2023爬虫学习笔记 -- 多线程操作
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- 多线程操作相关的知识,希望对你有一定的参考价值。
一、定义一个程序开始时间
程序开始时间=time.time()二、创建几个网址,模拟目标网站
网址列表=['http://www.baidu.com','http://www.sogou.com','http://www.163.com']三、创建一个函数访问网站,模拟爬取数据操作(耗时操作)
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
def 访问网站(url):
网站内容=requests.get(url=url,headers=头).text
time.sleep(2)
print(网站内容[1:20])四、调用函数,并获取时长,每次程序运行时间在6-7秒之间
for 网址 in 网址列表:
访问网站(网址)
print("总耗时长:",time.time()-程序开始时间)五、总耗时长

六、换成多线程操作
1、前三步和上面一样
程序开始时间=time.time()
网址列表=['http://www.baidu.com','http://www.sogou.com','http://www.163.com']
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
def 访问网站(url):
网站内容=requests.get(url=url,headers=头).text
time.sleep(2)
print(网站内容[1:20])2、创建一个线程,并将所有子线程放进去
线程池=[]
for 网址 in 网址列表:
线程=Thread(target=访问网站,args=(网址,))
线程池.append(线程)
线程.start()3、让子线程执行完毕,主程序再结束,并获取程序运行时间
for t in 线程池:
t.join()
print("总耗时长:",time.time()-程序开始时间)4、总耗时长在2-3秒之间,是上面的三倍
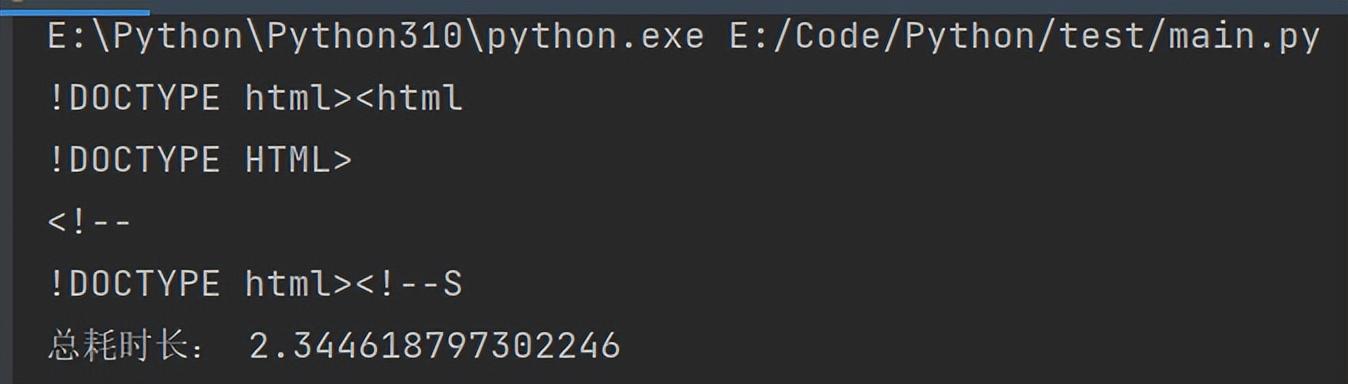
以上是关于2023爬虫学习笔记 -- 多线程操作的主要内容,如果未能解决你的问题,请参考以下文章