玩转StyleGAN2模型:教你生成动漫人物
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转StyleGAN2模型:教你生成动漫人物相关的知识,希望对你有一定的参考价值。

正文字数:2840 阅读时长:6分钟
生成式对抗网络(GAN)是一种能够生成新内容的生成模型。由于其有趣的应用,如生成合成训练数据、创建艺术、风格转换、图像到图像的翻译等,这个话题在机器学习的领域中非常流行。
Posted by Fathy Rashad
url : https://www.yanxishe.com/TextTranslation/2826
生成式对抗网络
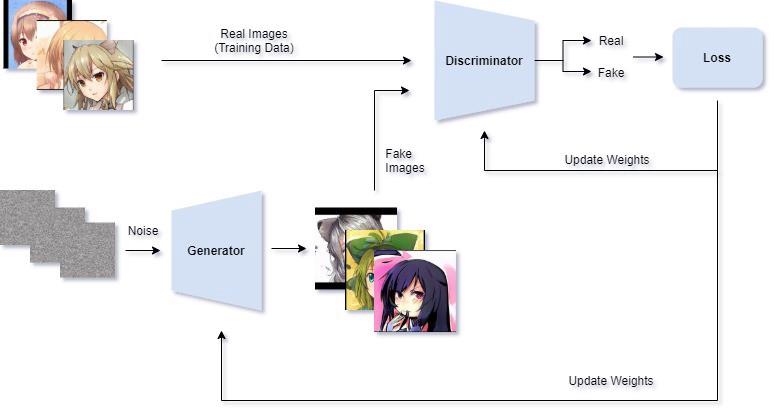
GAN架构 [Image by Author]
GAN由2个网络、即发生器/生成器和鉴别器组成。生成器将尝试生成假样本,并欺骗鉴别器相信它是真实样本。鉴别器将尝试从真样本和假样本中检测生成的样本。这个有趣的对抗概念是由伊恩·古德费罗(Ian Goodfellow)在2014年提出的。已经有很多资源可以用来学习GAN,因此我不解释GAN以避免冗余。
我建议阅读Joseph Rocca 的这篇文章来了解GAN。
理解生成式对抗网络(GANs)
https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Funderstanding-generative-adversarial-networks-gans-cd6e4651a29
风格GAN2
2018年,NVIDIA发布了StyleGAN论文“A Style-Based Architecture for GANs”。该文提出了一种新的GAN生成器结构,允许他们控制生成的样本的不同层次的细节水平,从粗略的细节(如头部形状)到更精细的细节(如眼睛颜色)。
StyleGAN还融合了Progressive GAN的思想,即网络最初在较低分辨率(4x4)上训练,然后在稳定后逐渐添加更大的层数。通过这样做,训练时间变得更快,训练也更加稳定。

