什么是对中国大学进行排名的爬窗系统
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是对中国大学进行排名的爬窗系统相关的知识,希望对你有一定的参考价值。
本教程主要参考中国大学慕课的 Python 网络爬虫与信息提取,为个人学习笔记。在学习过程中遇到了一些问题,都手动记录并且修改更正,保证所有的代码为有效。且结合其他的博客总结了一些常见问题的解决方式。
本教程不商用,仅为学习参考使用。如需转载,请联系本人。
Reference
爬虫 MOOC
数据分析 MOOC
廖雪峰老师的 Python 教程
功能描述
输入:大学排名URL链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests‐bs4
定向爬虫:仅对输入 URL 进行爬取,不扩展爬取
定向爬虫可行性
1.确定要爬取的信息是否写在 html 的页面代码中
https://www.shanghairanking.cn/rankings/bcur/2021
2.没有 robots 协议,即没有爬虫的限制
程序的结构设计
步骤1:从网络上获取大学排名网页内容 getHTMLText()
步骤2:提取网页内容中信息到合适的数据结构 fillUnivList()
步骤3:利用数据结构展示并输出结果 printUnivList()
程序编写
先使用异常处理形式爬取网站,修改编码并返回 url 的内容。(requests)
然后找到 tbody 标签,在tbody孩子标签中挨个检索 tr(for循环),如果类型和 tag 一致,则查找 tr 中的 td 标签,以二维列表的数据结构存储信息 [[“1”, “清华大学”, “北京”], [“2”, “北京大学”, “北京”], …]。(BeautifulSoup)
新版的排名的大学名字封装在 a 标签中,所以这里需要具体到查找属性为 ‘name-cn’ 的 a 标签并存储其字符串,即大学的中文名称。相应代码只需要做细微修改即可
最后格式化输出信息。
格式化输出回顾:
源代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: #先检索到tbody标签
if isinstance(tr, bs4.element.Tag):
tds = tr('td') #查询tr中的td标签,等价于tr.find_all('td')
# 新版的排名封装在a标签中,所以这里需要具体到查找属性为'name-cn'的a标签并存储其字符串,即大学的中文名称
a = tr('a','name-cn')
ulist.append([tds[0].string.strip(),a[0].string.strip(),tds[2].text.strip(),tds[4].string.strip()]) # 使用二维列表存储信息
def printUnivList(ulist, num):
print(":^10\t:^6\t:^10".format("排名","学校名称","总分")) #取10/6/10位中间对齐
for i in range(num):
u = ulist[i]
print(":^10\t:^6\t:^10".format(u[0], u[1], u[3]))
def main():
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2021"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univ
main()
登录后复制

程序优化
中文对齐问题的原因:
当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同。
中文对齐问题的解决:
采用中文字符的空格填充 chr(12288)
def printUnivList(ulist, num):
tplt = "0:^10\t1:3^10\t2:^10"
# 3表示需要填充时使用format的第三个变量进行填充,即使用中文空格
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[3], chr(12288)))
登录后复制
优化后的程序如下:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children: # 先检索到tbody标签
if isinstance(tr, bs4.element.Tag):
tds = tr('td') # 查询tr中的td标签,等价于tr.find_all('td')
# 新版的排名封装在a标签中,所以这里需要具体到查找属性为'name-cn'的a标签并存储其字符串,即大学的中文名称
a = tr('a','name-cn')
ulist.append([tds[0].string.strip(),a[0].string.strip(),tds[2].text.strip(),tds[4].string.strip()]) # 使用二维列表存储信息
def printUnivList(ulist, num):
tplt = "0:^10\t1:4^10\t2:^10\t3:^10"
# 3表示需要填充时使用format的第三个变量进行填充,即使用中文空格
print(tplt.format("排名", "学校名称", "地区", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
def main():
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2021"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univ
if __name__ == "__main__":
main()
登录后复制

总结
采用 requests‐bs4 路线实现了中国大学排名定向爬虫。
对中英文混排输出问题进行优化。
爬虫
python
数据挖掘
https
html
仙侠问道手机游戏
精选推荐
广告

