Snowflake & Delta Lake两大新型数仓对比分析
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Snowflake & Delta Lake两大新型数仓对比分析相关的知识,希望对你有一定的参考价值。
Snowflake & Delta Lake 代表了当前业内最先进的两种数仓形态,并且都得到了市场上用户的高度认可。
1
概述
数据分析从上世纪 80 年代兴起以来,大体经历了企业数仓(EDW)、数据湖(Data Lake)、以及现在的云原生数仓、湖仓一体等过程。企业数仓是数据仓库最原始的版本,从当前的视角来看,存在着只能处理结构化数据、集中式的存储和计算、以及成本昂贵等缺点。数据湖是伴随着数据爆炸式增长而出现的技术,它能够存储结构化以及非结构化的数据、拥有分布式的存储、以及经济的成本。但由于其“不管后面用不用,先存储起来”的理念,在数据治理、质量审核方面有很多的缺失,因此在后续实际的使用当中会面临较多的问题。以 Snowflake 和 Delta Lake 为代表的新兴数仓就是有针对性的去解决上述问题,并充分利用当前卓越技术(如云计算、Hadoop、Spark 等)的新一代企业数据解决方案。
总体来看,Snowflake 像是企业数仓(EDW)的 2.0 版本。Delta Lake 则是 Data Lake 的 2.0 版本。
两个阵营都在争相成为一站式服务,来处理用户的任何数据,以及应对任何场景。
Snowflake 2019 提出 Data Ocean - 支持结构化、半结构化数据,并提供弹性扩展,存储便宜、计算按需付费,事务支持,托管服务功能。19 Q3提供数据复制功能,使 Snowflake 客户能够复制数据库,并使数据库在不同区域和/或云提供商的多个帐户之间保持同步。这样可以确保在区域性或云提供商中断的情况下业务连续性。它还允许客户想要迁移到其他区域或云时所需的可移植性。另一个好处是能够轻松安全地在区域和云之间共享数据。扩展全球数据湖的覆盖范围,从而将数据湖变成数据海洋。
Databricks 2020 基于 Delta Lake 提出 Data Lakehouse 概念。数据湖 1.0 版本虽然适用于存储数据,但缺少一些关键功能:它们不支持事务,它们不强制执行数据质量,并且缺乏一致性/隔离性,几乎不可能混合添加和读取以及批处理和流式作业。由于这些原因,数据湖的许多承诺尚未实现,并且在许多情况下导致失去数据仓库的许多好处。Data Lakehouse 提供事务支持,强制的模式要求及健壮的治理和审核机制,除了提供对 BI 分析的支持,Data Lakehouse 还支持存算分离,数据格式开放性,非结构化到结构化数据类型全支持,以及支持机器学习、科学计算及 AI 等工作负载,并提供端到端流等功能。
下面对 Snowflake 和 Delta Lake 分别做一个详细介绍。
2
Snowflake 介绍
Snowflake 是完全建立在云上的企业级数据仓库解决方案。Snowflake 是云原生的因为它针对并基于云环境进行了根本性的重新设计,处理引擎和其他大部分组件都是从新开始开发的。Snowflake 在亚马逊及其他云上提供即付即用的服务。用户只需将数据导入云,就可以立即利用他们熟悉的工具和界面进行管理和查询。从 2012 年底,Snowflake 开始计划实施,到 2015 年 6 月,Snowflake 已经可以大体可用。目前,Snowflake 已经被越来越多的组织采用,每天管理者几百上千万次的查询以及 PB 级以上的数据。
