功能?

Delta Lake 是在 Apache Spark 之上构建的下一代引擎,支持 MERGE 命令,该命令使您可以有效地在数据湖中上传和删除记录。
MERGE 命令大大简化了许多通用数据管道的构建方式-所有重写整个分区的低效且复杂的多跳步骤现在都可以由简单的 MERGE 查询代替。
这种更细粒度的更新功能简化了如何为各种用例(从变更数据捕获到 GDPR )构建大数据管道的方式。您不再需要编写复杂的逻辑来覆盖表同时克服快照隔离的不足。
随着数据的变化,另一个重要的功能是在发生错误写入时能够进行回滚。 Delta Lake 还提供了带有时间旅行特性的回滚功能,因此如果您合并不当,则可以轻松回滚到早期版本。
在本章中,我们将讨论需要更新或删除现有数据的常见用例。我们还将探讨新增和更新固有的挑战,并说明 MERGE 如何解决这些挑战。

什么时候需要 upserts?
在许多常见场景中,都需要更新或删除数据湖中的现有数据:
- 遵守通用数据保护法规(GDPR):随着 GDPR 中数据遗忘规则(也称为数据擦除)的推出,组织必须根据要求删除用户的信息。数据擦除还包括删除数据湖中的用户信息。
- 更改传统数据库中获得的数据:在面向服务的体系结构中,典型的 web 和移动应用程序采用微服务架构,这些微服务架构一般是基于具有低延迟性能的传统 SQL/NoSQL 数据库搭建的。组织面临的最大挑战之一是将许多孤立的数据系统建立连接,因此数据工程师建立了管道,可以将所有数据源整合到中央数据湖中以加快分析。这些管道必须定期读取传统 SQL/NoSQL 表所做的更改,并将其应用于数据湖中的对应表中。此类更改可以支持多种形式:变化缓慢的表,所有插入/更新/删除数据的数据变更等。
- 会话化:从产品分析,到目标广告,再到预测性维护的许多领域,将多个事件分组为一个会话是常见的例子。建立连续的应用来跟踪会话并记录写入数据湖的结果是非常困难的,因为数据湖经常因为追加的数据而进行优化。
- 重复数据删除:常见的数据管道用例是通过追加数据的方式来将系统日志收集到 Delta Lake 表中。但是数据源通常会生成重复记录,并且需要下游删除重复数据来处理它们。
为什么对数据湖的 upserts 在传统上具有挑战性
由于数据湖基本上是基于文件的,它们经常针对新增数据而不是更改现有数据进行优化。因此构建上述用例一直是具有挑战性的。
用户通常会读取整个表(或分区的子集),然后将其覆盖。因此,每个组织都尝试通过编写复杂的查询 SQL,Spark 等方式来重新造轮子,来满足他们的需求。这种方法的特点是:
- 低效:为了更新很少的记录而读取和重写整个分区(或整个表)会导致管道运行缓慢且成本高昂。手动调整表布局以及优化查询是很繁琐的,而且需要深厚的领域知识。
- 有可能出错:手写代码来修改数据很容易出现逻辑和人为错误。例如,多个管道在没有任何事务支持的情况下同时修改同一张表可能会导致不可预测的数据不一致,在最坏的情况下有可能会导致数据丢失。通常,即使是单一的手写管道也可能由于业务逻辑中的错误,从而导致数据损坏。
- 难以维护:从根本上来说,这类手写代码难以理解,跟踪和维护。从长远来看,仅此一项就会显着增加组织和基础设施成本。
介绍 Delta Lake 中 MERGE 命令
使用 Delta Lake,您可以使用以下 MERGE 命令轻松解决上述用例,并且不会遇到任何上述问题:
让我们通过一个简单的示例来了解如何使用 MERGE。 假设您有一个变化缓慢的用户数据表,该表维护着诸如地址之类的用户信息。 此外您还有一个现有用户和新用户的新地址表。 要将所有新地址合并到主用户表中,可以运行以下命令:
MERGE INTO users
USING updates
ON users.userId = updates.userId
WHEN MATCHED THEN
UPDATE SET address = updates.addresses
WHEN NOT MATCHED THEN
INSERT (userId, address) VALUES (updates.userId, updates.address)
这完全符合语法的要求-对于现有用户(即 MATCHED 子句),它将更新 address 列,对于新用户(即 NOT MATCHED 子句),它将插入所有列。 对于具有 TB 规模的大型数据表,Delta Lake MERGE 操作比覆盖整个分区或表要快N个数量级,因为 Delta Lake 仅读取相关文件并更新它们。 具体来说,Delta Lake 的 MERGE 命令具有以下优势:
- 细粒度:该操作以文件而不是分区的粒度重写数据,这样解决了重写分区,使用 MSCK 更新 Hive 元数据库等所有复杂问题。
- 高效:Delta Lake 的数据 skip 功能使 MERGE 在查找要重写的文件方面更高效,从而无需手动优化管道。 此外 Delta Lake 对所有 I/O 和处理过程进行了优化,使得 MERGE 进行所有数据的读写速度明显快于 Apache Spark 中的类似操作。
- 事务性:Delta Lake 使用乐观并发控制来确保并发写入程序使用 ACID 事务来正确更新数据,同时并发读取程序始终会看到一致的数据快照。
下图是 MERGE 与手写管道的直观对比。
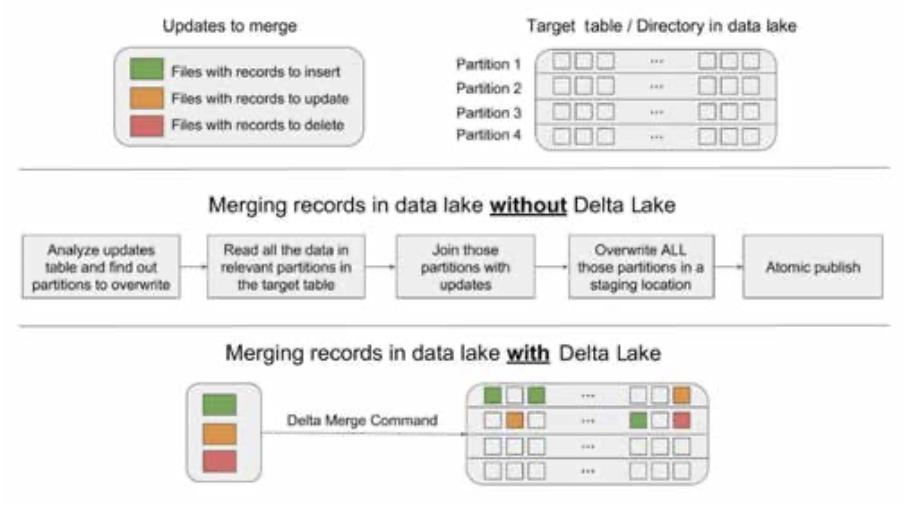
使用 MERGE 简化用例
遵守 GDPR 而删除数据
遵守 GDPR 的“被遗忘权”条款对数据湖中的数据进行任何处理都不容易。您可以使用示例代码来设置一个简单的定时计划作业,如下所示,删除所有选择退出服务的用户。
MERGE INTO users USING opted_out_users ON opted_out_users.userId = users.userId WHEN MATCHED THEN DELETE
数据库中的数据变更应用
您可以使用 MERGE 语法轻松地将外部数据库的所有数据更改(更新,删除,插入)应用到 Delta Lake 表中,如下所示:
MERGE INTO users USING ( SELECT userId, latest.address AS address, latest.deleted AS deleted FROM ( SELECT userId, MAX(struct(TIME, address, deleted)) AS latest FROM changes GROUP BY userId ) ) latestChange ON latestChange.userId = users.userId WHEN MATCHED AND latestChange.deleted = TRUE THEN DELETE WHEN MATCHED THEN UPDATE SET address = latestChange.address WHEN NOT MATCHED AND latestChange.deleted = FALSE THEN INSERT (userId, address) VALUES (userId, address)

