[Pytorch系列-61]:生成对抗网络GAN - 基本原理 - 自动生成手写数字案例分析
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Pytorch系列-61]:生成对抗网络GAN - 基本原理 - 自动生成手写数字案例分析相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121914862
目录
3.3 定义dataloader,并通过dataloader读取数据
第1章 基本原理
 https://blog.csdn.net/HiWangWenBing/article/details/121878299
https://blog.csdn.net/HiWangWenBing/article/details/121878299第2章 准备条件
import os
import numpy as np
import math
import random
import matplotlib.pyplot as plt # 画图库
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
import torchvision.utils as utils
import torch.utils.data as data_utils #对数据集进行分批加载的工具集
cuda = True if torch.cuda.is_available() else False
print(cuda)True
第3章 数据集
3.1 自动下载minist数据集
# Configure data loader
os.makedirs("./data/mnist", exist_ok=True)
img_size = 28
batch_size = 64
# 数据转换
tensor_transform = transforms.Compose([transforms.Resize(img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
print(tensor_transform)
# 自动下载minist数据集
train_data = datasets.MNIST("./data/mnist",
train=True,
download=True,
transform = tensor_transform)
print(train_data)
Compose(
Resize(size=28, interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.5], std=[0.5])
)
Dataset MNIST
Number of datapoints: 60000
Root location: ./data/mnist
Split: Train
StandardTransform
Transform: Compose(
Resize(size=28, interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.5], std=[0.5])
3.2 显示数据集信息
#原图不叠加噪声
#获取一张图片数据
print("原始图片")
image, label = train_data[0]
print("torch image shape:", image.shape)
print("torch image label:", label)
print("\\n单通道原始图片:numpy")
image = image.numpy().transpose(1,2,0)
print("numpy image shape:", image.shape)
print("numpy image label:", label)
print("\\n不叠加噪声, 原图显示")
plt.imshow(image)
plt.show()原始图片 torch image shape: torch.Size([1, 28, 28]) torch image label: 5 单通道原始图片:numpy numpy image shape: (28, 28, 1) numpy image label: 5 不叠加噪声, 原图显示
3.3 定义dataloader,并通过dataloader读取数据
# 为数据集启动data loader
dataloader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)
print(dataloader)
#显示一个batch图片
print("获取一个batch组图片")
imgs, labels = next(iter(dataloader))
print(imgs.shape)
print(labels.shape)
print(labels.size()[0])
print("\\n合并成一张三通道灰度图片")
images = utils.make_grid(imgs)
print(images.shape)
print(labels.shape)
print("\\n转换成imshow格式")
images = images.numpy().transpose(1,2,0)
print(images.shape)
print(labels.shape)
print("\\n显示样本标签")
#打印图片标签
for i in range(64):
print(labels[i], end=" ")
i += 1
#换行
if i%8 == 0:
print(end='\\n')
print("\\n显示图片")
plt.imshow(images)
plt.show()获取一个batch组图片 torch.Size([64, 1, 28, 28]) torch.Size([64]) 64 合并成一张三通道灰度图片 torch.Size([3, 242, 242]) torch.Size([64]) 转换成imshow格式 (242, 242, 3) torch.Size([64]) 显示样本标签 tensor(2) tensor(4) tensor(2) tensor(3) tensor(6) tensor(4) tensor(6) tensor(9) tensor(2) tensor(5) tensor(7) tensor(6) tensor(0) tensor(5) tensor(6) tensor(9) tensor(6) tensor(3) tensor(8) tensor(3) tensor(7) tensor(0) tensor(3) tensor(3) tensor(0) tensor(6) tensor(6) tensor(3) tensor(1) tensor(4) tensor(5) tensor(1) tensor(1) tensor(7) tensor(5) tensor(9) tensor(0) tensor(6) tensor(2) tensor(4) tensor(4) tensor(0) tensor(7) tensor(7) tensor(5) tensor(3) tensor(2) tensor(4) tensor(9) tensor(9) tensor(4) tensor(4) tensor(3) tensor(1) tensor(9) tensor(8) tensor(4) tensor(4) tensor(2) tensor(7) tensor(9) tensor(6) tensor(3) tensor(2) 显示图片

