对抗生成网络GAN系列——GAN原理及手写数字生成小案例
Posted 秃头小苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对抗生成网络GAN系列——GAN原理及手写数字生成小案例相关的知识,希望对你有一定的参考价值。
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:目标检测系列——开山之作RCNN原理详解 目标检测系列——Fast R-CNN原理详解 目标检测系列——Faster R-CNN原理详解
🍊近期目标:拥有10000粉丝
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
文章目录
对抗生成网络GAN系列——GAN原理及手写数字生成小案例
写在前面
其实关于GAN的讲解我早就做过一期,点击☞☞☞了解详情🌱🌱🌱由于最近会用到GAN的一些知识,自己又对GAN进行了一些整理,有了一些新的认识,便写了这篇文章。那么这篇文章和早期的文章有什么区别呢?首先,早期的文章只是对GAN做了一个大概的认识,而这篇文章会贴合论文较为详细的讲解GAN网络;其次,这次我准备写一个GAN系列,介绍一些经典的GAN网络,所以这篇文章和后面打算写的文章关联性更强。【注:我觉得大家可以先去读一下我之前的文章,对于损失函数部分我通过一个例子来讲解,还是很好理解的,文章也很短,能让大家快速对GAN有一个感性的认识】
准备好了嘛,下面就正式发车了。🚖🚖🚖
GAN简介
这里先来简单的介绍一下GAN,其完整的名称为Generative Adversarial Nets (生成对抗网络) 。其实这个起名还有个小故事,我简要的说一下,大家随便听听,就当放松了。当时作者Goodfellow 对于这篇文章其实是有好几个备选名字的,后来一个中国人说GAN(干)在中国有一种对抗的意思,作者一听,直接拍案选择了这个名称。🍋🍋🍋
接下来让我们看看论文中对GAN的解释,如下图所示:

我简单的来翻译一下,其大致意思是说:在我们提出的对抗生成网络中,有一个生成模型,也有一个对抗模型,它们互相对抗,互相促进。文中也举了个小例子,生成模型可以被认为是一个假币伪造团队,试图生产假币并使用,而判别器类似于警察,试图发现假币。这就是一个互相博弈的过程,生成模型不断的产生伪造水平高的假币,而判别器不断提高警察识别假币水平,直至两者达到一个平衡。这个平衡是指什么呢?即判别器对于生成模型产生的假币辨别的成功率大致为50%,即很难辨别真假。
生成对抗网络✨✨✨
GAN损失函数🧅🧅🧅
这部分我们主要结合生成对抗网络的损失函数来介绍网络的整个流程,首先呢,我们需要对一些字母做一些解释。如下:
| Z Z Z | 随机噪声 |
|---|---|
| P z ( Z ) P_z(Z) Pz(Z) | 随机噪声Z服从的概率分布 |
| G ( Z ; θ g ) G(Z;\\theta_g) G(Z;θg) | 生成器:输出为噪声Z,输出为假图像 |
| P g P_g Pg | 生成器生成的假图像服从的概率分布 |
| X ∼ P d a t a X \\sim P_data X∼Pdata | 真实数据服从的概率分布 |
| D ( X ; θ d ) D(X;\\theta_d) D(X;θd) | 判别器:输入为图像,输出为该图像为真实图像的概率,概率在[0,1]之间 |
对上述字母有一定的了解后,下面就可以给出生成对抗网络的损失函数了,如下图所示:

乍一看这个公式你应该是懵逼的,下面就跟着我的思路来分解分解上述公式。首先这个公式应该有两部分,一部分为给定G,找到使V最大化的D;另一部分为给定D,找到使V最小化的G。
我们先来看第一部分,即给定G,找到使V最大化的D。如下图所示:【注:我们为什么想要找到使V最大化的D,是因为使V最大化的D会使判别器的效果最好】
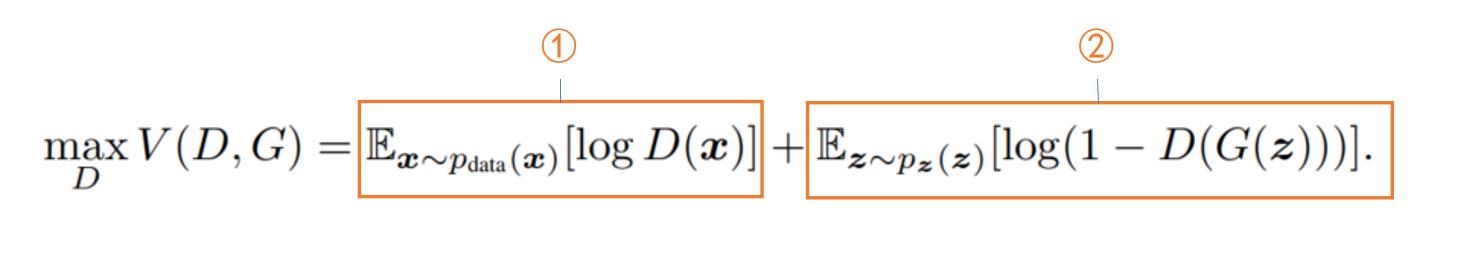
首先看第①部分,因为判别器此时的输入为 X X X,是真实数据, E X ∼ P d a t a [ l o g D ( X ) ] E_X \\sim P_data[logD(X)] EX∼Pdata[logD(X)] 值越大表示判别器认为输入X为真实数据的概率越大,也即表示判别器能力越强,因此这项的输出越大对判别器来说越好。接着来看第②部分,注意此时判别器的输入为 G ( Z ) G(Z) G(Z),即输入为假图像,那么此时对于 D ( G ( Z ) ) D(G(Z)) D(G(Z))来说这个值越小,表示判别器判定假图像为真实数据的概率越小,同样表示判别器能力越强。需要注意的是第二项为 l o g ( 1 − D ( G ( Z ) ) ) log(1-D(G(Z))) log(1−D(G(Z))) 的期望,当判别器越强时, D ( G ( Z ) ) D(G(Z)) D(G(Z)) 值越小,而 E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( Z ) ) ) ] E_z \\sim p_z(z)[log(1-D(G(Z)))] Ez∼pz(z)[log(1−D(G(Z)))] 越大。【注:部分①和部分②要想使给定G时,判别器的效果最好,都需要最大化V,即给定G,找到最大化V的D会使判别器的效果最好。】为方便大家理解,画出 l o g ( 1 − D ( G ( Z ) ) ) log(1-D(G(Z))) log(1−D(G(Z))) 的函数图像如下:

接着我们来看第二部分,即给定D,找到使V最小化的G。如下图所示:【注:我们为什么想要找到使V最小化的G,是因为使V最小化的D会使生成器的效果最好】

同样的,先来看第①部分,由于这次我们是固定了D,而①只和D有关,因此这部分是常量,其对最小化V是没有任何影响的,可以舍去。那么我们就来看看第②部分,此时判别器的输入同样是 G ( Z ) G(Z) G(Z),为假图像。不同的是现在我们期待的是生成器的效果好,即尽可能的瞒过判别器,也即期望 D ( G ( Z ) ) D(G(Z)) D(G(Z)) 尽可能大。 D ( G ( Z ) ) D(G(Z)) D(G(Z))越大就表示判别器判定假图像为真实数据的概率越大,也就表示生成器生成的图像效果好,可以很成功的骗过判别器。同样的 D ( G ( Z ) ) D(G(Z)) D(G(Z)) 值越大, E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( Z ) ) ) ] E_z \\sim p_z(z)[log(1-D(G(Z)))] Ez∼pz(z)[log(1−D(G(Z)))] 就越小,因此给定D,找到最小化V的G会使生成器的效果最好。
GAN流程🧅🧅🧅
论文中在给出损失函数后,又给了一个图例来解释GAN的过程,用原文的话来说就是一个不怎么正式,却更具教学意义的解释。(See Figure 1 for a less formal, more pedagogical explanation of the approach )

其实上图中的文字标注已经将这个过程解释的相当详细了,我再来简单的复述一遍。首先图中黑点表示真实图像的分布,绿点表示生成图像的概率分布,蓝点表示判别器预测 X X X为真实数据的概率。在(a)时,黑点和绿点的分布相差较大,判别器能大致辨别真实图像和生成图像,但分辨效果不好。【因为在黑点集中区域蓝点的值普遍较高,表示预测蓝点为真实图像的概率较大;同理,在绿点集中区域蓝点的值普遍较低,表示预测绿点为真实图像的概率较小。】 从(a)到(b)经过了判别器的训练,这会导致什么结果呢,从图(b)中可以发现,此时绿点表现的更加稳定,在黑点集中处预测概率大,在绿点集中处预测概率小,也就是说此时的判别器已经能很好的分辨什么是真实图像,什么是生成的假图像了。接下来从(b)到(c)经过了生成器的训练,这会导致什么结果呢,从图(c)中可以发现,此时绿点逐渐像黑点靠近,即生成的图像更加真实了,而此时蓝点没有变化,这就会导致现在判别器对真实图像和生成图像的辨别难度变大了。这样不断的训练判别器和生成器,最后变成图(d),即真实图像分部和生成器生成图像分布完全一致,判别器预测概率恒为0.5,也即此时判别器完全无法区分真实图像很生成图像了。🌾🌾🌾
接下来论文中给出了训练GAN网络的伪代码,如下图所示:

如果我前文的描述你都听懂了的话,其实这个过程就没什么好说的了,就是对判别器和生成器不断的迭代更新。需要注意的有两点,第一是在训练过程中,我们是训练K次判别器,训练一次生成器;第二是在训练生成器过程中,我们的损失函数没有了
1
m
∑
i
=
1
m
log
D
(
x
(
i
)
)
\\frac1m\\sum\\limits_i = 1^m \\log D(x^(i))
m1i=1∑mlogD(x(i)) 这一项,这个我在GAN损失函数这节有提到,因为训练生成器G时固定了判别器D,该项是定值,可省略。【注:这里的
1
m
∑
i
=
1
m
log
D
(
x
(
i
)
)
\\frac1m\\sum\\limits_i = 1^m \\log D(x^(i))
m1i=1∑mlogD(x(i)) 和
E
X
∼
P
d
a
t
a
[
l
o
g
D
(
X
)
]
E_X \\sim P_data[logD(X)]
EX∼Pdata[logD(X)] 完全一样,只是一个是用均值表示,一个用期望表示。】
GAN实现效果🧅🧅🧅
论文中给出了GAN的一些实现效果的图片,如下图所示:

上面四个图中,注意黄框框住的并不是GAN生成的图片,它们表示与GAN生成图片最相似的原始真实图片。而GAN生成的图片为黄框左侧第一张图片,可以看出,GAN生成的效果还是挺好的。
使用GAN生成手写数字小demo✨✨✨
上文算是把原理讲述清楚了,若你还不明白,慢慢的阅读每句话,加入自己的思考,或许会有不一样的收获。那么这节我讲来讲讲通过GAN网络生成手写数字的小demo,通过这部分你会了解搭建GAN网络的基本流程。下面就让我们一起来学学吧!!!🌻🌻🌻【注:其实大致的流程和一般分类网络的搭建是类似的,相关分类网络的搭建流程可参考我的这篇博文】
首先训练一个模型肯定少不了数据集,我们通过一下代码获取torch自带的MNIST数据集,代码如下:
#MNIST数据集获取
dataset = torchvision.datasets.MNIST("mnist_data", train=True, download=True,
transform=torchvision.transforms.Compose(
[
torchvision.transforms.Resize(28),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.5], [0.5]),
]
)
)
之后我们通过DataLoader方法加载数据集,代码如下:
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)
这样数据就准备好了,下面就来构建我们的模型,分为生成器(Generator)和判别器(Discriminator)。【注:由于这期算是入门GAN,所以模型搭建只采用了全连接层】
生成器模型搭建:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 128),
torch.nn.BatchNorm1d(128),
torch.nn.GELU(),
nn.Linear(128, 256),
torch.nn.BatchNorm1d(256),
torch.nn.GELU(),
nn.Linear(256, 512),
torch.nn.BatchNorm1d(512),
torch.nn.GELU(),
nn.Linear(512, 1024),
torch.nn.BatchNorm1d(1024),
torch.nn.GELU(),
nn.Linear(1024, np.prod(image_size, dtype=np.int32)),
nn.Sigmoid(),
)
def forward(self, z):
# shape of z: [batchsize, latent_dim]
output = self.model(z)
image = output.reshape(z.shape[0], *image_size)
return image
判别器模型搭建:
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(np.prod(image_size, dtype=np.int32), 512),
torch.nn.GELU(),
nn.Linear(512, 256),
torch.nn.GELU(),
nn.Linear(256, 128),
torch.nn.GELU(),
nn.Linear(128, 64),
torch.nn.GELU(),
nn.Linear(64, 32),
torch.nn.GELU(),
nn.Linear(32, 1),
nn.Sigmoid(),
)
def forward(self, image):
# shape of image: [batchsize, 1, 28, 28]
prob = self.model(image.reshape(image.shape[0], -1))
return prob
模型搭建好后,我们会对损失函数、优化器等参数进行设置:
g_optimizer = torch.optim.Adam(g以上是关于对抗生成网络GAN系列——GAN原理及手写数字生成小案例的主要内容,如果未能解决你的问题,请参考以下文章
[Pytorch系列-61]:生成对抗网络GAN - 基本原理 - 自动生成手写数字案例分析
对抗生成网络GAN系列——CycleGAN简介及图片春冬变换案例
生成对抗网络(GAN)详细介绍及数字手写体生成应用仿真(附代码)