百度阿里腾讯平台架构都熟悉,小米大数据平台架构OLAP架构演进是否了解
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度阿里腾讯平台架构都熟悉,小米大数据平台架构OLAP架构演进是否了解相关的知识,希望对你有一定的参考价值。
阿里、百度、腾讯的大数据平台架构都有很多地方有介绍了,接下来给大家深入了解小米大数据平台架构OLAP架构演进
全网最详细的Hadoop文章系列,强烈建议收藏加关注!
目录
历史文章
2021年大数据Hadoop(二十一):MapReuce的Combineer
2021年大数据Hadoop(二十):MapReduce的排序和序列化
2021年大数据Hadoop(十九):MapReduce分区
2021年大数据Hadoop(十八):MapReduce程序运行模式和深入解析
女朋友问阿里双十一实时大屏如何实现,我惊呆一会,马上手把手教她背后的大数据技术
2021年大数据Hadoop(十七):MapReduce编程规范及示例编写
前言
2021年全网最详细的大数据笔记,轻松带你从入门到精通,该栏目每天更新,汇总知识分享

小米大数据平台OLAP架构演进
一、数据仓库
1、离线数据仓库的架构
数据仓库一般架构
分析型系统进行联机数据分析,一般的数据来源是数据仓库,而数据仓库的数据来源为可操作型系统,可操作型 系统的数据来源于业务数据库中,那么我们常用的数据仓库的组成和架构一般如下图所示

上图将数据分为业务源头系统和数据仓库系统:
其中数据仓库系统又包括操作型(ODS)系统和数据仓库系统两部分。
操作型(ODS)系统的数据主要来自于各业务数据系统中,这其中包括:
①关系型数据库
②平面文件(文本文件,CSV文件,XML文件)等
③还有网络爬虫抓取的开放的数据等。
数据的种类也丰富多元:有结构化数据、半结构化数据、非结构化数据等,这些数据会通过抽取、转换和装载从 ODS进入到数据仓库系统中。
数据仓库常用架构
在数据仓库技术演进过程中,产生了几种主要的架构方法,包括 Inmon 企业信息工厂架构、 Kimba数据仓库架 构。
Inmon 企业信息工厂架构
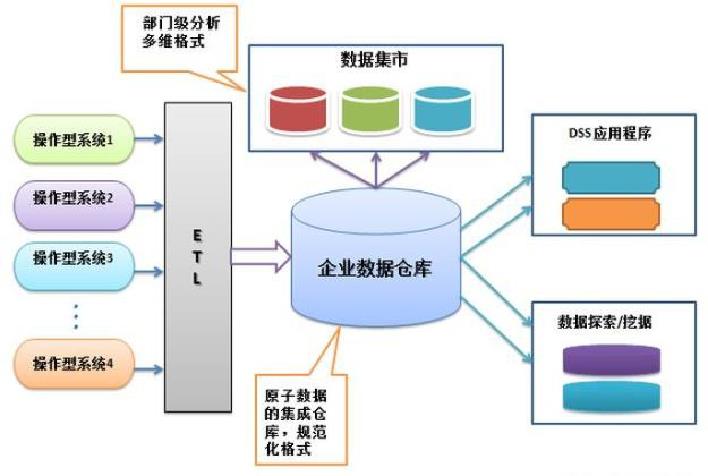
企业数据仓库是企业信息化工厂的枢纽,是原子数据的集成仓库,但是由于企业数据仓库不是多维格式,因此不适合分析型应用程序,BI工具直接查询。他的目的是将附加的数据存储用于各种分析型系统。
数据集市,是针对不同的主题区域,从企业数据仓库中获取的信息,转换成多维格式,然后通过不同手段的 聚集、计算,最后提供最终用户分析使用,因此Inmon把信息从企业数据仓库移动到数据集市的过程描述为“数据 交付”。
Kimball 的维度数据仓库
Kimball 的维度数据仓库是基于维度模型建立的企业级数据仓库,它的架构有的时候可以称之为“总线体系结 构”,和 inmon 提出的企业信息化工厂有很多相似之处,都是考虑原子数据的集成仓库。
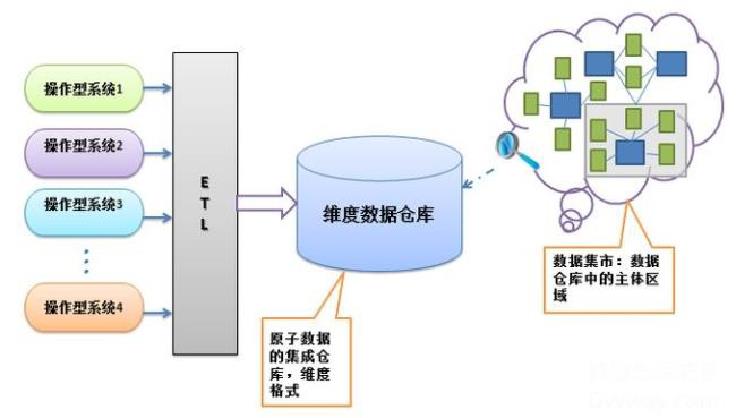