3.4 自定义数据集标签
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
print(imgs.size())
print(imgs.size(0))
# 原始的参考样本的标签为1
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
#生成图片的标签为0
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
print(valid.shape)
print(fake.shape)
#print(imgs.type(Tensor))
real_imgs = Variable(imgs.type(Tensor))
print(real_imgs.shape)torch.Size([64, 1, 28, 28]) 64 torch.Size([64, 1]) torch.Size([64, 1]) torch.Size([64, 1, 28, 28])
第4章 定义网络
4.1 定义网络参数
latent_dim = 100
channels = 1
img_shape = (channels, img_size, img_size)4.2 定义生成网络
(1)定义网络结构
# 定义生成图片的模型
# 输入:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
* block(latent_dim, 128, normalize=False),
* block(128, 256),
* block(256, 512),
* block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), * img_shape)
return img
(2)实例化网络
# 实例化生成网络的模型
# Initialize generator and discriminator
generator = Generator()
# 生成网络的输入输出
# 输入:长度为100的一维向量,在整个训练过程中,
# 输入图片虽然是随机产生的,但在训练过程中是不一直不变的。
#
# 输出:1 * 28 * 28 的图片
print(generator)Generator(
(model): Sequential(
(0): Linear(in_features=100, out_features=128, bias=True)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Linear(in_features=128, out_features=256, bias=True)
(3): BatchNorm1d(256, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Linear(in_features=256, out_features=512, bias=True)
(6): BatchNorm1d(512, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Linear(in_features=512, out_features=1024, bias=True)
(9): BatchNorm1d(1024, eps=0.8, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Linear(in_features=1024, out_features=784, bias=True)
(12): Tanh()
)
)
(3)测试网络
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
# 获取当前GPU或CPU的device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 定义随机样本,作为生成网络的输入
# 也可以采用其他样本,作为生成网络的输入
input = Variable(Tensor(np.random.normal(0, 1, (batch_size, latent_dim))))
# 部署到GPU上预测
input = input.to(device)
print(input.shape)
print(input)
# 生成一个批图片
# W,B的参数不同,生成的图片不同
# 在训练的过程中,不断的调整W,B的参数,输出的图片就不断的变换
# 在训练过程中,输入图片是不变的(其值是由随机产生的随机数,也可以是有一定意义的图片)
generator.to(device)
output = generator(input)
print(output.shape)torch.Size([64, 100])
tensor([[ 1.6243, -0.6118, -0.5282, ..., 0.0436, -0.6200, 0.6980],
[-0.4471, 1.2245, 0.4035, ..., 0.4203, 0.8110, 1.0444],
[-0.4009, 0.8240, -0.5623, ..., 0.7848, -0.9554, 0.5859],
...,
[ 0.3523, 0.0450, 1.8180, ..., 0.2559, -0.6614, -0.4892],
[-1.0460, 0.5973, 0.6259, ..., 0.4243, 0.3902, 2.0044],
[ 0.7353, -0.2814, -1.4044, ..., 2.3529, 1.0682, -1.8938]],
device='cuda:0')
torch.Size([64, 1, 28, 28])