中国大学排名的爬虫实战
1014阅读·0评论·0点赞
2022年1月24日
Python 爬虫-2020年中国大学排名
469阅读·5评论·1点赞
2020年9月13日
爬取大学排名信息实验报告
143阅读·0评论·0点赞
2022年10月23日
Python爬虫(一)—— 中国大学排名
6382阅读·11评论·11点赞
2022年4月2日
【Python爬虫】爬取2022软科全国大学排行榜
3115阅读·6评论·7点赞
2022年7月3日
【爬虫实战】5Python网络爬虫——中国大学排名定向爬虫
595阅读·3评论·5点赞
2021年1月17日
升级快的传奇手游

精选推荐
广告
Python练习-爬虫(附加爬取中国大学排名)
3539阅读·5评论·4点赞
2022年1月6日
【网络爬虫】爬取中国大学排名网站上的排名信息,将排名前20的大学的信息保存为文本文件并在窗口打印的python程序
1445阅读·1评论·4点赞
2022年1月26日
2.python爬虫实战:爬取近5年的中国大学排行榜信息【Python】(测试代码+api例程)
865阅读·0评论·1点赞
2022年5月19日
python爬虫案例典型:爬取大学排名(亲测有效)
2369阅读·0评论·5点赞
2022年6月12日
python爬虫 2021中国大学排名定向爬虫
5729阅读·8评论·26点赞
2021年4月28日
Python网络爬虫实例——“中国最好大学排名爬取”(嵩天:北理工大学)学习笔记
6217阅读·1评论·13点赞
2019年3月20日
最新2022中国大学排名发布!
216阅读·0评论·0点赞
2022年2月22日
python爬虫分析大学排名_Python爬虫之爬取中国大学排名(BeautifulSoup库)
1342阅读·0评论·2点赞
2021年2月4日
python实例,python网络爬虫爬取大学排名!
1931阅读·0评论·2点赞
2018年11月20日
学习笔记:中国大学排名定向爬虫
5171阅读·4评论·5点赞
2021年12月23日
【爬虫】爬取大学排名信息
252阅读·0评论·0点赞
2022年10月6日
网络爬虫爬取中国大学排名,并存入数据库
573阅读·0评论·1点赞
2019年9月21日
Python3爬虫爬取中国大学排名数据并写入mysql数据库
2272阅读·0评论·2点赞
2018年10月17日
python网络爬虫与信息提取-04-爬取某大学排名网站的排名数据
334阅读·0评论·0点赞
2020年1月19日
去首页
看看更多热门内容
评论18

