电子科技大学人工智能期末复习笔记:概率与贝叶斯网络
Posted Vec_Kun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电子科技大学人工智能期末复习笔记:概率与贝叶斯网络相关的知识,希望对你有一定的参考价值。
目录
⚠Active / Inactive Paths 判断独立性
多重连接和多重消除 Multiple Joins & Multiple Elimination
前言
本复习笔记基于李晶晶老师的课堂PPT与复习大纲,供自己期末复习与学弟学妹参考用。
2023-02-10更新:增加了贝叶斯网络中的抽样问题
概率
概率公式
贝叶斯公式

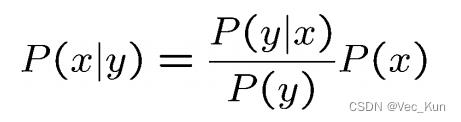
链式条件概率

例题
1. 求联合概率分布/边缘概率分布/条件概率分布

首先明确,P(W | dry)是一个概率分布,而不是一个概率值。不能写成 P(W | dry)=....
①求联合概率分布P(D,W);
②求边缘概率分布P(D);
③求条件概率分布P(W | D).
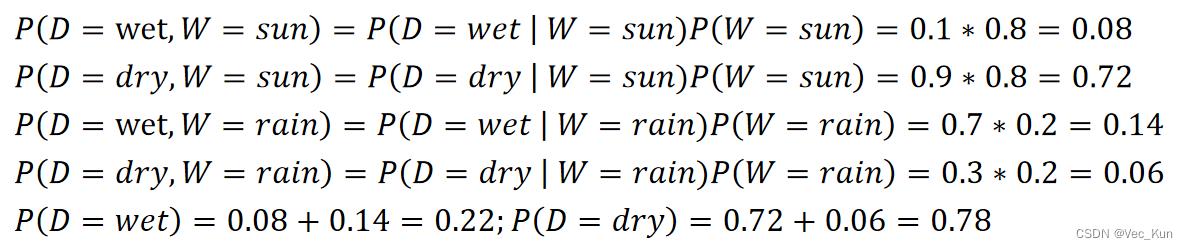
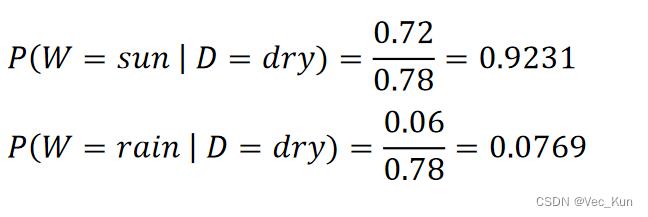
| P(W | dry) | ||
| D | W | P |
| dry | sun | 0.9231 |
| dry | rain | 0.0769 |
2. 灵活运用贝叶斯公式
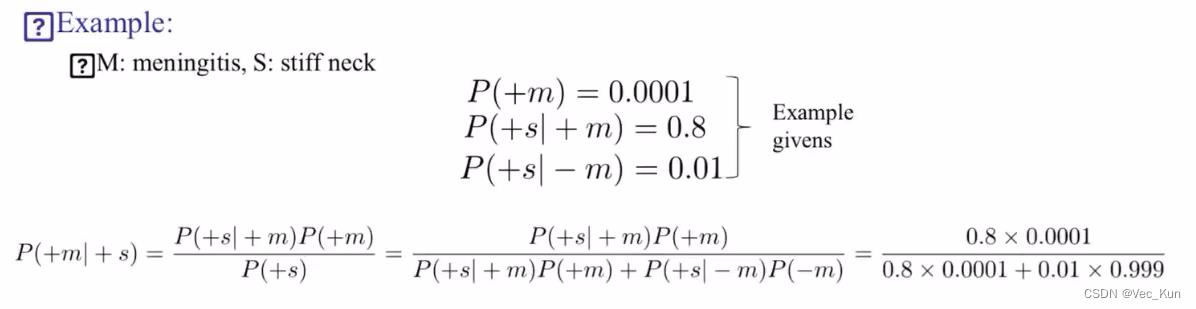
概率总结