从 streaming 管道更新会话信息
如果您有流事件的数据流入,并且想要对流事件数据进行会话化,同时增量更新会话并将其存储在 Delta Lake 表中,则可以使用结构化数据流和 MERGE 中的 foreachBatch 来完成此操作。 例如,假设您有一个结构化流数据框架,该框架为每个用户计算更新的 session 信息。 您可以在所有会话应用中启动流查询,更新数据到 Delta Lake 表中,如下所示(Scala 语言)。
streamingSessionUpdatesDF.writeStream
.foreachBatch { (microBatchOutputDF: DataFrame, batchId: Long) =>
microBatchOutputDF.createOrReplaceTempView(“updates”) microBatchOutputDF.sparkSession.sql(s”””
MERGE INTO sessions
USING updates
ON sessions.sessionId = updates.sessionId
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT * “””)
}.start()

Chapter-02 使用Python API在Delta Lake数据表上进行简单,可靠的更新和删除操作

在本章中,我们将演示在飞机时刻表的场景中,如何在 Delta Lake 中使用 Python 和新的 Python API。 我们将展示如何新增,更新和删除数据,如何使用 time travle 功能来查询旧版本数据,以及如何清理较旧的版本。
Delta Lake 使用入门
Delta Lake 软件包可以通过 PySpark 的--packages 选项来进行安装。在我们的示例中,我们还将演示在 VACUUM 文件和 Apache Spark 中执行 Delta Lake SQL 命令的功能。 由于这是一个简短的演示,因此我们还将启用以下配置:
spark.databricks.delta.retentionDurationCheck.enabled=false
允许我们清理文件的时间短于默认的保留时间7天。 注意,这仅是对于 SQL 命令 VACUUM 是必需的。
spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension
在 Apache Spark 中启用 Delta Lake SQL 命令;这对于 Python 或 Scala API 调用不是必需的。
# Using Spark Packages ./bin/pyspark --packages io.delta:delta-core_2.11:0.4.0 --conf “spark. databricks.delta.retentionDurationCheck.enabled=false” --conf “spark. sql.extensions=io.delta.sql.DeltaSparkSessionExtension”
Delta Lake 数据的加载和保存
这次将使用准时飞行数据或离港延误数据,这些数据是从 RITA BTS 航班离岗统计中心生成的;这些数据的一些示例包括 2014 Flight Departure Performance via d3.js Crossfilter 和 针对Apache Spark的具有图形化结构的准时飞行数据。 在 PySpark 中,首先读取数据集。
# Location variables tripdelaysFilePath = “/root/data/departuredelays.csv” pathToEventsTable = “/root/deltalake/departureDelays.delta” # Read flight delay data departureDelays = spark.read \\ .option(“header”, “true”) \\ .option(“inferSchema”, “true”) \\ .csv(tripdelaysFilePath)
接下来,我们将离港延迟数据保存到 Delta Lake 表中。 在保存的过程中,我们能够利用它的优势功能,包括 ACID 事务,统一批处理,streaming 和 time travel。
# Save flight delay data into Delta Lake format departureDelays \\ .write \\ .format(“delta”) \\ .mode(“overwrite”) \\ .save(“departureDelays.delta”)
注意,这种方法类似于保存 Parquet 数据的常用方式。 现在您将指定格式(“delta”)而不是指定格式(“parquet”)。如果要查看基础文件系统,您会注意到为 Delta Lake 的离港延迟表创建了四个文件。
/departureDelays.delta$ ls -l . .. _delta_log part-00000-df6f69ea-e6aa-424b-bc0e-f3674c4f1906-c000.snappy.parquet part-00001-711bcce3-fe9e-466e-a22c-8256f8b54930-c000.snappy.parquet part-00002-778ba97d-89b8-4942-a495-5f6238830b68-c000.snappy.parquet Part-00003-1a791c4a-6f11-49a8-8837-8093a3220581-c000.snappy.parquet
现在,让我们重新加载数据,但是这次我们的数据格式将由 Delta Lake 支持。
# Load flight delay data in Delta Lake format delays_delta = spark \\ .read \\ .format(“delta”) \\ .load(“departureDelays.delta”) # Create temporary view delays_delta.createOrReplaceTempView(“delays_delta”) # How many flights are between Seattle and San Francisco spark.sql(“select count(1) from delays_delta where origin = ‘SEA’ and destination = ‘SFO’”).show()
运行结果:
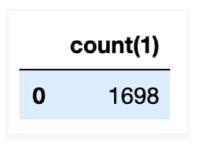
最后,我们确定了从西雅图飞往旧金山的航班数量;在此数据集中,有1698个航班。
立马转换到 Delta Lake
如果您有现成的 Parquet 表,则可以将它们转换为 Delta Lake 格式,从而无需重写表。 如果要转换表,可以运行以下命令。
from delta.tables import * # Convert non partitioned parquet table at path ‘/path/to/table’ deltaTable = DeltaTable.convertToDelta(spark, “parquet.`/path/to/ table`”) # Convert partitioned parquet table at path ‘/path/to/table’ and partitioned by integer column named ‘part’ partitionedDeltaTable = DeltaTable.convertToDelta(spark, “parquet.`/path/to/table`”, “part int”)
删除我们的航班数据
要从传统的数据湖表中删除数据,您将需要:
- 从表中选择所有数据,排除要删除的行
- 根据上面的查询创建一个新表
- 删除原始表
- 将新表重命名为原始表名,以获取下游依赖关系来代替执行所有这些步骤。使用 Delta Lake,我们可以通过运行 DELETE 语句来简化此过程。 为了展示这一点,让我们删除所有早点或准点抵达的航班(即,延误<0)。
from delta.tables import * from pyspark.sql.functions import * # Access the Delta Lake table deltaTable = DeltaTable.forPath(spark, pathToEventsTable ) # Delete all on-time and early flights deltaTable.delete(“delay < 0”) # How many flights are between Seattle and San Francisco spark.sql(“select count(1) from delays_delta where origin = ‘SEA’ and destination = ‘SFO’”).show()