weixin_48444032

1
为什么只能最多获取到30条?怎么修改?
2022.04.26

qq_56912992

赞
如果想把数据保存到excel具体应该怎么改呢
2022.12.03

qq_56912992

赞
你好我想多获取到办学资源那一列数据,但是为什么我添加了tds[5].string.strip()],后面的format也改了,但是只出现列头的”办学资源“文字,却不出现相应的数字数据呢,求解答!! 参考技术A 市民卡注销时押金退还:
市民办理注销市民卡时,如卡片完好能正常使用,凭押金收据退还25元押金;
如市民卡有弯、折、裂、破、洞、磨损、凹凸、火烧、水浸等痕迹或其他人为因素损坏的,不予退还25元押金。
注销办理条件:
市民卡退卡业务,需持卡满3个月;
市民因不再需要使用或户籍变动等原因办理注销的;
注销办理材料:
本人身份证或户口薄有效证件原件;
委托他人代办的:
须提供双方身份证件或户口薄有效证件原件及复印件;
办理网点:
市民卡退卡指定网点共三个:市民卡服务中心、市民卡星湖路网点、市民卡友爱路网点;
桂盛市民卡办理退卡业务需前往农信社营业网点办理,网点地点可致电农信社客服热线966888;
温馨提示:微信搜索公众号南宁本地宝,关注后在对话框回复【市民卡】,可获市民卡办理+挂失解挂指南、充值指南、乘车优惠功能开通、学生卡查询。
爬取中国大学排名
爬取最好大学网上最新2019年的中国大学排名情况
1.url:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html。
2.使用requests库和bs4库实现对中国大学排名的定向爬取。
3.对包含输出的列表进行排版。
1 import requests 2 from bs4 import BeautifulSoup #对bs4库中的Beautiful类引用 3 import bs4#引入bs4库 4 #获取界面的信息 5 def getHTMLText(url) : 6 try: 7 r = requests.get(url,timeout = 30) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return r.text 11 except: 12 print("获取失败") 13 return ‘‘ 14 #将获取的信息中有用的存入列表中 15 def fillUnivlist(ulist,html): 16 soup = BeautifulSoup(html,"html.parser")#html的方式保存 17 #查看源代码,大学排行信息包含在<tbody>,<tr>,<td>标签里面 18 #先解析<tbody>的位置 19 for tr in soup.find(‘tbody‘).children: 20 #用isinstance方法检测tr标签,如果tr标签不是bs4库中的Tag类型,过滤 21 if isinstance(tr,bs4.element.Tag): 22 #查出所有的tr标签后,查出td标签,将所有的td标签存入列表当中 23 tds = tr(‘td‘) 24 #在列表中增加需要的对应字段,大学排名,大学名称,大学评分 25 ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string]) 26 27 pass 28 #打印出获得的的信息 29 def printUnivlist(ulist,num): 30 #num为自己想要获取大学的数量 31 #打印表头 32 print("{:^10} {:^6} {:^10} {:^10}".format("排名","学校名称","省市","总分")) 33 for i in range(num): 34 u = ulist[i] 35 print("{:^10} {:^6} {:^10} {:^10}".format(u[0],u[1],u[2],u[3])) 36 37 38 print(‘Suc‘+str(num)) 39 40 41 def main(): 42 uinfo=[] #定义一个存放信息的列表 43 url=‘http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html‘ 44 html = getHTMLText(url) 45 fillUnivlist(uinfo,html) 46 printUnivlist(uinfo,20)#查看20个大学 47 main()
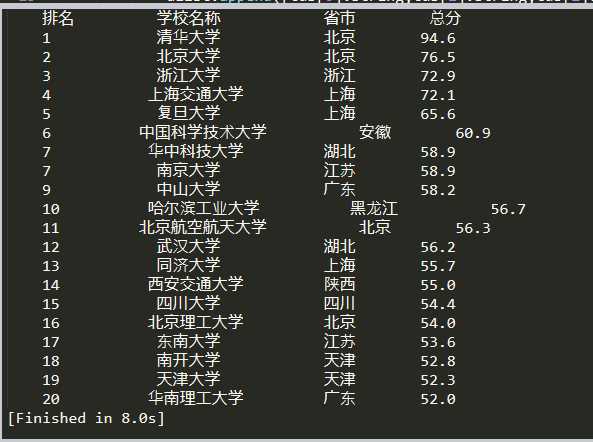
该程序主要包含四个函数:(1)def getHTMLText(url),获取URL中的所有信息;
(2)def fillUnivlist(ulist,html),j继续获取想得到的信息,并将这些信息存入列表当中;
(3)def printUnivlist(ulist,num),打印出(2)中获取的信息;
(4)def main(),初始化一些参数。
优化
中文对齐问题的解决
采用中文字 符的空格填充chr(12288)
{1:{4}^15},这个里面1和4对应format里面的顺序)(1为u[1],在1号位填充。4是四个要填充
的字符串中文空格,10为宽度),而“:” 后面的内容表示填充内容,当长度不够时将自动填充。
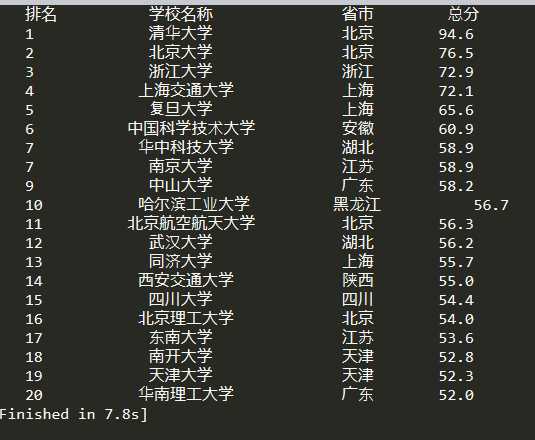
代码尚未优化完全,后期补全!
以上是关于什么是对中国大学进行排名的爬窗系统的主要内容,如果未能解决你的问题,请参考以下文章