论文笔记:Matrix Completion in the Unit Hypercube via Structured Matrix Factorization
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Matrix Completion in the Unit Hypercube via Structured Matrix Factorization相关的知识,希望对你有一定的参考价值。
2019 IJCAI
0 摘要
复杂任务可以通过将它们映射到矩阵完成(matrix completion)问题来简化。在本文中,我们解决了我们公司面临的一个关键挑战:预测艺术家在电影镜头中渲染视觉效果 (VFX) 的效率。我们通过使用双重方法来应对这一挑战:首先,我们将此任务转换为一个受约束的矩阵完成问题,其条目以单位间隔 [0, 1] 为界;其次,我们提出了两种新颖的矩阵分解模型,它们利用了我们对 VFX 环境的了解。我们的第一种方法,专业知识矩阵分解(EMF),是一种可解释的方法,将潜在因素构建为加权的用户-项目相互作用。第二个是生存矩阵分解 (SMF),它是一种概率模型,用于定义员工效率的基本过程。我们通过对我们的 VFX 数据集和两个附加数据集的广泛数值测试来展示我们提出的模型的有效性,这些数据集的值也在 [0, 1] 区间内。
1 introduction
出现在多个组织中的各种复杂应用程序可以转化为矩阵完成问题。在这项研究中,我们解决了我们公司面临的一个关键挑战:预测艺术家在电影镜头中渲染视觉效果 (VFX) 的效率。有效解决这个问题至关重要,因为项目经理经常依赖能力指标(例如员工的效率)来最好地控制和调整可用资产。
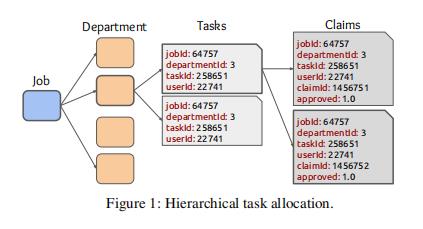
图 1 说明了 VFX 制作框架中艺术家(即员工)和工作分配之间的层级关系。在这里,组织的一项工作(job)是由不同部门(department)的一系列贡献组成,并且可能涉及众多员工(employee)。每个部门由一名经理(manager)领导,经理将她所在部门的工作划分为多个任务(task),每个任务分配给一个员工。员工从事这些任务并提交称为索赔(claim)的部分结果。在评估索赔的质量后,经理决定是否批准。因此,我们的目标是利用每位员工的潜在属性来解释他们在各种任务中的效率,以确保产品能够按时交付。
我们工作的主要贡献如下:
(i)将工业设置转换为稀疏实值矩阵,其中条目位于 [0, 1] 区间(例如,部门员工的效率)
(ii)提出两个 新颖的结构化矩阵分解(MF)模型,以有效解决由此产生的矩阵完成问题。
虽然我们的方法受到图 1 所示的分层任务分配的启发,但它们的公式非常通用,可以轻松应用于各种场景。 在本文中,我们特别考虑了另外两个应用:
(a) 向 OTT(over-the-top) 流媒体设备的用户推荐应用程序
(b) 在线广告投放中的推荐,以最大限度地提高点击率。 点击率。
这些应用程序的详细信息将在后面的部分中解释。
尽管传统的矩阵分解算法已被证明可以有效解决矩阵补全问题,但最近的研究表明,受约束的 MF 技术在各种数据集上都优于它们,包括 MovieLens、Jester 和 BookCrossing [Fang et al., 2017; Jawanpuria 和 Mishra,2018 年]。
此外,随着矩阵稀疏性的增加,MF 方法往往会产生不稳定和超出范围的预测 [Jiang et al., 2018]。
虽然大多数推荐系统的条目都在一系列可能的评分值范围内(例如,五星级评分系统中的 1 到 5 个),但我们的数据位于单位区间 [0, 1] 上。