这两种结构的相似之处:
一、都是假设操作型系统和分析型系统是分离的;
二、数据源(操作型系统)都是众多;
三、ETL整合了多种操作型系统的信息,集中到一个企业数据仓库。
最大的不同就是企业数据仓库的模式不同:inmon是采用第三范式的格式,kimball采用了多维模型–星型模型, 并且还是最低粒度的数据存储。
其次,维度数据仓库可以被分析系统直接访问(这种访问方式毕竟在分析过程中很少使 用)。
最后就是数据集市的概念有逻辑上的区别,在kimball的架构中,数据集市用维度数据仓库的高亮显示的表的子 集来表示。
在kimball的架构中,有一个可变通的设计,就是在ETL的过程中加入ODS层,使得ODS层中能保留第三范式的一组表 来作为ETL过程的过渡。但是这个思想,Kimball看来只是ETL的过程辅助而已。另外,还可以把数据集市和企业维 度数据仓库分离开来,这样多一层所谓的展现层(presentationlayer),这些变通的设计都是可以接受的,只要符合企业本身分析的需求。
混合型结构数据仓库指的是结合inmon和 kimball 两种结构的架构,可以从下图的结构中看出来,将 Inmon 架构 中的数据集市部分内容替换成了一个多维的数据仓库,二数据集市是多维数据仓库上的逻辑视图。使用这种架构的 好处是,既可以利用规范化设计消除数据冗余,保证数据的粒度足够细;又可以利用多维结构更为灵活地在企业中 实现报表和联机分析工作。
2、维度数据建模
维度数据建模主要应用于数据仓库的设计,维度模型是一种进行查询的设计技术。
维度建模中两个核心概念是事实表和维度表。
1. 事实表主要是围绕观察数据的角度,事实表通常是对具体的度量,可以对其进行聚合、累加、计算;
2. 维度表是站在什么角度去看待问题,一组层次关系比如时间、组织、部门、地域等维度表。
维度数据建模的流程
维度数据建模的方式一般有星型模型和雪花模型、星座模型,较为常用的是星型模型。所谓星型模型就是将事实表 作为数据分析的中心,将维度表环绕着事实表。一般使用以下过程构建维度模型分为如下四个步骤:
1. 待分析的业务流程
建模的第一个步骤就是描述需要建模的业务流程,简单来说就是要分析某个业务先将此业务需求的相关业务流程梳理清楚,比如说分析订单销售情况,就要将订单表和订单详情相关的业务通过统一建模语言UML等进行梳理;
2. 确定分析的粒度
确定了分析的业务流程之后,确定事实表中要分析的业务数据的粒度,比如说订单表中的订单是秒级数据,一般从 业务流程中获取的数据都是最细(最低)粒度的数据,同一个业务分析中不要使用多种粒度,一般情况下只是用一种粒 度,比如说统计某一天(或某一个小时的)的订单总金额和订单总笔数。
3.确定分析的角度也就是维度
确定分析的纬度主要取决于分析的粒度,比如说要分析某小时或者某一天的数据,就需要时间维度进行分析,就需 要维度表——时间表。如果需要进行小区、大区、全国进行数据分析就需要使用组织维度进行分析。
4.确认使用到的事实表
