2023爬虫学习笔记 -- m3u8视频下载
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- m3u8视频下载相关的知识,希望对你有一定的参考价值。
一、目标地址
https://www.XXXX.com/二、获取mu38文件
1、点击XHR,刷新页面,会看到这里有两个m3u8文件
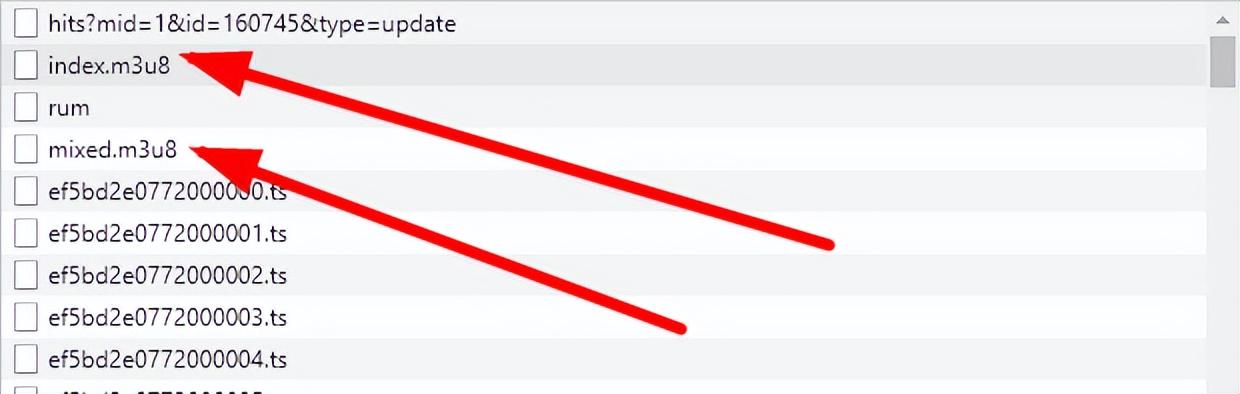
2、将m3u8地址复制到浏览器,会自动下载下来,index内容如下

mixed内容如下
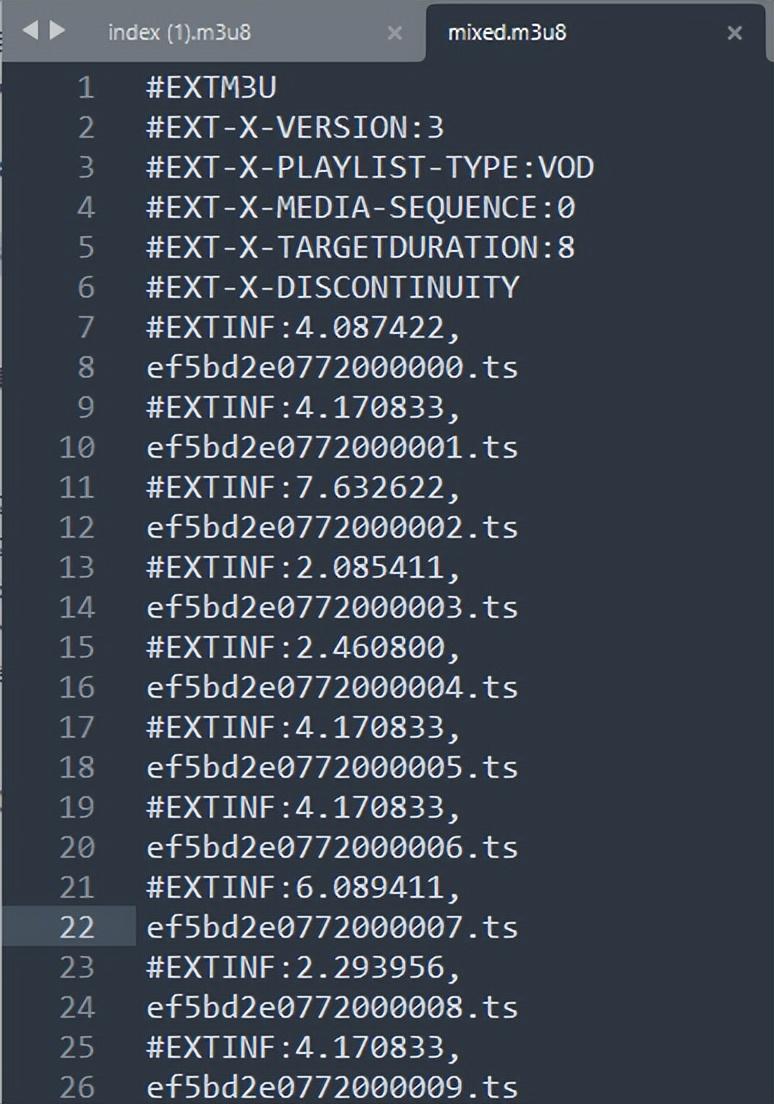
3、发现第二个才是我们需要的,重组m3u8地址,真实视频地址如下
https://vipXXXX.com/20230225/7657_80bc0440/2000k/hls/ef5bd2e0772000000.ts
https://vip.XXXXXX.com/20230225/7657_80bc0440/2000k/hls/ef5bd2e0772000001.ts三、下载视频
1、创建文件夹存放下载的片段
文件夹 = '片段'
if not os.path.exists(文件夹):
os.mkdir(文件夹)2、获取真是m3u8内容
m3u8地址="https://vipXXXXXom/20230225/7657_80bc0440/2000k/hls/mixed.m3u8"
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
m3u8内容=requests.get(url=m3u8地址,headers=头).text
print(m3u8内容)3、提取重要内容,重组真实的网址下载地址
切片列表=[]
for i in m3u8内容.split('\\n'):
if not i.startswith('#'):
切片=i
