云原生OLAP数据引擎
Posted 数据极客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生OLAP数据引擎相关的知识,希望对你有一定的参考价值。
文章标题没有采用OLAP数据库,也没有采用大数据字眼,根本原因在于,在基础架构向云原生演进的路线中,数据库,大数据等传统字眼,都在面临消失,融合的趋势。
数据库,本质上是利用专有存储引擎格式,解决小批量点查询及随机写入(OLTP),和大批量分析查询及随机或顺序写入(OLAP)的各种Trade Off设计,包含性能,事务(处理并发写入冲突),一致性(高可用多副本机制下的客户端视图),伸缩性等诸多方面。
而大数据体系来自于Hadoop社区,随着Hive,Spark,Presto,Impala等的完善和成熟,大家发现,貌似它们跟传统的OLAP数据库,除了对数据更新不友好之外,已经有了相互取代的可能。而即使对数据更新来说,也随着Hoodie,IceBerg等增量方案的出现,进而包装出了新概念——实时数据湖(Data Lake),似乎可以一统江湖了。
然而,事实果真如此么?本文站在一个另类的视角,来看待OLAP分析型需求的演进趋势。由于本文并不打算包装任何概念,因此暂用OLAP数据引擎,来指代针对所有海量数据的分析型查询需求。相比OLTP数据库来说,OLAP面临复杂得多的场景,所以市面上存在的OLAP数据引擎,开源的,不开源的,无比繁杂,因为没有一种解决方案可以满足所有场景。由于各种技术繁杂交互,下图是一个粗略的分类,当然还包含一些没有列入的。
以上分类,并不科学,但确实是尽可能涵盖到已有的OLAP数据引擎了。传统上的OLAP数据库分类,就只有3类:从普通关系型数据库RDBMS发展而来的ROLAP,基于Data Cube预计算路线的MOLAP,以及混合类型。但实际在实现过程中,面临分布式计算的需求又引入了一些其他的技术,比如MPP,顾名思义,它最早来自于Share Nothing结构之下的并行计算,其特点在于将查询计算跟存储绑定,每个节点独立完成任务,最后将各节点计算结果合并处理。普通ROLAP跟Share Nothing MPP结合的典型例子有GreenPlum,RedShift等,纯Share Nothing MPP的典型例子有ClickHouse等。
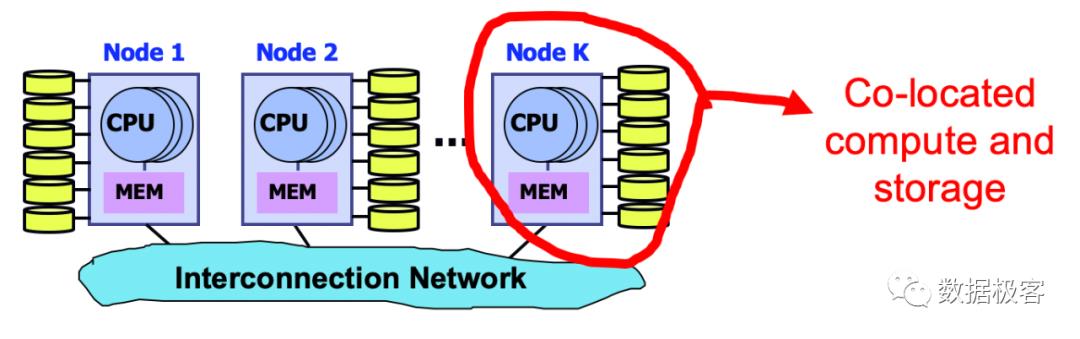
大数据体系从传统OLAP数据库社区借鉴了很多理念,尤其是全面的SQL能力,当然也包含MPP,只不过,由于大数据体系先天就是基于HDFS文件系统存在,因此天然就是共享存储,而不是Share Nothing,所以经常用SQL on Hadoop来笼统概括,用句时髦的话语,它们是天然的存储计算分离架构,相比Share Nothing MPP,SQL on Hadoop在伸缩性上真是具备得天独厚的优势,例如ClickHouse数据库,在容错,Auto Rebalance上缺乏相应的机制,使用者不得不忍受这些缺点。当然,并不是说Share Nothing机制就无法做到高可用和高伸缩了。一个典型设计是引入OLTP数据库体系的多组复制状态机协议,例如Multi-Raft,从而以Raft Group为单元进行数据复制和迁移。