待分析的业务确定下来之后,就需要获取分析的事实表(可度量)的数据表。事实表的数据都是可度量的,能够进行累加,统计的数字型数据。
3、数据集市
数据集市相比较于数据仓库最大的区别是,数据仓库数据来源于外部业务系统,外部系统数据等,而数据集市来源于数据仓库的数据;
两者的粒度是不同的,数据仓库的数据是最细粒度的数据,而数据集市是较粗粒度的数据; 数据仓库是面向企业主题的,数据集市是面向部门或者工作组的;
数据仓库是从业务库来的规范化结构数据,而数据集市是满足星型模型、雪花模型或者星座模型或者星型和雪花型模型的混合型维度模型等。
4、联机分析处理
联机分析处理又被称为 OLAP ,其允许使用多维数据集的结构,访问业务数据源进行清洗、转换、加载经过聚合后得到的聚合数据。
OLAP 是一种快速的多维分析查询的方法,DM 数据挖掘是一种发现数据内部规律的知识发现的技术,BI 商务智能侧重于将数据报表可视化。
通过使用OLAP工具,用户可以从多个视角交互式地查询多维数据 OLAP 由三个基本的分析操作构成:合并(上 卷)、下钻和切片。
合并是指数据的聚合,即数据可以在一个或多个维度上进行累积和计算。例如,所有的营业部数据被上卷到销售部门以分析销售趋势。
下钻是一种由汇总数据向下测览细节数据的技术。比如用户可以从产品分类的销售数据下钻查看单个产品的销 售情况。
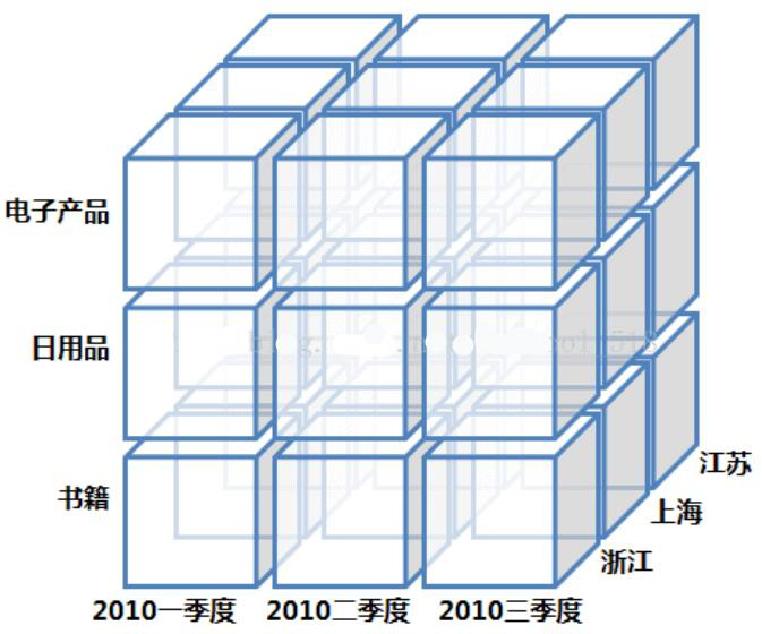
切片则是这样种特性,通过它用户可以获取OLAP立方体中的特定数据集合,并从不同的视角观察这些数据。这 些观察数据的视角就是我们所说的维度。例如通过经销商、日期、客产品或区域等,查看同一销售事实。
OLAP系统的核心是OLAP立方体,或称为多维立方体或超立方体。它由被称为度量的数值事实组成,这些度量被维度划分归类。
分类
通常将联机分析处理系统分为 ROLAP、 MOLAP 、HOLAP三种类型,其中MOLAP是一种典型的OLAP形式,默认的 OLAP 就是 MOLAP这种类型,其将数据存储在一个经过优化的多维数组中,而不是存储在关系数据库中。比如说预先计算并存 储计算后的数据这种操作叫做数据的预处理,将预计算后的数据集合作为一个数据立方体 CUBE 使用。对于给定范围的 数据都会计算出来,这样在进行查询的时候就能够快速响应。
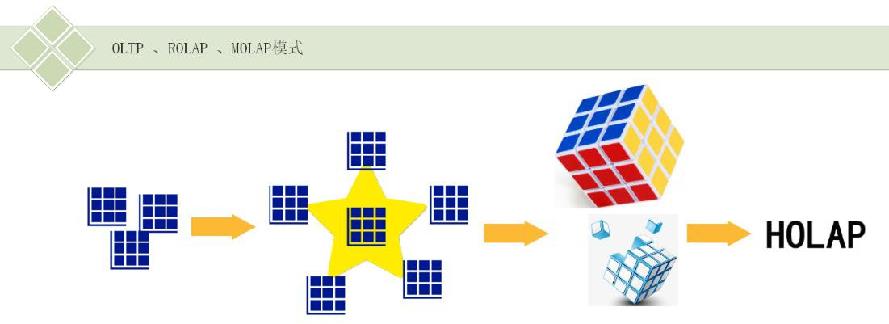
ROLAP 直接使用关系数据库存储数据,区别于 MOLAP不需要执行预计算,查询标准的关系数据库表根据过滤条件进行数据的查询聚合操作。基础的事实数据及其维度表作为关系表被存储,而聚合信息存储在新创建的附加表中,能够下钻到更为细节的明细数据。
ROLAP 以数据库模式设计为基础,操作存储在关系数据库中的数据,实现传统的OLAP数据切片和分块功能。本质上 讲,每种数据切片或分块行为都等同于在SQL语句中增加个 WHERE 子句的过滤条件。 ROLAP不使用预计算的数据立方体 ,取而代之的是查询标准的关系数据库表,返回回答问题所需的数据。
