2023爬虫学习笔记 -- selenium库的实际应用
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- selenium库的实际应用相关的知识,希望对你有一定的参考价值。
一、安装selenium库文件
pip install selenium二、查看浏览器版本信息
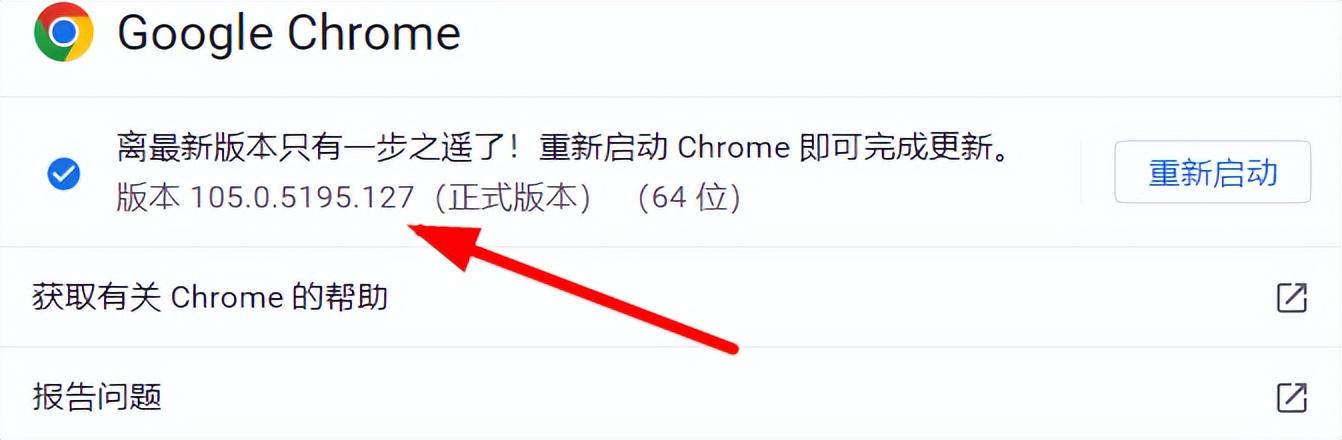
三、下载对应的驱动程序
http://chromedriver.storage.googleapis.com/index.html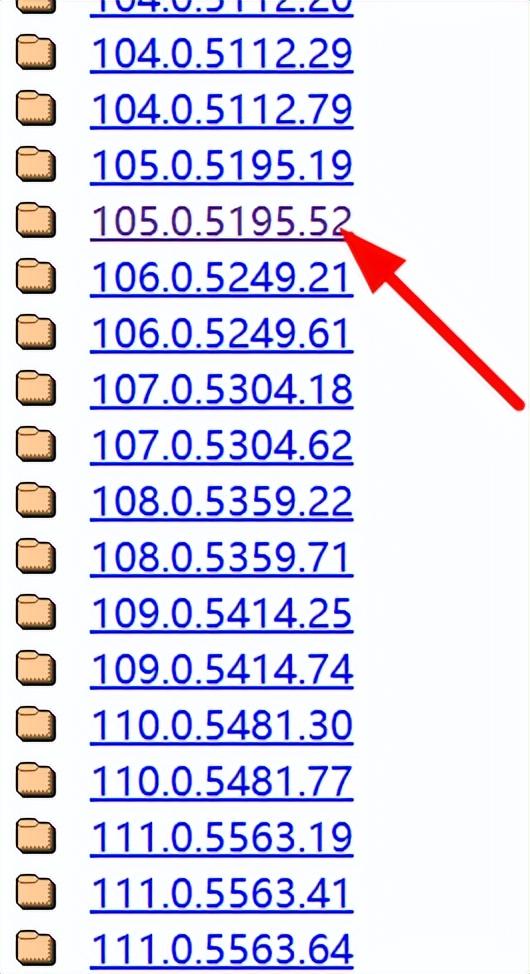
四、代码实现
1、打开浏览器
浏览器 = webdriver.Chrome(r'./chromedriver')2、访问网站
浏览器.get("https://www.baidu.com")3、获取网站的关键标签
第一个参数通过什么方式,支持id,classname等,然后右击复制xpath路劲
标签=浏览器.find_element('xpath','//*[@id="kw"]')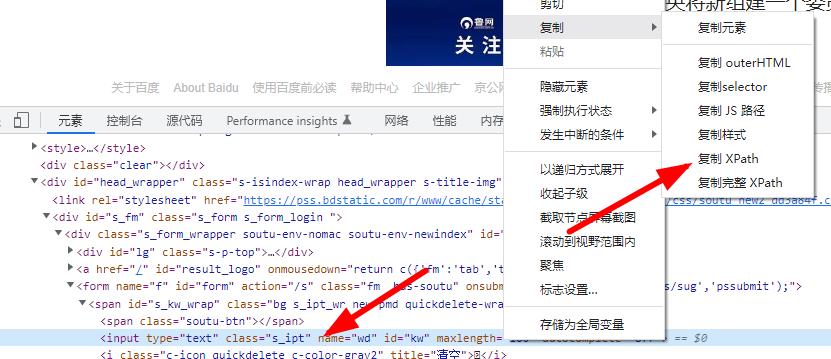
4、输入要搜索的内容
标签.send_keys("美女")5、获取搜索按钮xpath,并点击
按钮=浏览器.find_element('xpath','//*[@id="su"]')
按钮.click()6、网页向下滑动
浏览器.execute_script('document.documentElement.scrollTo(0,1000)')7、浏览器前进和后退
浏览器.back()
浏览器.forward()8、源码
from selenium import webdriver
from time import sleep
浏览器 = webdriver.Chrome(r'./chromedriver')
浏览器.get("https://www.baidu.com")
标签=浏览器.find_element('xpath','//*[@id="kw"]')
标签.send_keys("美女")
按钮=浏览器.find_element('xpath','//*[@id="su"]')
按钮.click()
sleep(3)
浏览器.execute_script('document.documentElement.scrollTo(0,1000)')
浏览器.back()
sleep(2)
浏览器.forward()
sleep(6)六、动作链操作
1、导入库文件
from selenium.webdriver import ActionChains2、访问网址
浏览器 = webdriver.Chrome(r'./chromedriver')
浏览器.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
sleep(3)
3、获取标签所在的iframe标签
浏览器.switch_to.frame('iframeResult')4、获取拖动标签的xpath
拖拽标签=浏览器.find_element("xpath",'//*[@id="draggable"]')5、先对标签进行按住的操作
动作对象=ActionChains(浏览器)
动作对象.click_and_hold(拖拽标签)6、再对标签进行移动操作,移动操作,每次向下移动10个像素
for i in range(3):
动作对象.move_by_offset(0,10).perform()
sleep(1)7、源码
浏览器 = webdriver.Chrome(r'./chromedriver')
浏览器.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
sleep(3)
浏览器.switch_to.frame('iframeResult')
拖拽标签=浏览器.find_element("xpath",'//*[@id="draggable"]')
print(拖拽标签)
动作对象=ActionChains(浏览器)
动作对象.click_and_hold(拖拽标签)
for i in range(3):
动作对象.move_by_offset(0,10).perform()
sleep(1)
sleep(6)以上是关于2023爬虫学习笔记 -- selenium库的实际应用的主要内容,如果未能解决你的问题,请参考以下文章