2023爬虫学习笔记 -- 某狗网站爬取数据
Posted web安全工具库
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023爬虫学习笔记 -- 某狗网站爬取数据相关的知识,希望对你有一定的参考价值。
一、爬取某狗网站的首页
1、导入需要的库文件
import requests2、指定我们要访问的网址
网页="https://www.sogou.com"3、获取服务器的返回的所有信息
响应=requests.get(网页)4、通过text属性,从返回信息中读取字符串内容
响应内容=响应.text5、查看读取到的内容
print(响应内容)6、将读取到的内容存放起来
withopen("sogou.html","w") as 数据: 数据.write(响应内容)7、程序执行完毕
print("存储数据成功!!!")8、预览我们保存的sogou.html页面
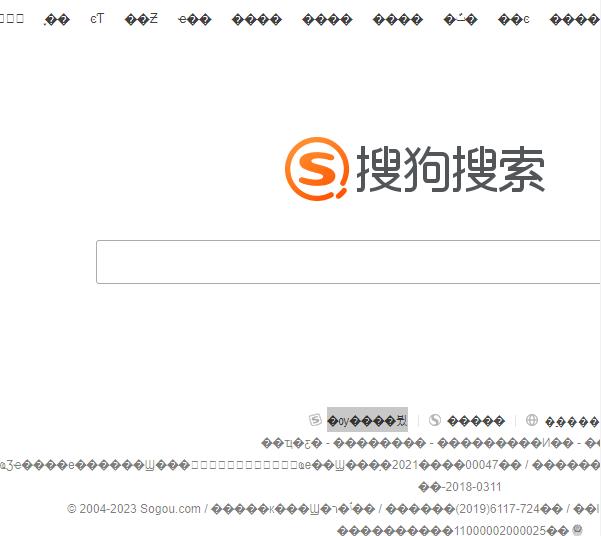
9、保存的内容有乱码,所以我们保存的时候要指定编码格式
withopen("sogou.html","w",encoding="utf-8") as 数据: 数据.write(响应内容)
二、实现搜索功能
1、搜狗首页输入要搜索的内容
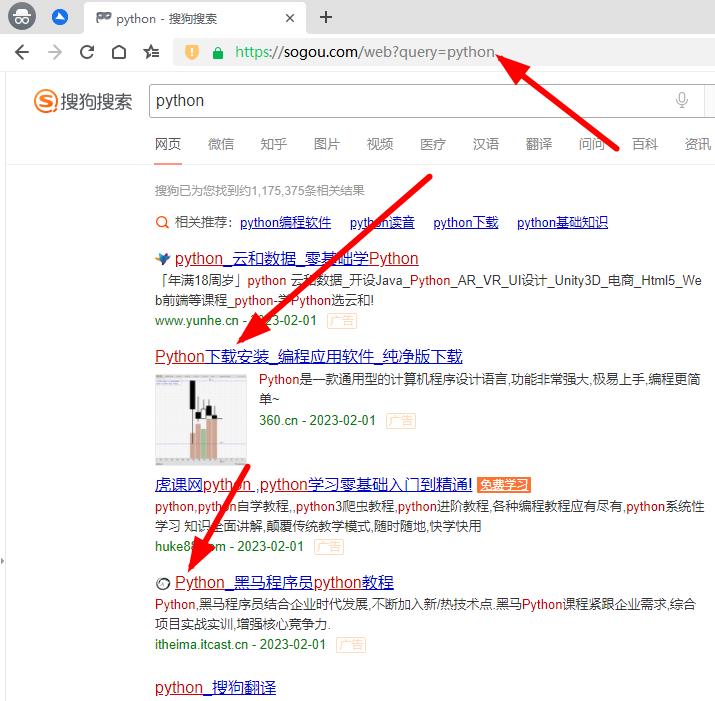
2、分析搜索的网址,query后面跟着的就是想要搜索的内容
https://sogou.com/web?query=python3、设置要搜索的关键字,修改上面的程序
搜索关键字=input("请输入要搜索的关键字:")网页="https://sogou.com/web?query="+搜索关键字4、重新运行程序,输入要搜索的关键字,按回车键

5、浏览保存的文件,又报错了,检测到了异常
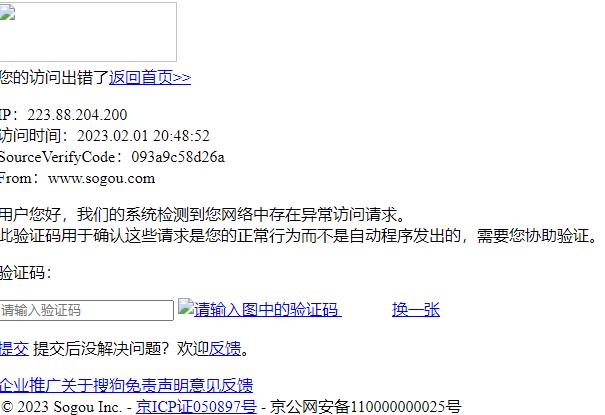
6、给他加上一个头信息,加上浏览器指纹
头="User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"响应=requests.get(网页,headers=头)7、运行结果
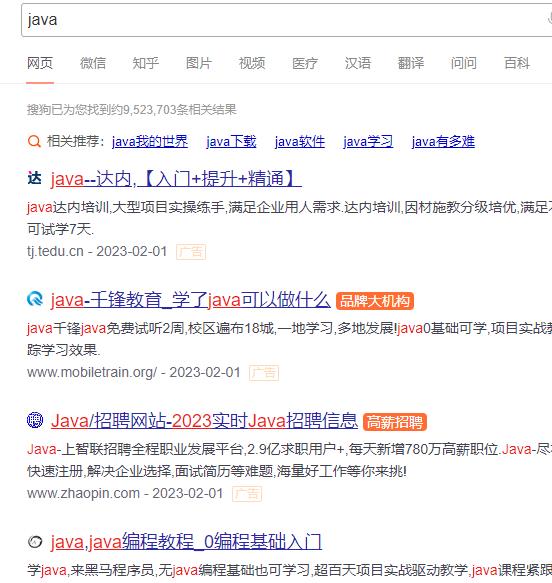
三、如果传递多个参数,可以将参数写成一个字典形式
参数="query":搜索关键字响应=requests.get(网页,params=参数,headers=头)四、最终源码
import requests搜索关键字=input("请输入要搜索的关键字:")参数="query":搜索关键字头="User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"## 网页="https://sogou.com/web"网页="https://sogou.com/web?query="+搜索关键字响应=requests.get(网页,params=参数,headers=头)响应内容=响应.textprint(响应内容)with open("sogou.html","w",encoding="utf-8") as 数据: 数据.write(响应内容)print("存储数据成功!!!")以上是关于2023爬虫学习笔记 -- 某狗网站爬取数据的主要内容,如果未能解决你的问题,请参考以下文章