论文笔记Deep Structured Output Learning for Unconstrained Text Recognition
Posted 糖梦梦是女侠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记Deep Structured Output Learning for Unconstrained Text Recognition相关的知识,希望对你有一定的参考价值。
写在前面:
我看的paper大多为Computer Vision、Deep Learning相关的paper,现在基本也处于入门阶段,一些理解可能不太正确。说到底,小女子才疏学浅,如果有错误及理解不透彻的地方,欢迎各位大神批评指正!E-mail:MerryTangMengyun@gmail.com.
论文结构:
Abstract
1.Introduction
2.Related Work
3.CNN Text Recognition Model
3.1 Character Sequence Model Review
3.2 Bag-of-N-gram Model Review
4.Joint Model
5.Evaluation
5.1 Datasets
5.2 Implementation Details
5.3 Experiments
6.Conclusion
《Deep Structured Output Learning for Unconstrained Text Recognition》
1.内容概述
这篇论文介绍了一种自然场景图片中无约束(unconstrained)words(ps:这个词不知道该如何翻译,文字?单词?词汇?感觉都比较奇怪,所以用原词,大家应该也能理解,就是一串字符)的识别方法。所谓“unconstrained”,就是指在没有固定的词典(lexion,ps:这个词在自然场景文本识别相关的paper中经常出现,也经常说free-lexion),并且不知道worlds的长度。
文章提出了一个卷积神经网络(Convolutional Neural Nework,CNN)与条件随机场(Conditional Random Field,CRF)相结合的模型,这个模型以整张word图片作为输入。CRF中的一项由CNN提供来预测每个位置的字符,高阶项由另一个CNN提供来检测N元文法(N-gram)的存在。这个模型(CRF,字符predictor,N元文法predictor)可以通过整体反向传播结构化输出损失来优化,本质上要求系统进行多任务学习,而训练仅要求生成综合数据。
相对于仅仅对字符进行预测(指不进行文法检测),文中提出的模型在标准文本识别benchmark中更加准确。除此之外,这个模型在lexicon-constrained(有固定字典,知道长度)的情景中获得了state-of-the-art的准确率(虽然这个方法是针对于free-lexcion及unconstrainted提出的,但是也对lexion-constrained的情况进行了实验)。
2.方法
(1)CNN文本识别模型(CNN Text Recognition Model)
a.字符序列模型( Character Sequence Model)
一个长度为N的word w的模式化为一个字符序列:w=(c1,c2,...,cN),ci表示这个word中的第i个字符,为10个数字和26个字母集合中的一个。一个word中的ci可以由一个分类器来预测。由于word的长度N是变化的,文中将N的最大值Nmax固定为训练集中最长的word长度(Nmax=23),同时引入了一个空字符类。由此,一个word可以表示为一个字符串:![]() 。
。
对于一个给定的输入图像x,返回预测的word w*,使![]() 最大化(Ps:这个P应该理解为一个可能性、概率或者准确度、整体置信度,指使预测的结果与输入图片尽可能贴近)。假设字符间是独立的,则有:
最大化(Ps:这个P应该理解为一个可能性、概率或者准确度、整体置信度,指使预测的结果与输入图片尽可能贴近)。假设字符间是独立的,则有:
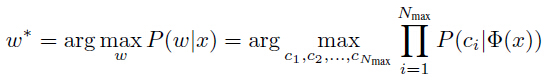 式(1)
式(1)
其中![]() (Ps:个人理解表示表示第i个字符的预测置信度)由作用一组于共享CNN特征
(Ps:个人理解表示表示第i个字符的预测置信度)由作用一组于共享CNN特征![]() 的第i个位置的分类器给定。word w*取每个位置最优可能的字符得到:
的第i个位置的分类器给定。word w*取每个位置最优可能的字符得到: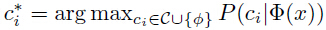 。(Ps:这两段的内容其实就是将字符序列模型的输入和输出结构使用数学公式进行量化表达。)
。(Ps:这两段的内容其实就是将字符序列模型的输入和输出结构使用数学公式进行量化表达。)
图1 展示了由CNN实现的字符序列模型(文中称这个模型为CHAR model)。word image归一化为统一大小(忽略长宽比),然后作为这个模型的输入。![]() 被输入到Nmax个独立的全连接层,每个字符类包含非字符。这些全连接层使用softmax正规化,可以表示为输入图像x的概率
被输入到Nmax个独立的全连接层,每个字符类包含非字符。这些全连接层使用softmax正规化,可以表示为输入图像x的概率![]() 。这个CNN使用多项逻辑回归损失(multinomial logistic regression loss)、反向传播(back-propagation)和随机梯度下降(stochastic gradient descent, SGD)来进行训练。
。这个CNN使用多项逻辑回归损失(multinomial logistic regression loss)、反向传播(back-propagation)和随机梯度下降(stochastic gradient descent, SGD)来进行训练。
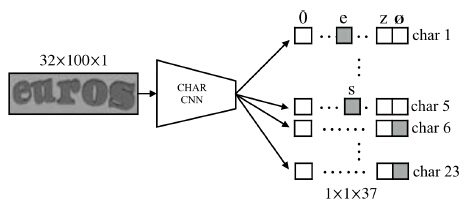
图1.字符序列模型。通过预测每个位置上的字符输出来识别一张word image,一次拼写出字符。
每个位置的分类器独自学习,但是共享一组联合优化的特征。
b.N元文法组合模型( Bag-of-N-gram Model)
这一张主要讨论了文中使用的第二个识别模型,它主要检测一个word的语义合成性(compositonality)。word可以看做是一组无需字符的N元文法组合,即bag-of-N-grams。
下面介绍一些基础知识:
i.若![]() 并且
并且![]() ,s、w为两个字符串,则
,s、w为两个字符串,则![]() 表示s为w的子串。
表示s为w的子串。
ii.一个word w的N元文法是指w长度为N的子串,即![]() ,并且s的长度
,并且s的长度![]() 。
。
iii.![]() 表示w长度小于等于N的子串的集合,即w长度小于等于N的所有N元文法的集合。例如:
表示w长度小于等于N的子串的集合,即w长度小于等于N的所有N元文法的集合。例如:![]() 。
。
iv.![]() 表示语言中所有类似文法的集合。
表示语言中所有类似文法的集合。
尽管N很小,![]() 可以近乎唯一地对每一个
可以近乎唯一地对每一个![]() 进行编码。例如,N=4时,在一个有90k个word的字典中仅有7个映射冲突。编码
进行编码。例如,N=4时,在一个有90k个word的字典中仅有7个映射冲突。编码![]() 可以表示为N元文法事件的 |
可以表示为N元文法事件的 |![]() | 维二值向量。这个向量十分分散,平均当
| 维二值向量。这个向量十分分散,平均当![]() 时,
时,![]() 。
。
使用CNN可以预测从一个输入图像x中获得的word w的![]() 。这个CNN的结构与上面的结构相似(如图2所示),但是最后的全连接层有
。这个CNN的结构与上面的结构相似(如图2所示),但是最后的全连接层有![]() 个神经元来表示编码向量。来自全连接层的的score可以表示为通过对每个神经元应用逻辑函数,一个N元文法的可能性。因此,CNN学习输入图像中每个N元文法的出现,所以是一个N元文法检测器。
