python高级算法与数据结构:“你如何压缩一部英文著作”,一道来自大厂的真实面试题
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python高级算法与数据结构:“你如何压缩一部英文著作”,一道来自大厂的真实面试题相关的知识,希望对你有一定的参考价值。
不久前我经历了某大厂的后台开发面试,对方给我抛过来一道开放式题目:”给你一本英文著作,你如何实现对它的有效压缩“。我当时看到问题心里感到一股拔凉,这道题非常适合那些熟悉数据压缩理论的同学,对我们这些非专业人士,需要压缩时就调用个gzip接口的人而言,看到这种问题感觉就是当头挨了狠狠一闷棍,心中堵得慌。
我当时觉得没戏了,接下来的时间感觉不知道如何应对是好,头皮一阵发麻。不知道是不是因为”急中生智“,我突然记起来一个数据结构,似乎可以用来应对这个问题,也许不是最佳答案,但用来应对这个问题也算合适,这个数据结构就是字典树。
对压缩而言,一个重要原则就是间可能减少那些重复出现的信息。对英文单词而言,常见的一种情况就是它们经常拥有相同的前缀,例如"antique" 和 “antihem”,它们就共享了前缀"anti",因此要实现有效压缩,我们要想办法让这类共同前缀尽可能少的出现。字典树是处理这种情况的好方法,所谓字典树其实就是多叉树,对英文而言,一个父节点最多对应26个子节点,举个例子,假设我们有单词:“a”,“and”, “ant”, “antique”, “anthem”, “antler”, “antonym”,那么对应的字典树结构如下:
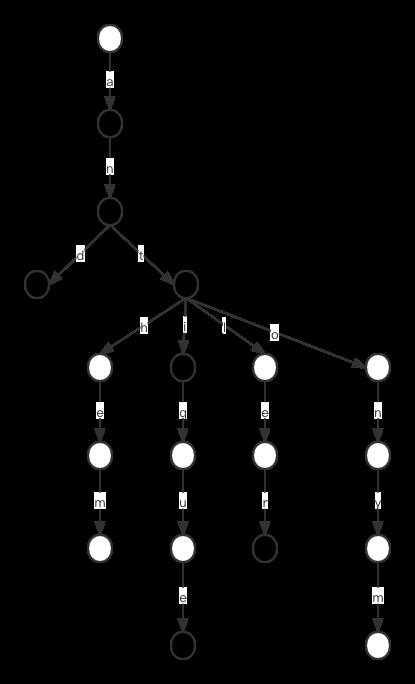
这个结构有几个特点,第一,字符出现在树的边上,第二,节点有两种类型,分别为实心和空心两种,实心节点表示,从根节点到当前实心节点路径上字符组成的字符串对应了被存储的单词,例如"and",如果是空心,那么从根节点到它路径上字符形成的字符串并没有对应存储的单词。第三,孩子节点最多有26个,但不用全部显示出来,我们只显示存储给定单词所需的节点。
首先我先用代码定义节点和字典树的类:
CHILD_NUM = 26
class Node:
def __init__(self, key_node):
self.key_node = key_node
self.children =
for c in range('a', 'z' + 1):
self.children[c] = None
class Trie: # 字典树对象
def __init__(self):
self.root = Node(False)
在代码中我们用map来存储子节点,虽然子节点最多26个,但有时候有些子节点并不需要创建,如果key_node设置为True,那表示从根节点到当前节点,路径上对应的字符合成的字符串就是我们要存储的单词。然后我们设立了字典树对象也就是Trie,然后初始化其根节点。
这里我们要注意的是,字典树的叶子节点一定是实心的,这是字典树自身特点所决定。同时从字典树的结构可以看到,所有拥有同一个父节点的子节点,他们路径对应的字符串一定共享了相同的前缀,这一点是产生”压缩“效果的所在。对于要压缩一部英文著作,除了将书中单词输入到字典树外,我们还需要在单词对应节点出生成一个队列,用来记录单词出现的位置,例如页数,行数,列数等。
下面我们看看如何搜索给定单词是否存储在字典树里。逻辑不难,假设要搜索的字符串为s,我们将其拆解成首字符加后缀s = c + s’,然后看根节点是否包含给定字符c的子节点,如果有的话,进入对应子节点,然后递归的查找是否包含s’。例如要查询"home"是否存储在字典树,我们先取出’h’,查询根节点是否有字符对应’h’的边,如果有的话得到对应子节点t,然后再次查询”ome"是否包含在以t为根节点的树中,一直这么递归,直到字符串为空时,如果对应节点的key_node为True,那么给定单词就存储在树中,要不然就不存在。
我们看看相应代码设计:
def search_node(self, node, s):
if s == "" :
return node
if len(s) > 1:
c, tail = s[0], s[1:]
else:
c, tail = s[0], ""
if c in node.children:
return None
else:
return self.search_node(node.children[c], tail)
def search(self, s):
if self.root is None :
return False
else:
return self.__search(self.root, s)
通常情况下有两种查找失败的情况,一是我们走到一个节点,它没有对应的边能匹配当前字符,另一种情况是所有字符都匹配上,但是对应节点key_node没有设置成True,这意味着对应单词没有存储在树中,具体情况如下所示:
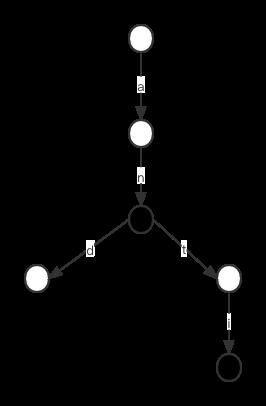
从上图看到,要搜索字符串“ant",我们会一直走到右边空心节点,但是由于空心节点对应的字符串没有存储在树中,因此即使从根节点到某个子节点,路径上的字符与要搜索的字符相对应,查找结果依然是失败。
查找是字典树中最重要的方法,后面很多方法需要依赖它。我们在该接口基础上创建另一个方法,它返回对应节点:
def search_node(self, node, s):
