PBI之模拟ABC 分析矩阵的建模(一)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PBI之模拟ABC 分析矩阵的建模(一)相关的知识,希望对你有一定的参考价值。
参考技术A 郑重声明:本文用BI佐罗案例及分析思维倒推ABC矩阵建模过程,用于提升POWER BI 编写DAX函数、构建视图能力。一、运用通用业务思维确立分析的客体
(一)分析主题:销售订单分析
(二)分析维度:
1、销售区域: 地区;
2、客户属性:职业、行业、细分(公司、消费者、小公司);
3、产品类别: 技术、家具、办公用品
(三)量化分析指标(KPI)及业务逻辑:
KPI1 营业收入 = 销售数量 * 销售单价 * (1- 折扣率) 注:也可能没有折旧率 ;
KPI2 利润(利润) = 营业收入 - 营业成本
营业成本 = 销售数量 * 单位成本
KPI3 订单数量:订单的个数,通常是一条记录一个订单,则记录条数;如果是一个订单多条记录,则取订单号的个数。
(四)ABC分析法
运用28法则,找出占比20%,贡献80%的产品。
二、转化POWER BI 分析框架
(一)数据准备
本案例中涉及的表,理想状态是可以从ERP中导出下列报,通过Power Query整理后,转换成“数据模型表”,“数据模型表”通常是通过对原始数据的清洗后得来。根据个人做数据模型的经验,建立好数据模型后,这个数据模型就是一整张表,当有一张表出现问题,则整个数据都会出现问题,准备数据是一项非常基础且重要的环节,特别是使用真实数据时,脏数据是会影响到整个数据模型。
准备的表(数据)如下:
1、订单表及字段:产品ID、订单日期、发货日期、邮寄方法、客户ID、城市、销售额 、数量、折扣、利润
2、产品表及字段:产品ID、类别、子类别;
3、日期表及字段:日期、年份名称 、年份序号 、月份名称 、月份序号 、年月名称 、年月序号(注:日期表可能用不上,但,时间是描述事实发生重要维度,数据模型中不可缺少的维度)
4、地区表及字段:国家、地区、省/自治区、城市
5、客户表及字段:客户ID、客户名称、性别、年龄、职业、行业、细分
(二)数据建模(表+关系)
在数据模型中,表被分类为两种:
1、事实表(fact table ):记录业务真实发生的过程,通过字段可以看出“订单表”记录了业务发生过程,也是本次分析的主体,记录表就是事实表;
2、维度表 (Dimension table ):分析事实表的角度。
在Power BI 中数据建模就是建立表与表之间的关系,关系是通过表与表之间相同的字段建立起来的索引,就像书中的目录,可以通过目录找到的指定的内容或是地点。如:订单表与客户表是通过客户ID字段建立了关系,进一步说是客户表对订单表建立了一对多的查询关系,值得注意的是,维度表与事实表建立关系最好是单向的、一对多关系,而不是双向的、多对多关系,因为,双向与多对多增加了模型的复杂性和关系传递的多路径,会导致“筛选”计算子集出现错误。
(三)图形草稿及需要构件
佐罗老师已经给了图例,按图制做就可以。
补充一下:在写销售占比 度量值时,考虑到环境以外的上下文环境时,才意识到,自己对案例框架并没有清晰的了解,也低估了“全动态”三个字的真正含义。还是需要用图的方式来进一步说明如何“全动态”!
ABC分析受到所有外部筛选环境的影响:
1、右侧字段共享轴是由左侧分析元素决定的,分析元素是一个变量,元素类型包括:省份、行业、职业和产品四类,当选择其中一个元素名称时,则共享轴依据元素类型控制元素名称所变化,如:此时元素类型为省份,在ABC矩阵中则显示的是各个省份的帕累托图形;
2、图中标注2的筛选条件,仍然对ABC矩阵有筛选作用,如,在地区中选择东北,ACB矩阵只会显示东北省份的数据;
3、图中标注3的筛选条件,是对分析指标的筛选,此时,是对销售额的筛选,也可以切换为 利润和订单数量的分析,分析的结果会显示在ABC矩阵分析图中。
细思极恐!!!
未完,待续……
备战数学建模5-数据统计分析多项式计算
目录
一、数据统计分析
1-求矩阵或向量的最大值与最小值
max()函数用于求向量或矩阵的最大元素,min()函数用于 求向量或矩阵的最小元素。
当参数是向量时,含有有两种调用格式:
y = max(x) 表示返回向量x的最大元素存入y,若x中有复数,则取模的最大值存入y。
[y,k] = max(x) 表示返回向量x的最大值存入y,并存入相应的序号k。