4.3 定义判决网络
(1)定义网络结构
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity(2)实例化网络
# 实例化判决判决神经网络
# 输入:728 = 1 * 28 * 28
# 输出:1 =》 1分类, 1表示图片为真,0表示图片为假
discriminator = Discriminator()
discriminator.to(device)
print(discriminator)Discriminator(
(model): Sequential(
(0): Linear(in_features=784, out_features=512, bias=True)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Linear(in_features=512, out_features=256, bias=True)
(3): LeakyReLU(negative_slope=0.2, inplace=True)
(4): Linear(in_features=256, out_features=1, bias=True)
(5): Sigmoid()
)
)
(3)测试网络
# 使用判决网络对生成图片进行预测
y = discriminator(output)
print(y.shape)
print(y[0])
# 使用判决网络对训练图片进行预测
imgs = imgs.to(device)
y = discriminator(imgs)
print(y.shape)
print(y[0])
# 训练目标
# 使得判决网络对训练图片和生成图片的loss和最小
# 也就是说,判决网络对训练图片,预测为真,同时对生成图片的预测也是为真torch.Size([64, 1]) tensor([0.5107], device='cuda:0', grad_fn=<SelectBackward0>) torch.Size([64, 1]) tensor([0.5150], device='cuda:0', grad_fn=<SelectBackward0>)
第5章 模型训练
5.1 定义训练参数
# 定义存放自动生成图片的路径
os.makedirs("images", exist_ok=True)
# 定义模型训练的超参数
n_epochs = 100
lr = 0.0002
b1 = 0.5
b2 = 0.999
n_cpu = 8
# 定义存放生成文件的间隔 (样本数间隔,而不是时间间隔)
sample_interval = 500
# 定义列表,存放训练过程中的loss
loss_g = []
loss_d = []5.2 定义loss
# 把网络和loss部署在GPU上
# Loss function
adversarial_loss = torch.nn.BCELoss()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(b1, b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(b1, b2))5.3 训练网络
# ----------
# Training
# ----------
for epoch in range(n_epochs):
# 读取一个batch的数据
for i, (imgs, _) in enumerate(dataloader):
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
# Adversarial ground truths
# 获取当前dataloader imgs的batch size
tmp_batch_size = imgs.size(0)
# 构建训练所需要的标签
# 真实图片的标签全部为1
valid = Variable(Tensor(tmp_batch_size, 1).fill_(1.0), requires_grad=False)
# 生成图片的标签全部为0
fake = Variable(Tensor(tmp_batch_size, 1).fill_(0.0), requires_grad=False)
# -----------------
# Train Generator 生成网络
# -----------------
# 复位G网络的梯度值
optimizer_G.zero_grad()
# Sample noise as generator input
# 生成与真实图片相同batch的输入向量
# 这里的输入是latent_dim=100长度的一维向量,向量的值为随机值
# 随机值在每次迭代时会发生变化吗?
input = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], latent_dim))))
# Generate a batch of images
# 用相同的生成网络,针对不同的批样本输入,生成一批不同的图片
gen_imgs = generator(input)
# 对生成的图片进行预测
y_gen = discriminator(gen_imgs)
# Loss measures generator's ability to fool the discriminator
# 目标是:使得当前G网络生成的图片,骗过当前的判决网络D, 判决为真实图片
# 每次迭代:G网络进化一点点,即使得g_loss降低一点点。
# 由于每次迭代, D网络也在进化,导致g_loss再提升一点点
# g_loss反应的是:使用当前的D网络,判断G网络生成的图片,是不是真实图片中的一个
# g_loss越小,生成的图片越接近真实的图片中的一个
g_loss = adversarial_loss(y_gen, valid)
# 求G网络的梯度
g_loss.backward()
# 反向迭代生成网络G, 只迭代G网络的W,B参数
optimizer_G.step()
loss_g.append(g_loss.item())
# ---------------------
# Train Discriminator 判决网络
# ---------------------
# 判决网络通过提高鉴别能力,朝着尽可能能够区分真实图片和生成图片的方向迭代、进化
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
# 用真实图片进行预测
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# 判决对生成图片进行判决: 尽可能识别生成图片与真实图片的差别