HOLAP 结合 MOLAP 和 ROLAP 两种联机分析处理方式,吸取了两种模式的优点,既可以用于细粒度的分析,也可以进行较粗粒度的数据分析处理,也支持多维立方体( CUBE )的分析。
大数据联机处理系统处理性能
OLAP分析一般涉及到的表的数据量级都非常的大,如何高效的进行数据的分析操作是首要考虑的问题,如果不能快速的对海量数据进行计算,那么 OLAP 将没什么意义,在大数据 Hadoop 生态圈中能够进行高效处理的解决方案和组件为 Impala 和 Kylin(麒麟)。
5、实时数据仓库
离线传统企业数据仓库都是 T+1 的数据。
随着企业业务数据的快速产生以及数据时效性在企业运营中的重要性日益显现,例如一些实时大屏展示,实时报表 ,实时推荐系统,实时物流信息,实时广告推荐效果等。数据的实时获取、实时处理、实时计算和实时展现的能力成为 企业竞争力的重要体现。
| 对比项 | 离线数据仓库 | 实时数据仓库 |
| 架构 | 离线大数据架构 | Kappa架构 |
| 数据时效性 | T+1 | 实时 |
| 计算框架 | MR/hive/spark | Flink等 |
| 数据吞吐量 | 批量处理、吞吐量大 | 流式处理,吞吐量较低 |
| 数据模型 | 星型、雪花等 | 宽表、轻微汇总等 |
6、实时数仓与离线数仓的对比
从架构上来说,离线数据仓库与实时数据仓库有着较为明显的差别,离线数据仓库主要以传统大数据架构体系进行设计为主,而实时数据仓库主要以 Kappa 架构设计思想为主,介于这两种架构之间有一种中间态就是 Lambda 架构。
从建设方法角度来说,离线数据仓库和实时数据仓库两者都沿用传统的数据仓库主题建模的理论,将明细数据生成 事实宽表,需要注意维度表也要存放于高速存储或读取的数据库中,比如redis等内存数据库。
从数据保障看,实时数仓要保证实时性,所以对数据量的变化较为敏感,在上线迎接大数据量流入时,要提前做好 压测和主备保障工作,这是与离线数据的一个较为明显的区别。
二、Kappa 流批一体架构
Kappa 架构的目标就是抛弃掉离线数据处理模块,形成流批统一的架构模型。这种流批统一的架构模型同时会丢掉离线计算更为可靠的特点,完全依赖于消息中间件(比如 kafka)的稳定性和缓存能力。
为了实现流批处理的一体,flink 1.12 版本真正意义的实现了流批一体的设计架构模式,flink是流式计算框 架,其中的批处理是流处理的一种特殊形式的存在。

1、Kappa 流批一体架构流程

2、Kappa 流批一体架构过程的阶段
以消息队列 kafka 作为流处理平台保留永久数据日志的的特性,重新处理实时层中的历史数据,全新的 Kappa 架 构的过程分为以下阶段:
1.输入数据存储到消息队列中比如 kafka 中,数据保留时间一般需要修改,不能使用默认的7天时间,要设置为指 定的时间区域,比如(365天)或者保留时间区域为无限制,永久。
实时层计算业务逻辑口径如果发生的变化,需要对消息队列中的所有数据进行重演(重新处理),如何重演 kafka 中的数据呢?