贝叶斯网络
判断独立性
两个事件独立的判断


条件独立性的判断

假设条件独立的链式法则

⚠Active / Inactive Paths 判断独立性
要判断X,Y的独立性:
1. 找到X到Y的所有路径paths
2. 如果一个path的所有三元组都是active那么此path就是active
3. 若存在一个path为active,那么X、Y就是非独立的,反之独立
简言之:找到一条path的所有三元组都是active那么就非独立;
若只存在一条路径,那么找到一个inactive的三元组就独立,如果全部active才非独立。
⭐可以把X、Y理解为两个水池,如果有一根连通水管(path)里的开关全打开了(active)那么二者连通,不独立(independence);如果就只有一根水管连接,那么只要有一个开关被关闭(inactive)那么就独立。
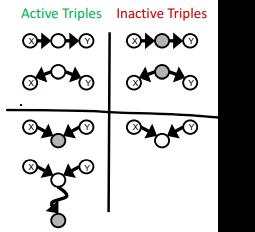
【上图阴影表示确定条件,即given。】
⭐只需要记间接因果(中间条件已知)、已知同因(父节点已知)、未知共果是active(子节点未知),其他三个对立的象限自己就出来了。
贝叶斯网络中的条件概率
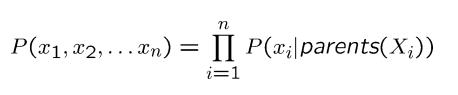
文字描述: 遍历每一项,分别以它们的父节点为条件,连乘即可。
举例说明比较直观:
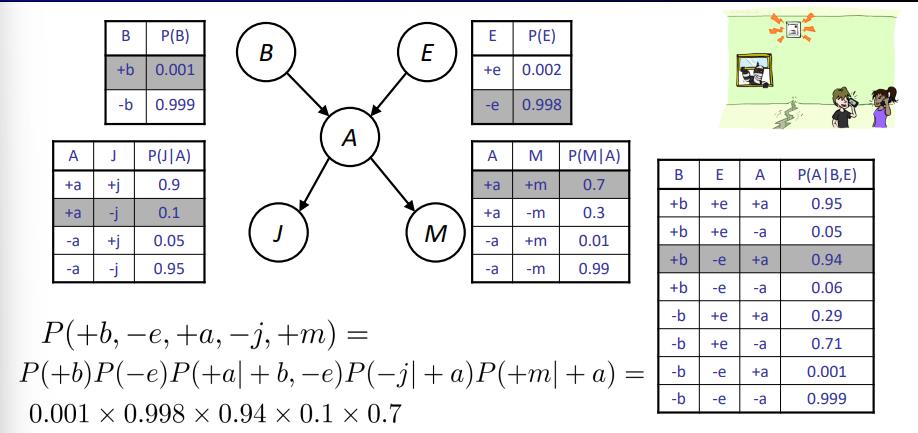
多重连接和多重消除 Multiple Joins & Multiple Elimination
对应乘起来就行了,没什么。