我们看一下上面的例子1,求出向量x中的最大值。
x = [-43, 72, 9, 16, 23, 47] ;
y = max(x) ; %求向量的最大值
y
[y,k] = max(x) ; %求向量的最大值和对应的序号
[y,k]当参数A是矩阵的时候,函数有三种调用格式
max(A)表示返回一个行向量,向量的第i个元素是矩阵第i列的最大值。
[Y,U] = max(A)表示返回向量Y和U,Y向量记录A的每列的最大值,U记录每列最大元素的行号。
max(A,[],dim)函数:当dim等于1时,与max(A)用法一样,当dim等于2时,返回一个列向量,表示第i个元素是A矩阵第i行的最大值。

我们看一下上面的例子2,求出矩阵行列最大元素和整个矩阵的最大元素。
代码如下所示:
A = [13,-56,78; 25,63,-235; 78,25,563; 1,0,-1] ;
max(A) %返回一个行向量,表示每一列的最大值
max(A') %返回一个行向量,表示每一行的最大值
max(A,[],2)%返回一个列向量,表示每一行的最大值
max(max(A)) %返回矩阵的最大值
2-求矩阵的平均值或中值
平均值:元素和除以元素个数,中值:元素个数为奇数,取中间值,元素个数为偶数,取中间两个值的平均值。
mean()函数用于求平均值,median()函数用于求中值。

我们对x求平均值,得到1900,求中值为1200,由于个不饿同学生活费过高,导致均值过高,所以此处选择中值作为生活额度更合理。
x = [1200, 800, 1500, 1000, 5000] ;
mean(x)
median(x)
3-求和和求积
sum()函数是矩阵或向量的求和函数,prod()函数是矩阵或向量的求积函数。
cumsum()函数求累加和,cumprod()函数求累乘积。
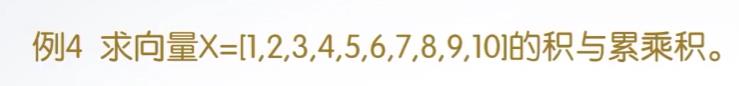
我们看一下上面的例子4,代码如下所示,其中积是一个标量,累乘积是一个向量,向量中的每个值都是之前元素的累乘值。代码如下所示:
x = [1,2,3,4,5,6,7,8,9,10] ;
y1 = prod(x)
y2 = cumprod(x) 4-标准差与相关系数
标准差用于计算数据偏离平均数的距离的平均值,std()函数计算标准差。
标准差的计算公式如下所示:s1为样本标准差,s2为总体标准差

调用格式:
(1)std(x):计算向量x的标准差。
(2) std(A):计算矩阵各列的标准差。
(3)std(A,flag,dim):flag取0或1,当flag取0,按s1所列公式计算样本标准差,flag=1时,按s2总体公式计算总体标准差。默认情况下,flag等于0,dim等于1.

我们看一下上面的例子5,具体的代码如下所示:
x = randn(50000,4) ;
y1 = std(x,0,1) %按公式s1求样本标准差
y2 = std(x,1,1) %按公式s2求总体标准差
%下面的写法也是可以的
x = randn(50000,4) ;
x1 = x' ;
y3 = std(x1,0,2);
y3'
y4 = std(x1,1,2);
y4'相关系数:能够反映两组序列之间的相互关系,其值越是接近于0,说明序列相关度越低,其值的绝对值越接近于1,说明序列的相关度越高。相关系数的计算公式如下:

corrcoef()函数计算相关系数。
该函数的调用方式如下:
corrcoef(A):返回矩阵A形成的一个相关系数矩阵,其中第i行第j列的元素表示原矩阵A中第i行第j列的相关系数。
corrcoef(X,Y):在这里,X,Y是向量,它们与这个crrcoef([X,Y])一样,用于求向量X,Y的相关系数。
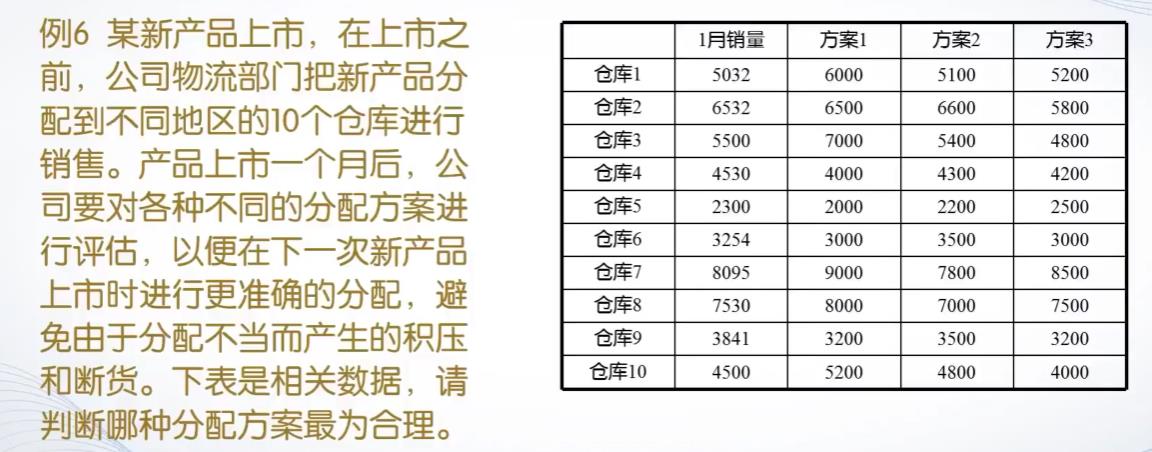
我们看一下例子6,1月销量和各个方案的相关系数,判断哪个方案最为合理,相关系数的绝对值越接近于1,说明相关性越强,最适合选择。
代码如下,求出的第一列与后面3列的相关系数分别为0.9630 0.9906 0.9782,故选择方案2最合理。
A = [5032, 6000, 5100, 5200;
6531, 6500, 6600, 5800;
5500, 7000, 5400, 4800;
4530, 4000, 4300, 4200;
2300, 2000, 2200, 2500;
3254, 3000, 3500, 3000;
8095, 9000, 7800, 8500;
7530, 8000, 7000, 7500;
3841, 3200, 3500, 3200;
4500, 5200, 4800, 4000];
corrcoef(A)5-排序
MATLAB中的排序函数sort().
排序函数的调用个数如下:
sort(X):对向量X按照升序进行排序。
[Y,I] = sort(A, dim, model):其中,dim指明对A的列还是行进行排序,model设置按照升序还是降序排序,默认升序,若取‘ascend’,则按升序,若取'descend'则按照降序排序。Y代表排序后的矩阵,I记录了Y中的元素在A中的位置。

我们看一下上面的例子7,对矩阵A进行各种排序。
A = [1, -8, 5; 4, 12, 6; 13, 7, -13] ;
sort(A) %对A的每一列进行升序排序
sort(A, 2, 'descend') %对A的每一行进行降序排序
[X,I] = sort(A) %对矩阵A进行升序排序,X是排序后的结果,I记录元素在A中的位置二、多项式计算
1-多项式的表示
在MATLAB中,n次的多项式用长度为n+1的行向量表示,如下所示:

在MATLAB中创建多项式向量时候,需要注意三点:
第一,多项式系数向量的顺序是从高到底。
第二,多项式系数向量包含0次项系数,所以其长度为多项式最高次加1。
第三,如果有的项没有,系数向量位置应该用0补充。
2-多项式的四则运算
1-多项式的加减运算,就是相应向量的相加减。
2-多项式乘法,使用多项式乘法函数conv(p1,p2),其中p1和p2是两个多项式系数向量。
3-多项式除法,[Q,r] = deconv(p1,p2),其中Q是多项式p1除以p2的商式,r是p1除以p2的余式,Q环和r仍是多项式的系数向量。
我们可以发现deconv()函数是conv()函数的逆函数,故我们可以得到如下等式:
p1 = conv(p2,Q) + r ;

我们通过上面的例子1,看一下多项式的四则运算,代码如下所示:
f = [3, -5, 0, -7, 5, 6] ;
g = [3, 5, -3] ;
g1 = [0, 0, 0, g] ;
f + g1
f - g1
conv(f,g)
[Q, r] = deconv(f, g)3-多项式的求导
在MATLAB中我们使用polyder()函数进行求导。
该函数的调用个数有如下几种:
p = polyder(P)表示求多项式P的导数。
p = polyder(P,Q)表示求P.Q的导函数。
[p,q] = polyder(P,Q)表示求P/Q的导函数,导函数的分子存入p,分母存入q。

我们看一下上面的例子2,求多项式乘积和商的导函数,代码如下所示:
a = [3, 1, 0, -6] ;
b = [1,2];
d = conv(a,b) ; %求两个多项式之积
c = polyder(d) %求导函数
c = polyder(a,b) %直接求两个多项式之积的导函数
[p,q] = polyder(a,b) %求多项式相除的导函数,导数的分子存入p,分母存入q4-多项式的求值
MATLAB中使用polyval(p,x)函数进行代数多项式求值,使用polyvalm(p,x)进行矩阵多项式求值。



我们看一下上面的例子2,具体的代码如下所示:
a = [1, 8, 0, 0, -10] ;
x = [-1, 1.2; 2, 1.8] ;
y1 = polyval(a,x)
y2 = polyvalm(a,x)
5-多项式的求根
MATLAB中使用roots(p)函数求多项式p的根,其中p为多项式的系数向量。