从上面的查询中可以看到,我们删除了所有准时航班和早班航班(更多信息,请参见下文),从西雅图到旧金山的航班有837班延误。 如果您查看文件系统,会注意到即使删除了一些数据,还是有更多文件。
/departureDelays.delta$ ls -l _delta_log part-00000-a2a19ba4-17e9-4931-9bbf-3c9d4997780b-c000.snappy.parquet part-00000-df6f69ea-e6aa-424b-bc0e-f3674c4f1906-c000.snappy.parquet part-00001-711bcce3-fe9e-466e-a22c-8256f8b54930-c000.snappy.parquet part-00001-a0423a18-62eb-46b3-a82f-ca9aac1f1e93-c000.snappy.parquet part-00002-778ba97d-89b8-4942-a495-5f6238830b68-c000.snappy.parquet part-00002-bfaa0a2a-0a31-4abf-aa63-162402f802cc-c000.snappy.parquet part-00003-1a791c4a-6f11-49a8-8837-8093a3220581-c000.snappy.parquet part-00003-b0247e1d-f5ce-4b45-91cd-16413c784a66-c000.snappy.parquet
在传统的数据湖中,删除是通过重写整个表(不包括要删除的值)来执行的。 使用 Delta Lake,可以通过有选择地写入包含要删除数据的文件的新版本来执行删除操作,同时仅将以前的文件标记为已删除。 这是因为 Delta Lake 使用多版本并发控制(MVCC)对表执行原子操作:例如,当一个用户正在删除数据时,另一用户可能正在查询之前的版本。这种多版本模型还使我们能够回溯时间(即 time travel)并查询以前的版本,这个功能稍后我们将看到。
更新我们的航班数据
要更新传统数据湖表中的数据,您需要:
- 从表中选择所有数据,不包括想要修改的行。
- 修改需要更新/更改的行
- 合并这两个表以创建一个新表
- 删除原始表
- 将新表重命名为原始表名,以实现下游依赖
代替上面的步骤,使用 Delta Lake 我们可以通过运行 UPDATE 语句来简化此过程。 为了显示这一点,让我们更新所有从底特律到西雅图的航班。
# Update all flights originating from Detroit to now be
originating from Seattle
deltaTable.update(“origin = ‘DTW’”, { “origin”: “’SEA’” } )
# How many flights are between Seattle and San Francisco
spark.sql(“select count(1) from delays_delta where origin = ‘SEA’
and destination = ‘SFO’”).show()

如今底特律航班已被标记为西雅图航班,现在我们有986航班从西雅图飞往旧金山。如果您要列出您的离岗延迟文件系统(即 $ ../departureDelays/ls -l),您会注意到现在有11个文件(而不是删除文件后的8个文件和表创建后的4个文件)。
合并我们的航班数据
使用数据湖时,常见的情况是将数据连续追加到表中。这通常会导致数据重复(您不想再次将其插入表中),需要插入的新行以及一些需要更新的行。 使用 Delta Lake,所有这些都可以通过使用合并操作(类似于 SQL MERGE 语句)来实现。
让我们从一个样本数据集开始,您将通过以下查询对其进行更新,插入或删除重复数据。
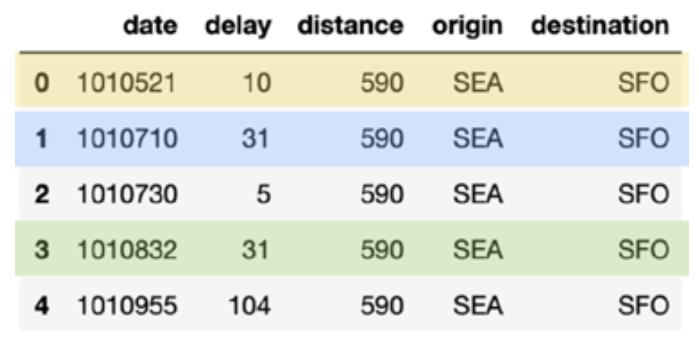
# What flights between SEA and SFO for these date periods spark.sql(“select * from delays_delta where origin = ‘SEA’ and destination = ‘SFO’ and date like ‘1010%’ limit 10”).show()
该查询的输出如下表所示。 请注意,已添加颜色编码以清楚地标识哪些行是已删除的重复数据(蓝色),已更新的数据(黄色)和已插入的数据(绿色)。
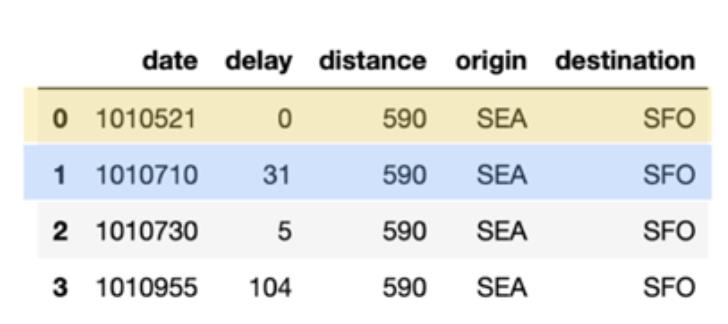
接下来,让我们生成自己的 merge_table,其中包含将插入,更新或删除重复的数据。具体看以下代码段
items = [(1010710, 31, 590, ‘SEA’, ‘SFO’), (1010521, 10, 590, ‘SEA’, ‘SFO’), (1010822, 31, 590, ‘SEA’, ‘SFO’)] cols = [‘date’, ‘delay’, ‘distance’, ‘origin’, ‘destination’] merge_table = spark.createDataFrame(items, cols) merge_table.toPandas()
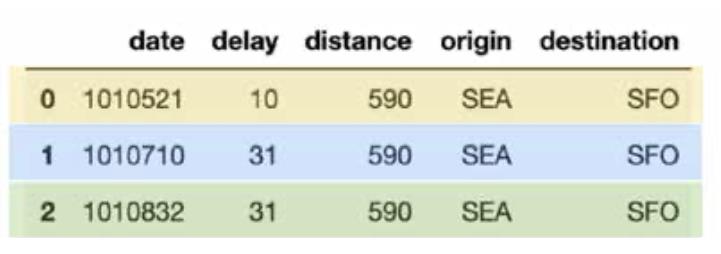
在上表(merge_table)中,有三行不同的日期值:
- 1010521:此行需要使用新的延迟值(黄色)更新排期表。
- 1010710:此行是重复的(蓝色)
- 1010832:这是要插入的新行(绿色)
使用 Delta Lake,可以通过合并语句轻松实现,具体看下面代码片段。
# Merge merge_table with flights
deltaTable.alias(“flights”) \\
.merge(merge_table.alias(“updates”),”flights.date = updates.date”) \\
.whenMatchedUpdate(set = { “delay” : “updates.delay” } ) \\ .whenNotMatchedInsertAll() \\
.execute()
# What flights between SEA and SFO for these date periods
spark.sql(“select * from delays_delta where origin = ‘SEA’ and destination = ‘SFO’ and date like ‘1010%’ limit 10”).show()
一条语句即可有效完成删除重复数据,更新和插入这三个操作。
查看数据表历史记录
如前所述,在我们进行每个事务(删除,更新)之后,在文件系统中创建了更多文件。 这是因为对于每个事务,都有不同版本的 Delta Lake 表。
这可以通过使用 DeltaTable.history() 方法看到,如下所示。
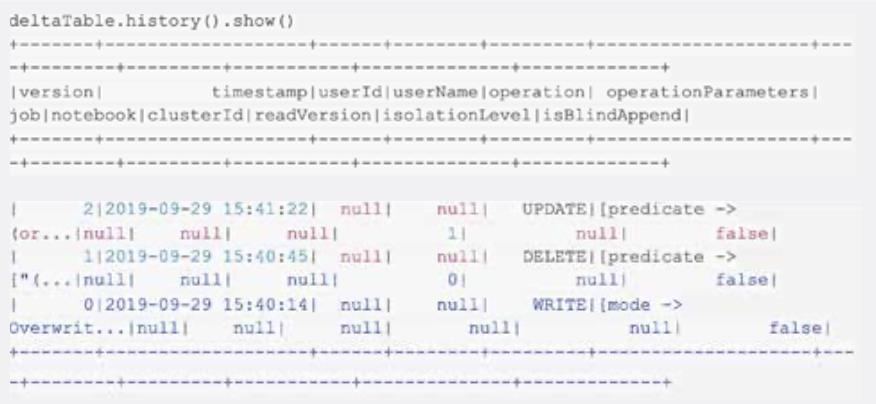
注意,您还可以使用 SQL 执行相同的任务:
spark.sql(“DESCRIBE HISTORY ‘” + pathToEventsTable + “’”).show()
如您所见,对于每个操作(创建表,删除和更新),都有三行代表表的不同版本(以下为简化版本,以帮助简化阅读):