贝叶斯网络抽样(Bayes' Nets Sampling)
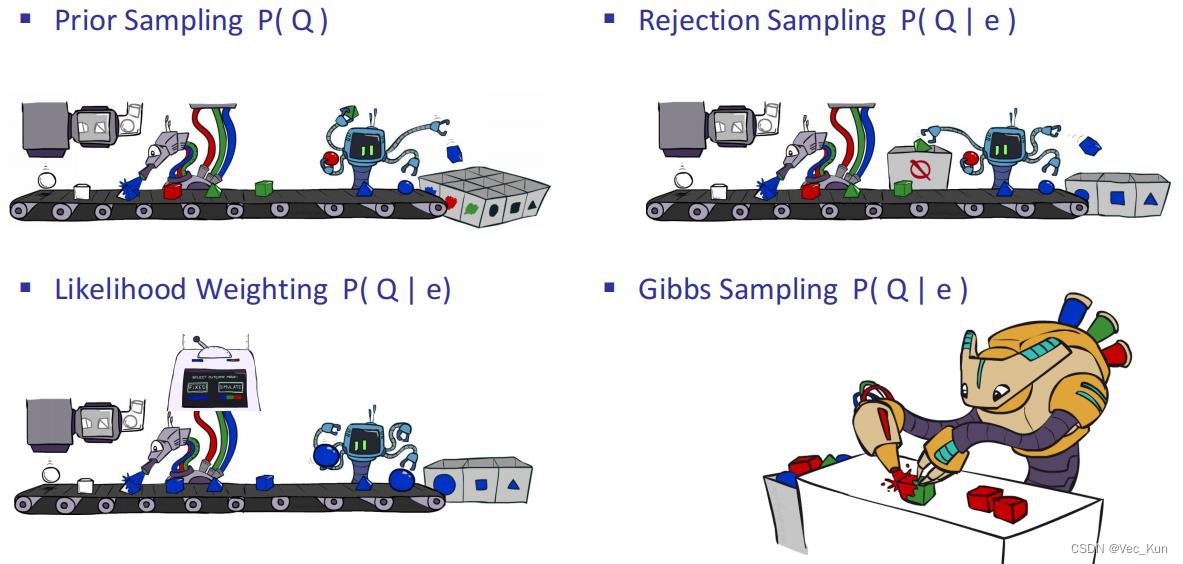
贝叶斯网络的抽样大致分为:
- 先验抽样 ▪ Prior Sampling
- 拒绝抽样 ▪ Rejection Sampling
- 加权抽样 ▪ Likelihood Weighting
- 吉布斯抽样 ▪ Gibbs Sampling
其目的是进一步加快贝叶斯网络近似的速度。
采样是什么?——Sampling
采样,顾名思义就是从特定的概率分布中抽取相应样本点的过程。它可以将复杂的分布简化为离散的样本点、可以用于随机模拟已进行复杂模型的近似求解或推理等。
先验抽样 ▪ Prior Sampling
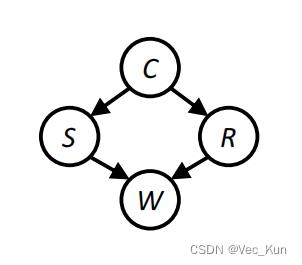
获取样本的方式为祖先抽样,从父节点开始逐渐扩展,类似于贝叶斯网络中的联合分布,下面以一个经典的例题直观感受一下:
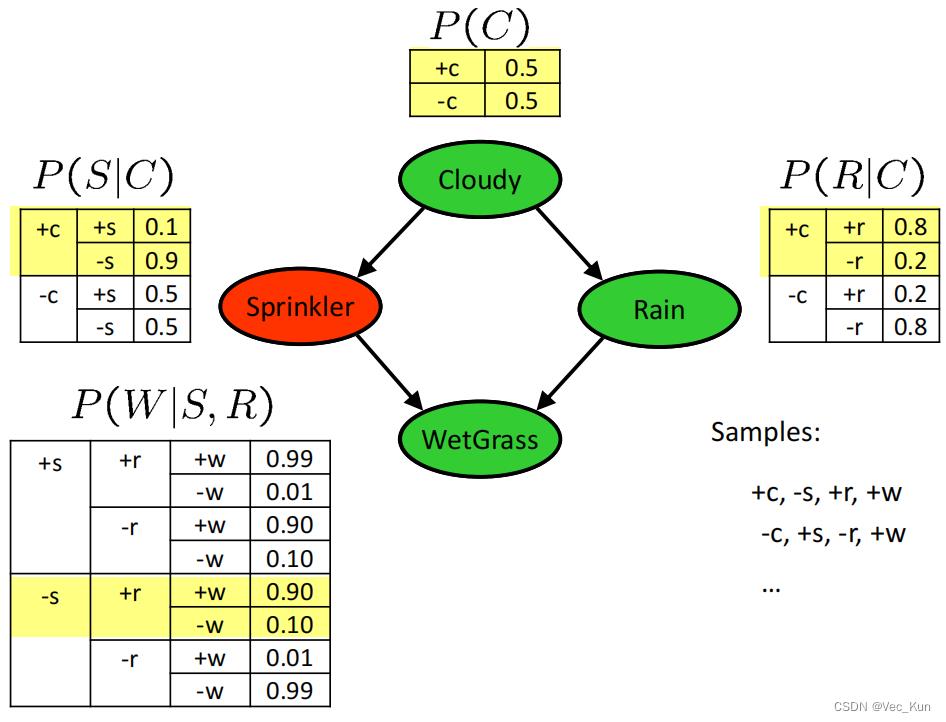
如图,它的核心思想是根据有向图的顺序,先对祖先节点进行采样,只有当某个节点的所有父节点都已完成采样,采对该结点进行采样。以上图为场景,先对Cloudy变量进行采样,然后对Sprinkle和Rain变量进行采样,最后对WetGrass变量采样。根据贝叶斯网络的全概率公式