渐进式增长GAN [Source: Sarah Wolf]
StyleGAN进一步改进了它,增加了一个映射网络,将输入向量编码成一个中间的潜伏空间,w,然后将有单独的值用来控制不同层次的细节。
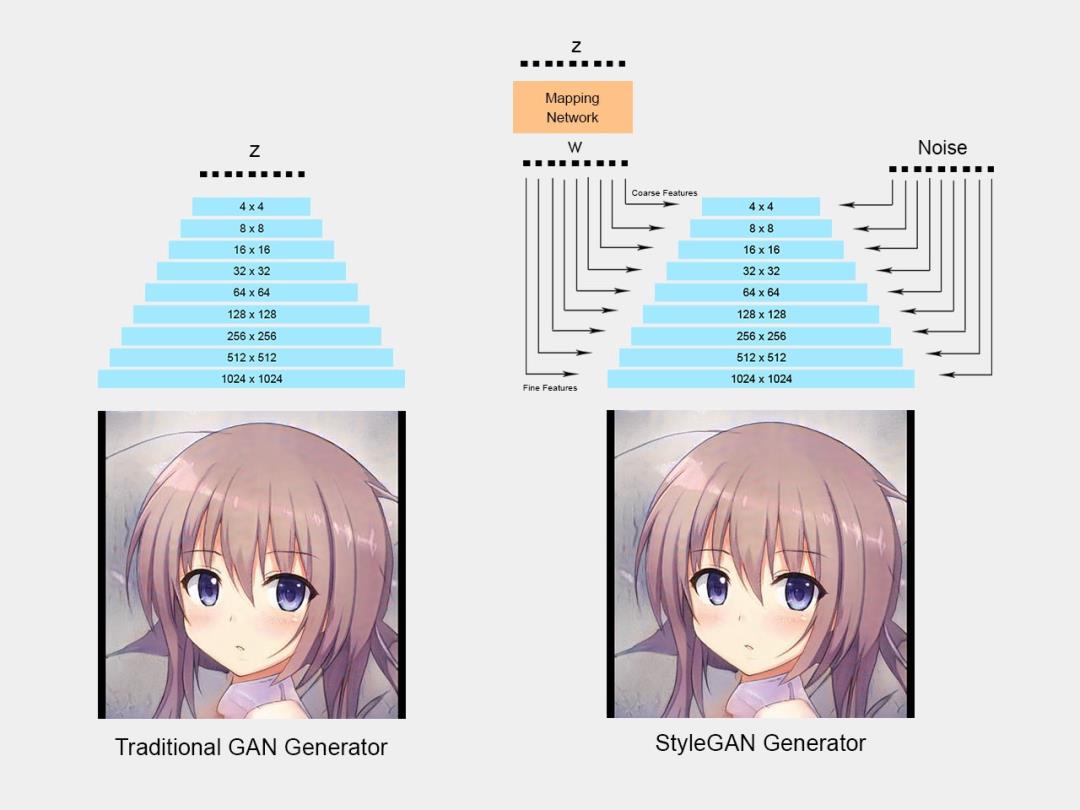
StyleGAN生成器架构 [Image by Author]
为什么要增加一个映射网络?
GAN的一个问题之一在于它的纠缠潜码表示(输入向量,z)。例如,假设我们有2个维度的潜伏码,它分别代表了脸的大小和眼睛的大小。在这种情况下,脸的大小与眼睛的大小高度纠缠在一起(眼睛越大,脸也越大)。另一方面,我们可以通过存储脸部和眼睛的比例来简化这一点问题,这将使我们的模型更简单,因为无纠缠的表示方式更容易被模型解释。
在纠缠表示下,数据分布可能不一定遵循正态分布,我们希望从中采样输入向量z。例如,数据分布会有这样一个缺失的角点,它表示眼睛和脸部的比例变得不现实的区域。
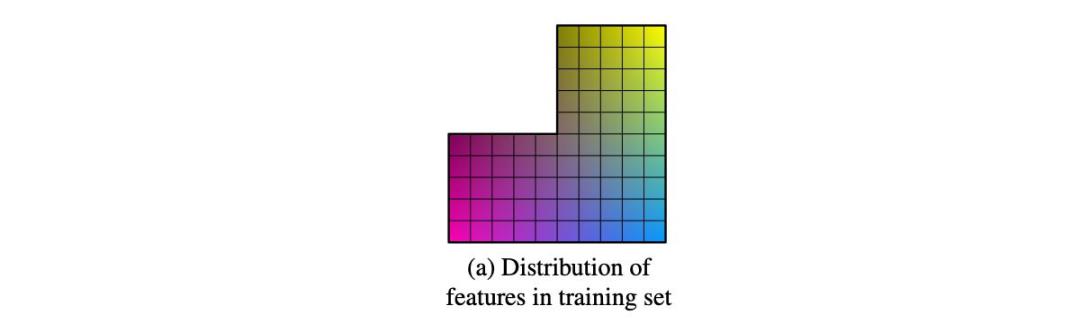
[Source: Paper]
如果我们从正态分布中采样z,我们的模型也会尝试生成缺失的区域,并且其中的比例是不现实的,因为没有具有这种特性的训练数据,生成器将生成较差的图像。因此,映射网络的目的是拆分潜伏表征,并扭曲潜伏空间,使其能够从正态分布中采样。
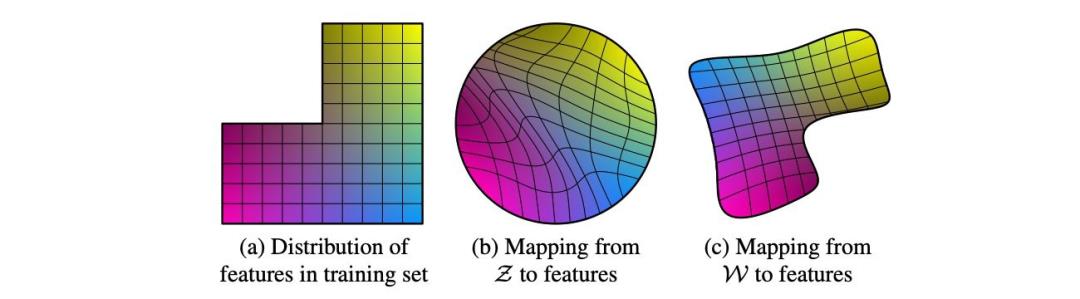
[Source: Paper]
另外,在每个层次上有单独的输入向量w,使得生成器可以控制不同层次的视觉特征。前几层(4x4、8x8)将控制更高级别(相对粗糙的)的细节,例如头部形状、姿势和发型。最后几层(512x512、1024x1024)将控制更精细的细节级别,例如头发和眼睛的颜色。
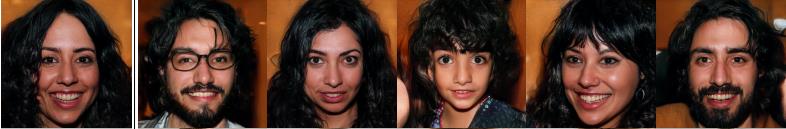
粗糙细节的变化(头部形状,发型,姿势,眼镜) [Source: Paper]