回溯数据表的历史
借助 Time Travel,您可以查看带有版本或时间戳的 Delta Lake 表。要查看历史数据,请指定版本或时间戳选项。 在以下代码段中,我们将指定版本选项。
# Load DataFrames for each version dfv0 = spark.read.format(“delta”).option(“versionAsOf”, 0).load(“departureDelays.delta”) dfv1 = spark.read.format(“delta”).option(“versionAsOf”, 1).load(“departureDelays.delta”) dfv2 = spark.read.format(“delta”).option(“versionAsOf”, 2).load(“departureDelays.delta”) # Calculate the SEA to SFO flight counts for each version of history cnt0 = dfv0.where(“origin = ‘SEA’”).where(“destination = ‘SFO’”).count() cnt1 = dfv1.where(“origin = ‘SEA’”).where(“destination = ‘SFO’”).count() cnt2 = dfv2.where(“origin = ‘SEA’”).where(“destination = ‘SFO’”).count() # Print out the value print(“SEA -> SFO Counts: Create Table: %s, Delete: %s, Update: %s” % (cnt0, cnt1, cnt2)) ## Output SEA -> SFO Counts: Create Table: 1698, Delete: 837, Update: 986
无论是用于治理,风险管理,合规(GRC)还是错误时进行回滚,Delta Lake 表都包含元数据(例如,记录操作员删除的事实)和数据(例如,实际删除的行)。但是出于合规性或大小原因,我们如何删除数据文件?
使用 vacuum 清理旧版本的数据表
默认情况下,Delta Lake vacuum 方法将删除所有超过7天参考时间的行(和文件)。如果要查看文件系统,您会注意到表的11个文件。
/departureDelays.delta$ ls -l _delta_log part-00000-5e52736b-0e63-48f3-8d56-50f7cfa0494d-c000.snappy.parquet part-00000-69eb53d5-34b4-408f-a7e4-86e000428c37-c000.snappy.parquet part-00000-f8edaf04-712e-4ac4-8b42-368d0bbdb95b-c000.snappy.parquet part-00001-20893eed-9d4f-4c1f-b619-3e6ea1fdd05f-c000.snappy.parquet part-00001-9b68b9f6-bad3-434f-9498-f92dc4f503e3-c000.snappy.parquet part-00001-d4823d2e-8f9d-42e3-918d-4060969e5844-c000.snappy.parquet part-00002-24da7f4e-7e8d-40d1-b664-95bf93ffeadb-c000.snappy.parquet part-00002-3027786c-20a9-4b19-868d-dc7586c275d4-c000.snappy.parquet part-00002-f2609f27-3478-4bf9-aeb7-2c78a05e6ec1-c000.snappy.parquet part-00003-850436a6-c4dd-4535-a1c0-5dc0f01d3d55-c000.snappy.parquet Part-00003-b9292122-99a7-4223-aaa9-8646c281f199-c000.snappy.parquet
要删除所有文件,以便仅保留当前数据快照,您可以 vacuum 方法指定一个较小的值(而不是默认保留7天)。
# Remove all files older than 0 hours old. deltaTable.vacuum(0) Note, you perform the same task via SQL syntax: ̧ # Remove all files older than 0 hours old spark.sql(“VACUUM ‘” + pathToEventsTable + “‘ RETAIN 0 HOURS”)
清理完成后,当您查看文件系统时,由于历史数据已被删除,您会看到更少的文件。
/departureDelays.delta$ ls -l _delta_log part-00000-f8edaf04-712e-4ac4-8b42-368d0bbdb95b-c000.snappy.parquet part-00001-9b68b9f6-bad3-434f-9498-f92dc4f503e3-c000.snappy.parquet part-00002-24da7f4e-7e8d-40d1-b664-95bf93ffeadb-c000.snappy.parquet part-00003-b9292122-99a7-4223-aaa9-8646c281f199-c000.snappy.parquet
请注意,运行 vacuum 之后,回溯到比保留期更早的版本的功能将会失效。