个神经元来表示编码向量。来自全连接层的的score可以表示为通过对每个神经元应用逻辑函数,一个N元文法的可能性。因此,CNN学习输入图像中每个N元文法的出现,所以是一个N元文法检测器。
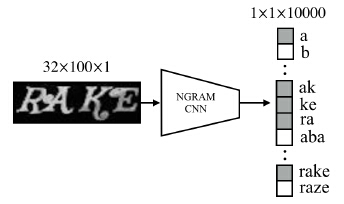
图2.N元文法编码模型。被识别的文本被表示为它的N元文法的组合(bag-of-N-grams)。
可以将其视为10k个使用共享联合学习特征集合的独立训练的二值分类器,训练用以检测某个特定N元文法的出现。
通过使用逻辑函数,训练问题转化为 |![]() | 个二值分类问题,各自反向传播与每个N元文法类相关的逻辑回归损失。为了整体训练整个变化范围的N元文法(一些出现很频繁,一些出现次数极少),反转训练word语料库中每个N元语法类出现的频率来scale它们的梯度。
| 个二值分类问题,各自反向传播与每个N元文法类相关的逻辑回归损失。为了整体训练整个变化范围的N元文法(一些出现很频繁,一些出现次数极少),反转训练word语料库中每个N元语法类出现的频率来scale它们的梯度。
在这个模型中,在所有可能的N元文法建模空间中选取 |![]() |个N元文法自己进行内在语言的统计。这可以看做是用一个语言模型来对编码表示空间进行压缩,但是不会限制非限制识别的预测能力。
|个N元文法自己进行内在语言的统计。这可以看做是用一个语言模型来对编码表示空间进行压缩,但是不会限制非限制识别的预测能力。![]() 大多数时候总是对应于自然语言中唯一的worlds,非言语words总是包含极少数的
大多数时候总是对应于自然语言中唯一的worlds,非言语words总是包含极少数的![]() 模型集合中的N元文法,会产生大量非唯一的编码。
模型集合中的N元文法,会产生大量非唯一的编码。
(2)组合模型(Joint Model)
最大化一个字符序列的后验概率(posterior probability)(式(1))等价于最大化log-score![]() ,其中
,其中![]() 表示序列中第i个字符的后验概率的对数。与这个函数相关的图表是点的集合,每一个为一元条目
表示序列中第i个字符的后验概率的对数。与这个函数相关的图表是点的集合,每一个为一元条目![]() ,不包含任何边。因此最大化这个函数即单独最大化每一个条目。
,不包含任何边。因此最大化这个函数即单独最大化每一个条目。
在此,对这个模型进行扩展,使之与N元文法也测器想结合,编码一张word image x中出现的N元文法。N元文法计分函数![]() 给每个长度小于N的字符串s分配一个score,N是N元文法建模的最大值。注意,与前面定义的
给每个长度小于N的字符串s分配一个score,N是N元文法建模的最大值。注意,与前面定义的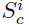 不同的是,
不同的是,![]() 与位置无关。但是,它重复应用于一个word中的每个位置i。
与位置无关。但是,它重复应用于一个word中的每个位置i。
 式(2)
式(2)
如图3所示,![]() 从CNN字符预测器(CNN character predictor)获得,
从CNN字符预测器(CNN character predictor)获得,![]() 由CNN N元文法预测器获得。注意:N元文法计分函数仅对CNN建模的N元文法子集
由CNN N元文法预测器获得。注意:N元文法计分函数仅对CNN建模的N元文法子集![]() 进行定义,若
进行定义,若![]() ,则socre
,则socre![]() =0。
=0。
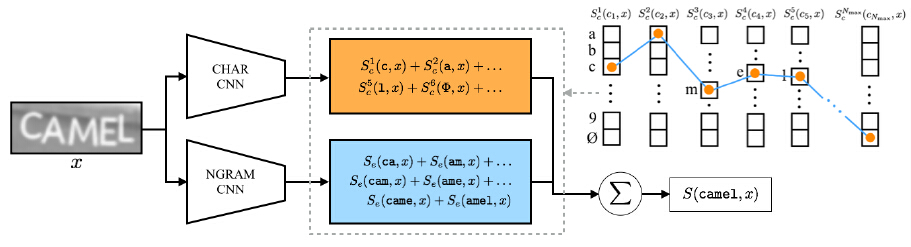
图3.word camel的路径score S(camel,x)的构造说明。用于score的一元及边条目由穿过字符位置图的路径选择,如右上角所示。
这些条目的值,![]() 和
和![]() ,其中
,其中 ,由字符序列CNN(CHAR CNN)和N元文法编码CNN(NGRAM CNN)的输出给定。
,由字符序列CNN(CHAR CNN)和N元文法编码CNN(NGRAM CNN)的输出给定。
与函数(2)相关的图与序列N相关。因此,当N适度大小,采用定向搜索来最大化(2),然后找到预测world w*.