Snowflake 的关键特点如下:
* 纯粹的 SaaS 服务体验:用户不需要购买机器、聘请数据库管理员或安装软件。用户要么已经在云中拥有数据,要么上传数据。然后,就可以使用 Snowflake 的图形界面或 ODBC 等标准化接口立即操作和查询数据。与其他数据库即服务(DBaaS)产品不同,Snowflake 的服务覆盖了整个用户体验。用户无需调优,无需物理设计,无需存储整理任务。
* 关系型语法兼容:Snowflake 对 ANSI SQL 和 ACID 事务提供了全面的支持。大多数用户几乎不需要更改就可以迁移现有工作负载。
* 半结构化数据支持:自动模式发现(schema)及列式存储等功能使得 Snowflake 可以像普通关系数据一样处理无 schema、半结构化的数据,并没有额外开销。
* 弹性
* 高可用
* 数据持久性
* 经济:以上都是云原生所带来的好处。
* 安全:Snowflake 中所有的数据包括临时文件及网络传输都是端到端加密的,没有任何信息会暴露。并且基于角色的权限控制使用户能够在 SQL 级别上执行细粒度的访问控制。
3
Snowflake 核心技术
存储和计算分离
Shared-nothing 架构目前已经成为高性能数据仓库的主流体系结构,主要原因有两个:可扩展性和商用廉价硬件。在 Shared-nothing 结构中,每个查询处理器节点都有自己的本地磁盘。表是跨节点水平分区的,每个节点只负责其本地磁盘上的行。这种设计可以很好地扩展星型模式查询,因为将一个小的(广播的)维度表与一个大的(分区的)事实表连接起来只需要很少的带宽。而且,由于共享数据结构或硬件资源几乎没有争用,因此不需要昂贵的定制硬件。这种方法是很容易理解的并具有良好优点的软件设计。
不过,纯粹的 Shared-nothing 结构有一个重要的缺点:它将计算资源和存储资源紧密耦合,这在某些场景中会导致问题。
异构工作负载:虽然硬件是同样的,但工作负载通常不是。有些任务需要高 IO,轻计算,有些需要重计算,轻 IO。因此,硬件配置需要在平均利用率较低的情况下进行权衡。
节点关系变化:如果一些节点发生更改,或者是由于节点故障,或者是用户调整系统大小,则大量数据需要重新 shuffle。由于相同的节点同时负责数据 shuffle 和查询,因此会对性能有显著的影响,从而限制了灵活性和可用性。
在线升级:虽然可以通过数据复制、系统节点交替升级等技术减少影响,但总体上还是比较困难。
在本地环境,这些问题,发生的频率较小,通常都可以容忍。但在云上,云服务商有很多不同规格的节点,只要正确的选择就能充分利用资源,而节点的故障等引起的关系变化是常态,用户也有强烈的需求需要在线升级和弹性扩展。因此,基于上述等等原因,Snowflake 选择了存储和计算分离设计。
存储和计算由两个松耦合、独立可扩展的服务来处理。计算是通过 Snowflake 的(专有的)shared-nothing 引擎提供的。存储是通过亚马逊 S3(或 Azure 对象存储,Google云存储) 提供的。同时,为了减少计算节点和存储节点之间的网络流量,每个计算节点在本地磁盘上缓存了一些表的数据。
存储和计算分离的另一个好处是,本地磁盘空间不用存储整个数据,这些数据可能非常大,而且大部分是冷数据(很少访问)。本地磁盘专门用于临时数据和缓存,两者都是热数据(建议使用高性能存储设备,如 SSD)。因此,缓存了热数据,性能就接近甚至超过纯 shared-nothing 结构的性能。Snowflake 称这种新的体系结构为 multi-cluster、shared-data 架构。