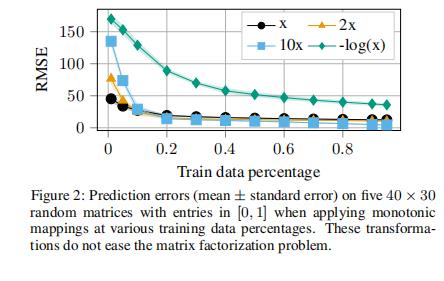
虽然我们可以将数据转换为序数空间,例如 1 到 5 之间的评级,但如图 2 所示,任何将单位区间映射到更大区间的单调变换都不会简化预测问题。
因此,我们针对这种情况提出了两种新方法:
a)专业知识矩阵分解(EMF),其中条目通过用户和项目潜在因素(即低秩特征)之间的加权相关性来近似,
b) 生存矩阵分解( SMF),它使用概率模型通过对导致部门员工平均效率的过程进行建模来捕获潜在因素。
我们的两种方法都是结构化矩阵分解方法,其约束是通过对所呈现的设置进行建模而得出的。
2 related work
资源分配是业务流程管理中提高组织绩效的一个相关问题 [Dumas et al., 2013]。最近,已经提出了流程挖掘中的不同方法 [Van Der Aalst, 2011],以从历史数据中提取有用的知识 [Arias et al., 2018]。然而,之前的研究集中在特定的过程案例[Huang et al., 2012; Conforti 等人,2015]。作为回应,我们研究了一个可以映射到各种组织的通用框架。
我们提出的方法的灵感来自于一系列关于低秩矩阵补全的工作,以及它们在推荐系统中的应用[Hu et al., 2008; Candes and Recht, 2009; ` Candes and Plan, 2010; Koren ` et al., 2009; Funk, 2011; Jain et al., 2013].。 适合我们任务的一类方法包括有界矩阵分解方法。非负矩阵分解 (NMF) 是此类中最流行的方法,它只为预测值提供 0 的下限。有界矩阵分解 (BMF) [Kannan et al., 2014] 给出了一种更通用的方法:一种低秩近似,它利用了推荐系统中的所有评级都在一个范围  范围内这一事实。
范围内这一事实。
我们提出的方法,专业矩阵分解,与这些在潜在因素上具有额外结构的矩阵完成模型密切相关[Soni et al., 2016; Hoyer, 2004; Aharon et al., 2006; Kannan et al., 2014]。然而,我们的方法与它们的不同之处在于其独特的结构,由我们设置中的单位间隔约束给出。据我们所知,这种结构在现有的 MF 文献中并没有明确的数据处理。 隐式反馈数据的 MF 方法 [Hu et al., 2008; Johnson, 2014] 在相同的区间上工作,但主要区别在于仅依赖于二进制值的矩阵条目。
我们的第二种方法,生存矩阵分解,与概率矩阵分解方法有关 [Mnih 和 Salakhutdinov,2008; Salakhutdinov 和 Mnih,2008 年]。虽然他们还将矩阵条目解释为概率,但我们的方法在其制定过程中专门模拟了端到端的批准过程。
3 问题定义
如第 1 节所述,我们提出的模型受到图 1 中描述的框架的启发。该流程图受到 Technicolor 电影制作中工作分配的具体应用场景的启发,其中艺术家(员工)在各种电影镜头中渲染视觉效果。
尽管如此,这个框架非常通用,其他生产流程可以很容易地映射到这个设置中。 例如,如果一个组织以 100 分制记录员工在工作中的表现,则可以通过定义工作质量的阈值(例如,90/100)将每个分数映射到批准或拒绝一个claim。
考虑到工作分配场景,员工效率的自然能力指标是由接受的claim数量与部门员工提交的claim总数的比率给出。
接受的claim计入员工的整体表现。 如果被拒绝,员工会在他们认为符合要求的质量时提交新的claim。 claim被拒绝显然会导致整个组织的绩效损失,因为员工可能需要重新开始,或者经理可能决定指定另一名员工。
令