细微层次细节的变化(发色) [Source: Paper]
关于StyleGAN架构的完整细节,我建议您阅读NVIDIA关于其实现的官方论文。这是从论文本身对整个体系结构的说明和架构图。
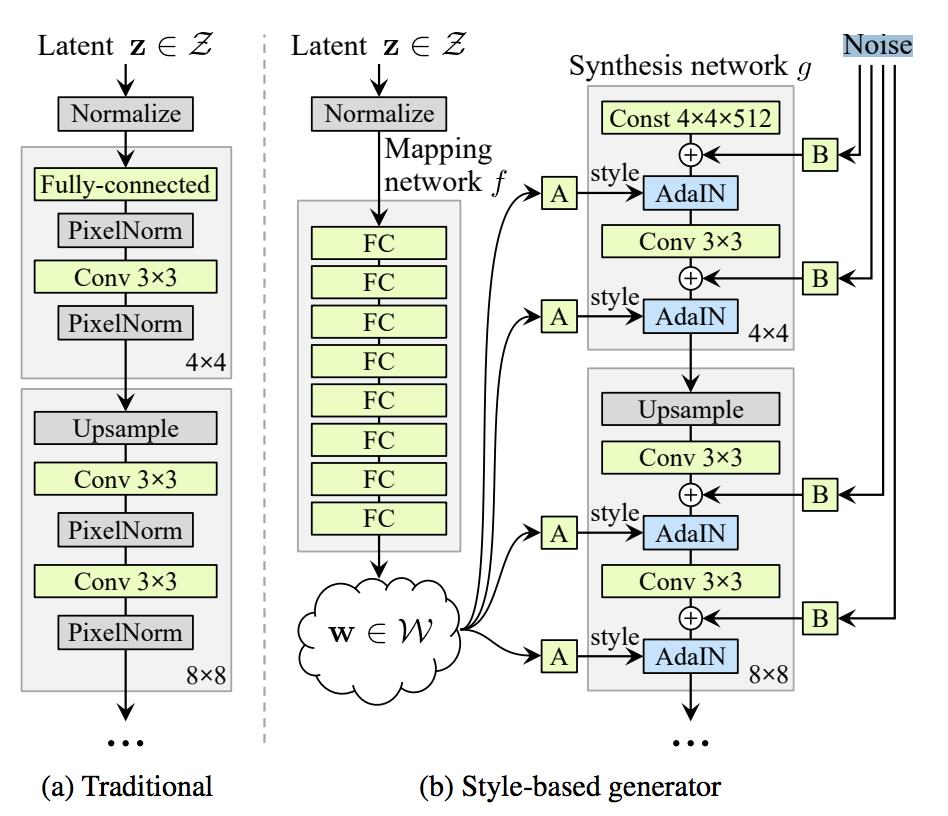
基于风格的全球行动网文件架构
随机变化
StyleGAN还允许您通过在各个图层上给予噪声来控制不同层次的细节的随机变化。随机变化是图像上微小的随机性,不会改变我们对图像的感知或图像的身份,例如不同的梳理的头发、不同的头发位置等。您可以在下面的动画图像中看到变化的效果。