架构介绍
Snowflake 是一个面向服务的体系结构,由高度容错和独立可扩展的服务组成。这些服务通过 RESTful 接口进行通信,分为三个体系结构层:
* 数据存储。该层使用 amazon s3 存储表数据和查询结果。
* 虚拟仓库。系统的“肌肉”。该层通过弹性的虚拟集群(称为虚拟仓库),执行查询。
* 云服务。系统的“大脑”。这一层是管理虚拟仓库、查询、事务和围绕虚拟仓库的所有元数据的服务的集合,包含数据库元信息、访问控制信息、加密密钥、使用情况统计等。
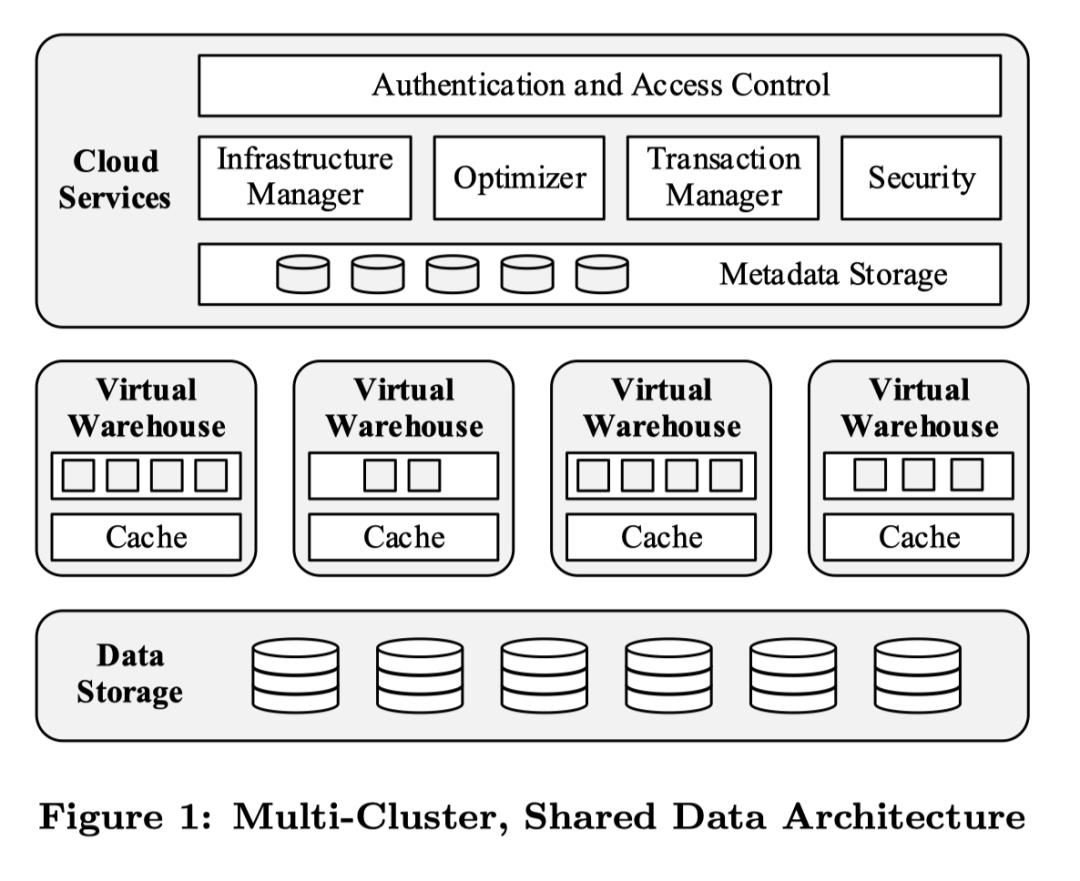
数据存储
Snowflake 数据存储直接采用了 Amazon S3 等云存储服务,并没有自己开发,而是将精力投入在了数据处理优化的其他方面。
S3 是一个对象存储,具有一个相对简单的基于 HTTP 的 PUT/GET/DELETE 接口。对象(即文件)只能完全写入。甚至不可能将数据附加到文件的末尾。文件的确切大小需要在 PUT 请求中前就确定。并且,S3 支持对部分(范围)文件的 GET 请求。
Snowflake 存储的数据格式采用的是列存 + 每个表文件都有一个文件头,其中包含文件中每列的偏移量,以及其他元数据。因为 S3 允许对部分文件执行 GET 请求,所以查询只需要下载文件头和它们需要的列。
Snowflake 不仅在表数据上使用 S3。当本地磁盘空间耗尽时,它还使用 S3 存储由查询(例如,大量连接)生成的临时数据,以及大型查询结果。将 temp 数据溢出到 S3,系统可以计算任意大的查询,而不会出现内存不足或磁盘不足的错误。将查询结果存储在 S3 中,实现了客户端交互新方式并简化查询处理,因为它消除了对传统数据库系统中的服务端游标的需要。
元数据,例如 catalog 信息,由 S3 文件、统计信息、锁、事务日志等组成,存储在可伸缩的事务 KV 存储中,这也是云服务的一部分。
虚拟仓库(Virtual Warehouses)
虚拟仓库层由 EC2 实例集群组成。
虚拟仓库的弹性与隔离
VM 层是纯计算资源,可以按照需求创建、销毁或者在任意时刻改变大小。创建或者销毁一个 VM 对数据库状态没有任何影响。当没有查询时候,用户可以关闭所有的 VM 资源。这种弹性容许用户独立于数据层,按照需求动态的伸缩他们的计算资源。
每个查询只在一个 VW 上运行。工作节点不会在 VW 之间共享,从而使查询具有强大性能隔离。(Snowflake 计划后续会加强工作节点共享)。每个用户可以在任何给定的时间运行多个 VW,而每个 VW 又可以运行多个并发查询。每个 VW 都可以访问相同的共享表,而无需物理复制数据。
另一个与弹性有关的重要结果是,通常可以用大致相同的价格获得更好的性能表现。例如,在具有 4 个节点的系统上,数据加载需要 15 小时,而在具有 32 个节点的系统上,数据加载可能只需要 2 小时。由于计算是按时间付费的,所以总体成本非常相似,但用户体验却截然不同。因此,弹性是 Snowflake 架构最大的优点和区别之一,因为需要一种新颖的设计来利用云的独特功能。
虚拟仓库的本地缓存和文件窃取
每一个 worker 节点在本地磁盘上缓存了一些表数据。缓存的文件是一些表文件,即节点过去访问过的 S3 对象。准确地说,缓存保存文件头和文件的各个列,因为查询只下载它们需要的列。缓存在工作节点的工作时间内有效,并在并发和后续工作进程(即查询)之间共享。Snowflake 使用最近最少使用(LRU)策略替换缓存文件。为了提高命中率并避免 VW 的工作节点之间对单个表文件进行冗余缓存,查询优化器使用表文件名上的一致哈希将输入文件集分配给工作节点。因此,访问同一表文件的后续查询或并发查询将在同一工作节点上执行。
