StyleGAN及其改进型(StyleGAN2)——基于样式的生成对抗网络论文整理与总结
Posted 康x呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了StyleGAN及其改进型(StyleGAN2)——基于样式的生成对抗网络论文整理与总结相关的知识,希望对你有一定的参考价值。
StyleGAN及其改进型(StyleGAN2)——基于样式的生成对抗网络论文整理与总结
论文: https://arxiv.org/pdf/1812.04948.pdf
代码: https://link.zhihu.com/?target=https%3A//github.com/NVlabs/stylegan
StyleGAN论文简介
论文研究背景及意义
NVIDIA在2017年提出的ProGAN解决了生成高分辨率图像(如1024×1024)的问题。ProGAN的关键创新之处在于渐进式训练——从训练分辨率非常低的图像(如4×4)的生成器和判别器开始,每次都增加一个更高的分辨率层。
存在的问题:与多数GAN一样,ProGAN控制生成图像的特定特征的能力非常有限。这些属性相互纠缠,即使略微调整输入,会同时影响生成图像的多个属性。所以如何将ProGAN改为条件生成模型,或者增强其微调单个属性的能力,是一个可以研究的方向。
解决方法:StyleGAN是NVIDIA继ProGAN之后提出的新的生成网络,其主要通过分别修改每一层级的输入,在不影响其他层级的情况下,来控制该层级所表示的视觉特征。这些特征可以是粗的特征(如姿势、脸型等),也可以是一些细节特征(如瞳色、发色等)。
论文的工作和贡献
①借鉴风格迁移,提出基于样式的生成器(style-based generator)。
实现了无监督地分离高级属性(人脸姿势、身份)和随机变化(例如雀斑,头发)实现对生成图像中特定尺度的属性的控制。
生成器从一个可学习的常量输入开始,隐码在每个卷积层调整图像的“样式”,从而直接控制不同尺度下图像特征的强度。
②实现了对隐空间(latent space)较好的解耦。
生成器将输入的隐码z嵌入一个中间的隐空间。因为输入的隐空间Z必须服从训练数据的概率密度,这在一定程度上导致了不可避免的纠缠,而嵌入的中间的隐空间W不受这个限制,因此可以被解耦。
③提出了两个新的量化隐空间解耦程度的方法
感知路径长度和线性可分性。与传统的生成器体系结构相比,新的生成器允许更线性、更解耦地表示不同的变化因素。
④提出了新的高质量的人脸数据集(FFHQ,7万张1024×1024的人脸图片)
论文的模型和方法
基于样式的生成器结构
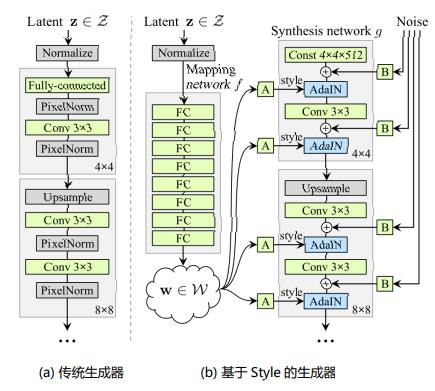
具体生成器结构的细节从以下四点分析:
移除传统输入
映射网络(Mapping Network)
样式模块(style module,AdaIN)
随机变化(Stohastic variation,加入噪声)
正则化-混合正则化(mixing regularization)
为了进一步鼓励styles的局部化(减小不同层之间样式的相关性),本文对生成器使用混合正则化。
方法:对给定比例的训练样本(随机选取)使用样式混合的方式生成图像。在训练过程中,使用两个随机隐码z(latent code)而不是一个,生成图像时,在合成网络中随机选择一个点(某层),从一个隐码切换到另一个隐码(称之为样式混合)。具体来说,通过映射网络运行两个潜码z1、z2,并让对应的w1、w2控制样式,使w1在交点前应用,w2在交点后应用。
这种正则化技术防止网络假设相邻样式是相关的,随机切换确保网络不会学习和依赖于级别之间的相关性。
两种新的量化隐空间(latent space)耦合度的方法
解耦的目标是使隐空间(latent space)由线性子空间组成,即每个子空间(每个维度)控制一个变异因子(特征)。
但是隐空间Z中的各个因子组合的采样概率需要与训练数据中响应的密度匹配,就会产生纠缠。而中间隐藏空间W不需要根据任何固定分布进行采样;它的采样密度是由可学习的映射网络f(z)得到的,使变化的因素变得更加线性。
本文假设,生成器基于解耦的表示比基于纠缠的表示应该更容易产生真实的图像(若在FID变小的同时,隐空间耦合度变小,则可以得证)。因此,我们期望训练在无监督的情况下(即,当不预先知道变异的因素时)产生较少纠缠的W
所以本文提出了两种新的量化解耦的方法,它们都不需要编码器,所以对于任何数据集和生成器都是可计算的。
感知路径长度(Perceptual path length)
线性可分性(linear separability)
论文生成的图像的质量
评估指标:FID(遛狗绳距离)(Fréchet Inception Distance,越小越好)