粗糙的随机变化 [Source: Paper]
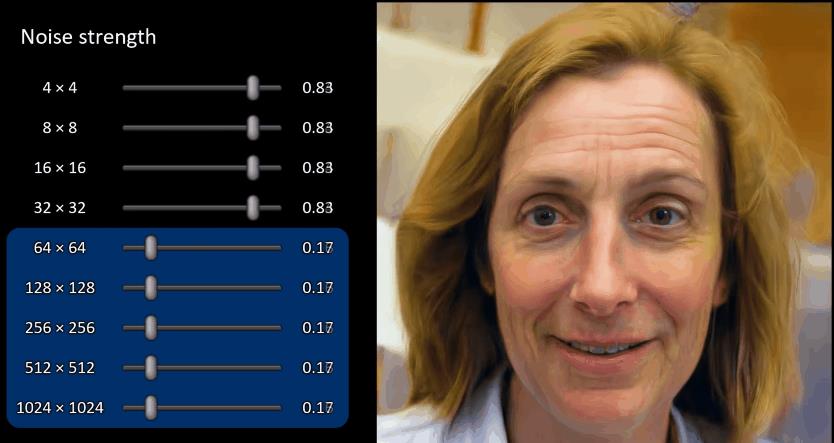
精细的随机变化[Source: Paper]
StyleGAN还做了一些其他改进,我在这些文章中就不一一介绍,比如AdaIN规范化和其他正则化/常规化。你可以阅读官方论文,Jonathan Hui的这篇文章,或者Rani Horev的这篇文章来代替阅读进一步的细节。
截断技巧
当训练样本中存在代表性不足的数据时,生成器可能无法学习样本,并产生较差的结果。为了避免这种情况,StyleGAN使用了一种“截断技巧”,截断中间的潜在向量w,使其接近平均值。
????(psi)是阈值,用来截断和重新采样高于阈值的潜向量。因此,如果使用更高的????,你可以在生成的图像上获得更高的多样性,但它也有更高的机会生成奇怪或破碎的面孔。对于这个网络来说,????的值在0.5到0.7之间,根据Gwern的说法,似乎可以得到一个具有足够多样性的好图像。虽然,可以随意试验一下阈值。