除了缓存,倾斜处理在云数据仓库中尤为重要。由于虚拟化问题或网络争用,某些节点的执行速度可能比其他节点慢得多。在这点上,Snowflake 在扫描文件的时候就处理了这个问题。每当工作进程完成对其输入文件集的扫描时,它就会从其对等进程请求其他文件,这个过程称之为文件窃取。当请求到达时,如果一个 worker 发现它的输入文件集合中还有许多文件要处理,这个时候又有其他 worker 请求帮助,这个 worker 将这个请求中他需要的查询的范围内的一个剩余文件的处理权力转移给其他 worker。然后其他 worker 直接从 S3 下载文件,而不是从这个 worker 下载。这种设计确保了文件窃取不会给当前 worker 增加额外的处理负担。
虚拟仓库执行引擎
Snowflake 自己实现了 SQL 执行引擎。并且构建的引擎是列式的、向量化的和基于 push 的。
* 列式存储在数据分析场景更适用,因为它更有效地使用了 CPU 缓存和 SIMD 指令,并且能进行更有效的压缩。
* 向量化执行。与 MapReduce 相比,Snowflake 避免了中间结果的物化。相反,数据是以 pipeline 方式处理的,每次以列成批处理几千行。这种方法由 VectorWise(最初是 MonetDB/X100)首创,这能节省 I/O 并大大提高了缓存效率。
* 基于 push 的执行是指,关系运算符将过滤推送到其下游运算符,而不是等待这些运算符拉取数据。
云服务
虚拟仓库是临时的、特定于用户的资源。相反,云服务层在很大程度上是多租户的。这一层的每个服务访问控制、查询优化器、事务管理器和其他服务都是长期存在的,并在许多用户之间共享。多租户提高了利用率并减少了管理开销,这比传统体系结构中每个用户都有一个完全私有的系统在体系结构上具有更好的规模经济。并且每个服务都被复制以实现高可用性和可扩展性。
查询管理和优化
用户所有的查询都通过云服务层。云服务层处理查询生命周期的所有早期阶段:解析、对象解析、访问控制和计划优化。优化器完成后,生成的执行计划将分发给部分查询节点。当查询执行时,云服务会不断跟踪查询的状态,收集性能指标并检测节点故障。所有查询信息和统计信息都存储起来,进行审计和性能分析。用户可以通过 Snowflake 图形界面监视和分析之前和正在进行的查询。
并发控制
如前所述,并发控制完全由云服务层处理。Snowflake 是为分析工作而设计的,这些工作往往会有大量读取、批量或随机插入以及批量更新。与大多数系统一样,我们决定通过快照隔离(Snapshot Isolation)实现 ACID 事务。
在 SI 下,事务的所有读取都会看到事务启动时数据库的一致性快照。通常,SI 是在多版本并发控制(MVCC)之上实现的,因此每个更改的数据库对象的一个副本都会保留一段时间。
MVCC 是使用 S3 等服务存储后自然的选择(因为文件不可变更),只有将文件替换为包含更改的其他文件,才能实现更改。因此,表上的写操作(insert、update、delete、merge)通过添加和删除相对于上一个表版本的整个文件来生成新版本的表。在元数据(在全局键值存储中)中跟踪文件的添加和删除,这种形式对属于特定表版本的文件集计算非常高效。
除了 SI 之外,Snowflake 还使用这些快照来实现时间旅行(Time Travel)和高效的数据库对象复制。
剪枝优化