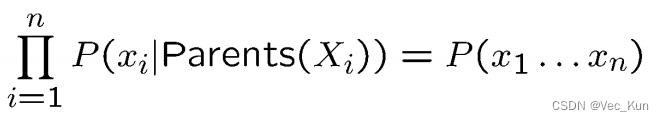
可以看出祖先采样得到的样本服从贝叶斯网络的联合概率分布。
如果只需要对贝叶斯网络中一部分随机变量的边缘分布进行采样,可以用祖先采样对全部随机变量进行采样,然后直接忽视那些不需要的变量的采样值即可。由图可见,如果需要对边缘分布p(Rain)进行采样,先用祖先采样得到全部变量的一个样本,如(Cloudy=T,Sprinkler=T,Rain=T,WetGrass=T),然后忽略掉无关变量,直接把这个样本看成是Coludy=T即可。
大致流程:
- 设一个事件的样本数为:
- 计算生成样本的概率:
- 套用公式:
- 采样程序是一致的,这样就估计出联合分布的概率。
例题:
从贝叶斯网络中得到的样本:
需要求P(W)
- 计数:+w——4;-w——1
- 计算概率:+w——4/5=0.8;-w——1/5=0.2
- (样本越多越接近真实概率)
总结:
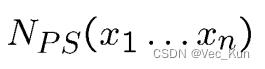
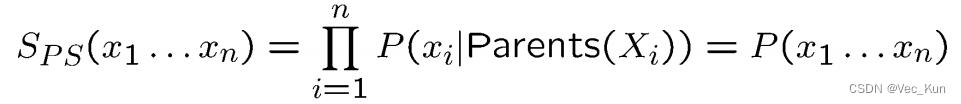