在实际的计算中,只需要将日志偏移量(log offset)设置为 0 即可,作业就会从最早 (earlist) 开 始处理历史数据;在流批一体中,使用 flink 作为实时计算引擎组件,Flink 的流表可以存储上百张粒度为日的数 据,从而保证微批处理足够大可以替换掉离线处理数据。
2. 后端服务层主要从将实时计算引擎得到的结果(结果存储数据库中)获取之后为用户提供查询接口并实现前端 可视化大屏展示,为用户提供查询服务。
Kappa架构能够将实时和批处理有机的结合到一起,方便运维维护,而且对外提供了一套数据口径和访问接口问题。
三、小米整体架构模型演进
1、小米整体架构 – 离线架构1.0
离线架构的目标是设计出一个能满足离线数据分析的大数据架构,参考下图离线架构流程:

首先业务数据(比如订单、店铺数据)或者埋点(手机 app 后台)数据从通过canal 或 flume采集(或使用 lua 脚本)到数据,通过负载均衡均匀分发到kafka服务器上;
每天定点跑 spark 微批次任务获取数据并进行复杂业务处理最终落地到 Hive 离线数据仓库分为四层(ODS层, DWD层,DWS层,APP层)进行复杂的业务分析,或者 HBase 数据库进行明细数据的查询操作;
Hive 离线数据仓库进行复杂的业务处理之后将数据保存到关系型数据库中,比如mysql中,提供对外查询访问 的接口;
最终将指标或者报表通过查询接口绑定前端界面或者 echarts 进行数据可视化。
2、Lambda 混合架构v2.0
Lambda 流批混合架构
Lambda 架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等 。Lambda架构整合离线计算和实时计算,融合不可变性( Immunability ),读写分离和复杂性隔离等一系列架构原则 。
Lambda 架构主要思想是将大数据系统架构分为多个层次,分别为批处理层,实时处理层,服务层等。
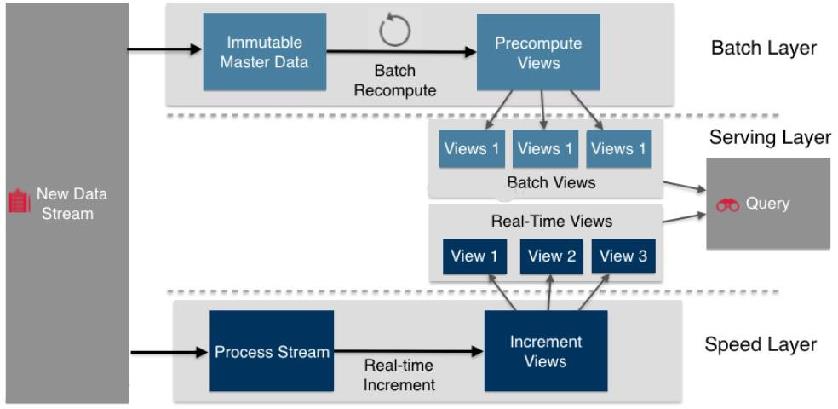
一般分为 BatchLayer 和 SpeedLayer,BatchLayer处理的是离线的全量数据,SpeedLayer处理是实时的增量 数据,BatchLayer 根据全体离线数据得到BatchView,BatchLayer处理的是全体数据集,SpeedLayer处理的数据是最近的增量数据流,SpeedLayer是增量而非重新计算,从而 SpeedLayer 是 BatchLayer 在实时性上的一个补充。