Snowflake 无法使用 B+ 树或其他类似索引结构来做剪枝优化,因为它们严重依赖随机访问。因此 Snowflake 使用了另一种在大规模数据处理常用的技术:最小-最大值剪枝。系统维护给定数据块(记录集、文件、块等)的数据分布信息,特别是块内的最小值和最大值。根据查询谓词的不同,这些值可用于确定给定查询可能不需要给定的数据块。与传统索引不同,这种元数据通常比实际数据小几个数量级,因此存储开销小,访问速度快。
除了静态剪枝,Snowflake 还在执行过程中执行动态剪枝。例如,作为 hash join 处理的一部分,Snowflake 收集有关 build-side 记录中 join key 分布的统计信息。然后将此信息推送到 probe-side,并用于过滤 probe side 的整个文件,甚至可能跳过这些文件。
4
Delta Lake 介绍
Delta Lake 是 Spark 背后的公司 Databricks 开发的数据仓库表存储层管理技术(table storage layer)。Delta Lake 通过使用压缩至 Apache Parquent 格式的事务性日志来提供ACID,Time Travel 以及海量数据集的高性能元数据操作(比如快速搜索查询相关的上亿个表分区)。同时 Delta Lake 也提供一些高阶的特性,比如自动数据布局优化,upsert,缓存以及审计日志等。
根据 Delta Lake 与云客户工作的经验来看,客户在云上管理数据的主要痛点是性能及一致性无法满足,这些一致性以及性能方面的问题对企业的数据团队产生了很大的挑战。大多数的企业数据是持续更新的,所以需要原子写的解决方案,多数涉及到用户信息的数据需要表范围的更新以满足GDPR这样的合规要求。即使是内部的数据也需要更新操作来修正错误数据以及集成延迟到达的记录。
Delta Lake 的核心概念很简单:Delta Lake 使用存储在云对象中的预写日志,以 ACID 的方式维护了哪些对象属于 Delta table 这样的信息。对象本身写在 parquet 文件中,使已经能够处理Parquet格式的引擎可以方便地开发相应的 connectors。这样的设计可以让客户端以串行的方式一次更新多个对象,替换一些列对象的子集,同时保持与读写 parquet 文件本身相同的高并发读写性能。日志包含了为每一个数据文件维护的元数据,如 min/max 统计信息。相比“对象存储中的文件”这样的方式,元数据搜索相关数据文件速度有了数量级的提升。最关键的是,Delta Lake 的设计使所有元数据都在底层对象存储中,并且事务是通过针对对象存储的乐观并发协议实现的(具体细节因云厂商而异)。这意味着不需要单独的服务来维护 Delta table 的状态,用户只需要在运行查询时启动服务器,享受存储计算扩展分离带来的好处。
基于这样的事务性设计,Delta Lake 能够提供在传统云数据湖上无法提供的解决用户痛点的特性,包括:
* Time travel:允许用户查询具体时间点的数据快照或者回滚错误的数据更新。
* Upsert,delete 以及 merge 操作:高效重写相关对象实现对存储数据的更新以及合规工作流(比如 GDPR)
* 高效的流I/O:流作业以低延迟将小对象写入表中,然后以事务形式将它们合并到大对象中来提高查询性能。支持快速“tail”读取表中新加入数据,因此作业可以将 Delta 表作为一个消息队列。
* 缓存:由于 Delta 表中的对象以及日志是不可变的,集群节点可以安全地将他们缓存在本地存储中。
* 数据布局优化:在不影响查询的情况下,自动优化表中对象的大小,以及数据记录的聚类(clustering)(将记录存储成 Zorder 实现多维度的本地化)。
