DSSM框架(Deep Structured Semantic Model):深度学习计算语义相似度
Posted 算法程序媛成长记录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DSSM框架(Deep Structured Semantic Model):深度学习计算语义相似度相关的知识,希望对你有一定的参考价值。
文章:
Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]// ACM International Conference on Conference on Information & Knowledge Management. ACM, 2013:2333-2338.
两篇写得很好的博客,有助于理解:
https://cloud.tencent.com/developer/article/1005600
http://kubicode.me/2017/04/21/Deep%20Learning/Study-With-Deep-Structured-Semantic-Model/
有个博主自己写的代码:
https://github.com/InsaneLife/dssm
文章理解起来并不难,对于没有NLP基础的读者比较友好。主要是设计了一个深度网络结构来计算文本之间的相似度。这几篇博客对文章讲解得很详细了,我就简单写一下自己对这篇文章的理解,以及我在看文章以及看这两篇博客的时候觉得写得不是很清楚的地方吧。
1.背景
文章主要目的是利用点击数据作为监督信息,对query和doc在语义层面的匹配上进行模型的训练。训练完成后,输入一条query文本,可以根据DSSM模型计算这条query与各个doc文件的相似度,得到的相似度最接近语义层面的相似。
它的原理很简单,就是把用one-hot方式生成的高维词向量,通过设计的DNN模型降维,生成低维语义向量,并用cosine距离来衡量两个语义向量之间的相似度,通过曝光点击日志来作为监督信息,训练出语义相似度模型。主要创新点在于输入层word hashing层的设计,其余网络结构与普通DNN网络结构一致。
相信有NLP基础知识的读者可能对上面的很多术语很熟悉,但是作为刚接触自然语言处理的新人来说,对上面的很多词汇并不了解,所以我在这里为和我一样的新人同学们介绍一下这里面的一些术语是什么意思。ps:我介绍的是我自己在读文章和博客时不太清楚的词,如果介绍不全面或者觉得太浅显还请见谅~
(1)怎样用曝光点击日志来当做监督信息:即通过用户是否点击来作为query和title(doc)是否相似的标签。
(2)one-hot:直观来说就是有多少个状态就有多少比特,而且只有一个比特为1,其他全为0的一种码制。在词向量生成中,数据库中有多少种不同的词就有多少位,所以通常词向量的维度都很高。
2.网络结构
文章中的网络结构如图所示:
可以看出,网络主要分为三个模块,输入层、表示层和匹配层。
输入高维原始向量,通过一个word hash层以及数个隐藏层,最后输出一个低维语义向量。通过余弦距离计算低维语义向量之间相似性,用softmax把query和doc之间的相似度转化为后验概率。
2.1 输入层
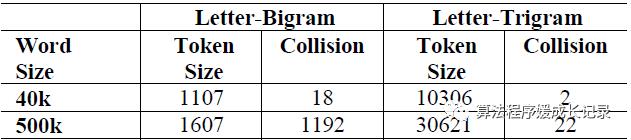
输入层负责把query和doc的句子转换成词向量的形式并输入到网络中。原始的生成向量的方式会导致数据空间太大,例如,假如所有的句子一共包涵50万个不同的词汇,就需要50万维的向量来表示每一条句子,这样计算量太大,时间和空间花费都无法接受。于是文章中提出一种叫做n-gram的分词方式。简单来说,就是把一个词汇,前后加一个指示符,如good,加前后标志后变成#good#,如果是trigram(也就是三个字母的分词方式),那么这个词就有#go,goo,ood,od#这几种形式。由于分词后三个字符一组,大大减少了词汇的多样性,就算是枚举,最多也就27*26*27种,文章中提到,三个字符一组的分词方式,对50万词汇可以降成三万多种类,而collision才22个,冲突的概率仅为0.0044%。这种冲突率是可以接受的。也就是说,通过这种方式,可以将50万维的向量降低成3万维。不过这种分词方式只适用于英文词汇,中文词汇由于单字远远不止26个,如果多字分割和按词分割相比区别不大,所以按照单字来降维。
