GAN 系列的探索与pytorch实现 (数字对抗样本生成)
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GAN 系列的探索与pytorch实现 (数字对抗样本生成)相关的知识,希望对你有一定的参考价值。
GAN 系列的探索与pytorch实现 (数字对抗样本生成)
GAN的简单介绍
生成对抗网络(英语:Generative Adversarial Network,简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由伊恩·古德费洛等人于2014年提出。生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
生成对抗网络常用于生成以假乱真的图片。此外,该方法还被用于生成影片、三维物体模型等。
虽然生成对抗网络原先是为了无监督学习提出的,它也被证明对半监督学习、完全监督学习、强化学习是有用的。在一个2016年的研讨会,杨立昆描述生成式对抗网络是“机器学习这二十年来最酷的想法”。
若想仔细的了解一下,具体的介绍和应用都在一文看懂「生成对抗网络 - GAN」基本原理+10种典型算法+13种应用中有详细的介绍
生成对抗网络 GAN 的基本原理
大白话版本
知乎上有一个很不错的解释,大家应该都能理解:
假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的「运动」,警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。

警察们开始继续训练自己的破案技术,开始抓住那些越来越狡猾的小偷。随着这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯;小偷们的日子也不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。

为了避免被捕,小偷们努力表现得不那么「可疑」,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。随着警察和小偷之间的这种「交流」与「切磋」,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了「火眼金睛」,一旦发现可疑人员,就能马上发现并及时控制——最终,我们同时得到了最强的小偷和最强的警察。

非大白话版本
生成对抗网络(GAN)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”

下面详细介绍一下过程:
第一阶段:固定「判别器D」,训练「生成器G」
我们使用一个还 OK 判别器,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。
一开始,「生成器G」还很弱,所以很容易被揪出来。
但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。
到了这个时候,「判别器D」基本属于瞎猜的状态,判断是否为假数据的概率为50%。

第二阶段:固定「生成器G」,训练「判别器D」
当通过了第一阶段,继续训练「生成器G」就没有意义了。这个时候我们固定「生成器G」,然后开始训练「判别器D」。
「判别器D」通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,「生成器G」已经无法骗过「判别器D」。

