2023爬虫学习笔记 -- 某简历模板的爬取过程
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- 某简历模板的爬取过程相关的知识,希望对你有一定的参考价值。
一、目标地址
https://sc.cxxxx.com/jianli/free.html二、分析要获取的数据
1、首先获取模板的名字和详情页
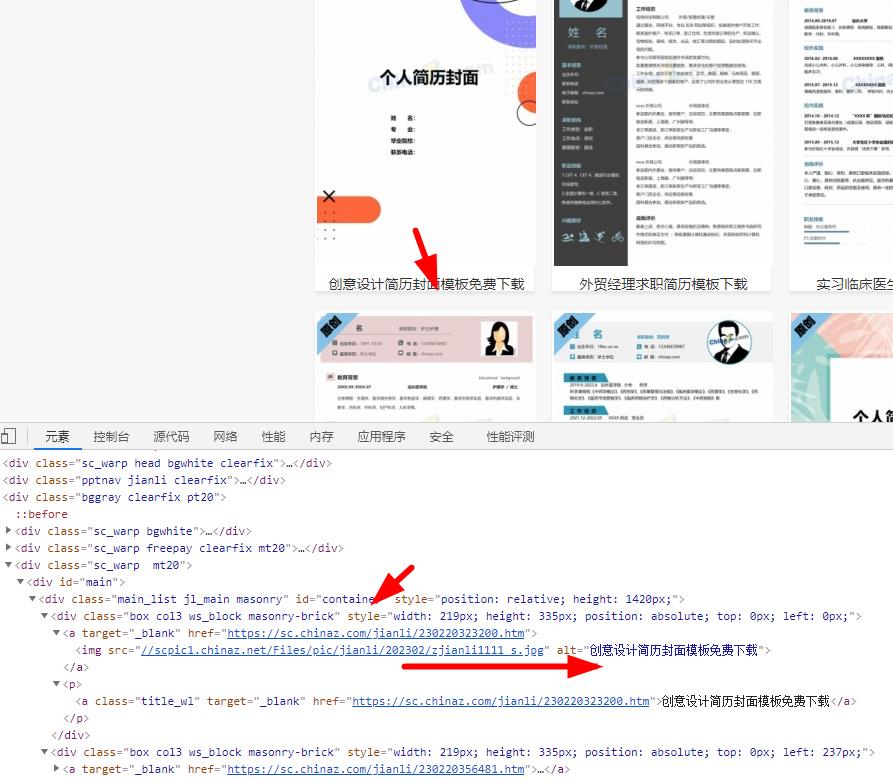
2、详情页内获取下载地址
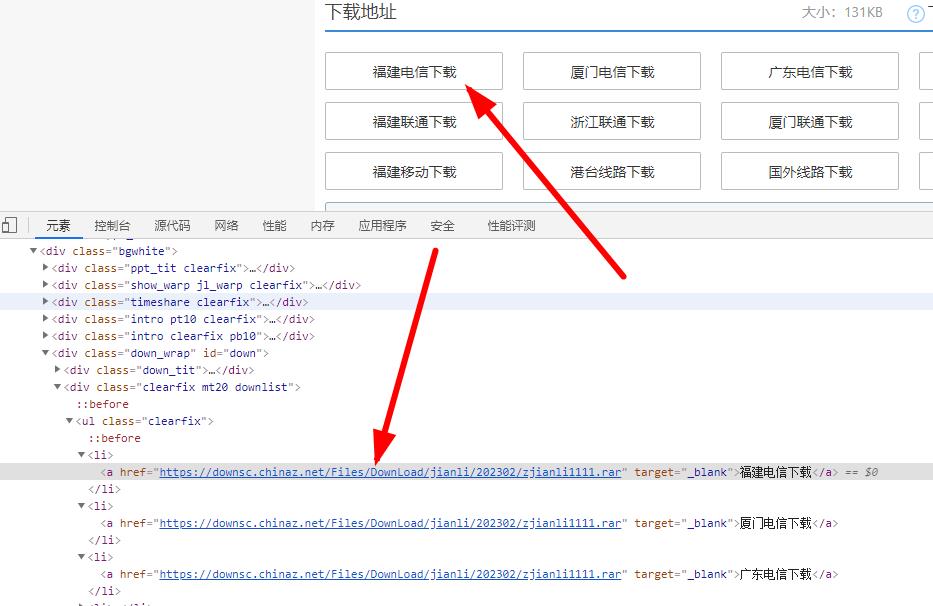
3、分析第一页第二页和第三页的网址
https://sc.xxxxz.com/jianli/free.html
https://sc.cxxxxz.com/jianli/free_2.html
https://sc.cxxxx.com/jianli/free_3.html三、代码实现
1、新建一个模板的文件夹,将下载好的模板全部放进去
文件夹="模板"
if not os.path.exists(文件夹):
os.mkdir(文件夹)2、构建动态爬取网址
动态目标地址="https://sc.Xxxxx.com/jianli/free_%d.html"
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
for pg in range(1,6):
if pg==1:
目标地址="https://sc.cxxxxz.com/jianli/free.html"
else:
目标地址=format(动态目标地址%pg)3、获取响应页面的内容,出现乱码
响应内容 = requests.get(url=目标地址, headers=头).text
print(响应内容)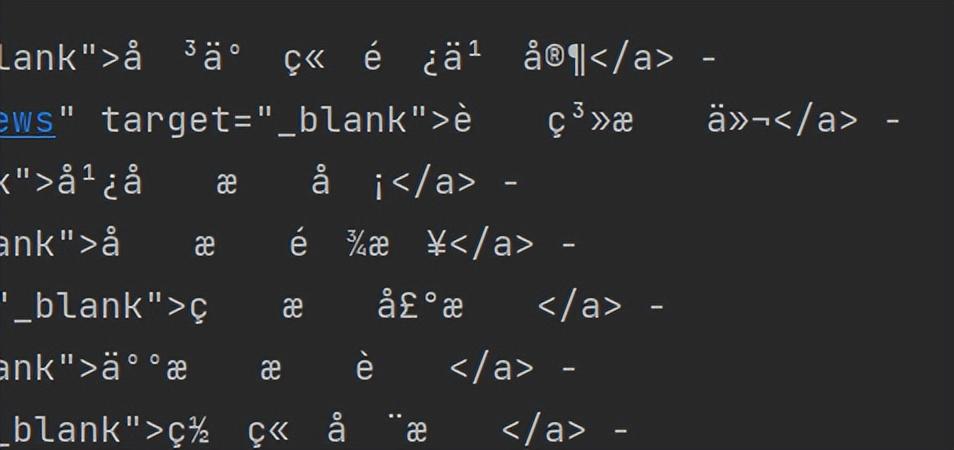
4、对获取的内容进行编码处理
响应内容 = requests.get(url=目标地址, headers=头)
响应内容.encoding="utf-8"
编码后的内容=响应内容.text
print(编码后的内容)5、从响应内容获取简历名称及详情页地址
数据解析=etree.HTML(编码后的内容)
数据列表=数据解析.xpath('//*[@id="container"]/div')
print(数据列表)
for i in 数据列表:
详情页=i.xpath('./a/@href')[0]
标题=i.xpath('./a/img/@alt')[0]
print(详情页,标题)6、从详情页获取下载地址
详情页内容=requests.get(url=详情页, headers=头).text
#print(详情页内容)
数据解析=etree.HTML(详情页内容)
下载地址=数据解析.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href')[0]
