DSSM 阅读 - Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DSSM 阅读 - Learning Deep Structured Semantic Models for Web Search using Clickthrough Data相关的知识,希望对你有一定的参考价值。
论文发布于2013
摘要
通过深度网络将 query 和 document 映射到相同的低维空间,在该空间中, document 和给定的 query 的相似度可以通过他们之间的距离给出。所提出的深度结构化语义模型( deep structured semantic model )使用点击数据训练,训练的目标是给定 query 下最大化 clicked document 条件概率。为了适用大规模 web 搜索场景,采用了 word hashing ,使得模型能够应对实际任务中存在的大规模词表的情况。
引言
诸如 LSA 的隐语义模型可以将 query 在语义的层面上匹配 document,而基于关键词匹配的方法在很多情况下会失效。隐语义模型通过将出现在相似 context 的不同的 terms 聚合到同一个语义集群来处理 query 和 document 的语义鸿沟。隐语义模型将 query 和 document 表示为低维空间中的两个向量,这样即使 query 和 document 没有相同的 terms ,依旧可能在低维空间有较高的相似性。诸如 LSA 、 PLSA 和 LDA 均是这一类模型。然而,这些模型经常使用无监督方式进行训练,训练的目标函数和检索任务的评价指标是松耦合的。因此,在web搜索任务中这些模型的效果没有最初预期的好。
针对上述情况有两个方向来拓展隐语义模型,使用点击数据 & 采用深度学习。
第一个,训练数据采用由一系列 queries 和对应的 clicked documents 组成的点击数据,以此消除 queries 和 documents 的语义鸿沟。例如, Gao 等人在[10]中提出使用双语主题模型( BLTMs )和线性判别映射模型( DPMs )在语义级别上进行 query-document 匹配。这些模型在点击数据上使用适合文档排序任务的目标进行训练。尽管使用点击数据来训练 BLTM,但其目标函数是最大化对数极大似然,这对于文档排序任务中的评估指标而言不是最优的。另一方面,DPM的训练涉及大规模的矩阵乘法。矩阵大小通常会随着词汇量的增加而迅速增长,在web搜索任务中,这可能是百万级别的量。为了使训练时间可接受,需要对词汇进行大幅度修剪。词汇量减少,使得模型易于训练,但会导致性能欠佳。
第二个, Salakhutdinov 和 Hinton 使用深度自动编码器扩展了语义模型。他们证明了可以通过深度学习提取嵌入在query和document中的分层语义结构。这个性能优于常规的LSA[22]。然而,他们使用的深度学习方法仍采用无监督学习方法,其中模型参数优化是为了 documents 的重建,而不是给定 query 下区分相关的 documents 和不相关的 documents 。因此,深度学习模型并没有显著优于基于关键字匹配的基线检索模型。此外, semantic hashing model 同样面临大规模矩阵乘法的可可扩展性挑战。我们将在本文中证明,学习具有大量词汇的语义模型的能力对于在真实世界的web搜索任务中获得良好的结果是至关重要的。
模型架构
用 DNN 来提取语义特征