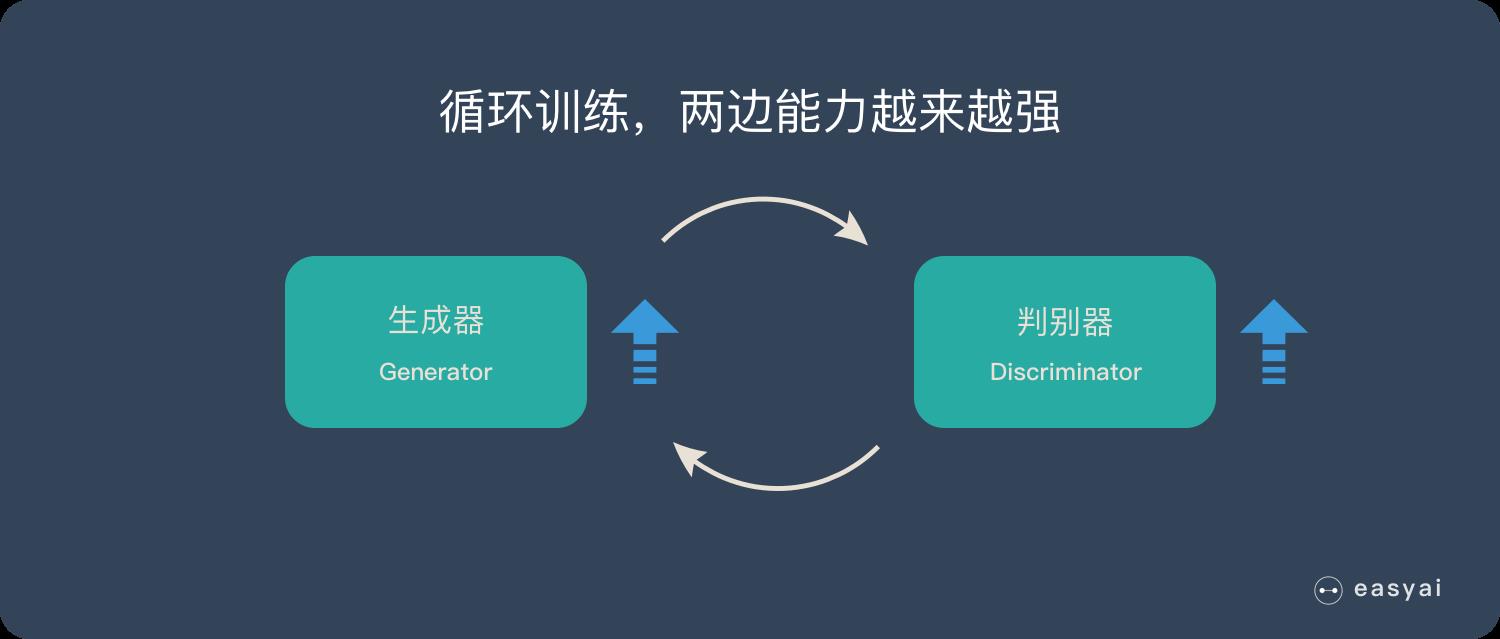
循环阶段一和阶段二
通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。
最终我们得到了一个效果非常好的「生成器G」,我们就可以用它来生成我们想要的图片了。
下面的实际应用部分会展示很多“惊艳”的案例。
如果对 GAN 的详细技术原理感兴趣,可以看看下面2篇文章:
数字对抗样本产生
首先简要看一下我们的实验
LeNet是一个小型的神经网络结构,仅包含两层卷积层、两个池化层以及三层全连接。该轻量级网络能快速、占内存小、高精确度的解决复杂度比较低的问题,如手写数字识别。本实验要求:
- (步骤1)用
LeNet网络完成手写数字识别任务。 - (步骤2)利用对抗样本工具包生成针对该网络的对抗样本。
步骤1:用LeNet网络完成手写数字识别任务。
LeNet 网络
在之前VGG的介绍中,我们介绍了一个ILSVRC比赛,当时说我们的VGG是14年的亚军,但是在之前,LetNet曾统治过一个时代。LeNet-5是较早的一个卷积神经网络,在1998年的时候被提出。这个网络一大特点,是那时候计算机处理速度不快,因此网络整个的设计都比较小,总参数约6万个。
开山之作:LeNet
LetNet是卷积神经网络的祖师爷LeCun在1998年提出,用于解决手写数字识别的视觉任务。自那时起,CNN的最基本的架构就定下来了:卷积层、池化层、全连接层。如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5(-5表示具有5个层),和原始的LeNet有些许不同,比如把激活函数改为了现在很常用的ReLu。
可以说,它定义了CNN的基本组件,是CNN的鼻祖。
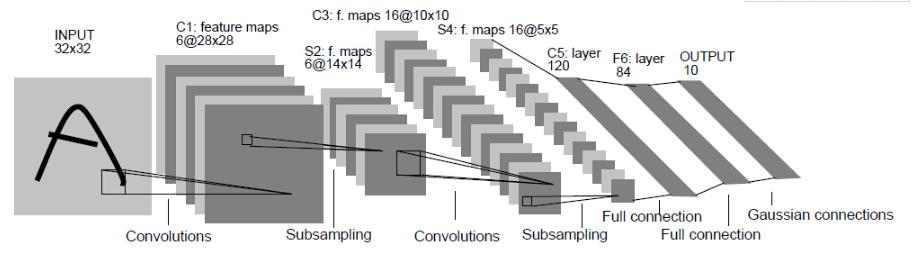
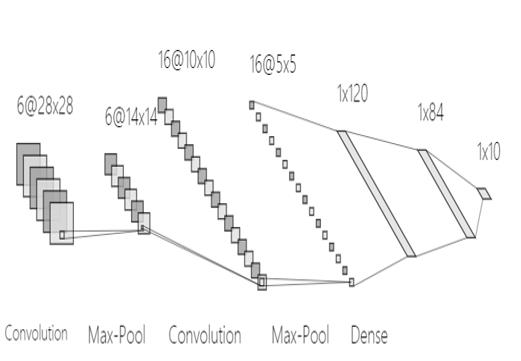
LeNet-5跟现有的conv->pool->ReLU的套路不同,它使用的方式是conv1->pool->conv2->pool2再接全连接层,但是不变的是,卷积层后紧接池化层的模式依旧不变。