为部门 n 中员工 d 提出的claim总数,
表示部门 n 中员工 d 提出的第 i 个claim是被接受 (1) 还是被拒绝 (0)。
然后我们定义部门n中员工d的效率
,如下:
可以很轻易第发现

我们研究的目标是预测每个部门员工的效率。
我们通过建立一个效率矩阵 来应对这一挑战,其条目
来应对这一挑战,其条目  表示部门 n 中员工 d 的效率。 由于大多数员工在整个职业生涯中只在少数几个部门工作,因此该矩阵中只有少数条目(对应于观察指标集 Ω ⊂ [D] × [N])是已知的。 因此,我们预测员工效率的目标现在简化为预测 X 的缺失条目。
表示部门 n 中员工 d 的效率。 由于大多数员工在整个职业生涯中只在少数几个部门工作,因此该矩阵中只有少数条目(对应于观察指标集 Ω ⊂ [D] × [N])是已知的。 因此,我们预测员工效率的目标现在简化为预测 X 的缺失条目。
4 模型部分
4.1 expertise matrix factorization
在第一种方法中,我们将效率矩阵建模为低秩矩阵
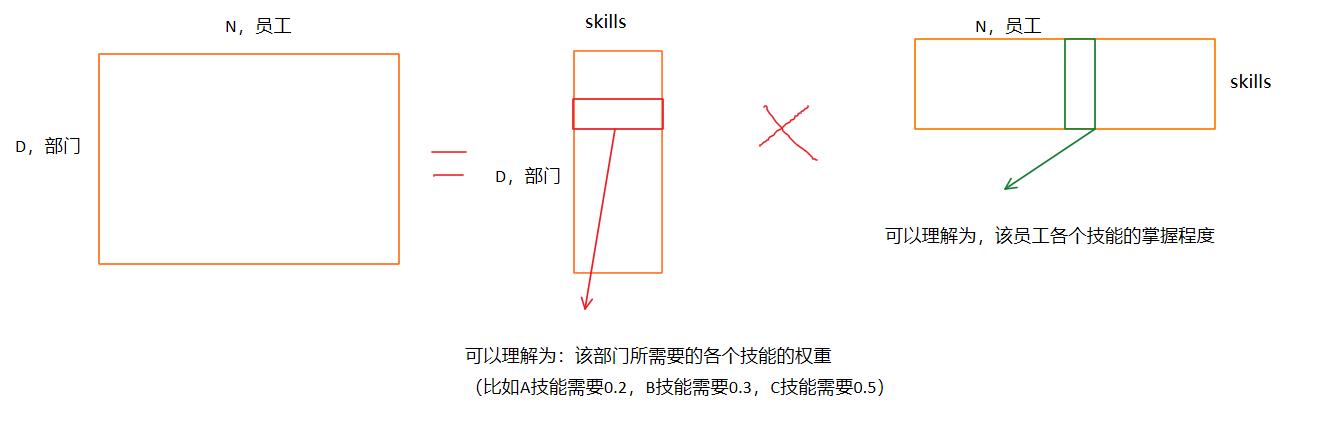
。 在我们的设置中,我们可以将潜在因素视为在给定部门工作所需的一组技能或专业知识。 特别是,我们假设每个员工的潜在因素(技能)在 0 到 1 的范围内,而每个部门的潜在因素是非负的并且总和为 1。一方面,员工在每项技能上都有一定的水平,其中 0表示没有能力,1表示熟练。 另一方面,假设每个部门都具有完成任务所需的各项技能的重要程度占比。
我们假设一个基于直觉推理的低秩模型,即可能需要少量技能来完成不同部门的任务。使用该模型,部门 n 中员工 d 的效率近似为员工技能的加权和,其中权重由部门中每种技能的重要性给出。 潜在向量中的结构确保该模型下的效率值位于 [0, 1] 内。
我们进一步扩展此模型以适应用户偏差,代表每个员工在每项技能上的最低熟练程度。 请注意,为部门添加的偏差项是不一致的,因为并非每种技能都应该在每个部门中都有用‘
最终的目标函数如下:

我们依靠基于交替最小化的算法来解决这个问题,首先求解 W 和 β,然后求解 Z。
4.2 Survival Matrix Factorization
在这种方法中,我们旨在为导致效率值的基础过程推导出概率模型
回想一下等式 (1),效率矩阵 X 中的每个条目
员工提交的每项claim都可以视为独立同分布。 可以看作来自伯努利随机变量
的样本,并且根据弱大数定律,矩阵项
介绍了这个概率框架后,为了定义 P(
claim代表员工交付给经理的工作,经理评估每个claim的质量并仅在它们足够好时接受它们。
首先,我们假设员工 d 以一定的质量分布向部门 n 提交索赔。 也就是说,每个索赔 i 都有相应的质量
,这是一个随机变量,它是从部门 n 中员工 d 所产生的工作质量的潜在概率分布中抽取的。
其次,我们通过单个参数 γn 对部门 n 的经理进行建模,表示他们的质量阈值:部门 n 的claim只有在其质量高于阈值时才被接受(如图 3 所示)。
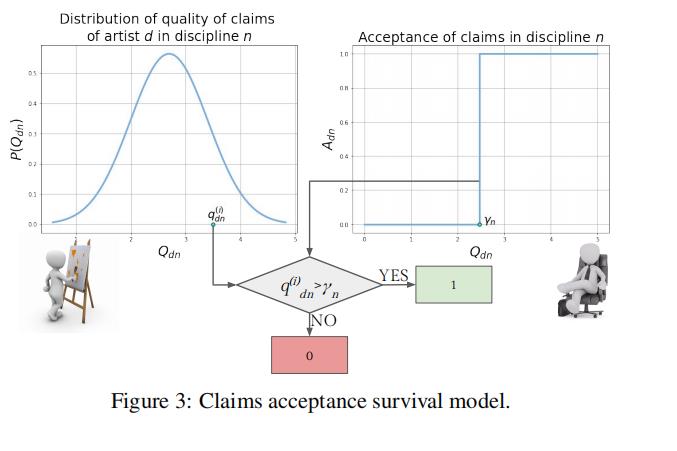
于是,每个
其中
是survival 函数,或者称之为互补累积分布函数,
是概率密度函数
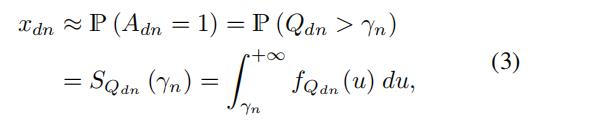
在本文中,我们假设员工的质量概率分布是正态的,并且所有员工和部门的claim质量方差相同:
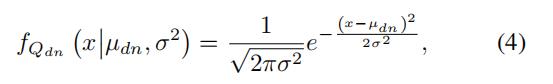
进一步,我们令
,于是有:
我们的目标函数问题是
上述问题中的目标函数在 W、Z、γ 和 σ 上是平滑的,可以使用随机梯度下降来解决。