切片=urljoin(m3u8地址,切片)
切片列表.append(切片)
print(切片列表)4、通过真实地址,下载并保存视频
for i in 切片列表:
视频数据=requests.get(url=i,headers=头).content
视频名字=i.split('/')[-1]
保存路径=文件夹+'/'+视频名字
with open(保存路径,'wb')as fp:
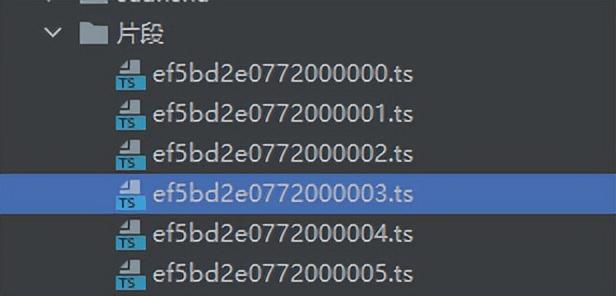
fp.write(视频数据)5、运行结果
6、源码
from urllib.parse import urljoin
文件夹 = '片段'
if not os.path.exists(文件夹):
os.mkdir(文件夹)
m3u8地址="https://vipXXXXX.com/20230225/7657_80bc0440/2000k/hls/mixed.m3u8"
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
m3u8内容=requests.get(url=m3u8地址,headers=头).text
#print(m3u8内容)
切片列表=[]
for i in m3u8内容.split('\\n'):
if not i.startswith('#'):
切片=i
切片=urljoin(m3u8地址,切片)
切片列表.append(切片)
print(切片列表)
for i in 切片列表:
视频数据=requests.get(url=i,headers=头).content
视频名字=i.split('/')[-1]
保存路径=文件夹+'/'+视频名字
with open(保存路径,'wb')as fp:
fp.write(视频数据)以上是关于2023爬虫学习笔记 -- m3u8视频下载的主要内容,如果未能解决你的问题,请参考以下文章