以上图为例,对经典的LeNet-5做深入分析:
- 首先输入图像是单通道的28*28大小的图像,用矩阵表示就是[1,28,28]
- 第一个卷积层conv1所用的卷积核尺寸为5*5,滑动步长为1,卷积核数目为20,那么经过该层后图像尺寸变为24,28-5+1=24,输出矩阵为[20,24,24]。
- 第一个池化层pool核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为12×12,输出矩阵为[20,12,12]。
- 第二个卷积层conv2的卷积核尺寸为5*5,步长1,卷积核数目为50,卷积后图像尺寸变为8,这是因为12-5+1=8,输出矩阵为[50,8,8].
- 第二个池化层pool2核尺寸为2*2,步长2,这是没有重叠的max pooling,池化操作后,图像尺寸减半,变为4×4,输出矩阵为[50,4,4]。
- pool2后面接全连接层fc1,神经元数目为500,再接relu激活函数。
- 再接fc2,神经元个数为10,得到10维的特征向量,用于10个数字的分类训练,送入softmaxt分类,得到分类结果的概率output。
数据集的下载和预处理
这里我们用的都是经典的数据集,也就是minst数据集,并且我们可以利用torchvision,他还提供了transforms类可以用来正规化处理数据。
# mean = 0.5
# std = 0.5
mean = 0.1307
std = 0.3081
transformtion = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((mean,),(std,))]
)
train_dataset = datasets.MNIST('./mnist',train=True,transform = transformtion, download=True)
test_dataset = datasets.MNIST('./mnist',train=False,transform = transformtion, download=True)
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=64,shuffle=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=64,shuffle=True, num_workers=4)
len(train_dataset),len(test_dataset)
(60000, 10000)
我们可以看到我们的训练数据集有60000个,测试数据集有10000个
Image displaying
import matplotlib.pyplot as plt
def plot_img(image):
image = image.numpy()[0]
# print(image.shape)
image = ((mean * image) + std)
plt.imshow(image ,cmap='gray')
images, label = next(iter(train_loader))
img = torchvision.utils.make_grid(images)
img= img.numpy().transpose(1,2,0)
img = img*std + mean
plt.imshow(img)