Lambda 架构的 servingLayer 用于相应用户的查询请求,合并生成的 BatchLayer和SpeedLayer的数据集到最终的数据集。
Lambda 架构的批处理部分存储一般使用 Hadoop 的 HDFS, 计算使用MapReduce离线计算;Hbase用于查询大 量的历史结果数据; 流处理部分采用增量数据处理 Structure Streaming 或 Flink Streaming 处理,存储增量 的结果一般会放到消息队列 kafka 中,内存数据库 redis 或者 分布式Mpp 数据库 clickhouse doris等。
Lambda 架构能够保障离线计算的准确性,但是对于运维来说增大了工作量,需要维护两套流程和批处理和流 处理计算框架。
3、小米架构 – lambda 架构v2.0
小米大数据平台 lambda 架构v2.0
小米 lambda 架构流程如下图所示:
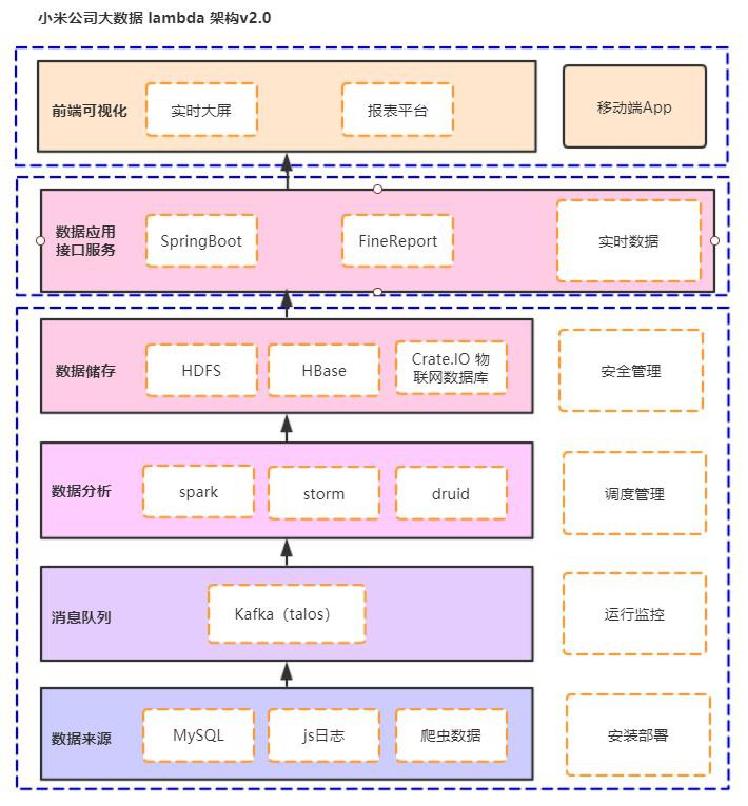
数据采集
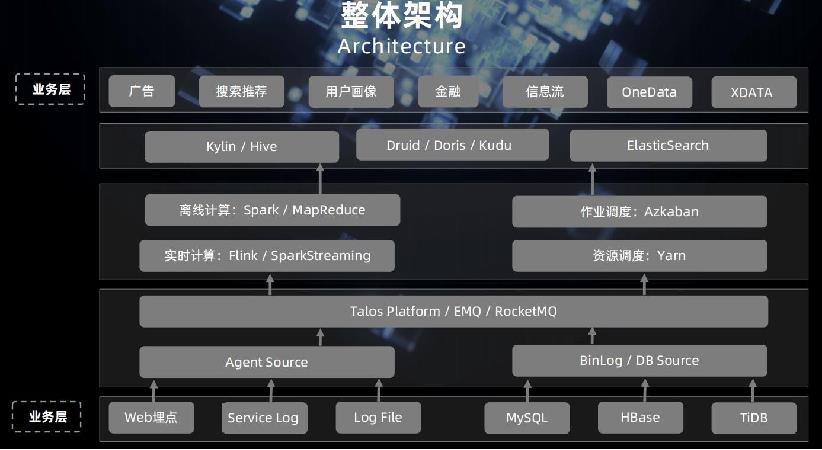
小米公司业务复杂,业务场景包括:广告、搜索推荐、用户画像、金融、信息流,OneData等场景;业务规模包括 1000+运行作业,20000+的CPU Core数,81+TB的内存数;业务数据(比如订单、店铺数据)或者埋点(手机 app 后台)数据从通过canal 或 flume采集(或使用 lua 脚本)到数据,通过负载均衡均匀分发到kafka服务器上;
数据分析和计算层
接着进行数据业务处理时,两条主线:
一条进行离线分析,spark从kafka中消费业务数据,基于业务口径进行数据的计算聚合并将数据落地到 HDFS 分布 式文件系统中,明细数据保存到 HBase中,用于即席查询;
对于传感器等物联网日志数据也会保存到 Crate.IO 分布式数据库中;
另外一条主线是 storm 实时分析 kafka 中的业务数据进行流计算,根据业务需求进行分析计算最终将结果保存到 HBase中;
同时对于时序有强相关性的数据单调递增的数据,比如根据订单时间、入库时间、采购时间、财务入账时间等业务 数据可以直接加载 kafka集群中的数据,实时聚合并将结果用于前端报表展现或者实时大屏看板的输出;
数据可视化平台
MPP数据库构建 OLAP服务的可视化平台,支持数据可视化,报表平台,如下图数鲸一站可视化平台中有某 汽车APP 用户城市占比分布饼图和热力图等展示。