测量不同的生成器结构产生的图像的质量。FID计算真实样本,生成样本在特征空间之间的距离。预训练的 Inception V3 来提取全连接层之前的 2048 维向量,作为图片的特征,然后根据均值和协方差来进行距离计算。具体公式如下:

公式中: [公式] 真实图片的特征的均值, [公式] 生成的图片的特征的均值, [公式] 真实图片的特征的协方差矩阵, [公式] 生成图片的特征的协方差矩阵
FID 只把 Inception V3 作为特征提取器,并不依赖它判断图片的具体类别,因此不必担心 Inception V3 的训练数据和生成模型的训练数据不同。
StyleGAG总结
关键点:
结合AdaIN模块
使用中间隐变量w实现映射关系的解耦
通过随机噪声进一步提升图像细节,丰富多样性
创新点:
加入可通用的映射网络
样式混合,使用两个中层隐变量生成一张图像,扩大W WW的训练空间
感知路径长度
线性可分性
启发:
损失函数、模型结构、隐变量分布、数据集,每一项对于生成式模型都很关键。
解耦 - 让映射空间更线性的思想
StyleGAN的缺点
StyleGAN是目前最先进的高分辨率图像合成方法,已被证明可以在各种数据集上可靠地工作。除了逼真的人像,StyleGAN还可以用于生成其他动物,汽车甚至房间。
然而,StyleGAN并不完美,最明显的缺陷是生成的图像有时包含斑点似的伪影(artifacts)
NVIDIA的研究人员发布了StyleGAN的升级版——StyleGAN2,重点修复artifacts问题,并进一步提高了生成图像的质量。
StyleGAN2
论文:https://arxiv.org/pdf/1912.04958.pdf
代码:https://github.com/NVlabs/stylegan2
StyleGAN2的模型和方法
新的网络结构
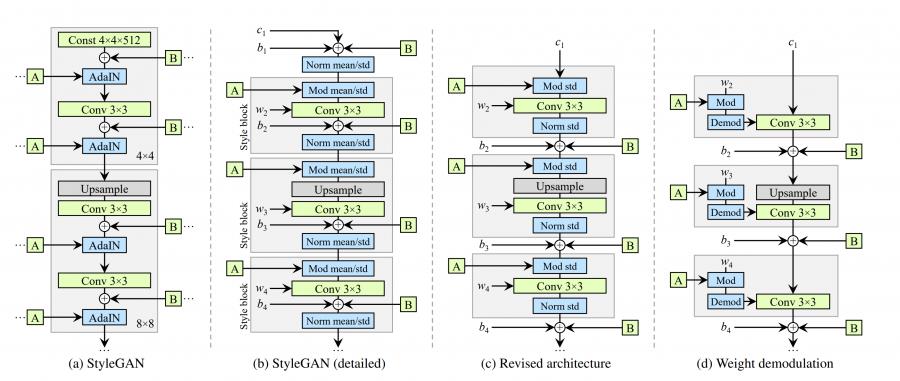
我们重新设计了 StyleGAN 合成网络的架构。(a)原始 StyleGAN,其中 A 表示从 W 学习的仿射变换,产生样式向量,而 B 表示噪声广播操作。(b)完整细节相同的图。在这里,我们将 AdaIN 分解为显式归一化后再进行调制,然后对每个特征图的均值和标准差进行操作。我们还对学习的权重(w),偏差(b)和常数输入(c)进行了注释,并重新绘制了灰色框,以便每个框都激活一种样式。激活函数
(Leaky ReLU)总是在添加偏置后立即应用。(c)我们对原始架构进行了一些改动,这些改动在正文中是有效的。我们从一开始就删除了一些多余的操作,将 b 和 B 的相加移到样式的有效区域之外,并仅调整每个要素图的标准偏差。(d)修改后的体系结构使我们能够用“解调”操作代替实例归一化,该操作适用于与每个卷积层相关的权重。
StyleGAN2的主要改进
生成的图像质量明显更好(FID分数更高、artifacts减少)
提出替代progressive growing的新方法,牙齿、眼睛等细节更完美
改善了Style-mixing
更平滑的插值(额外的正则化)
训练速度更快
改进详述
1.Weight Demodulation
karras和ming-yu liu等大佬非常擅长用改造的normalization层进行image synthesis任务(如GauGAN和StyleGAN)。如GauGAN中的SPADE和StyleGAN的AdaIN。
对StyleGAN,karras等人使用AdaIN (adaptive instance normalization)来控制source vector w ww对生成人脸的影响程度。
对StyleGAN2来讲,作者们调整了AdaIN的使用,从而有效的避免了水印artifacts(water droplet artifacts)
AdaIN是被用于快速Neural Style Transfer的normalization层。在Neural Style Transfer任务中,研究者们发现:AdaIN可以显著的解耦(remarkable disentanglement) low-level的"style"特征和high-level的"content"特征。
不同于一般的风格迁移(Style Transfer)任务,AdaIN的出现使得风格迁移任务从受限于一种风格或者需要lengthy optimization process的情况中摆脱了出来。
AdaIN表明,仅通过归一化统计就可以将风格(style)和内容(content)结合起来。
Karras等人在StyleGAN2中解释了AdaIN这种归一化方法会"discard information in feature maps encoded in the relative magnitudes of activations"。(丢弃以激活的相对大小编码的特征图中的信息)
生成器(Generator)通过将信息sneaking在这些层中来克服信息丢失的问题,但是这却带来了水印问题(water-droplet artifacts)。
