大数据OLAP架构及技术实现的演进简介
Posted 橙子园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据OLAP架构及技术实现的演进简介相关的知识,希望对你有一定的参考价值。
文章目录
你的点赞与评论是我最大的创作动力!

一、架构分类
OLAP名为联机分析,又称多维分析,什么是多维分析,指的是多种不同的维度审视数据,进行深层次分析。
进行分析必不可少对数据进行下钻、上卷、切片、切块、旋转等操作,为了更加直观,我们可以使用立方体来表示。
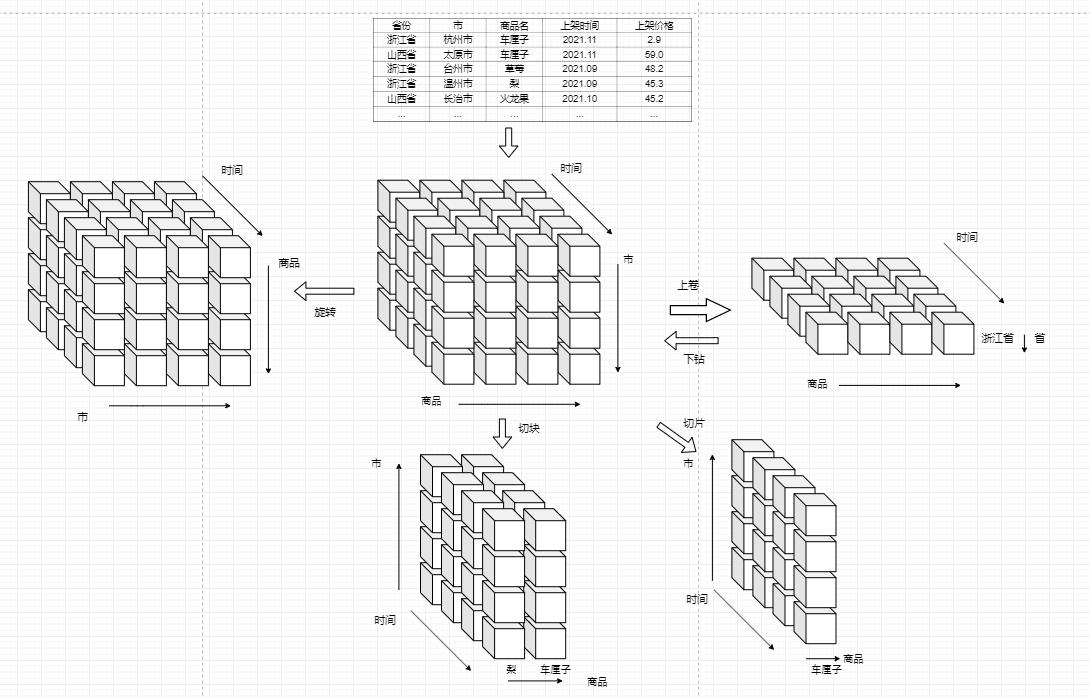
-
下钻:从高层次向低层次明细数据穿透。例如从“省”下钻到“市”,从“浙江省”穿透到“杭州市”和“台州市”。
-
上卷:和下钻相反,从低层次向高层次聚合。例如从“市”汇聚成“省”,将“杭州市”、“台州市”聚合成“湖北”。
-
切片:观察立方体的一层,将一个或多个维度设为单个固定值,然后观察剩余的维度,例如将商品维度固定为“车厘子”。
-
切块:与切片类似,只是将单个固定值变成多个值。例如将商品维度固定成“梨”、“车厘子”。
-
旋转:旋转立方体的一面,如果要将数据映射到一张二维表,那么就要进行旋转,这就等同于行列置换。
为了实现上述操作,将常见的OLAP架构分为三类:
1、ROLAP(Relational OLAP)是直接使用关系模型构建,因为早期OLAP概念提出的时候是建立在关系型数据库之上的。,多维分析的操作,可以直接转换成SOL查询。
2、MOLAP(Multidimensional OLAP),一般称为多维型OLAP,它可以缓解ROLAP性能问题,使用多维数组的形式保存数据。核心思想就是采用空间换取时间的形式,预先聚合结果来提高查询性能。
首先,对需要分析的数据进行建模,框定需要分析的维度字段;然后,通过预处理的形式,对各种维度进行组合并事先聚合;最后,将聚合结果以某种索引或者缓存的形式保存起来(通常只保留聚合后的结果,不存储明细数据)。这样一来,在随后的查询过程中,就可以直接利用结果返回数据。但是这种架构也并不完美。维度预处理可能会导致数据的膨胀
3、HOLAP(Hybrid OLAP)这种架构思想可谓是上面两种架构思想的混合,这种思想对于具体的了解、实现现在还不多。
二、技术演进
技术的演进我们可以分为两个标志性的阶段。
1、传统关系型数据库时期
这个阶段中,OLAP主要基于以Oracle、mysql为代表的一众关系型数据实现。在ROLAP架构下,直接使用这些数据库作为存储与计算的载体。在MOLAP架构下,则借助物化视图的形式实现各数据操作。但难以解决的问题是,不论是ROLAP还是MOLAP,在数据体量大、维度数目多的情况下都存在严重的性能问题。
2、大数据技术时期
由于大数据处理技术的普及,大家开始使用大数据技术重构ROLAP和MOLAP。
先看ROLAP架构,传统关系型数据库就被Hive和SparkSQL这类新兴技术所取代。虽然,以Spark为代表的分布式计算系统,相比Oracle这类传统数据库而言,在面向海量数据的处理性能方面已经优秀很多,但是直接把它们作为面向终端用户的在线查询系统还是太慢了。
再看MOLAP架构,MOLAP背后也转为依托MapReduce或Spark这类新兴技术,将其作为立方体的计算引擎,加速立方体的构建过程。其预聚合结果的存储载体也转向HBase这类高性能分布式数据库。大数据技术阶段,主流MOLAP架构已经能够在亿万级数据的体量下,实现毫秒级的查询响应时间。尽管如此,MOLAP架构依然存在维度爆炸、数据同步实时性不高的问题。
以上是关于大数据OLAP架构及技术实现的演进简介的主要内容,如果未能解决你的问题,请参考以下文章