Chapter-03 大型数据湖的 Time Travel 功能

Delta Lake 提供 Time Travel 功能。 Delta Lake 是一个开源存储层,可为数据湖带来可靠性。 Delta Lake 提供 ACID 事务,可伸缩的元数据处理,以及批流一体数据处理。 Delta Lake 在您现有的数据湖之上运行,并且与 Apache Spark API 完全兼容。
使用此功能,Delta Lake 会自动对您存储在数据湖中的大数据进行版本控制,同时您可以访问该数据的任何历史版本。这种临时数据管理可以简化您的数据管道,包括简化审核,在误写入或删除的情况下回滚数据以及重现实验和报告。
您的组织最终可以在一个干净,集中化,版本化的云上大数据存储库上实现标准化,以此进行分析。
更改数据的常见挑战
- 审核数据更改:审核数据更改对于数据合规性以及简单的调试(以了解数据如何随时间变化)都至关重要。在这种情况下,传统数据系统都转向大数据技术和云服务。
- 重现实验和报告:在模型训练期间,数据科学家对给定的数据集执行不同参数的各种实验。当科学家在一段时间后重新访问实验以重现模型时,通常源数据已被上游管道修改。很多时候他们不知道这些上游数据发生了更改,因此很难重现他们的实验。一些科学家和最好的工程师通过创建数据的多个副本来进行实践,从而增加了存储量的费用。对于生成报告的分析师而言,情况也是如此。
- 回滚:数据管道有时会向下游消费者写入脏数据。发生这种情况的原因可能是基础架构不稳定或者混乱的数据或者管道中的 Bug 等问题。对目录或表进行简单追加的管道,可以通过基于日期的分区轻松完成回滚。随着更新和删除,这可能变得非常复杂,数据工程师通常必须设计复杂的管道来应对这种情况。

使用Time Travel功能
Delta Lake 的 time travel 功能简化了上述用例的数据管道构建。Delta Lake 中的 Time Travel 极大地提高了开发人员的生产力。它有助于:
- 数据科学家可以更好地管理实验
- 数据工程师简化了管道同时可以回滚脏数据
- 数据分析师可以轻松地分析报告
企业最终可以在干净,集中化,版本化的云存储中的大数据存储库上建立标准化,在此基础上进行数据分析。我们很高兴看到您将能够使用此功能完成工作。
当您写入 Delta Lake 表或目录时,每个操作都会自动进行版本控制。您可以通过两种不同的方式访问数据的不同版本:

使用时间戳
Scala 语法
您可以将时间戳或日期字符串作为 DataFrame 阅读器的选项来提供:
val df = spark.read .format(“delta”) . option(“timestampAsOf”, “2019-01-01”) .load(“/path/to/my/table”) df = spark.read \\ .format(“delta”) \\ .option(“timestampAsOf”, “2019-01-01”) \\ .load(“/path/to/my/table”) SQL语法 SELECT count(*) FROM my_table TIMESTAMP AS OF “2019-01-01” SELECT count(*) FROM my_table TIMESTAMP AS OF date_sub(current_date(), 1) SELECT count(*) FROM my_table TIMESTAMP AS OF “2019-01-01 01:30:00.000”
如果您无权访问阅读器的代码库,您可以将输入参数传递给该库以读取数据,通过将 yyyyMMddHHmmssSSS 格式的时间戳传递给表来进行数据回滚:
val inputPath = “/path/to/my/table@20190101000000000”
val df = loadData(inputPath)
// Function in a library that you don’t have access to def loadData(inputPath : String) : DataFrame = {
spark.read
.format(“delta”)
.load(inputPath)
}
inputPath = “/path/to/my/table@20190101000000000”
df = loadData(inputPath)
# Function in a library that you don’t have access to
def loadData(inputPath):
return spark.read \\
.format(“delta”) \\
.load(inputPath)
}

使用版本号
在 Delta Lake 中,每次写入都有一个版本号,您也可以使用该版本号来进行回溯。
Scala语法
val df = spark.read
.format(“delta”)
.option(“versionAsOf”, “5238”)