* Schema 演化:当表的 schema 变化时,允许在不重写 parquet 文件的情况下读取旧的 parquet 文件。
* 日志审计:基于事务日志的审计功能。
这些特性改进了数据在云对象存储上的可管理性和性能,并且结合了数仓和数据湖的关键特性创造了“湖仓”的典范:直接在廉价的对象存储上使用标准的 DBMS 管理功能。

5
Delta Lake 存储格式及访问协议
Delta Lake 表是云对象存储或文件系统上的一个目录,其中包含了表数据对象和事务操作日志(以及 checkpoint 日志)对象。客户端使用乐观并发控制协议来更新这些数据结构。
存储格式示例如下所示:

数据对象
Delta Lake 中,数据对象采用 parquet 格式存储,数据对象可分区,并且名称为唯一的 GUID。
日志对象
Delta Lake 日志对象存储在表的 _delta_log 子目录中,它包含一系列连续的递增数字作为 ID 的 JSON 对象用于存储日志记录,以及某些特定日志对象的检查点,这些检查点将检查点之前的日志合并为 Parquet 格式。每个日志记录对象(比如 000003.json)包含了在前一个版本的表基础上进行的操作数组。这些操作数组用于保存数据对象信息,数据对象的添加记录还可以包括数据统计信息,例如总记录条数以及每列的最小/最大值和空计数。
另外 Delta Lake 的日志对象还可以保存一些额外信息,比如更新应用事务 ID。Delta Lake 为应用程序提供了一种将应用程序的数据包括在日志记录中的方法,允许应用程序在其日志记录对象中写入带有 appId 和版本字段的自定义 txn 操作,这样该日志对象就可以用来跟踪应用程序特定的信息,例如应用程序输入流的对应偏移量。这对于实现端到端事务性应用很有用。例如,写入 Delta 表的流处理系统需要知道先前已经提交了哪些写入,才能实现Exactly Once 语义:如果流作业崩溃,则需要知道其哪些写入先前已写入表中,以便它可以从输入流中的正确偏移处开始重播后续写入。
日志 checkpoint
日志 checkpoint 的主要作用是对日志对象(json 文件)进行定期压缩,删除冗余,冗余的操作包括:
* 对同一数据对象先执行添加操作,然后执行删除操作。可以删除添加项,因为数据对象不再是表的一部分。根据表的数据retention配置,应将删除操作保留为墓碑具体来说,客户端使用在删除操作中的时间戳来决定何时从存储中删除对象。
* 同一对象的多个添加项可以被最后一个替换,因为新添加项只能添加统计信息。
* 来自同一 appId 的多个 txn 操作可以被最新的替换,因为最新的 txn 操作包含其最新版本字段
* changeMetadata 以及协议操作也可以进行合并以仅保留最新的元数据。
checkpoint 采用 parquet 格式保存,这种面向列的文件对于查询表的元数据以及基于数据统计信息查找哪些对象可能包含与选择性查询相关的数据来说是非常理想的存储格式。默认情况下,客户端每10个事务会写入一个检查点。为了便于查找,另外还有一个 _last_checkpoint 文件用于保存最新的 Checkpoint ID。
读表操作
Delta Lake 按以下步骤对表进行读取:
1. 在 table 的 log 目录读取 _last_checkpoint 对象,如果对象存在,读取最近一次的 checkpoint ID
