属性分解 GAN 复现 实现可控人物图像合成
Posted 叶庭云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了属性分解 GAN 复现 实现可控人物图像合成相关的知识,希望对你有一定的参考价值。
文章目录
一、引言
论文介绍:Controllable Person Image Synthesis with Attribute-Decomposed GAN
论文地址:https://arxiv.org/abs/2003.12267
代码Github:https://github.com/menyifang/adgan
属性分解生成对抗式网络(Attribute-Decomposed GAN) 是一种新颖的用于可控人物图像合成的模型,该模型可以生成具有预期人类属性(例如姿势、头部、上衣和裤子)的逼真人物图像,这些属性在各种源输入中提供。模型的核心思路是将人类属性作为独立代码嵌入到潜在空间中,从而通过在显式样式表示中进行组合和插值操作来实现对灵活而连续的人物图像合成的控制。具体而言,研究者提出一种新颖的体系架构,该架构由具有样式块连接的两个编码路径组成,以将原始硬映射(直接学习从源图像 + 姿势到目标图像的映射)分解为多个更易于访问的子任务。在源路径中,进一步利用现有的人类解析器提取组件布局,并将它们注入到全局共享的纹理编码器中,以分解潜在代码。这种策略能够合成更逼真的输出图像,并实现自动分离未注释的属性。实验结果表明该方法在姿态转移方面优于现有的技术,且在组件属性转移这一全新任务中具有很高的有效性。
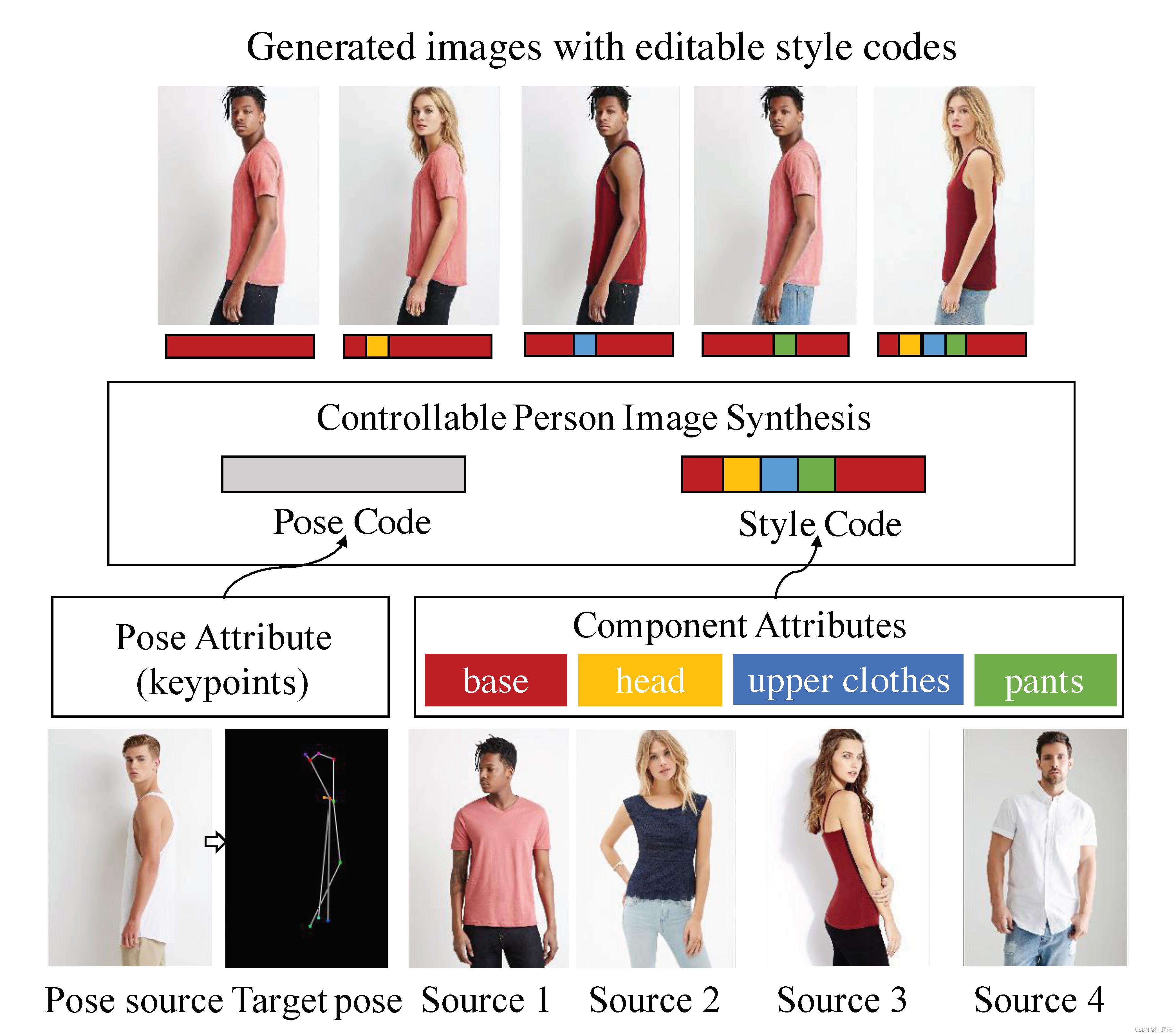
属性灵活可控的人物图像合成(PIS)是计算机图形学与计算机视觉领域里一个非常具有挑战性的任务,在图像编辑、人物重新识别、虚拟试衣等方面都具有巨大的应用价值。
二、本文主要内容
复现属性分解 GAN 的实验,并总结学习过程。
论文代码的 Github 地址:https://github.com/menyifang/adgan
1. 环境配置说明
Anaconda + Python3.8 + CUDA 11.1 新建一个自己的虚拟环境
将整个项目拉取到本地,然后获取包含大量各种外观和姿势的人物图像数据集 In-shop Clothes Retrieval Benchmark:
- http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion/InShopRetrieval.html
安装有关依赖库:
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
pip install scikit-image==0.16.2
pip install visdom
pip install numpy
pip install scipy
pip install pillow
pip install pandas
pip install tqdm
pip install dominate
ImportError: cannot import nane ‘circle’ fron 'skinage.draw’报错,直接安装 scikit-image 版本将为 0.19.1,降低版本为 0.16.2 即可解决!所以安装指定版本 scikit-image==0.16.2。并且注意这个项目是需要两块 GPU:
- Github Issues:https://github.com/menyifang/ADGAN/issues/6
Github Issues 上有人反馈,作者回答了,目前是需要两块 GPU (并行训练)才能得到合理的结果(我用的是两块 GeForce RTX 3080 GPU、Ubuntu 18.04 操作系统),没有单 GPU 版本,单 GPU 不能得到合理结果,会得到合成的像素团。

2. 数据预处理
根据提供的 train.lst 和 test.lst 里的图片名称信息,利用 Python 多线程脚本 tool/train_test_split.py 对应将原始图像数据集随机划分为训练集(48674 张图像)和测试集(4038 张图像),并以中心裁剪的方式将图像裁剪为 176x256 的分辨率,然后分别保存到 train 和 test 文件夹。Github下载的项目里,tool/generate_fashion_datasets.py 是从 train.lst 和 test.lst 对应提取图像来划分训练集和测试集,因为下载的 In-shop Clothes Retrieval Benchmark 图像数据是分层级对应保存的,如下所示:
然后 tool/resize_fashion.py 才进行图像裁剪。所以完全可以重写个脚本,并用多线程,直接一键快速从 train.lst 和 test.lst 的信息对应提取图像来划分训练集和测试集,并同时裁剪后,保存到 train 和 test 文件夹。代码如下:
from pathlib import Path
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
from skimage.io import imread, imsave
from skimage.transform import resize
import os
import numpy as np
import pandas as pd
import json
from PIL import Image
from datetime import datetime
def save_imgs1(name):
if name in path_name.keys():
# print(path_name[name]) 图片名 对应的路径
img_path = r"".format(path_name[name])
# 中心裁剪的方式 176*256的分辨率 然后分别保存到train和test文件夹
new_size = (256, 176)
crop_bord = 40
img = Image.open(img_path)
w, h =img.size
if crop_bord == 0:
pass
else:
img = img.crop((crop_bord, 0, w - crop_bord, h))
img = img.resize([new_size[1], new_size[0]])
img.save(f"./test/name")
def save_imgs2(name):
if name in path_name.keys():
# print(path_name[name]) 图片名 对应的路径
img_path = r"".format(path_name[name])
# 中心裁剪的方式 176*256的分辨率 然后分别保存到train和test文件夹
new_size = (256, 176)
crop_bord = 40
img = Image.open(img_path)
w, h =img.size
if crop_bord == 0:
pass
else:
img = img.crop((crop_bord, 0, w - crop_bord, h))
img = img.resize([new_size[1], new_size[0]])
img.save(f"./train/name")
with open("train.lst", "r") as f:
train_imgs = f.read().split("\\n")
with open("test.lst", "r") as f:
test_imgs = f.read().split("\\n")
# 下载的DeepFashion数据原始图片数据集
path = r'D:\\project\\img'
p = Path(path)
file_name = list(p.glob('**/*.jpg'))
file_name = [str(i) for i in file_name]
path_name =
for path in tqdm(file_name):
try:
path = r"".format(path)
name = "".join(path.split("\\\\")[-4:])
name1 = name[:name.index("id")]
name2 = name[name.index("id"):].split("_")
name2 = name2[0] + name2[1] + "_" + name2[2] + name2[3]
final_name = "fashion" + name1 + name2
path_name[final_name] = path
except:
continue
start = datetime.now()
with ThreadPoolExecutor(max_workers=4) as executor:
future_tasks = [executor.submit(save_imgs1, i) for i in test_imgs]
wait(future_tasks, return_when=ALL_COMPLETED)
with ThreadPoolExecutor(max_workers=4) as executor:
future_tasks = [executor.submit(save_imgs2, i) for i in train_imgs]
wait(future_tasks, return_when=ALL_COMPLETED)
delta = (datetime.now() - start).total_seconds()
print(f'用时:deltas')
提取位姿关键点用的是 OpenPose,已经给了标注了人体关键点的 csv。
可以利用 tool/generate_pose_map_fashion.py,直接提取训练集和测试集的位姿关键点,分别保存到 trainK 和 testK 文件夹。主要操作是需要修改一下代码里的路径,然后分别运行两次:
# 训练集提取位姿关键点的路径
img_dir = r'你的路径/ADGAN/deepfashion/fashion_resize'
annotations_file = "你的路径/ADGAN/deepfashion/fasion-resize-annotation-train.csv" # pose annotation path
save_path = os.path.join(img_dir, 'trainK')
# 测试集提取位姿关键点的路径
img_dir = r'你的路径/ADGAN/deepfashion/fashion_resize'
annotations_file = "你的路径/ADGAN/deepfashion/fasion-resize-annotation-test.csv" # pose annotation path
save_path = os.path.join(img_dir, 'testK')
利用现有的人体解析器 LIP_SSL 可以实现自动分离人体组件属性,并将其合并为 8 个类别。分割结果保存在 semantic_merge3 文件夹。最终文件目录如下所示:
3. 模型训练和合成结果
更改一下 scripts/train.sh 里的一些配置为你的环境里的路径,以及调整设置参数,如下所示:
python train.py
--dataroot 你的路径/ADGAN/deepfashion/fashion_resize
--dirSem 你的路径/ADGAN/deepfashion
--pairLst 你的路径/ADGAN/deepfashion/fashion-resize-pairs-train.csv
--name fashion_adgan_test
--model adgan
--lambda_GAN 5
--lambda_A 1
--lambda_B 1
--dataset_mode keypoint
--n_layers 3
--norm instance
--batchSize 6
--pool_size 0
--resize_or_crop no
--gpu_ids 0,1
--BP_input_nc 18
--SP_input_nc 8
--no_flip
--which_model_netG ADGen
--niter 500
--niter_decay 500
--checkpoints_dir ./checkpoints
--L1_type l1_plus_perL1
--n_layers_D 3
--with_D_PP 1
--with_D_PB 1
--display_id 0
--which_epoch 800
切换到 ADGAN 目录,用以下命令训练模型:
bash ./scripts/train.sh
一些合成结果:


调参和更改配置,修改 .sh 文件里对应参数的配置即可。从实践来看,Pose Extraction 和 Segmentation Map 的提取对模型的性能有明显影响。测试操作跟之前类似:
# 计算评测指标
python tool/getMetrics_market.py
python ssd/compute_ssd_score_fashion.py --input_dir path/to/generated/images
属性分解 GAN 这个项目还是挺有意思,但感觉属性分解 GAN 的整个网络太大了,训练这个网络需要消耗巨大的计算资源和内存。因此,可能需要找到一些解决方案来降低这个网络的训练成本,无论是使用新颖的网络架构,还是使用特殊的数据预处理方法。emmm 跑一个 epoch 大概在 8 分钟左右(两块 GeForce RTX 3080 GPU),复现它的 1000 个 epoches 的结果大约需要 5.6 天,成本挺高的。
三、总结
- 属性分解 GAN 将目标姿势 P t P_t Pt 与源人物图像 I s I_s Is 通过两个分别叫做姿势编码和独立部位编码的路径嵌入到潜在空间中。这两条路径通过一系列的样式块连接,有效地将源人物图像的纹理信息注入到姿势特征中去。对于独立部位编码,我们利用现有的人体部位解析器 LIP_SSL 提取分割图,该方法有 20 20 20 个标签,利用它合并得到 8 8 8 个标签(即背景、脸、上衣、裤子、头发、手臂、裙子和腿),并利用现有的姿势估计方法 OpenPose 自动从源图像中提取位姿关键点生成 18 18 18 个关节位置的引向图。利用全局纹理编码器(共享的)对其进行编码,并通过控制 AdaIN 层中的仿射变换参数,引入一系列带有 Fusion 融合模块的样式块,将源人物的纹理样式注入到姿势编码中。最后,再通过解码器重构人体图像,获得拥有 I s I_s Is 的外观但是遵循 P t P_t Pt 的姿势的合成图像 I g I_g Ig ,并且判别器会对合成图像的真实性进行判别。
- 属性分解 GAN 的方法应用于人图像合成中,合成高质量的人物图像,可以控制像姿势、头发、上衣和裤子这些属性,并能处理大姿势变换。
- 论文的作者团队今年又进一步提出了 ADGAN++,所提出的 ADGAN 和 ADGAN++ 的核心思想都是将组件属性作为独立的代码嵌入到潜在空间中,从而通过显式样式表示中的混合和插值操作实现对属性的灵活和连续控制。 它们之间的主要区别在于 ADGAN 同时处理所有组件属性,而 ADGAN++ 使用串行编码策略。 更具体地说,ADGAN 由两个具有样式块连接的编码路径组成,并且能够将原始硬映射分解为多个更易于访问的子任务。 在源路径中,通过语义解析器提取组件布局,并将分割的组件馈送到共享的全局纹理编码器中,以获得分解的潜在代码。 该策略允许合成更真实的输出图像并自动分离未注释的组件属性。 虽然原始的 ADGAN 以一种微妙而高效的方式工作,但当属性类别的数量巨大时(如真实世界图像),它本质上无法处理语义图像合成任务。为了解决这个问题,ADGAN++ 采用不同分量属性的串行编码来合成目标真实世界图像的各个部分,并采用多个带有分割引导实例归一化的残差块来组装合成的分量图像并细化原始合成结果。两阶段的 ADGAN++ 旨在减轻合成具有众多属性的真实世界图像时所需的大量计算成本,同时保持不同属性的解耦,以实现对合成图像的任意组件属性的灵活控制。实验结果证明了所提出的方法在姿势迁移、人脸风格迁移和语义图像合成方面优于现有技术,以及它们在组件属性迁移任务中的有效性。ADGAN++ 看起来更有意思!论文地址:https://ieeexplore.ieee.org/document/9741362
补充学习:
- Men Y, Mao Y, Jiang Y, et al. Controllable person image synthesis with attribute-decomposed gan[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 5084-5093.
- Pu G, Men Y, Mao Y, et al. Controllable Image Synthesis with Attribute-Decomposed GAN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2022 (01): 1-1.
以上是关于属性分解 GAN 复现 实现可控人物图像合成的主要内容,如果未能解决你的问题,请参考以下文章
GAN如此简单的PyTorch实现,一张脸生成72种表情(附代码)