.load(“/path/to/my/table”)
val df = spark.read
.format(“delta”)
.load(“/path/to/my/table@v5238”)
Python语法
df = spark.read \\
.format(“delta”) \\
.option(“versionAsOf”, “5238”) \\
.load(“/path/to/my/table”)
df = spark.read \\
.format(“delta”) \\
.load(“/path/to/my/table@v5238”)
SQL语法
SELECT count(*) FROM my_table VERSION AS OF 5238
审核数据变更
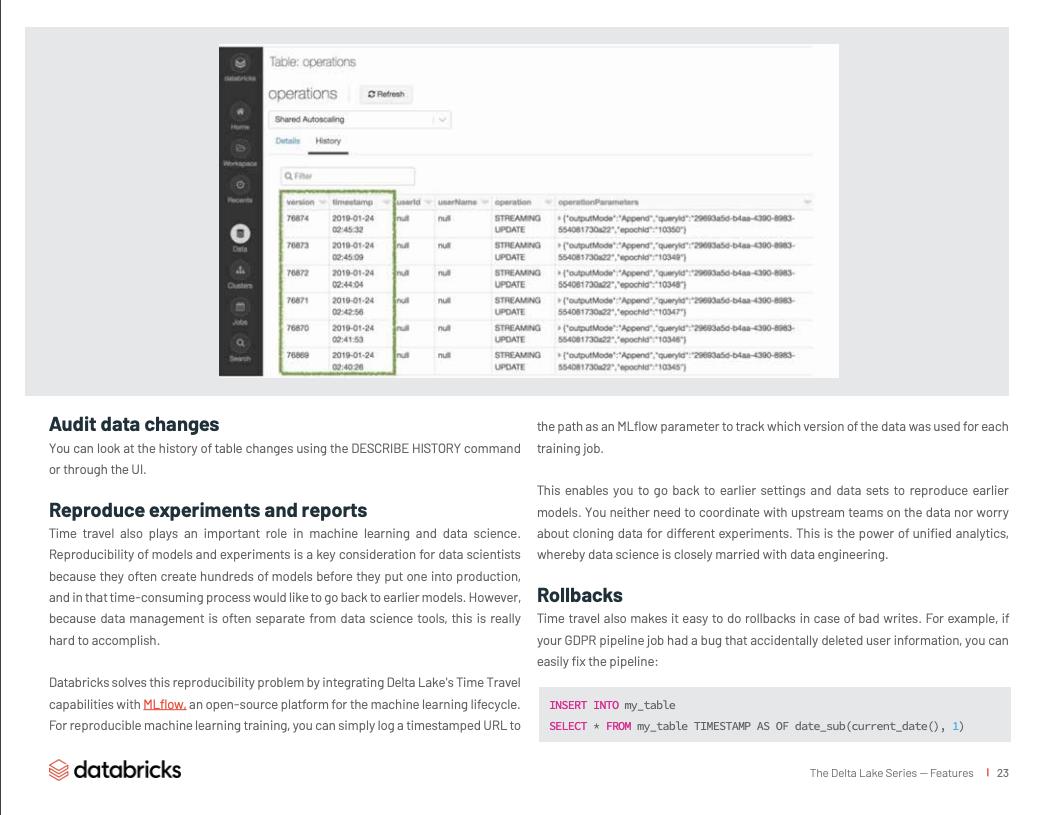
您可以使用 DESCRIBE HISTORY 命令或通过 UI 来查看表更改的历史记录。
重做实验和报告
Time travel 在机器学习和数据科学中也起着重要作用。模型和实验的可重复性是数据科学家的关键考虑因素,因为他们通常在投入生产之前会创建数百个模型,并且在那个耗时的过程中,有可能想回到之前早期的模型。 但是由于数据管理通常与数据科学工具是分开的,因此确实很难实现。
Databricks 将 Delta Lake 的 Time Travel 功能与 MLflow(机器学习生命周期的开源平台)相集成来解决可重复实验的问题。 为了重新进行机器学习培训,您只需将带有时间戳的 URL 路径作为 MLflow 参数来跟踪每个训练作业的数据版本。
这使您可以返回到较早的设置和数据集以重现较早的模型。 您无需与上游团队就数据进行协调,也不必担心为不同的实验克隆数据。 这就是统一分析的力量,数据科学与数据工程紧密结合在一起。
回滚
Time travel 可以在产生脏数据的情况下方便回滚。 例如,如果您的 GDPR 管道作业有一个意外删除用户信息的 bug,您可以用下面方法轻松修复管道:
INSERT INTO my_table SELECT * FROM my_table TIMESTAMP AS OF date_sub(current_date(), 1) WHERE userId = 111 You can also fix incorrect updates as follows: MERGE INTO my_table target USING my_table TIMESTAMP AS OF date_sub(current_date(), 1) source ON source.userId = target.userId WHEN MATCHED THEN UPDATE SET *
如果您只想回滚到表的之前版本,则可以使用以下任一命令来完成:
RESTORE TABLE my_table VERSION AS OF [version_number] RESTORE TABLE my_table TIMESTAMP AS OF [timestamp]
固定视图的不断更新跨多个下游作业的 Delta Lake 表
通过 AS OF 查询,您现在可以为多个下游作业固定不断更新的 Delta Lake 表的快照。考虑一种情况,其中 Delta Lake 表正在不断更新,例如每15秒更新一次,并且有一个下游作业会定期从此 Delta Lake 表中读取数据并更新不同的目标表。 在这种情况下,通常需要一个源 Delta Lake 表的一致视图,以便所有目标表都反映相同的状态。
现在,您可以按照下面的方式轻松处理这种情况:
version = spark.sql(“SELECT max(version) FROM (DESCRIBE HISTORY my_table)”).collect()
# Will use the latest version of the table for all operations below
data = spark.table(“my_table@v%s” % version[0][0]
data.where(“event_type = e1”).write.jdbc(“table1”)
data.where(“event_type = e2”).write.jdbc(“table2”)
...
data.where(“event_type = e10”).write.jdbc(“table10”)
时间序列分析查询变得简单
Time travel 还简化了时间序列分析。例如,如果您想了解上周添加了多少新客户,则查询可能是一个非常简单的方式,如下所示:
SELECT count(distinct userId) - ( SELECT count(distinct userId) FROM my_table TIMESTAMP AS OF date_sub(current_date(), 7)) FROM my_table