pytorch 搭建LeNet
在前面我们已经粗略的介绍了一下我们的LeNet,现在我们就可以用Pytorch来搭建我们的LeNet模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 输入 1 * 28 * 28
self.conv = nn.Sequential(
# 卷积层1
# 在输入基础上增加了padding,28 * 28 -> 32 * 32
# 1 * 32 * 32 -> 6 * 28 * 28
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), nn.ReLU(),
# 6 * 28 * 28 -> 6 * 14 * 14
nn.MaxPool2d(kernel_size=2, stride=2), # kernel_size, stride
# 卷积层2
# 6 * 14 * 14 -> 16 * 10 * 10
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), nn.ReLU(),
# 16 * 10 * 10 -> 16 * 5 * 5
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
# 全连接层1
nn.Linear(in_features=16 * 5 * 5, out_features=120),
nn.ReLU(),
# 全连接层2
nn.Linear(in_features=120, out_features=84),
nn.ReLU(),
nn.Linear(in_features=84, out_features=10)
)
def forward(self, img):
img = self.conv(img)
out = img.view(img.size(0),-1)
out = self.fc(out)
return out
summary(net, (1, 28, 28))
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 6, 28, 28] 156 ReLU-2 [-1, 6, 28, 28] 0 MaxPool2d-3 [-1, 6, 14, 14] 0 Conv2d-4 [-1, 16, 10, 10] 2,416 ReLU-5 [-1, 16, 10, 10] 0 MaxPool2d-6 [-1, 16, 5, 5] 0 Linear-7 [-1, 120] 48,120 ReLU-8 [-1, 120] 0 Linear-9 [-1, 84] 10,164 ReLU-10 [-1, 84] 0 Linear-11 [-1, 10] 850 ================================================================ Total params: 61,706 Trainable params: 61,706 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.11 Params size (MB): 0.24 Estimated Total Size (MB): 0.35 ----------------------------------------------------------------
LetNet 训练
超参数的设置
首先我们进行超参数的设置
lr = 1e-2
momentum = 0.9
weight_decay = 5e-4
nepochs = 300
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=momentum, weight_decay=weight_decay, nesterov=True) # 优化器
criterion = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.5,verbose=True,patience = 5,min_lr = 0.000001) # 动态更新学习率
训练及测试模型
然后我们就可以进行训练了
[150/200, 9 seconds]| loss: 0.27686, accuaracy: 99.99% | val_loss: 3.08028, val_accuaracy: 99.08% [151/200, 9 seconds]| loss: 0.27358, accuaracy: 99.98% | val_loss: 3.05407, val_accuaracy: 98.99% [152/200, 9 seconds]| loss: 0.27556, accuaracy: 99.99% | val_loss: 3.21076, val_accuaracy: 98.99% [153/200, 9 seconds]| loss: 0.27647, accuaracy: 99.98% | val_loss: 3.00075, val_accuaracy: 99.08% [154/200, 9 seconds]| loss: 0.27396, accuaracy: 99.98% | val_loss: 3.15662, val_accuaracy: 99.03% [155/200, 8 seconds]| loss: 0.27436, accuaracy: 99.98% | val_loss: 2.98197, val_accuaracy: 99.05% [156/200, 9 seconds]| loss: 0.27354, accuaracy: 99.98% | val_loss: 3.07788, val_accuaracy: 99.07% [157/200, 9 seconds]| loss: 0.27384, accuaracy: 99.98% | val_loss: 3.07084, val_accuaracy: 99.07% [158/200, 9 seconds]| loss: 0.27617, accuaracy: 99.98% | val_loss: 2.97456, val_accuaracy: 99.04% [159/200, 9 seconds]| loss: 0.27438, accuaracy: 99.98% | val_loss: 3.24354, val_accuaracy: 99.03% [160/200, 9 seconds]| loss: 0.27527, accuaracy: 99.99% | val_loss: 2.94451, val_accuaracy: 99.06% [161/200, 9 seconds]| loss: 0.27702, accuaracy: 99.98% | val_loss: 2.98104, val_accuaracy: 99.07% Epoch 162: reducing learning rate of group 0 to 2.5000e-04. [162/200, 9 seconds]| loss: 0.27402, accuaracy: 99.99% | val_loss: 2.98107, val_accuaracy: 99.03% [163/200, 9 seconds]| loss: 0.25684, accuaracy: 99.99% | val_loss: 2.99173, val_accuaracy: 99.03% [164/200, 9 seconds]| loss: 0.25519, accuaracy: 99.99% | val_loss: 2.97158, val_accuaracy: 99.05% [165/200, 9 seconds]| loss: 0.25442, accuaracy: 99.99% | val_loss: 3.02820, val_accuaracy: 99.03% [166/200, 9 seconds]| loss: 0.25639, accuaracy: 99.99% | val_loss: 3.00219, val_accuaracy: 99.02% [167/200, 14 seconds]| loss: 0.25652, accuaracy: 99.99% | val_loss: 2.99334, val_accuaracy: 99.04% [168/200, 20 seconds]| loss: 0.25747, accuaracy: 99.99% | val_loss: 2.99055, val_accuaracy: 99.03% [169/200, 20 seconds]| loss: 0.25656