将高维稀疏的文本特征转换成语意空间中地位稠密的特征。其输入是未进行截断的原始输入(很多模型为了控制计算成本,会只截取高频 term 以减少词汇量),第一个隐层用3万个神经元( 线性即不含激活函数)来进行 word hashing ( 见式3的  ),再经过多层非线性映射 ( MLP,
),再经过多层非线性映射 ( MLP,  ),最后一层(
),最后一层( 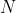 )的输出就是语义空间的特征。一共两个步骤:1)将 term vectors 映射到语意空间;2)计算 query 和 document 的语义相似度,用它们在语义空间中的对应向量的余弦相似度表示。
)的输出就是语义空间的特征。一共两个步骤:1)将 term vectors 映射到语意空间;2)计算 query 和 document 的语义相似度,用它们在语义空间中的对应向量的余弦相似度表示。
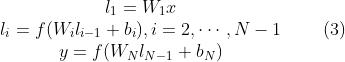
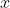 为输入向量,
为输入向量,  为输出向量,
为输出向量, 是激活函数,文中用的是 tanh 。
是激活函数,文中用的是 tanh 。
query 和 document 的语义相似度如下:
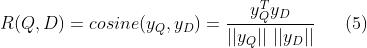
在 web 搜索的场景中,给定 query ,documents 按照它们的语义相似度排序。
通常, term vector 的维度与词表的大小是相同的。在实际的 Web 搜索任务中,词汇表通常非常大。因此,当使用 term vector 作为输入时,神经网络的输入层的大小对于推理和模型训练来说是巨大的。为了处理该问题,在第一层采用 word hashing ,这一层仅仅由线性隐藏单元组成,其权重矩阵比较大,但无需学习 ( 即 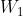 无需学习),具体的在下一小节介绍。
无需学习),具体的在下一小节介绍。
Word Hashing
word hashing 方法旨在减少 term vector 的维度。它是基于字母( letter )的 n-gram 算法,是专门针对我们任务开发的一种新方法。给定一个单词(如 good ), 我们首先添加单词的开头和结尾标识(如 #good# )。然后,我们按照字母的 n-gram 拆分单词(如 tri-grams :#go , goo , ood , od# )。最后,使用字母 n-grams的向量表示这个单词。
该方法的一个问题是冲突,即两个不同的单词可能具有相同的字母 n-gram 向量表示。表1展示了两个词汇表中 word hashing 的一些统计信息。对比原始 one-hot 向量的大小, word hashing 允许我们使用更低维的向量表示 query 和 document 。以4万的词汇表为例,使用字母 tri-gram ,每个单词可以使用 10306 维向量表示,在少量冲突的情况下,维度是原先的 1/4 。应用于较大的词汇表时,维度的减少更为显着。如表1所示,在50万的词汇表中,使用字母 tri-gram ,每个单词可以表示为 30621 维向量,在可忽略的冲突率为 0.0044%(22 / 500000)的情况下维度是原先的 1/16 。

虽然英语单词的数量是很大的,但在英语(或其他相似的语言)中字母 n-grams 的个数是有限的。此外, word hashing 能够将同一单词的形态变化映射到字母 n-gram 空间中彼此接近的点。更重要的是,基于单词表示的方法在遇到训练集中未出现的词时无法很好的表达,但基于字母 n-gram 表示时这就不是问题了。唯一的风险是如图1 所示的轻微冲突。因此,基于字母 n-gram 的 word hashing 处理对于 out-of-vocabulary 问题具有鲁棒性。这使我们能够将DNN解决方案扩展到具有超大词汇表的Web搜索任务中。我们将在第4节中介绍该技术的优势。
在我们的实现中,基于字母 n-gram 的 word hashing 可以看成是一个固定的(即非自适应)线性变换,通过该变换,输入层 term 向量可以映射到下一层的字母 n-gram 向量中,如图1所示。由于字母 n-gram 向量的维度低得多,因此可以有效地进行 DNN 学习。
损失函数
点击日志由一系列 queries 和它们被点击的 documents 组成。我们假设一个 query 和因为它被点击的 documents 是相关至少部分相关的。提出了一种有监督的训练方法,来学习模型参数,使得给定 queries 的情况下被点击 documents 的条件似然概率最大化。
首先,我们通过 softmax 函数计算给定 query 的情况下 document 的后验概率,该概率来自于它们之间的语义相似度

其中  是根据经验设置的 softmax 函数的平滑因子。
是根据经验设置的 softmax 函数的平滑因子。 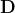 表示待排序 documents 候选集。理想情况, 应该包含所有可能的 documents 。实际上,若将每个(query,clicked-document)对,表示成
表示待排序 documents 候选集。理想情况, 应该包含所有可能的 documents 。实际上,若将每个(query,clicked-document)对,表示成 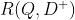 ,其中, Q 表示 query ,
,其中, Q 表示 query ,  表示被点击的 document ,我们用 和四个随机选择的未点击 document (表示为
表示被点击的 document ,我们用 和四个随机选择的未点击 document (表示为  )来表示 。在我们初步研究中,通过不同的采样策略选择未点击的 document 并没有什么不同。
)来表示 。在我们初步研究中,通过不同的采样策略选择未点击的 document 并没有什么不同。
在训练过程中,期望寻找到参数使得给定 query 的情况下最大化被点击 documents 的似然概率估计。相当于最小化损失函数(交叉熵损失),如下所示:
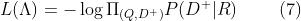
以上是关于DSSM 阅读 - Learning Deep Structured Semantic Models for Web Search using Clickthrough Data的主要内容,如果未能解决你的问题,请参考以下文章
深度学习阅读列表 Deep Learning Reading List
推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)
推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)
推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)