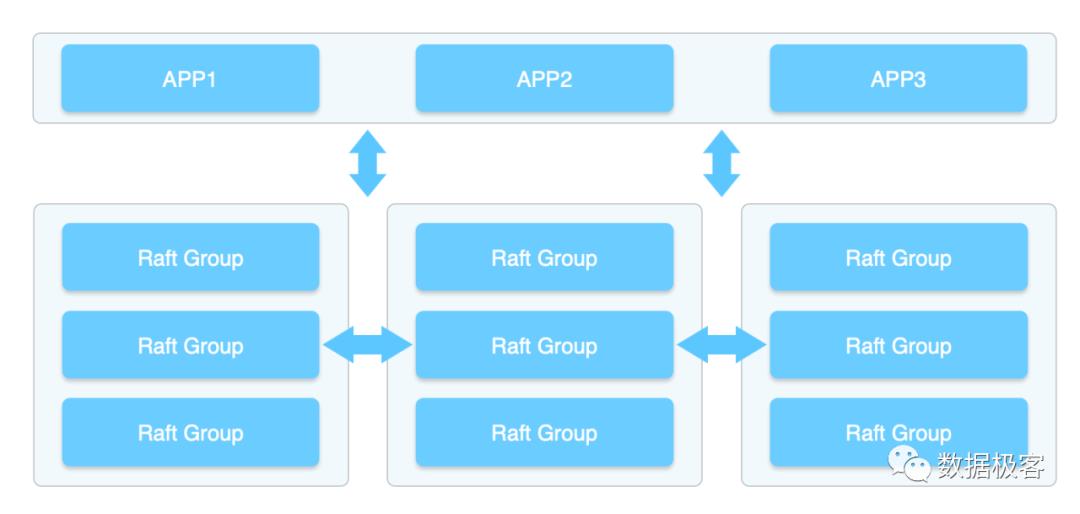
MOLAP是指在进行SQL查询过程中,由于获取结果的时间过长,因此将部分指标列跟维度的组合,预先计算出来,这称之为Data Cube,如下图所示。当数据和需求不变时,这种预计算的模式具有先天的高性能优势,因为相当多的结果在查询之前已经存在了,查询只是把需要的结果找出来,做简单处理后返回。然而,当数据和需求发生变化,这些预先计算的结果不得不全部作废,因此它的使用限制很高。典型的MOLAP例子包括Kylin等。预计算Data Cube作为性能提升的一种手段,实际上在其他数据库中也有使用,例如Doris,Druid等,只不过它们并不像Kylin这样只提供预计算,还结合了其他技术希望能够规避掉预计算不灵活的缺陷。
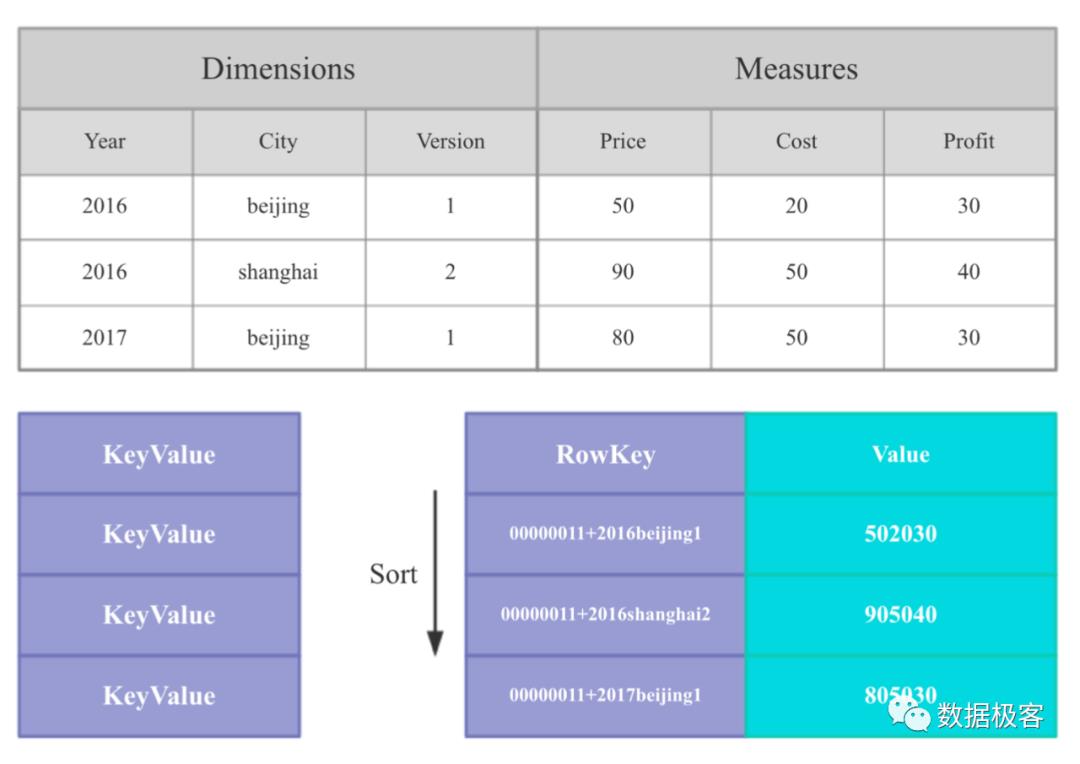
所有前述的技术路线,在底层数据存储格式上,都只包含两类:按行存储和按列存储。ROLAP的OLAP引擎基本都是按行存储的,这使得它们在处理更新的时候拥有天然的优势,但OLAP分析需要大量的扫描操作,按行存储在这方面会引起过大的开销,因此列存普遍成为OLAP引擎的标准配置,即使是来自于ROLAP的GreenPlum,也单独配置的列存用来提升查询性能,当然这会导致数据更新并不好处理。除了这两种存储格式之外,还有一类存储是来自于搜索引擎的倒排索引,典型的代表例子有开源的ElasticSearch,它在诸多场景下得到使用,尤其是用户画像等,然而,缺乏全面完整的SQL能力,一直是它的痛点之一。由于倒排索引可以在部分场景中大量节约IO的特点,因此后续有部分专用OLAP引擎如Druid,Pinot等也引入了倒排索引技术,当然跟ElasticSearch类似,它们同样在SQL能力上有所欠缺。另一个典型例子来自于阿里云的AnalyticDB,就是从前的ADS,它也采用了全倒排索引的技术路线,但是它能够提供完整的SQL支持。
我们对以上各种OLAP按照更细的分类做个简单总结,分类如前图所示:
类型1,以传统行存数据库类型1,以传统行存数据库为基础,部分引入列存MPP技术。这类OLAP性能有限,但对更新友好,不易扩缩容
类型2,以列存MPP为核心优化,查询性能优秀,并发不高,不易扩缩容。这里多说明一点,以ClickHouse为代表的MPP列存OLAP引擎,性能非常优良,但它的并发能力有限,因为它的查询受限于IO