4、小米架构 – kappa 流批一体架构v3.0
小米大数据平台 kappa 架构v3.0
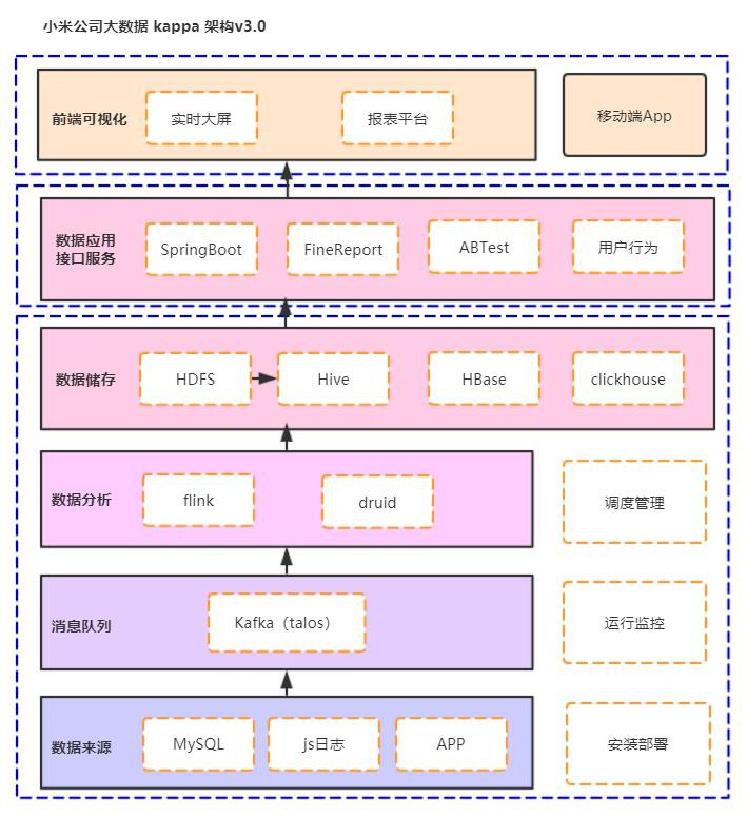
数据采集
小米内部各个业务系统每一天都会生成大量的业务数据,这些数据中有些是实时的用于计算的,有的日志数据需要先保存到文件系统后续再进行分析和处理的,当然大多数还是以关系型数据会写入到MySQL数据库中,那么如何高 效的实现业务数据向大数据分析平台的数据抽取或同步,小米内部定制了 AgentSource。
此 AgentSource平台中重要的数据采集方式,主要支持6种接入方式,分别是文件传输、HTTP传输,TailDir传输,scribe传输,Thrift传输和OceanDir传输等。
从以上6种数据源采集数据到 Talos(类似于 kafka)消息队列,我们在这里使用 kafka 作为我们的消息队列 中间件。
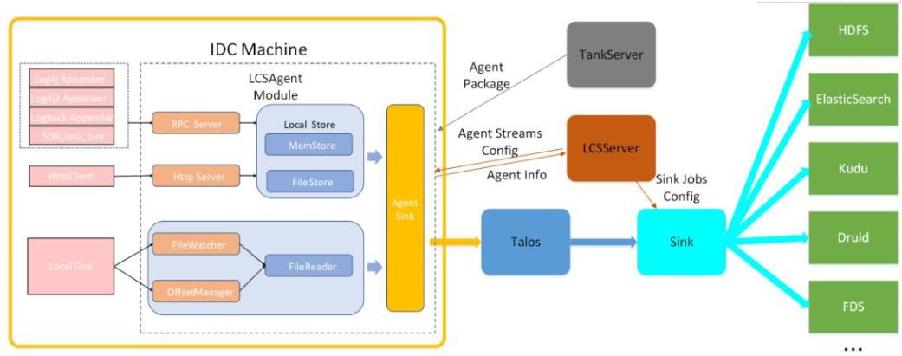
数据存储层
在小米公司的整个大数据生态中,数据存储层涉及到方方面面的技术栈,使用 HDFS 离线分布式存储会保存维度 数据,主要存储历史数据,使用redis内存数据库主要存储热数据,Kudu主要存储历史数据用于数据仓库的计算分析 ,Hive数据仓库主要用于离线数据仓库的历史数据存储,HBase主要用于存储即席数据的数据和细粒度数据明细。
数据分析和计算层
计算层主要以 flink 流式计算框架对消息队列中的数据进行实时处理,实时部分会将数据保存到clickhouse数 据库或者 doris 数据库中,来保证数据的时效性;flink 还会将离线数据保存到 Hive 离线数据仓库中,计算,用 于与实时的数据的对数、补数等;除此之外部分业务也会基于 druid on kafka 对时间序列数据进行实时聚合操作落 地存储,为实时数据提供服务保障。
数据可视化平台层
当实时数据计算之后就需要对数据进行一站式可视化的展示,基于 echarts 和 BI 报表工具对数据进行实时展 现,当然也可能是 AB测试,为某些业务用户行为分析提供数据源等。小米的基于统一OLAP服务的可视化平台统称为 数鲸平台,提供一站式服务,BI工具、可视化、用户增长分析、移动应用统计、千亿级在线分析等可视化。

下图为小米公司架构数据流程逻辑图:

首先业务数据(比如订单、店铺数据)或者埋点(手机 app 后台)数据从通过 canal 或 flume采集(或使用 lua 脚本)到数据,通过负载均衡均匀分发到 kafka 服务器上;