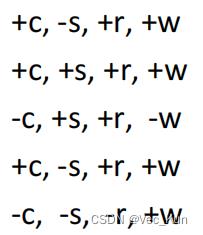

拒绝抽样 ▪ Rejection Sampling
类似,就不赘述了,它采样的方式就是根据条件取,不符合条件的丢弃:
假设在上例中我们要求C的概率,此时保留所有样本就没有意义了,我们选择对C计数;
假设我们想要P(C|+s),同样的,我们要统计C结果,但忽略(拒绝)没有+s的样本。
这就是拒绝抽样,它对于条件概率而言也是一致的。

似然加权 ▪ Likelihood Weighting
举一个例子:在有观测变量(Sprikeler = T, WetGrass = T)时,可以先对Cloudy进行采样,再对Rain进行采样,对于Sprikeler、WetGrass则直接赋观察值,得到下面的一个样本:
这样得到的样本的重要性权值为:
w 正比于 p(Sprinkler = T| Cloudy = T)p(WetGrass = T| Sprinkler = T,Rain = T) = 0.1*0.99 = 0.099
该式子可以理解为:当其他变量取得样本中的取值时(Cloudy = T,Rain = T),预测变量取得其确定值的可能性。

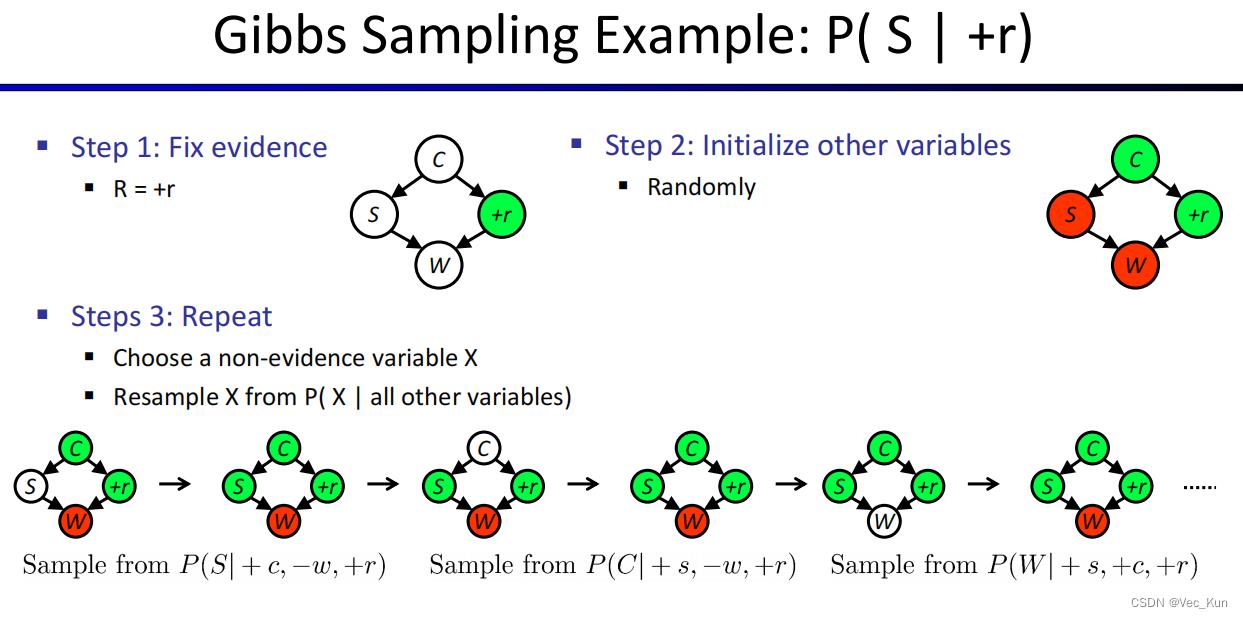
吉布斯抽样 ▪ Gibbs Sampling

总结
直接采样:按照拓扑顺序依次对每个变量进行采样。变量值被采样的概率分布依赖于父结点已得到的赋值。
拒绝采样:给定一个易于采样的分布,为一个难于采样的分布生成采样样本。
似然加权(likelihood weighting)只生成与证据e一致的事件,从而避免拒绝采样算法的低效率。
Gibbs采样算法:贝叶斯网络的Gibbs采样算法从任意的状态出发,通过(给定马尔可夫覆盖)对一个非证据变量Xi随机采样而生成下一个状态。对Xi的采样条件依赖于Xi的马尔可夫覆盖中的变量的当前值。
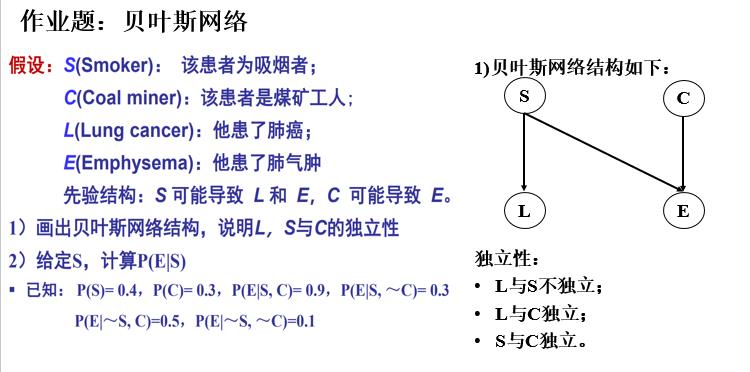
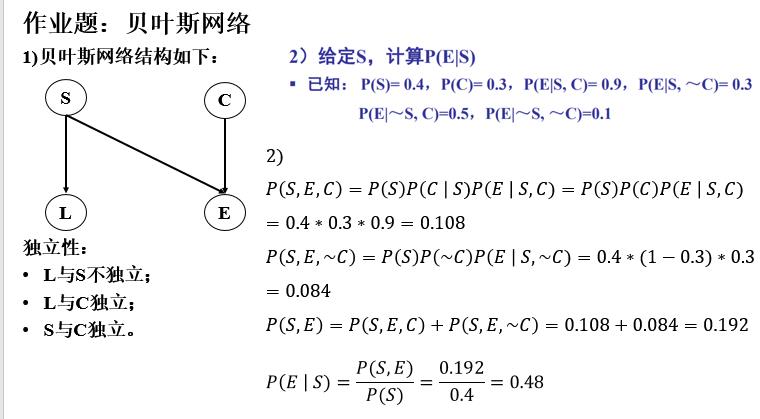
⚠作业题

以上是关于电子科技大学人工智能期末复习笔记:概率与贝叶斯网络的主要内容,如果未能解决你的问题,请参考以下文章