在StyleGAN2中,AdaIN被重构为Weight Demodulation, 如上图网络结构所示:
AdaIN 层的含义: 同BN层类似,其目的是对网络中间层的输出结果进行scale和shift,以增加网络的学习效果,避免梯度消失。相对于BN是学习当前batch数据的mean和variance,Instance Norm则是采用了单张图片。AdaIN则是使用learnable的scale和shift参数去对齐特征图中的不同位置。
Weight demodulation的处理流程如下:
① 如上图里面的©所示,Conv 3x3后面的Mod std被用于对卷积层的权重进行scaling(缩放),这里的i ii表示第i ii个特征图。 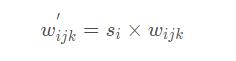
② 接着对卷积层的权重进行demod
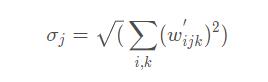
那么,得到新的卷积层权重为:
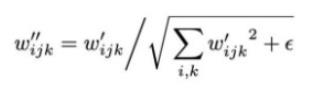
加一个小的ϵ \\epsilonϵ是为了避免分母为0,保证数值稳定性。尽管这种方式与Instance Norm并非在数学上完全等价,但是weight demodulation同其它normalization 方法一样,使得输出特征图有着standard的unit和deviation。
此外,将scaling参数挪为卷积层的权重使得计算路径可以更好的并行化。
2.Progressive growth
Progressive growing指的是:“先训一个小分辨率的图像,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率。”
progressive growing还是属于一种比较直观的对高分辨率图像合成的coarse-to-fine(由粗到细)的方式
不同于StyleGAN第一代使用progressive growing的策略,StyleGAN2开始寻求其它的设计以便于让网络更深,并有着更好的训练稳定性。
对Resnet结构而言,网络加深是通过skip connection实现的。所以StyleGAN2采用了类似ResNet的残差连接结构(residual block)。对于这些设计,我们使用双线性滤波对前一层进行上/下采样,并尝试学习下一层的残差值(residual value)。
受MSG-GAN启发,StyleGAN2设计了一个新的架构来利用图像生成的多个尺度信息(不需要像progressive growing那样麻烦了),他们通过一个resnet风格的跳跃连接在低分辨率的特征映射到最终生成的图像(下图的绿色block)

3.Lazy Regularization(正则化)
StyleGAN1对FFHQ数据集使用了R1正则化。实验结果表明,在评估计算代价的时候,regularization是可以忽略的。实际上,即使每隔16个mini-batch使用regularization的方式,模型效果依旧很不错,因此,在StyleGAN2中,我们可以使用lazy regularization的策略,即对数据分布开始跑偏的时候才使用R1 regularization,其它时候不使用。
4.Path Length Regularization(路径长度正则化)
Path Length Regularization的意义是使得latent space的插值变得更加smooth和线性。简单来说,当在latent space中对latent vector进行插值操作时,我们希望对latent vector的等比例的变化直接反映到图像中去
总结
关键点:
使用Weight demodulation代替AdaIN
发现PPL与生成图像质量的关系
去除渐进式网络
创新点:
Weight demodulation
Path length regularization
在生成器和判别其中采用不同的网络结构
启发:
Normalization可能带来不好的结果
复杂的渐进网络看起来很酷,但往往复杂的东西更容易出错
把评价指标直接用作正则项,lazy正则化
参考博客及文章
https://zhuanlan.zhihu.com/p/63230738
https://blog.csdn.net/weixin_39538889/article/details/114947559
https://blog.csdn.net/g11d111/article/details/109187245
https://blog.csdn.net/weixin_43013761/article/details/100895333
以上是关于StyleGAN及其改进型(StyleGAN2)——基于样式的生成对抗网络论文整理与总结的主要内容,如果未能解决你的问题,请参考以下文章