2. 在对象存储 table 的 log 目录中执行一次 LIST 操作,如果“最近一次 checkpoint ID”存在,则以此 ID 做 start key;如果它不存在,则找到最新的 .parquet 文件以及其后面的所有 .json 文件。这个操作提供了数据表从最近一次“快照”去恢复整张表所有状态所需要的所有文件清单。
3. 使用“快照”(如果存在)和后续的“日志记录”去重新组成数据表的状态(即,包含 add records,没有相关 remove records 的数据对象)和这些数据对象的统计信息。
4. 使用统计信息去定位读事务的 query 相关的数据对象集合。
5. 可以在启动的 spark cluster 或其他计算集群中,并行的读取这些相关数据对象。
这个访问协议的每一步中都有相关的设计去规避对象存储的最终一致性。比如,客户端可能会读取到一个过期的 _last_checkpoint 文件,仍然可以用它的内容,通过 LIST 命令去定位新的“日志记录”文件清单,生产最新版本的数据表状态。这个 _last_checkpoint 文件主要是提供一个最新的快照 ID,帮助减少 LIST 操作的开销。同样的,客户端能容忍在 LIST 最近对象清单时的不一致(比如,日志记录 ID 之间的 gap),也能容忍在读取日志记录中的数据对象时,还不可见,通过等一等/重试的方式去规避。
写事务
一个写入数据的事务,一般会涉及最多 5 个步骤,具体有几步取决于事务中的具体操作:
1. 找到一个最近的日志记录 ID,比如 r,使用读事务协议的 1-2 步(比如,从最近的一次 checkpoint ID 开始往前找)。事务会读取表数据的第 r 个版本(按需),然后尝试去写一个 r+1 版本的日志记录文件。
2. 读取表数据的 r 版本数据,如果需要,使用读事务相同的步骤(比如,合并最新的checkpoint .parquet 和 较新的所有 .json 日志记录文件,生成数据表的最新状态,然后读取数据表相关的数据对象清单)
3. 写入事务相关的数据对象到正确的数据表路径,使用 GUID 生成对象名。这一步可以并行化。最后这些数据对象会被最新的日志记录对象所引用。
4. 尝试去写本次写事务的日志记录到 r+1 版本的 .json 日志记录对象中 ,如果没有其他客户端在尝试写入这个对象(乐观锁)。这一步需要是原子的(atomic),如果失败需要重试。
5. 此步可选。为 r+1 版本的日志记录对象,写一个新的 .parquet 快照对象。然后,在写事务完成后,更新 _last_checkpoint 文件内容,指向 r+1 的快照。
关于隔离级别
Delta Lake 写事务实现了线性隔离级别,也使得事务的日志记录 ID 可以线性的增长。Delta Lake 读事务是 snapshot isolation 级别或者 serializability 的。根据默认的读数据流程(如上所述),读取过程是快照隔离级别的,但是客户端如果想达到线性化(serializable)的读取,可以发出一个“read-write”的事务,假装 mock 一次写事务然后再读,来达到线性化。
Delta 中的高级功能
* Time Travel(时间旅行)
* 高效效的更新,删除和合并
* 流式的数据导入和消费
* 数据布局优化(OPTIMIZE Command / Z-Ordering by Multiple Attributes)
* 缓存
* 审计日志
* Schema 演变和增强
Delta 探讨 & 局限