结构化输出损失(Structured Output Loss)。一元运算和边的评分函数![]() 和
和![]() 应该分别与字符序列模型和N元文法编码模型的输出相结合。一种简单的方式是在移除softmax规范化和逻辑损失后,对CNN的输出进行加权:
应该分别与字符序列模型和N元文法编码模型的输出相结合。一种简单的方式是在移除softmax规范化和逻辑损失后,对CNN的输出进行加权:
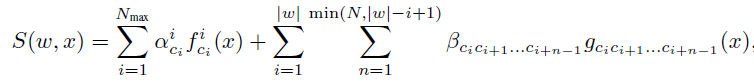 式(3)
式(3)
其中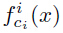 为字符序列CNN中第i个字符ci的输出,
为字符序列CNN中第i个字符ci的输出,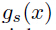 是N元文法编码CNN的N元文法s的输出。如果需要,可以约束字符权重
是N元文法编码CNN的N元文法s的输出。如果需要,可以约束字符权重 和边权重
和边权重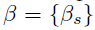 在不同字符、字符位置、相同顺序不同文法或所有N元文法间共享。
在不同字符、字符位置、相同顺序不同文法或所有N元文法间共享。
式(3)中权重α、β集合,或者式(3)中限制权重的变体,可以在结构化输出学习框架中学习,使得真是word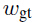 (ground-truth word)的得分大于等于最高错误预测word的得分加上一个边缘,即:
(ground-truth word)的得分大于等于最高错误预测word的得分加上一个边缘,即: ,其中
,其中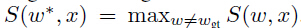 。使之在严凸损失(convex loss)中作为一个轻约束:
。使之在严凸损失(convex loss)中作为一个轻约束:
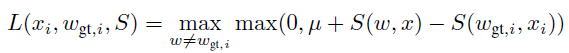 式(4)
式(4)
并且,在调整的经验风险对象中求M个样本对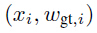 结果的平均值:
结果的平均值:
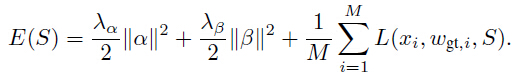 式(5)
式(5)
然而,在式(3)的大多数情况中,权重可以与CNN函数f和g相结合,作用于score:
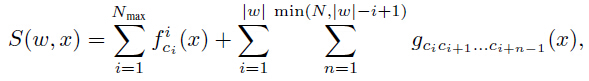 式(6)
式(6)
函数f和g由CNN定义,因此可以优化它们的参数来降低式(5)的损失,。这里可以简单使用标准的反向传播和SGD来实现。S相关的差异化损失L给出:
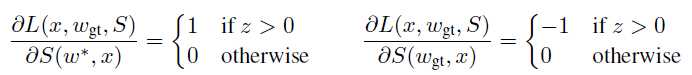 式(7)
式(7)
其中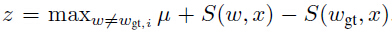 。字符序列模型及N元文法编码模型输出
。字符序列模型及N元文法编码模型输出 和
和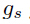 相关的差异化评分函数公式(6)给出:
相关的差异化评分函数公式(6)给出:
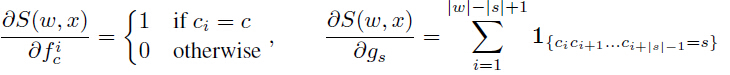 式(8)
式(8)
这允许错误被反向传播到整个网络。
使用结构化输出损失可以使整个模型的参数在式(6)提出的的结构中联合最优化。图4展示了所使用的训练结构。由于式(6)中的高阶得分,使得穷尽遍历所有可能的路径空间来找到w*代价巨大,即使使用动态规划,因此使用定向搜索来找到近似得分最高的路径。

图4.联合模型的训练结构,将字符序列模型(CHAR)和N元文法编码模型(NGRAM)与结构化输出损失相结合。