类型3,在类型2的基础上做存储计算分离,迎合云原生需求。这里的优秀代表包括Snowflake,它类似于SQL on Hadoop体系的存储计算分离机制,但在成本和性能上更优秀,缺点是并发能力依然受限于IO
类型4,这就是最常见的SQL on Hadoop体系。整体来看,这一类解决方案性能都不算很好,数据难以实时更新,单个查询延迟高,并发能力差。除此之外,由于Hadoop体系天然对云不友好,在云端几乎都要单独部署,因此几乎所有的配套产品都是放在企业自有环境中,给企业带来了沉重的成本开销。基本上,它们的这些标签,就是导致为什么大数据从08年开始流行至今十多年,依然没有真正给企业带来明显价值的重要原因
类型5,修改自开源搜索引擎,如前所述,这类方案的SQL能力弱,难以处理表JOIN等复杂查询,但是因为倒排索引节省IO,因此并发能力高。这里要多说明一点,并发能力高,不代表单个查询延迟就低,例如在同样查询上,良好的列存引擎,完全可以比这些基于搜索引擎的OLAP更快地返回结果,只是它们并发不高而已。这听起来很矛盾,为何会如此呢?举例来说:倒排索引可以快速返回基于过滤后的记录ID列表,然而一个查询,远不是获得记录ID列表这么简单,它还需要对过滤后的记录,在其他字段上做聚合,分组等操作,这些操作,就不是普通倒排索引可以帮上的了。现实中的典型场景包括日志分析,这是一个低并发的检索需求。以ElasticSearch为代表的ELK体系,几乎成为了日志分析的代名词,可是从成本,性能上,越来越多的案例已经表明它们表现并不能比MPP列存更快速。最后一个要补充的在于,来自搜索引擎的OLAP方案,跟Share Nothing MPP列存有类似,它们都是存储计算耦合的解决方案,因此在高可用,高伸缩方面也面临挑战。ElasticSearch的做法,是自己管理副本机制,确保高可用,但它无法搞定Auto Rebalance,Druid/Pinot等则规避了问题,索性把各种索引数据存放到Hadoop大数据系统上,需要的时候再通过内存映射mmap机制映射到内存。这是一种绕过问题而不是直面挑战的手段,因为对于存储的管理,几乎可以决定一个项目最终能否成功,这点我们后边会继续谈到
类型6,同时引入搜索和MPP列存,以前者为主,查询性能优秀,并发高,这是目前唯一的同类解决方案。当然,它依赖阿里云专有存储和分布式计算系统,别人想要用,只能给阿里云付钱并且依托阿里云构建解决方案了
类型7和8,构建Data Cube,性能高,并发高,但需要预计算,导致数据膨胀数倍缺乏灵活性,数据表Schema变更需要重新入库
本文的标题叫做云原生OLAP数据引擎,到这里,我们才讨论到什么叫云原生3个字。云原生,看起来并不是那么复杂,将已有体系部署在公有云上即可,然而,事实并不是那么简单。首先我们要回答一个问题,为什么要上云?答案只有2个字,便宜。可是上云真的便宜么?这取决于你的选择。公有云最便宜的资源,就2个:计算和存储。下表展现了典型的公有云存储价格:
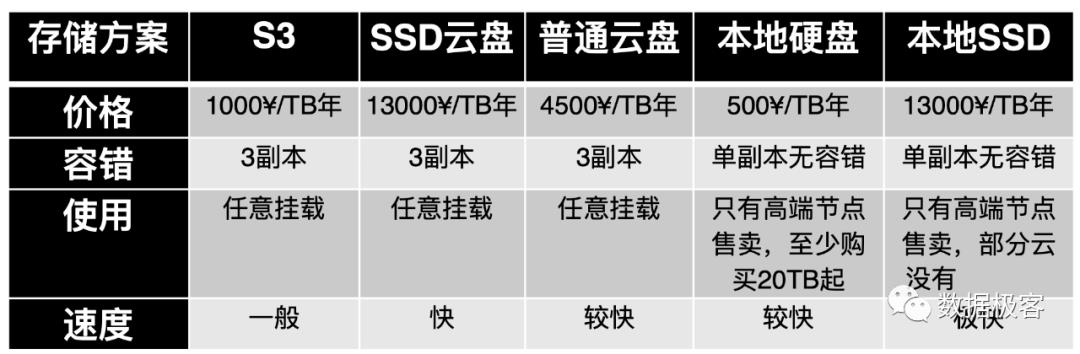
需要说明的是,表中提到的3副本,实际可能不一定,但用户无需关心,只需要知道存储通过多副本机制提供高可用能力即可。从表中可以看到,S3真是便宜啊,比本地硬盘都便宜(因为本地硬盘不具备多副本高可用能力),而且本地硬盘,在公有云当中,只有非常有限的实例才能购买,这些实例通常非常巨大,例如单个节点挂载20TB的本地硬盘,因此通常都是给在公有云当中自行部署大数据系统服务的,这会导致计算和存储资源的严重不均衡。那么,是否仅仅依赖公有云最便宜的计算和存储,就可以构建便宜的解决方案,从而真正降低成本了么?答案显然并非如此,这里边有若干因素需要考虑:
任何解决方案,都依赖复杂的中间件,数据库,消息队列等等,这些组件的高可用,是个麻烦的问题。完全依靠自己的技术团队搭建,对于绝大多数公司来说,并不具备相应的能力。公有云倒是会完整提供配套能力,可以直接购买,可是相比廉价的存储和计算来说,这些组件的价格,并不便宜。这甚至是公有云盈利的主要来源之一。
假如自己的技术团队具备较强的能力(我们把人力成本排除在外),可以自行维护以上中间件和核心引擎,数据库等。在公有云上,就可以降低成本么?以云原生OLAP为例,这里有2个技术路线:
将Share Nothing体系的解决方案,部署在云端。如前所述,为了解决高可用问题,通常引入基于多副本的复制状态机协议,例如Multi-Raft,以及ElasticSearch自己的协议(尽管从高可用角度,不怎么靠谱)。这些解决方案,本身是通过多副本提供高可用机制,根据以上列表,它们的选择,只有云盘和本地磁盘两种。本地磁盘,只有本地SSD可以购买较少的容量,本地HDD硬盘通常10-20TB起才能购买。如果为了降低成本,需要跟每个虚拟机配置几个TB的普通存储,只能购买云盘,而云盘本身就已经提供了多副本高可用能力,因此,这就导致出现一种Replication on Replication的尴尬场景,假设应用本身提供了3副本的复制状态机协议,那么最终就是9副本的数据复制,这显然是巨大的浪费
将Share Storage的SQL on Hadoop解决方案,部署在云端。如前所述的问题,Hadoop大数据体系对云并不友好,尽管Hadoop社区已经有Ozone类似的方案辅助将Hadoop体系部署在S3云存储之上,部分公有云也已经提供原生的云端Hadoop(如EMR),但是SQL on Hadoop本身的问题,并没有得到解决。SQL on Hadoop的性能就不咋样,SQL on Hadoop over S3,更不会好到哪里去了。尽管如此,这种方案,已经对于很多企业来说,具备很强的吸引力了。代表例子有Presto,正是因为它不仅仅可以查询Hadoop之上的数据,也可以直接查询S3之上的数据,因此早在15年,云原生的互联网公司如Netflix就拿它作为自己数据仓库的基石了——代价是忍受较慢的查询和较低的并发能力