Chapter-04 轻松克隆您的 Delta Lake 以方便测试,数据共享以及重复进行机器学习

Delta Lake 有一个表克隆的功能,可以轻松进行测试,共享和重新创建表以实现 ML 的多次训练。在数据湖或数据仓库中创建表的副本有几种实际用途。但是考虑到数据湖中表的数据量及其增长速度,进行表的物理副本是一项昂贵的操作。
借助表克隆,Delta Lake 现在使该过程更简单且更省成本。
什么是克隆?
克隆是源表在给定时间点的副本。它们具有与源表相同的元数据:相同表结构,约束,列描述,统计信息和分区。但是它们是一个单独的表,具有单独的体系或历史记录。对克隆所做的任何更改只会影响克隆表,而不会影响源表。由于快照隔离,在克隆过程中或之后发生的源表更改也不会反映到克隆表中。在 Delta Lake 中,我们有两种克隆方式:浅克隆或深克隆。
浅克隆
浅克隆(也称为零拷贝)仅复制要克隆的表的元数据;表本身的数据文件不会被复制。这种类型的克隆不会创建数据的另一物理副本,从而将存储成本降至最低。浅克隆很便宜,而且创建起来非常快。
这些克隆表自己不作为数据源,而是依赖于它们的源文件作为数据源。如果删除了克隆表所依赖的源文件,例如使用 VACUUM,则浅克隆可能会变得不可用。因此,浅克隆通常用于短期使用案例,例如测试和实验。
深克隆
浅克隆非常适合短暂的用例,但某些情况下需要表数据的独立副本。深克隆会复制源表的元数据和数据文件全部信息。从这个意义上讲,它的功能类似于使用 CTAS 命令(CREATE TABLE .. AS ... SELECT ...)进行复制。但是由于它可以按指定版本复制原始表,因此复制起来更简单,同时您无需像使用 CTAS 一样重新指定分区,约束和其他信息。此外它更快,更健壮,也可以针对故障使用增量方式进行工作。
使用深克隆,我们将复制额外的元数据,例如 streaming 应用程序事务和 COPY INTO 事务。因此您可以在深克隆之后继续运行 ETL 应用程序。
克隆的适用场景?
有时候我希望有一个克隆人来帮助我做家务或魔术。但是我们这里不是在谈论人类克隆。在许多情况下,您需要数据集的副本-用于探索,共享或测试 ML 模型或分析查询。以下是一些客户用例的示例。
用生产表进行测试和试验
当用户需要测试其数据管道的新版本时,他们通常依赖一些测试数据集,这些测试数据跟其生产环境中的数据还是有很大不同。数据团队可能也想尝试各种索引技术,以提高针对海量表的查询性能。这些实验和测试想在生产环境进行,就得冒影响线上数据和用户的风险。
为测试或开发环境拷贝线上数据表可能需要花费数小时甚至数天的时间。此外,开发环境保存所有重复的数据会产生额外的存储成本-设置反映生产数据的测试环境会产生很大的开销。 对于浅克隆,这是微不足道的:
-- SQL CREATE TABLE delta.`/some/test/location` SHALLOW CLONE prod.events # Python DeltaTable.forName(“spark”, “prod.events”).clone(“/some/test/location”, isShallow=True) // Scala DeltaTable.forName(“spark”, “prod.events”).clone(“/some/test/location”, isShallow=true)
在几秒钟内创建完表的浅克隆之后,您可以开始运行管道的副本以测试新代码,或者尝试在不同维度上优化表,可以看到查询性能提高了很多很多。 这些更改只会影响您的浅克隆,而不会影响原始表。
暂存对生产表的重大更改
有时,您可能需要对生产表进行一些重大更改。 这些更改可能包含许多步骤,并且您不希望其他用户看到您所做的更改,直到您完成所有工作。 浅克隆可以在这里为您提供帮助:
-- SQL CREATE TABLE temp.staged_changes SHALLOW CLONE prod.events; DELETE FROM temp.staged_changes WHERE event_id is null; UPDATE temp.staged_changes SET change_date = current_date() WHERE change_date is null; ... -- Perform your verifications
对结果满意后,您有两种选择。 如果未对源表进行任何更改,则可以用克隆替换源表。如果对源表进行了更改,则可以将更改合并到源表中。
-- If no changes have been made to the source REPLACE TABLE prod.events CLONE temp.staged_changes; -- If the source table has changed MERGE INTO prod.events USING temp.staged_changes ON events.event_id <=> staged_changes.event_id WHEN MATCHED THEN UPDATE SET *; -- Drop the staged table DROP TABLE temp.staged_changes;
机器学习结果的可重复性
训练出有效的 ML 模型是一个反复的过程。在调整模型不同部分的过程中,数据科学家需要根据固定的数据集来评估模型的准确性。
这是很难做到的,特别是在数据不断被加载或更新的系统中。 在训练和测试模型时需要一个数据快照。 此快照支持了 ML 模型的重复训练和模型治理。
我们建议利用 Time Travel 在一个快照上运行多个实验;在 Machine Learning Data Lineage With MLflow and Delta Lake 中可以看到一个实际的例子。
当您对结果感到满意并希望将数据存档以供以后检索时(例如,下一个黑色星期五),可以使用深克隆来简化归档过程。 MLflow 与 Delta Lake 的集成非常好,并且自动记录功能(mlflow.spark.autolog()方法)将告诉您使用哪个数据表版本进行了一组实验。
# Run your ML workloads using Python and then DeltaTable.forName(spark, “feature_store”).cloneAtVersion(128, “feature_ store_bf2020”)
数据迁移
出于性能或管理方面的原因,可能需要将大量表移至新的专用存储系统。原始表将不再接收新的更新,并且将在以后的某个时间点停用和删除。深度克隆使海量表的复制更加健壮和可扩展。
-- SQL CREATE TABLE delta.`zz://my-new-bucket/events` CLONE prod.events; ALTER TABLE prod.events SET LOCATION ‘zz://my-new-bucket/events’;
由于借助深克隆,我们复制了流应用程序事务和 COPY INTO 事务,因此您可以从迁移后停止的确切位置继续ETL应用程序!
资料共享
在一个组织中,来自不同部门的用户通常都在寻找可用于丰富其分析或模型的数据集。您可能希望与组织中的其他用户共享数据。 但不是建立复杂的管道将数据移动到另一个里,而是创建相关数据集的副本通常更加容易和经济。这些副本以供用户浏览和测试数据来确认其是否适合他们的需求而不影响您自己生产系统的数据。在这里深克隆再次起到关键作用。
-- The following code can be scheduled to run at your convenience CREATE OR REPLACE TABLE data_science.events CLONE prod.events;
数据存档
出于监管或存档的目的,表中的所有数据需要保留一定的年限,而活动表则将数据保留几个月。如果您希望尽快更新数据,但又要求将数据保存几年,那么将这些数据存储在一个表中并进行 time travel 可能会变得非常昂贵。
在这种情况下,每天,每周,每月归档数据是一个更好的解决方案。深克隆的增量克隆功能将在这里为您提供真正的帮助。
-- The following code can be scheduled to run at your convenience CREATE OR REPLACE TABLE archive.events CLONE prod.events;
请注意,与源表相比此表将具有独立的历史记录,因此根据您的存档频率,源表和克隆表上的 time travel 查询可能会返回不同的结果。
看起来真棒!有问题吗?
这里只是重申上述一些陷阱,请注意以下几点:
- 克隆是在你的快照上进行的。对克隆开始后的源表变化不会反映在克隆中。
- 浅克隆不像深克隆那样是自包含的表。如果在源表中删除了数据(例如通过 VACUUM),那么您的浅克隆可能无法使用。
- 克隆与源表具有独立的历史记录。在源表和克隆表上的 time travel 查询可能不会返回相同的结果。
- 浅克隆不复制流事务或将副本复制到元数据。使用深层克隆来迁移表,可以从上次暂停的地方继续进行 ETL 处理。
我该如何使用?
浅克隆和深克隆支持数据团队在测试和管理其新型云数据湖和仓库如何开展新功能。表克隆可以帮助您的团队对其管道实施生产级别的测试,微调索引以实现最佳查询性能,创建表副本以进行共享-所有这些都以最小的开销和费用实现。如果您的组织需要这样做,我们希望您能尝试克隆表并提供反馈意见-我们期待听到您将来的新用例和扩展。