#print(下载地址)7、获取下载地址
数据解析=etree.HTML(详情页内容)
下载地址=数据解析.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href')8、保存下载的内容
for i in 下载地址:
下载数据=requests.get(url=i,headers=头).content
保存路径=文件夹+'/'+标题
with open(保存路径,'wb') as fp:
fp.write(下载数据)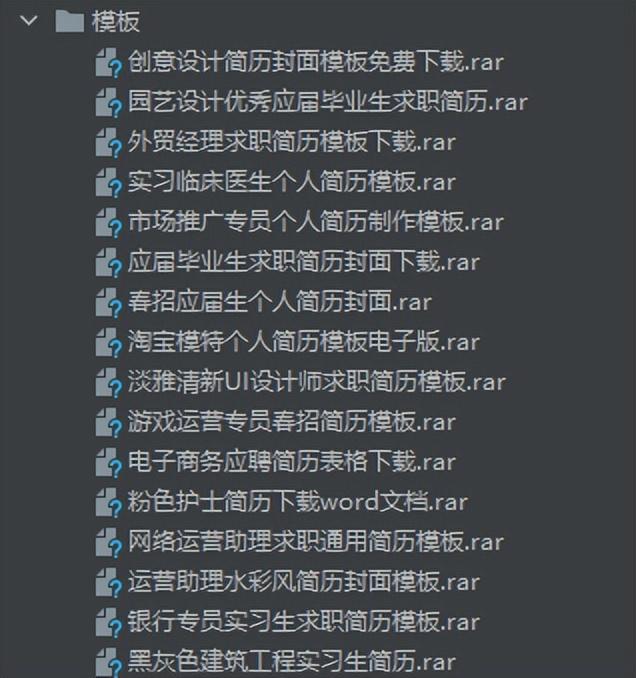
9、完整代码
import os.path
import time
from lxml import etree
import requests
文件夹="模板"
if not os.path.exists(文件夹):
os.mkdir(文件夹)
动态目标地址="https://sc.XXXXX.com/jianli/free_%d.html"
头=
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
for pg in range(1,2):
if pg==1:
目标地址="https://sc.XXX.com/jianli/free.html"
else:
目标地址=format(动态目标地址%pg)
响应内容 = requests.get(url=目标地址, headers=头)
响应内容.encoding="utf-8"
编码后的内容=响应内容.text
#print(编码后的内容)
数据解析=etree.HTML(编码后的内容)
数据列表=数据解析.xpath('//*[@id="container"]/div')
print(数据列表)
for i in 数据列表:
详情页=i.xpath('./a/@href')[0]
标题=i.xpath('./a/img/@alt')[0]+'.rar'
#print(详情页,标题)
详情页内容=requests.get(url=详情页, headers=头).text
#print(详情页内容)
数据解析=etree.HTML(详情页内容)
下载地址=数据解析.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href')
#print(下载地址)
for i in 下载地址:
下载数据=requests.get(url=i,headers=头).content
保存路径=文件夹+'/'+标题
with open(保存路径,'wb') as fp:
fp.write(下载数据)以上是关于2023爬虫学习笔记 -- 某简历模板的爬取过程的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫之Scrapy框架系列(12)——实战ZH小说的爬取来深入学习CrawlSpider