因此,云原生,并不是一个简单的问题——如果你真的来考虑上云的优点并期望受益的话。其实上述的问题,业界也一直有人在思考和关注,这里我们列举2个有代表性的工作:
在HotCloud 2020上,SAP Lab[1]提出了前述的Replication on Replication问题。并针对已有的开源中间件和数据库,如Kafka,MongoDB,Cassandra,提出了如何在公有云上提供多副本高可用,且避免"副本on副本"导致的巨大浪费的解决方案思路。总体而言,是将存储分为主体和增量部分,主体构建于S3对象存储之上,无需复制,增量部分继续依赖复制状态机协议保证的高可用机制,从而避免过多浪费
硅谷数据库创业公司RockSet开源了底层存储引擎RocksDB-Cloud,RockSet公司团队基本都来自于Facebook的RocksDB团队,因此他们的Idea是直接把RocksDB搬到S3上,这样上层写数据库应用就可以无缝迁移了。RocksDB-Cloud的架构如下所示,由于S3存储需要以较大尺寸对象为单元进行操作,才能充分利用其吞吐量。如果每条记录都要同步到S3之 上,那么S3存储无法跟上数据库所需要的性能下限。因此,需要机制确保数据在存放到S3之前的高 可靠性,换句话,如果节点在数据同步到S3之前宕机,将导致数据丢失。RocksDB-Cloud的做法是同步一份数据到全局日志,全局日志可以是公有云上的高可靠消息队列服务,也可以是自己搭建的高可靠消息队列等
以上两种方案,其核心,都是利用到了每个虚拟机搭配的较小数据的本地硬盘或者云盘,来提供Disk Cache能力,从而规避掉S3存储本身的性能瓶颈带来的问题。因此,Disk Cache设计的好坏,直接决定了,想要依托S3构建数据引擎的性能,这从云原生数据库公司Snowflake,在系统顶会NSDI 2020上提出的参考设计[2],也可以看出。Snowflake的方案,是将所有虚拟机搭配的本地硬盘,都看作是一个全局的HashTable,它并不关心某个包含Disk Cache节点是否会宕机,这对于完全存储计算分离的Snowflake,是没有任何问题的。
因此借鉴上述的各种思路,提出一种云原生的高性价比高可靠存储方案,就是水到渠成的事情了。我们再回到本文开头的论点:在基础架构向云原生演进的路线中,数据库,大数据等传统字眼,都在面临消失,融合的趋势。这是从何说起呢?
在前述的OLAP数据库,以及SQL on Hadoop的过程中,我们可以看出来,其实双方已经在相互融合了。在迁移到云原生体系之后,出于为降低成本广泛引入S3作为共享对象存储的考虑,以及在引入合理可靠的Disk Cache之后从而确保兼顾低成本和高可靠之后,我们确实可以设想,是不是所有的组件,都可以这么来,当然包含OLAP数据引擎?