if s == "" :
return node
c, tail = s[0], s[1:]
if (c in node.children) is False:
return None
else:
return self.search_node(node.children[c], tail)
从效率上看,search方法的复杂度取决于两个因素,一个是字符串的长度,一个是树的高度。因此对于长度为m的字符串,search方法的时间复杂度就是O(m)。下面我们看如何将单词插入字典树,插入时又得看两种情况,第一是字典树从根节点开始有对应路径形成的字符串与插入字符串相同,例如我们要把"ant"插入上面的字典树,这时我们只要将对应节点的key_node设置成True即可。第二中情况是,在当前树中,只有一部分边能与给定字符串匹配,这样我们就得往树中增加新的节点和边。
我们看看相应的实现逻辑:
def insert(self, s):
return self.__insert(self.root, s)
def __insert(self, node, s):
if s == "": #所有边对应上,设置节点的key_node属性
node.key_node = True
return
if len(s) > 1:
c, tail = s[0], s[1:]
else:
c, tail = s[0], ""
if c in node.children: #当前节点有和当前字符匹配的边
return self.__insert(node.children[c], tail)
else:
return self.__add_new_branch(node, s) # 增加新的边与节点
def __add_new_branch(self, node, s):
if s == "":
node.key_node = True
return
if len(s) > 1:
c, tail = s[0], s[1:]
else:
c, tail = s[0], ""
node.children[c] = Node(False) # 增加新的节点和边
return self.__add_new_branch(node.children[c], tail)
现在我们可以看看如何往字典树中添加单词:
the_trie = Trie()
the_trie.insert("a")
the_trie.insert("and")
the_trie.insert("antique")
print(the_trie.search("a"))
print(the_trie.search("ant"))
上面代码运行后输出结果为True, False,这里我们可以看到,加入两个单词后,字典树中有对应"ant"的路径,但是由于该单词没有被加入字典树,因此查找它时返回False。接下来我们看看如何实现移除,移除有两种选择,一种是将节点的key_node属性设置为False,但这种做法简单,但会导致内存占用。第二种选择较为复杂,它需要把对应的节点和边删除掉。我们先看简单方法的实现:
def remove(self, s):
node = self.search_node(self.root, s) # 先找到对应节点
if node is not Node or node.key_node is False:
return False
else:
node.key_node = False
return True
在代码中首先查找字符串对应节点,该节点有两种情况,第一,节点是中间节点,有某些单词对应的节点必须通过它才能到达,第二,节点是叶子,它下面不再有子节点。第二种情况,节点就会变成“悬挂形态”,也就是它除了浪费内存外没有任何作用,如下图所示:
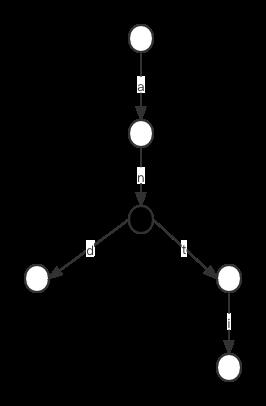
例如我们把前面字典树中包含单词"anti"删除后,右下角节点由实心变成空心,这种情况下,留着它就会造成内存占用,如果字典树中包含了很多单词,同时有进行很多次删除操作,那就有可能造成多个“悬挂”节点,从而造成内存浪费。
处理这种情况就需要进行“剪支”操作,我们删除当前悬挂节点,然后逆向回去看起父节点是否也是悬挂节点,例如上图去掉右下角节点后,它上面的父节点变成悬挂节点,因此可以继续去除,此时如果继续沿着边t返回父节点发现此时是个实心节点,这样就不能继续删除。还有一种情况是,父节点是空心节点,但它有分支使得其所在路径最终指向实心节点,那么它也不能删除,我们看看相应代码实现:
def __split(self, s):
if len(s) > 1:
c, tail = s[0], s[1:]
else:
c, tail = s[0], ""
return c, tail
def remove(self, s):
return self.__remove(self.root, s)
def __remove(self, node, s): # 该调用返回两个值,第一个用于表明当前节点是否被删除,第二个表明节点是否"悬挂"
if s == "":
deleted = node.key_node
return deleted, len(node.children.keys()) == 0
c, tail = self.__split(s)
if c in node.children:
deleted, dangling = self.__remove(node.children[c], tail)
if deleted and dangling:
node.children[c] = None # 删除悬挂边,对应节点由于没有被程序引用因此会被内存回收算法回收
if node.key_node is True and len(node.children.keys()) > 0:
dangling = False
return deleted, dangling # 当前节点是实心点或含有其他分支
else:
return False, False
我们可以简单测试一下用于删除节点的代码:
the_trie = Trie()
the_trie.insert("a")
the_trie.insert("and")
the_trie.insert("anti")
the_trie.remove("anti")
print(the_trie.search("and"))
上面代码运行后返回结果为:True, False。
对于字典树而言,它有一个非常重要功能那就是返回当前存在树中的,能与给定字符串形成最长前缀匹配的单词。假设在树中存储了单词“a",“and”, “anti”, 那么对于单词"antique",那么能与其形成最长前缀匹配的就是"anti",我们看看相应实现:
def longest_prefix(self, s):
prefix = ""
return self.__longest_prefix(self.root, s, prefix)
def __longest_prefix(self, node, s, prefix):
if s == "":
if node.key_node: # 这里意味着输入字符串是存储在树中的单词
return prefix
else:
return None
c, tail = self.__split(s)
if (c in node.children) is False:
if node.key_node: # 找到最长匹配的单词
return prefix
else:
return None # 当前树中不存在与给定字符串形成前缀匹配的单词
else:
result = self.__longest_prefix(node.children[c], tail, prefix + c) # 看看能不能再多匹配一个字符
if result is not None:
return result
elif node.key_node: # 不能继续多匹配字符,而且当前节点是实心,那么当前节点对应的字符串就是最长匹配字符
return prefix
else:
return None
我们测试一下上面实现的代码:
the_trie = Trie()
the_trie.insert("a")
the_trie.insert("and")
the_trie.insert("anti")
print(the_trie.longest_prefix("antique"))
代码运行后结果为:”anti",如此看来查找最长前缀的逻辑实现基本正确。最后我们再实现一个方法,那就是给定一个字符串,我们返回存在字典树中的所有单词。假设当前字典树存储了单词"and", “ant”, “anthem”,那么给定字符串“an"就可以把前面三个单词都返回,我们看看实现:
def keys_starting_with(self, prefix):
node = self.search_node(self.root, prefix)
if node is None:
return []
else:
return self.__all_keys(node, prefix)
def __all_keys(self, node, prefix):
keys = []
if node.key_node:
keys.append(prefix) # 输入的前缀字符串是当前节点的前缀
for c in node.children.keys():
keys += self.__all_keys(node.children[c], prefix + c) # 在当前单词基础上延长一个字符然后看给定字符串是否是存在树中的单词
return keys
上面代码虽然短,但是逻辑并不是很好理解,我们看看它的运行结果或许能更好的解释其逻辑:
the_trie = Trie()
the_trie.insert("a")
the_trie.insert("and")
the_trie.insert("anti")
the_trie.insert("anthem")
print(the_trie.keys_starting_with("an"))
上面代码运行后结果如下:
[‘and’, ‘anti’, ‘anthem’]
从输出结果看,我们把所有以“an"作为前缀的单词都返回来。代码会根据输入字符串的长度逐渐查找,同时在__all_keys实现中有一个for循环,总的循环次数不会超过树中单词数量,也就是实心节点的数量,因此该接口的时间复杂度为O(m+j)。代码下载:https://github.com/wycl16514/radix-tries.git
以上是关于python高级算法与数据结构:“你如何压缩一部英文著作”,一道来自大厂的真实面试题的主要内容,如果未能解决你的问题,请参考以下文章
python实现高级算法与数据结构:如何实现百度的竞价排名1