2.2 表示层
DSSM的word hashing层采用bag-of-words的方式,也就是抛弃词汇之间的前后关系,只关心每种分词出现的次数。
接着是含有几层隐藏层的深度网络,用 Wi 表示第 i 层的权值矩阵,bi 表示第 i 层的 bias 项。则第一隐层向量 l1(300 维),第 i 个隐层向量 li(300 维),输出向量 y(128 维)可以分别表示为:
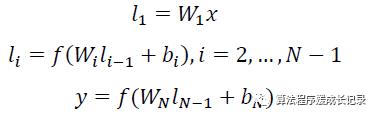
初始化权重为:
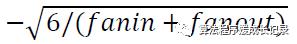 和
和
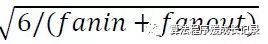 之间的随机数,fanin是上一层的unit数,fanout是下一层的unit数。
之间的随机数,fanin是上一层的unit数,fanout是下一层的unit数。
用tanh作为隐层和输出层的激活函数:
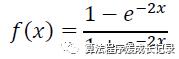
最后输出128维的向量。
2.3 匹配层
通过余弦距离计算query和doc之间的语义相似度:
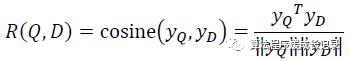
通过softmax函数把query和doc之间的相似度转换为一个后验概率:
其中 r 为 softmax 的平滑因子,D 为 Query 下的正样本,D-为 Query 下的负样本(采取随机负采样),D 为 Query 下的整个样本空间。
2.4 training训练
其中 r 为 softmax 的平滑因子,D 为 Query 下的正样本,D-为 Query 下的负样本(采取随机负采样),D 为 Query 下的整个样本空间。
残差会在表示层的 DNN 中反向传播,最终通过随机梯度下降(SGD)使模型收敛,得到各网络层的参数{Wi,bi}。
3. 优势与不足
这里我就直接贴博客里总结的了:
https://cloud.tencent.com/developer/article/1005600
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:上文提到 DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
http://kubicode.me/2017/04/21/Deep%20Learning/Study-With-Deep-Structured-Semantic-Model/
DSSM类的模型其实在计算相似度的时候最后一步除了使用Cosine,可能再接入一个MLP会更加好,因为Cosine是完全无参的。
DSSM的优势:
DSSM看起来在真实检索场景下可行性很高,一方面是直接使用了用户天然的点击数据,出来的结果可行度很高,另一方面文中的doc可以使用title来表示,同时这个部分都是可以离线进行语义向量计算的,然后最终query和doc的语义相似性也是相当诱人DSSM出的结果不仅可以直接排序,还可以拿中间见过做文章:semantic feature可以天然的作为word embedding嘛
DSSM的劣势:
用户信息较难加入(不过可以基于
MVDSSM改造)貌似训练时间很长啊
4. 总结
后续还可以再介绍CNN-DSSM和LSTM-DSSM以及MV-DSSM等模型,这些模型对DSSM进行了一些改进,弥补了一些不足。
欢迎大家找po主交流~最近在看DSSM的代码,发现自己有好多不会的东西。。。以前光看文章搞理论了,工程上的东西还是有太多需要恶补的了,现在发现,彻底理解一个算法,最好的方法就是用它,比单纯的看文章获得的理解会深入很多。不过这方面还是需要补课~以前看看文档就觉得学会各种工具了,现在发现too young too naive,各种工程上的trick不了解的太多了。
接下来可能会分享一些自己的工程上的学习心得和以前看过的一些图像方面的文章吧。感觉当初看的文章都快忘完了。。。好记性不如烂笔头,读文章学东西做笔记真的很重要的哇~
各位程序猿程序媛程序员大家一起加油~
以上是关于DSSM框架(Deep Structured Semantic Model):深度学习计算语义相似度的主要内容,如果未能解决你的问题,请参考以下文章