举例来说,我们是否可以把OLTP数据库,也这么撸?还真有这么干的,比如Intel联合MariaDB推出的Cloud Native mysql方案[3],腾讯云新近推出的PostgreSQL for Serverless等。当然,早先Amazon推出的Aurora数据库,本质也是这个路子。这种解决方案,虽然无法像近年来的NewSQL那样提供多点写入,但确实可以以很高的性价比,满足90%以上的商业需求,因此是个非常良好的商业产品设计理念。
再回到OLAP数据引擎,如果我们在上述的S3+Disk Cache之上,再仔细地设计存储引擎和查询引擎,我们完全可以提供一种高并发,低延迟,低成本的OLAP数据分析引擎解决方案。这里想说的是,OLAP,不是只有行存,和列存两种底层,高并发能力依赖于索引的精细设计,这需要仔细地考量。再结合S3廉价的特性,我们几乎可以任意定制各种查询需求,除了典型的OLAP分析需求之外,还可以加入高并发Serving的点查询需求等等,因此可以做到真正一体化的高性价比分析引擎。到了这个地步,还在乎云端选型有什么数据库,搭配什么大数据这些问题么?因此在云原生体系之上,是可以进入到一种自由的创作王国。借用阿里Hologres的一张宣传图,云原生的引擎,本就是融合的,而且世上也不会只有阿里这一种选择,开源的也可以做的更好。
后续,本号将逐步推出引擎的设计细节,欢迎有需求的同僚前来沟通。
参考资料
[1] Hemant Saxena and Jeffrey Pound. A cloud-native architecture for replicated data services. In 12th {USENIX} Workshop on Hot Topics in Cloud Computing (HotCloud 20), 2020.
[2] Midhul Vuppalapati, Justin Miron, Rachit Agarwal, Dan Truong, Ashish Motivala, and Thierry Cruanes. Building an elastic query engine on disaggregated storage. In 17th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 20), pages 449–462, 2020
[3] Cloud Native MySQL.https://www.slideshare.net/MariaDB/intel-and-mariadb-webscale-applications-with-distributed-logs 2019.
以上是关于云原生OLAP数据引擎的主要内容,如果未能解决你的问题,请参考以下文章