DWD层:Flink 集群读取 kafka(小米自研的 talos 的消息队列)集群中的业务流数据,将明细数据打成大宽表 ,分别将数据保存到离线数据仓库 hive 中,实时的 clickhouse 数据库中,前者主要作为备份和数据质量保证(对 数、补数等),后者主要作为查询与分析的核心分析操作,维度数据保存在 redis 内存数据库中;
DWS层:数据汇总层,部分指标会通过Flink进行实时计算汇总至HBase中或Redis内存数据库中,提供对外接口供 大屏展现使用;其他的业务指标或者报表通过 clickhouse 物化视图等机制周期性汇总,最终生成折线图、柱状图、热力图等报表。同时明细数据也可以保存在 clickhouse 或 hbase 中,方便高级 BI 人员通过 zeppelin 等可视化工 具对订单、店铺、手机访问的日志的进行漏斗、留存、用户行为分析等灵活地 ad-hoc 查询,这个也是 clickhouse 远超于其他 OLAP引擎的强大的地方;
对于流数据还会将数据保存到 HBase 数据库中,phoenix on hbase 通过查询业务逻辑,对最终的结果数据进行落地保存;
同时保留了 druid on kafka,基于对时间序列强相关的数据进行实时的加载汇总处理;
最终使用 springcloud 提供最终的数据服务接口,结合echarts 或 fineReport报表平台工具用于展示最终的数据。
四、环境准备
1、软件清单
| 软件名称 | 版本 | 部署节点 |
| Jdk | 8u241 | node1.cn |
| mysql | 8.0.22 | |
| ZooKeeper | 3.4.6 | |
| Hadoop | 2.7.5 | |
| Hbase | 2.1.0 | |
| Kafka | 2.11-0.11.0.3 | |
| Canal | 1.1.4 | |
| Flink | 1.11.2 | |
| Clickhouse | 21.1.2.15 |
2、环境搭建
文章篇幅有限,此处略过,后续项目篇会详细每个软件的安装步骤
本博客大数据系列文章会一直每天更新,记得收藏加关注喔~
以上是关于百度阿里腾讯平台架构都熟悉,小米大数据平台架构OLAP架构演进是否了解的主要内容,如果未能解决你的问题,请参考以下文章
大公司都有哪些开源项目~~~阿里,百度,腾讯,360,新浪,网易,小米等
大公司都有哪些开源项目~~~阿里,百度,腾讯,360,新浪,网易,小米等