3x3 Grid Images generated with 0.3 psi (left) vs 0.7 psi (middle) vs 1.3 psi (right)
生成动漫人物
我将使用Aaron Gokaslan预先训练好的Anime StyleGAN2,以便我们可以加载模型直接生成动画脸。所以,打开你的Jupyter笔记本或googlecolab,让我们开始编码。
注意:如果你遇到困难,可以参考我的Colab笔记本
因此,首先,我们应该克隆styleGAN repo。
$ git clone https://github.com/NVlabs/stylegan2.git
如果您使用的是googlecolab,可以在命令前面加上“!'以命令的形式运行它:!!"git clone https://github.com/NVlabs/stylegan2.git
接下来,我们需要下载预先训练好的权重并加载模型。当您使用googlecolab时,请确保您是使用GPU运行时运行的,因为模型被配置为使用GPU。
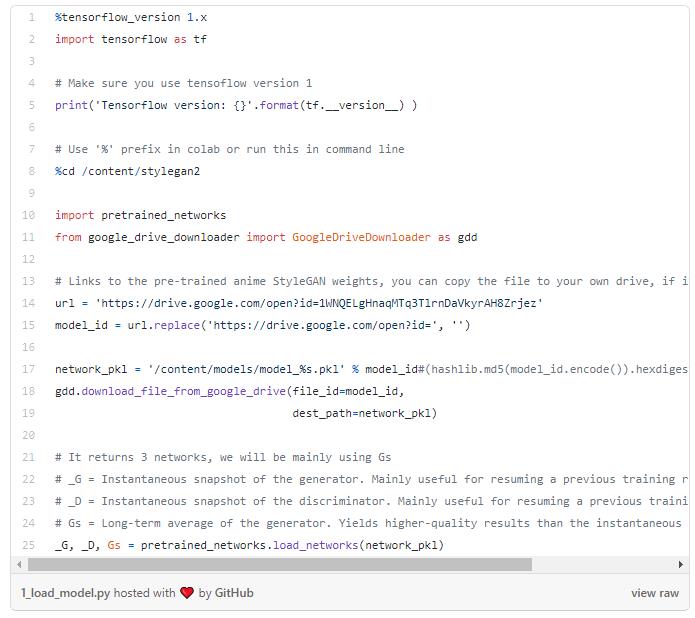
这段代码是从这个笔记本上修改而来的
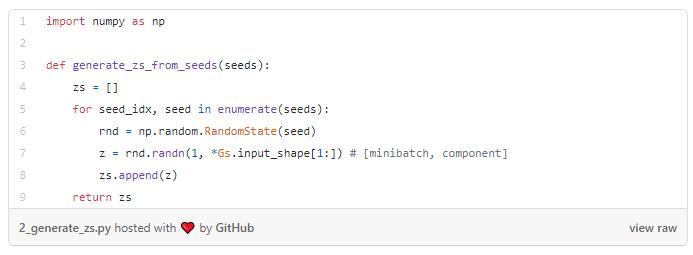
现在,我们需要生成随机向量z,作为我们的生成器的输入。让我们创建一个函数,从给定的种子生成潜在代码z。
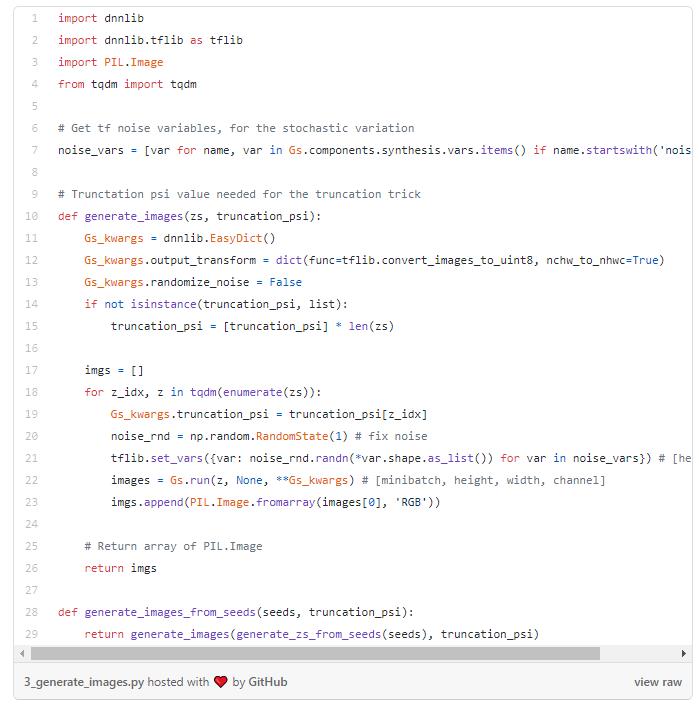
然后,我们可以创建一个函数,将它生成的随机向量z,生成图像。
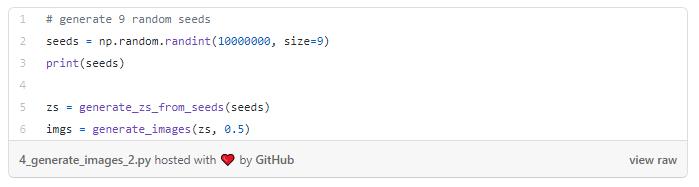
现在,我们可以尝试生成一些图像并查看结果。
该函数将返回一个PIL.Image的数组. 在googlecolab中,可以通过打印变量直接显示图像。这是第一个生成的图像。

