2023爬虫学习笔记 -- 解决爬虫Cookies问题
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- 解决爬虫Cookies问题相关的知识,希望对你有一定的参考价值。
一、目标地址
https://xXXXXu.com/二、分析要获取的内容
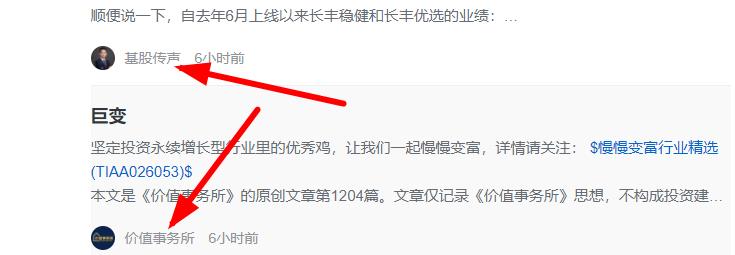
1、获取这些用户名字
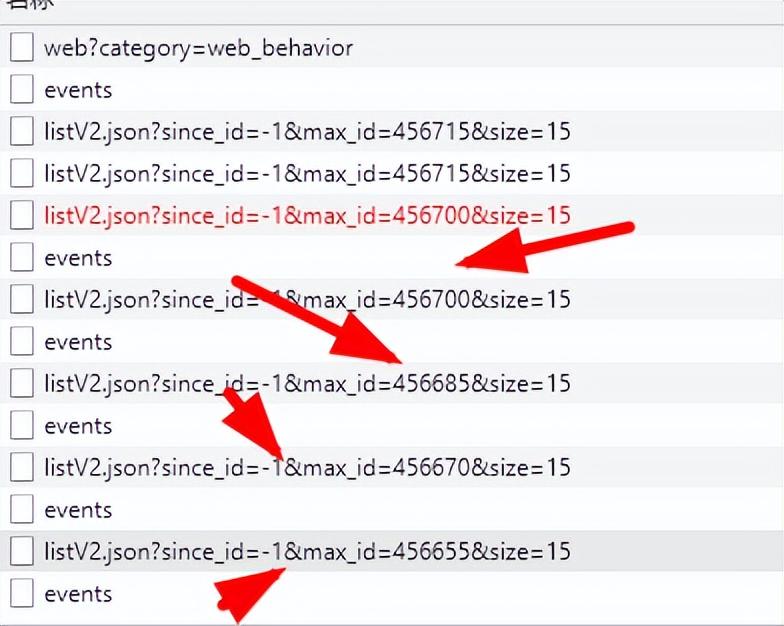
2、通过刷新页面,发现内容是通过Ajax加载,主要是通过max_id参数获取内容
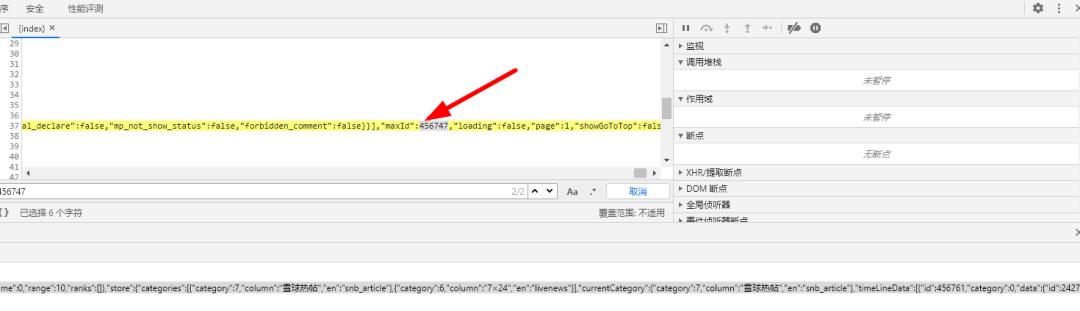
3、找到起始的max_id
三、代码实现
1、通过session自动获取相关cookie信息,没有cookie该网站禁止获取信息
se对象=requests.session()
'items[0].original_status.user.screen_name'
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
首地址="https://xXXXX.com/"
se对象.get(url=首地址,headers=头)2、通过正则获取max_id的起始值
t=re.findall('is_private":false,"id":(.*?),"category":',响应内容.text)
print(t)3、构造Ajax动态网址
动态目标地址='https://XXXX.com/statuses/hot/listV2.json?since_id=-1&max_id=&size=15'
for i in range(1,4):
if i==1:
目标地址 = "https://XXXX.com/"
else:
目标地址 = 动态目标地址.format(int(t[-1])-(i-2)*15)
print(目标地址)4、第一页内容通过xpath获取
if 目标地址 == "https://xXXXX.com/":
相应内容 = se对象.get(url=目标地址, headers=头)
相应内容.encoding="utf-8"
数据解析=etree.HTML(相应内容.text)
数据列表=数据解析.xpath('//*[@id="app"]/div[3]/div[1]/div[2]/div[2]/div[1]/div/div/div/a[2]/text()')
print(数据列表)5、第二页往后通过JSON数据获取用户名信息
相应内容 = se对象.get(url=目标地址, headers=头).json()
#print(相应内容)
#print(type(相应内容))
#print(相应内容["items"])
for i in 相应内容["items"]:
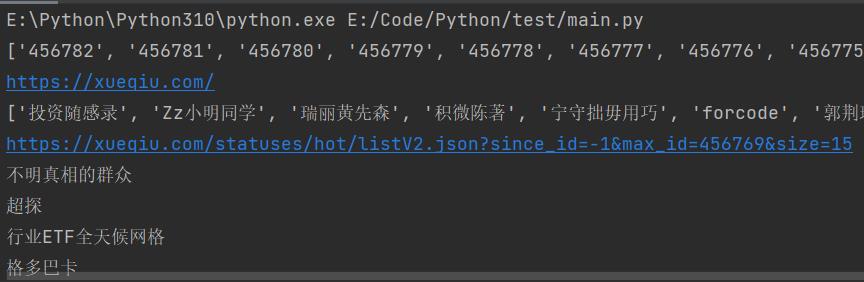
print(i['original_status']['user']['screen_name'])6、运行结果
7、源码
import os.path
import re
import time
from lxml import etree
import requests
se对象=requests.session()
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
首地址="https://XXXX.com/"
响应内容=se对象.get(url=首地址,headers=头)
#print(响应内容.text)
t=re.findall('is_private":false,"id":(.*?),"category":',响应内容.text)
print(t)
动态目标地址='https://XXXX.com/statuses/hot/listV2.json?since_id=-1&max_id=&size=15'
for i in range(1,4):
if i==1:
目标地址 = "https://XXXXX.com/"
else:
目标地址 = 动态目标地址.format(int(t[-1])-(i-2)*15)
print(目标地址)
if 目标地址 == "https://XXXXX.com/":
相应内容 = se对象.get(url=目标地址, headers=头)
相应内容.encoding="utf-8"
数据解析=etree.HTML(相应内容.text)
数据列表=数据解析.xpath('//*[@id="app"]/div[3]/div[1]/div[2]/div[2]/div[1]/div/div/div/a[2]/text()')
print(数据列表)
else:
相应内容 = se对象.get(url=目标地址, headers=头).json()
#print(相应内容)
#print(type(相应内容))
#print(相应内容["items"])
for i in 相应内容["items"]:
print(i['original_status']['user']['screen_name'])以上是关于2023爬虫学习笔记 -- 解决爬虫Cookies问题的主要内容,如果未能解决你的问题,请参考以下文章