Chapter-05 在 Apache Spark 3.0 上的 Delta Lake 中启用 Spark SQL DDL 和 DML 功能

Delta Lake 0.7.0 的发布与 Apache Spark 3.0 的发布相吻合,从而启用了一组新功能,这些功能使用了 Delta Lake 的 SQL 功能进行了简化。以下是一些关键功能。
在 Hive Metastore 中定义表支持 SQL DDL 命令
现在,您可以在 Hive Metastore 中定义 Delta 表,并在创建(或替换)表时在所有 SQL 操作中使用表名。
创建或替换表
-- Create table in the metastore
CREATE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING DELTA
PARTITIONED BY (date)
LOCATION ‘/delta/events’
-- If a table with the same name already exists, the table is replaced with
the new configuration, else it is created
CREATE OR REPLACE TABLE events (
date DATE,
eventId STRING,
eventType STRING,
data STRING)
USING DELTA
PARTITIONED BY (date)
LOCATION ‘/delta/events’
显式更改表架构
-- Alter table and schema
ALTER TABLE table_name ADD COLUMNS (
col_name data_type
[COMMENT col_comment]
[FIRST|AFTER colA_name],
...)
您还可以使用 Scala / Java / Python API:
- DataFrame.saveAsTable(tableName) 和 DataFrameWriterV2 APIs。
- DeltaTable.forName(tableName) 这个 API 用于创建 io.delta.tables.DeltaTable 实例,对于在 Scala/Java/Python 中执行 Update/Delete/Merge 操作是非常有用。
支持 SQL 插入,删除,更新和合并
通过 Delta Lake Tech Talks,最常见的问题之一是何时可以在 Spark SQL 中使用 DML 操作(如删除,更新和合并)?不用再等了,这些操作现在已经可以在 SQL 中使用了! 以下是有关如何编写删除,更新和合并(使用 Spark SQL 进行插入,更新,删除和重复数据删除操作)的示例。
-- Using append mode, you can atomically add new data to an existing
Delta table
INSERT INTO events SELECT * FROM newEvents
-- To atomically replace all of the data in a table, you can use overwrite mode
INSERT OVERWRITE events SELECT * FROM newEvents
-- Delete events
DELETE FROM events WHERE date < ‘2017-01-01’
-- Update events
UPDATE events SET eventType = ‘click’ WHERE eventType = ‘click’
-- Upsert data to a target Delta
-- table using merge
MERGE INTO events
USING updates
ON events.eventId = updates.eventId
WHEN MATCHED THEN UPDATE
SET events.data = updates.data
WHEN NOT MATCHED THEN INSERT (date, eventId, data)
VALUES (date, eventId, data)
值得注意的是,Delta Lake 中的合并操作比标准 ANSI SQL 语法支持更高级的语法。例如,合并支持
- 删除操作-删除与源数据行匹配的目标。 例如,“...配对后删除...”
- 带有子句条件的多个匹配操作-当目标和数据行匹配时具有更大的灵活性。 例如:
... WHEN MATCHED AND events.shouldDelete THEN DELETE WHEN MATCHED THEN UPDATE SET events.data = updates.data
- 星形语法-用于使用名称相似的源列来设置目标列值的简写。 例如:
WHEN MATCHED THEN SET *
WHEN NOT MATCHED THEN INSERT *
-- equivalent to updating/inserting with event.date = updates.date,
events.eventId = updates.eventId, event.data = updates.data
自动和增量式 Presto/Athena 清单生成
正如 Query Delta Lake Tables From Presto and Athena, Improved Operations Concurrency,andMergePerformance 文章中所述,Delta Lake 支持其他处理引擎通过 manifest 文件来读取 Delta Lake。manifest 文件包含清单生成时的最新版本。如上一章所述,您将需要:
- 生成 Delta Lake 清单文件
- 配置 Presto 或 Athena 读取生成的清单
- 手动重新生成(更新)清单文件
Delta Lake 0.7.0的新增功能是使用以下命令自动更新清单文件:
ALTER TABLE delta.`pathToDeltaTable`
SET TBLPROPERTIES(
delta.compatibility.symlinkFormatManifest.enabled=true
)
通过表属性文件来配置表
通过使用 ALTER TABLE SET TBLPROPERTIES,您可以在表上设置表属性,可以启用,禁用或配置 Delta Lake 的许多功能,就像自动清单生成那样。例如使用表属性,您可以使用 delta.appendOnly=true 阻止 Delta 表中数据的删除和更新。
您还可以通过以下属性轻松控制 Delta Lake 表保留的历史记录:
- delta.logRetentionDuration:控制表的历史记录(即事务日志历史记录)保留的时间。默认情况下会保留30天的历史记录,但是您可能需要根据自己的要求(例如GDPR历史记录上下文)更改此值。
- delta.deletedFileRetentionDuration:控制文件成为 VACUUM 的候选时必须在多久被删除。默认情况下会删除7天以上的数据文件。
从 Delta Lake 0.7.0 开始,您可以使用 ALTER TABLE SET TBLPROPERTIES 来配置这些属性。
ALTER TABLE delta.`pathToDeltaTable` SET TBLPROPERTIES( delta.logRetentionDuration = “interval “ delta.deletedFileRetentionDuration = “interval “ )
在 Delta Lake 表中提交支持添加用户定义的元数据
您可以指定自定义的字符串来作为元数据,通过 Delta Lake 表操作进行的提交,也可以使用DataFrameWriter选项userMetadata,或者 SparkSession 的配置spark.databricks.delta.commitInfo。 userMetadata。
在以下示例中,我们将根据每个用户请求从数据湖中删除一个用户(1xsdf1)。为确保我们将用户的请求与删除相关联,我们还将 DELETE 请求 ID 添加到了 userMetadata中。
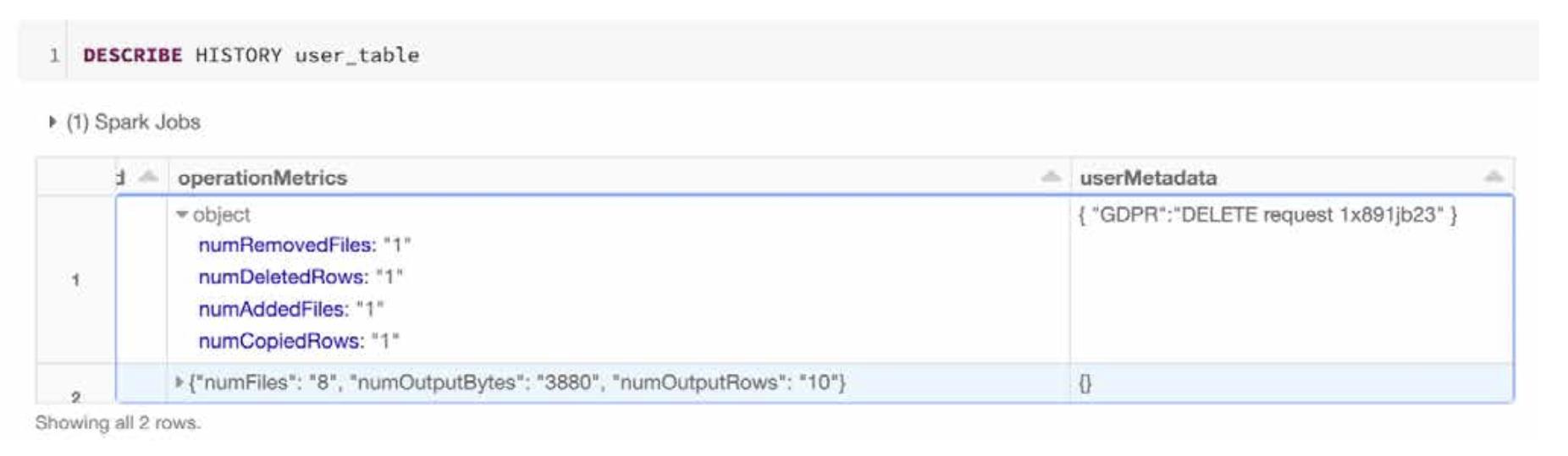
SET spark.databricks.delta.commitInfo.userMetadata={
“GDPR”:”DELETE Request 1x891jb23”
};
DELETE FROM user_table WHERE user_id = ‘1xsdf1’
当查看用户表(user_table)的历史记录操作时,可以轻松地在事务日志中标识关联的删除请求。
其他亮点
Delta Lake 0.7.0 版本的其他亮点包括:
- 支持 Azure Data Lake Storage Gen2-Spark 3.0 已经支持 Hadoop 3.2 库,也被 Azure Data Lake Storage Gen2 支持。
- 改进了对流式一次触发的支持-使用 Spark 3.0,我们确保一次触发(Trigger.Once)在单个微批处理中处理 Delta Lake 表中的所有未完成数据,即使使用 DataStreamReader 选项 maxFilesPerTriggers 速度受限。
在 AMA 期间,关于结构化流和使用 trigger.once 的问题又很多。
有关更多信息,一些解释此概念的有用资源包括:
- 每天运行一次流作业,可节省10倍的成本
- 超越 Lambda:引入Delta架构:特别是成本与延迟的对比

后续
您已经了解了 Delta Lake 及其特性,以及如何进行性能优化,本系列还包括其他内容:
- Delta Lake 技术系列-基础和性能
- Delta Lake 技术系列-Lakehouse
- Delta Lake 技术系列-Streaming
- Delta Lake 技术系列-客户用例(Use Case)
本文为阿里云原创内容,未经允许不得转载。
以上是关于详谈 Delta Lake 系列技术专题 之 特性(Features)的主要内容,如果未能解决你的问题,请参考以下文章