# 优化判决网络,尽可能使得判决网络把真实图片判定为1, 因此使用了标签1
y_real = discriminator(real_imgs)
real_loss = adversarial_loss(y_real, valid)
# 优化判决网络,尽可能使得判决网络把生成图片判定为0,因此使用了标签0
y_fake = discriminator(gen_imgs.detach())
fake_loss = adversarial_loss(y_fake, fake)
# 对loss进行叠加:真实图片的判决值与1的距离 + 生成图片的判决值与0的距离
d_loss = (real_loss + fake_loss) / 2
# 判决网络D的反向求导
d_loss.backward()
# 反向迭代判决网络D
optimizer_D.step()
loss_d.append(d_loss.item())
# 每隔sample_interval=400个生成样本,存储一个到文件中
batches_done = epoch * len(dataloader) + i
if batches_done % sample_interval == 0:
#save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)
#存储一个batch中的所有生成图片,每行8张图片
save_image(gen_imgs.data[:], "images/%d.png" % batches_done, nrow=8, normalize=True)
print( "[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, n_epochs, i, len(dataloader), d_loss.item(), g_loss.item()))
print(input.shape)
print(input)
print("DONE")[Epoch 0/100] [Batch 0/938] [D loss: 0.549743] [G loss: 0.854249] [Epoch 0/100] [Batch 500/938] [D loss: 0.499816] [G loss: 1.630219] [Epoch 1/100] [Batch 62/938] [D loss: 0.494236] [G loss: 0.888763] [Epoch 1/100] [Batch 562/938] [D loss: 0.499833] [G loss: 0.994551] [Epoch 2/100] [Batch 124/938] [D loss: 0.555602] [G loss: 1.024219]
第6章 模型预测与评估
6.1 显示g网络loss
# 显示迭代过程中loss的变换过程
plt.grid()
plt.xlabel("loss_g")
plt.ylabel("")
plt.title("loss_g", fontsize = 12)
plt.plot(loss_g, "r")
plt.show()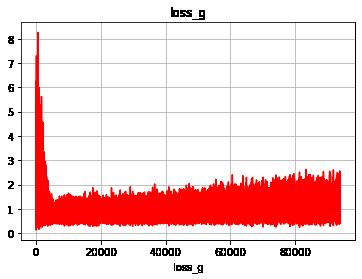
6.2 显示D网络loss
# 显示迭代过程中loss的变换过程
plt.grid()
plt.xlabel("loss_d")
plt.ylabel("")
plt.title("loss_d", fontsize = 12)
plt.plot(loss_d, "r")
plt.show()
6.3 自动生成图片测试
# 生成图片
seed = 1
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
# 获取当前GPU或CPU的device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 定义随机样本,作为生成网络的输入
# 也可以采用其他样本,作为生成网络的输入
input = Variable(Tensor(np.random.normal(0, 1, (batch_size, latent_dim))))
# 部署到GPU上预测
input = input.to(device)
print(input.shape)
print(input)
# 生成一个批图片
# W,B的参数不同,生成的图片不同
# 在训练的过程中,不断的调整W,B的参数,输出的图片就不断的变换
# 在训练过程中,输入图片是不变的(其值是由随机产生的随机数,也可以是有一定意义的图片)
generator.to(device)
imgs = generator(input)
print(imgs.shape)
print("\\n合并成一张三通道灰度图片")
images = utils.make_grid(imgs)
print(images.shape)
print("\\n转换成imshow格式")
images = images.to("cpu")
images = images.numpy().transpose(1,2,0)
print(images.shape)
print("\\n显示图片")
plt.imshow(images)
plt.show()torch.Size([64, 100])
tensor([[ 1.6243, -0.6118, -0.5282, ..., 0.0436, -0.6200, 0.6980],
[-0.4471, 1.2245, 0.4035, ..., 0.4203, 0.8110, 1.0444],
[-0.4009, 0.8240, -0.5623, ..., 0.7848, -0.9554, 0.5859],
...,
[ 0.3523, 0.0450, 1.8180, ..., 0.2559, -0.6614, -0.4892],
[-1.0460, 0.5973, 0.6259, ..., 0.4243, 0.3902, 2.0044],
[ 0.7353, -0.2814, -1.4044, ..., 2.3529, 1.0682, -1.8938]],
device='cuda:0')
torch.Size([64, 1, 28, 28])
合并成一张三通道灰度图片
torch.Size([3, 242, 242])
转换成imshow格式
(242, 242, 3)
显示图片

作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121914862
以上是关于[Pytorch系列-61]:生成对抗网络GAN - 基本原理 - 自动生成手写数字案例分析的主要内容,如果未能解决你的问题,请参考以下文章