首先,Delta Lake 目前只支持单表的序列化级别的事务,因为每张表都有它自己的事务日志。如果有跨表的事务日志将能打破这个局限,但这可能会显著的增加并发乐观锁的竞争(在给日志记录文件做 append 时)。在高 TPS 的事务场景下,一个 coordinator 是可以承接事务 log 写入的,这样能解决事务直接读写对象存储。
然后,在流式工作负载下,Delta Lake 受限于云对象存储的 latency。比如,使用对象存储的 API 很难达到 ms 级的流式延迟要求。另外一边看,我们发现大企业的用户一般都跑并行的任务,在使用 Delta Lake 去提供秒级的服务延迟在大多数场景下也是能够接受的。
第三,Delta Lake 目前不支持二级索引(只有数据对象级别的 min/max 统计),我们已经开始着手开发一个基于 Bloom filter 的 index 了。Delta 的 ACID 事务能力,允许我们以事务的方式更新这些索引。
6
Snowflake & Delta Lake 对比总结
Snowflake 拥有很纯粹的 SaaS 服务体验,开箱即用,用户无需任何调优,具有非常大的易用性。Delta Lake 更像是数仓的底层基础设施,但 Databricks 公司也提供了开箱即用的一整套方案,基于 Delta Lake,并包含 Delta Engine、机器学习、科学计算及可视化平台等。
弹性和成本方面,两者依赖云平台,都提供了相应的能力。
数据开放性方面,Delta Lake 优于 Snowflake。Delta Lake 采用了开放的 Apache Parquet 格式,因此不受计算引擎的绑定,可以轻易在数据集上构建机器学习、科学计算等应用。这也是 Databricks 在大力推动发展的方向。Snowflake 由于使用的是内部专有格式,在性能上可能有特殊的定制化提升,但接入外部计算引擎上就会存在难度。每个对接的计算引擎或框架都需要专门定制开发相应的 connector。
实时数据支持方面 Delta Lake 优于 Snowflake,Delta Lake 提供了流式数据的写入和读取,提供的数据实时性为秒级。Snowflake 也提供了一个 Snowpipe 工具用以微批的形式写入数据,提供的数据实时性为分钟级。
支持的平台类型上,Delta Lake 更丰富。Snowflake 为云而生,并只支持各类云平台。Delta Lake 不限定于云平台,还可以支持 Hadoop 等大数据平台,甚至你将数据部署在本地环境,Delta Lake 也能支持。
参考资料
[1]The Snowflake Elastic Data Warehouse
[2]Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
[3]Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
[4]https://mp.weixin.qq.com/s/PgpTUs_B2Kg3T5klHEpFVw
[5]https://www.sohu.com/a/431026284_315839
[6]https://www.datagrom.com/data-science-machine-learning-ai-blog/snowflake-vs-databricks
作者简介
大鲸,网易数帆有数实时数仓开发工程师,曾从事搜索系统、实时计算平台等相关工作。
以上是关于Snowflake & Delta Lake两大新型数仓对比分析的主要内容,如果未能解决你的问题,请参考以下文章
如何使用 Python 将 blob 数据移动到 Snowflake