Image by Author
让我们在一个图像网格中显示它,这样我们可以一次看到多个图像。
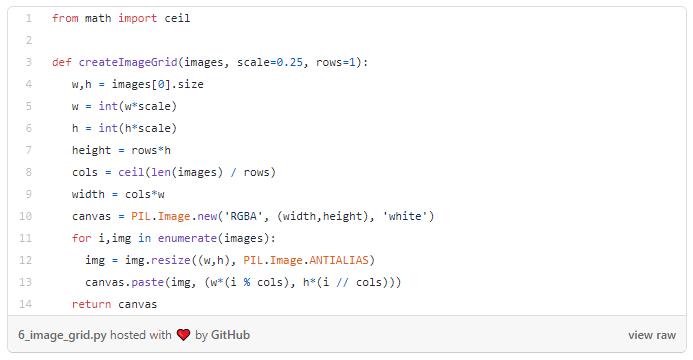
然后我们可以在一个3x3的网格中显示生成的图像。

Image by Author
GAN的一个优点是它具有平滑和连续的潜伏空间,而不像VAE(变分自动编码器Variational Auto Encoder)那样有间隙。因此,当您在潜伏空间中获取两个将生成两个不同面的点时,您可以通过在两个点之间采用线性路径来创建两个面的过渡或插值。
潜伏空间的插值 [Source: Joseph Rocca]
让我们在代码中实现这一点,并创建一个函数来在z向量的两个值之间进行插值。
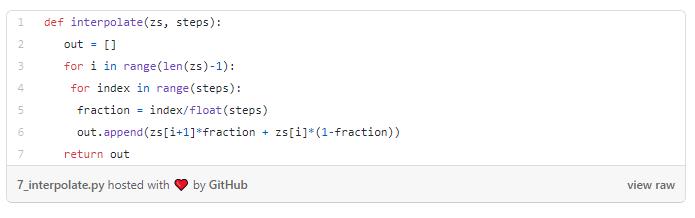
让我们看看插值结果。您可以看到第一个图像逐渐过渡到第二个图像。

Image by Author
现在我们已经完成了插值。最后我们可以尝试在上面的缩略图中制作插值动画。我们将使用moviepy库创建视频或GIF文件。


当您运行代码时,它将生成一个插值的GIF动画。您还可以使用顶部的变量修改持续时间、网格大小或fps。

生成的StyleGAN2插值GIF [Image by Author]
如果你成功了,恭喜你!你已经使用StyleGAN2生成了动画人脸面孔,并学习了GAN和StyleGAN架构的基础知识。
接下来我们应该做什么
既然我们已经完成了,你还能做些什么来进一步改进呢?这里有一些你可以做的事情。
其他数据集
显然,StyleGAN不仅仅局限于动画/动漫数据集,还有许多可以使用的预先训练得数据集,比如真实的脸、猫、艺术和绘画的图像。
查看此GitHub repo(https://github.com/justinpinkney/awesome-pretrained-stylegan2),了解可用的预训练权重。另一方面,您还可以使用自己选择的数据集训练StyleGAN。
有条件的GAN
目前,我们无法真正控制我们想要生成的特征,例如头发颜色、眼睛颜色、发型和配饰。条件GAN允许您在输入向量z旁边给出一个标签,从而将生成的图像调整为我们想要的样子。或者,您可以尝试通过回归或手动来理解潜伏空间。如果你想朝这个方向发展,斯诺·哈尔西Snow Halcy repo或许能帮到你,因为他已经做了,甚至在这个Jupyter笔记本上做了互动。
特别鸣谢
我要感谢gwenn Branwen就如何用StyleGAN生成动画人脸做了大量的文章和解释,我在文章中强烈提到了这一点。我完全建议你访问他的网站,因为他的著作是知识宝库。此外,看看访问waifudoesnotex(https://www.thiswaifudoesnotexist.net/)网站,它拥有StyleGAN模型来生成动画人脸和GPT模型来生成动画情节。

LiveVideoStackCon 2020 北京
2020年10月31日-11月1日
点击【阅读原文】了解更多详细信息
以上是关于玩转StyleGAN2模型:教你生成动漫人物的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch 深度学习实战 | 基于生成式对抗网络生成动漫人物
Midjourney|文心一格prompt教程[Text Prompt(下篇)]:游戏实物人物风景动漫邮票海报等生成,终极模板教学
StyleGAN及其改进型(StyleGAN2)——基于样式的生成对抗网络论文整理与总结