看一下上面的例子,代码如下所示:
a = [1, 8, 0, 0, -10] ;
roots(a)若已知多项式的全部根,可以用poly函数建立其多项式,调用格式为p = poly(x),x为根,p为系数向量。

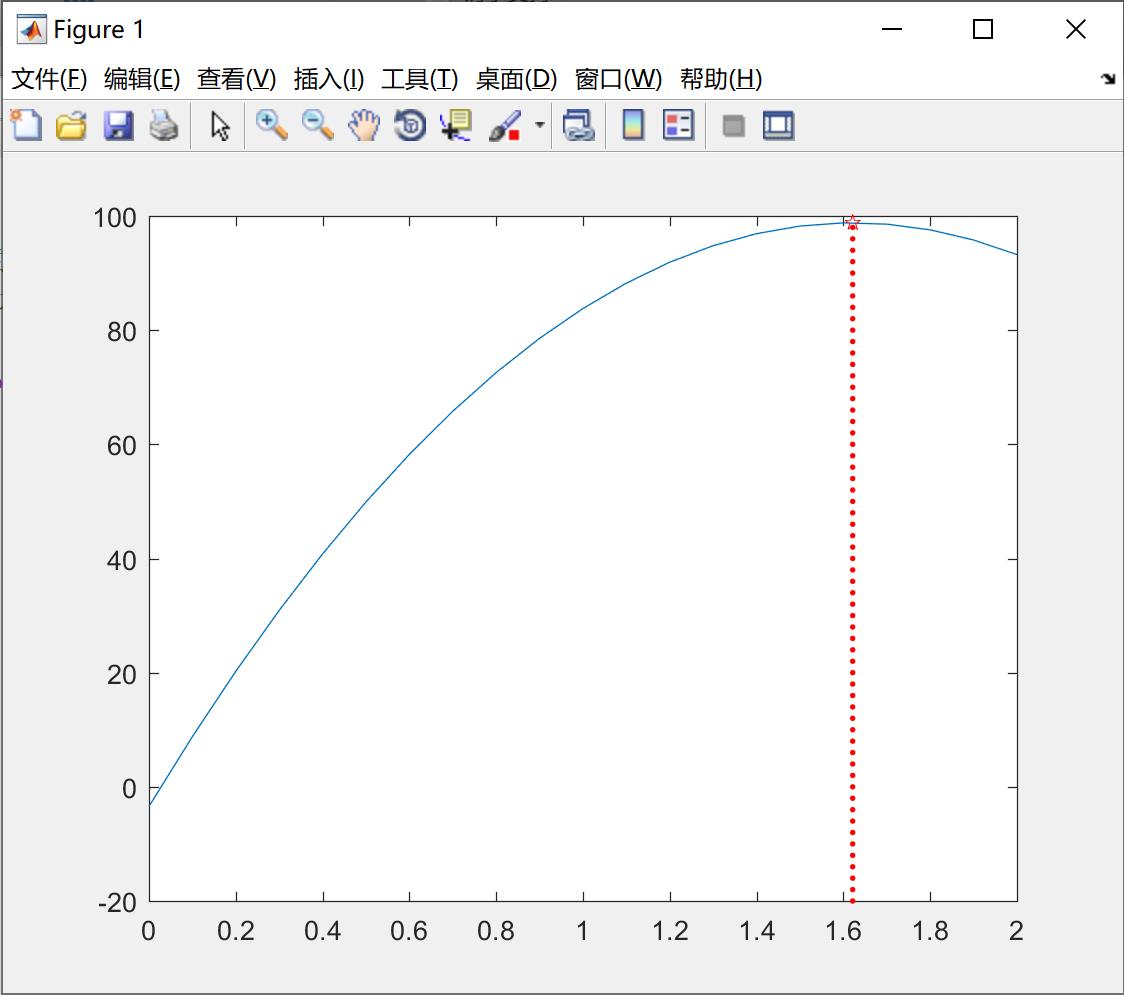
我们看一下例子4这个优化问题,其实就算找多项式在区间内的极值点,代码如下:
p = [-38.89, 126.11, -3.42] ; %构建多项式系数向量
q = polyder(p) ; %求导数
r = roots(q) %求导数等于0时候的根
ans = polyval(p,r) %根据极值点求极值
x = 0 : 0.1 : 2 ;
plot(x, polyval(p,x),r,ans,'rp')
set(gca, 'xTick', 0:0.2:2) ;
hold on ;
y = -20 : 2 : ans ;
plot(x1,y,'r.')绘制的图形如下所示,我们可以发现,当x= 1.6214时,加热效率p(x)最高,最高为 98.8154.
以上是关于PBI之模拟ABC 分析矩阵的建模(一)的主要内容,如果未能解决你的问题,请参考以下文章
AtCoder abc256全题解(区间合并模板矩阵快速幂优化dp线段树……)