路径选择层(Path Selecet Layer)通过对输入的ground-truth word求和来生成score  。
。
定向搜索层(Beam Search Layer)通过定向搜索来从输入中选择最大的score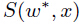 。
。
hinge loss实现了一个ranking loss,限制最高得分路径为ground-truth路径,可以反向传播到整个网络来联合学习所有参数
3.实验及结果
(1)数据集:ICDAR 2003、ICDAR 2013、Street View Text、IIIT 5K-word、Synth90k
(2)实现细节
用CHAR来表示字符序列模型,用NGRAM来表示N元文法编码模型,组合模型表示为JOINT。
CHAR和NGRAM具有相同的base CNN结构。这个base CNN有5个卷积层和2个全连接层 。word image归一化为32*100的灰度图像(忽略长宽比),然后作为这个模型的输入。除了最后一层,其他每一层都使用了激活函数(Rectified linear units)。卷积层一次有64、128、256、512、512个square filter,滑窗的边的大小依次为5、5、3、3、3。卷积滑动的步长为1,并且通过填充输入特征图来保护空间维度。2*2 的max-pooling层跟在第1、2、3层卷积层之后。全连接层有4096个单元。在这个base CNN的顶端,这个CHAR model有23个独立的带有37个单元的全连接层,允许识别最长为Nmax=23个字符的word。NGRAM模型在10k个频繁出现的(在Synth9k word语料库中至少出现10次,包含36个一元文法,522个二院文法,3965个三元文法,以及5477个四元文法)、N小于等于4的N元文法中执行选择操作。要求base CNN最后的全连接层具有10k个单元。在训练时定向搜索宽度为5,在测试时为10。如果使用一个lexicon来约束输出,而不是使用定向搜索,与lexion word相关的路径使用式(6)来评分,具有最高评分的word作为最终的结果。
这三个模型都使用SDG和dropout regularisation来进行训练。JOINT由训练好的CHAR和NGRA网络权值来初始化,并且卷积层权在训练时不变(文中用了frozen这个词,不知这样理解对不对)。
(3)实验及结果
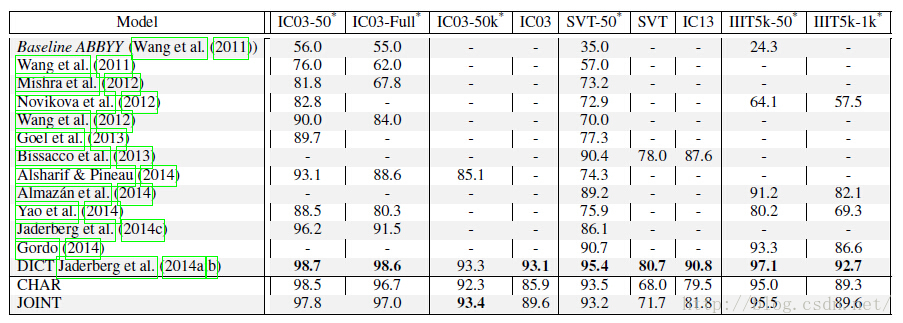
a.CHAR及JOINT识别准确率

b.本文中的方法与相关论文中的方法的对比
以上是关于论文笔记Deep Structured Output Learning for Unconstrained Text Recognition的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记Deep Structured Output Learning for Unconstrained Text Recognition
DSSM 阅读 - Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
DSSM 阅读 - Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
论文笔记:Matrix Completion in the Unit Hypercube via Structured Matrix Factorization
MapTR:Structured Modeling and Learning for Online Vectorized HD Map Construction——论文笔记
MapTR:Structured Modeling and Learning for Online Vectorized HD Map Construction——论文笔记