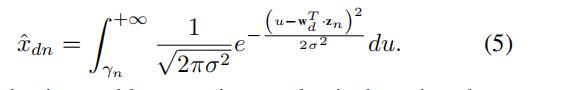
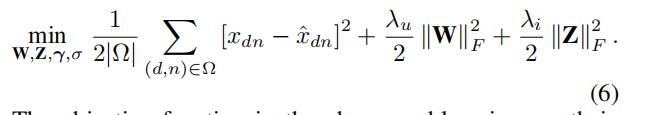
5 实验部分
5.0 数据集
在本节中,我们评估我们的模型在
(a) VFX 渲染数据集
(b) Technicolor 的 OTT 流数据集和
(c) 在线点击率 (CTR) 的公共数据集上。
5.1 方法
5.1.1 评估函数
推荐算法的质量可以使用不同类型的指标来评估。 我们使用 RMSE 和 MAE 作为统计准确度指标,而 Precision@N 和 Re call@N 作为决策支持指标,对于 N ∈ 2, 3, 5, 10。 在推荐系统的上下文中,我们通常对向用户推荐前 N 个项目感兴趣。 我们的框架显然也是如此,项目可以是员工、应用程序或网站类别。
5.1.2 training detail
我们使用了最多100个epoch,同时设置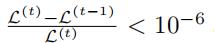 作为训练结束标记,其中
作为训练结束标记,其中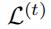 是时刻t的目标函数值
是时刻t的目标函数值
在SGD算法中,我们使用batch-size的大小为8(VFX数据集),128(OTT数据,CTR数据)
在 VFX 数据中的所有可能值上搜索潜在因子 K(W,Z的rank) 的最佳数量,而我们在较大的 OTT 和 CTR 数据中使用 K ∈ 10, 15, 20 的常见值。 每个矩阵因子用 (0, 1) 中的均匀随机数初始化,偏差初始化为零向量。
5.1.3 baseline & 论文提出的方法
- MF:有偏差的MF,使用SGD更新
- NMF :NMF 的交替非负最小二乘法。 每个块都通过投影梯度下降进行更新。
- BMF: 有界矩阵分解。 为了解决
 的限制,我们对随机初始化的W和Z 进行
的限制,我们对随机初始化的W和Z 进行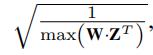 的规约
的规约 - PMF : 概率矩阵分解
- LMF : logistic 矩阵分解

- EMF:论文提出的方法1 Expertise matrix factorization.
- SMF:论文提出的方法2 Survival matrix factorization (方差σ设置为1)
5.2 电影数据
我们的分析是由 Technicolor 收集的数据驱动的,其中不同的学科(部门)负责在电影(工作)中生成 VFX,员工被称为艺术家。 所有数据都是根据适当的最终用户协议和隐私政策收集的。
我们的电影制作数据集由索赔记录组成,每个记录都有以下字段:jobId (int)、disciplineId (int)、taskId (int)、userId (int)、claimId (int)和approved (bool)。
为了确保每个平均效率都足以代表一个艺术家在一个学科中的真实效率,我们 删除由平均少于 10 个claim产生的所有条目。这也确保了根据 Hoeffding 定理 [Hoeffding, 1963],等式 (3) 中引入的近似值以高概率成立。
此外,为了缓解冷启动问题,我们删除了少于 10 个艺术家的声明的学科,并删除了少于 3 个非缺失条目的艺术家。
在这些预处理步骤结束时,我们剩下一个 312 × 25 矩阵和 1, 026 个非缺失条目。这个矩阵不仅非常稀疏(86.85%),而且每个用户的评分也很少,大多数艺术家只研究过三个学科。效率分布呈指数增长(图 4)。
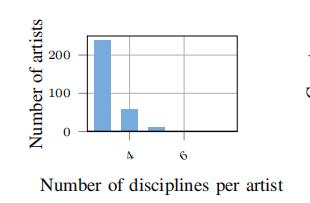
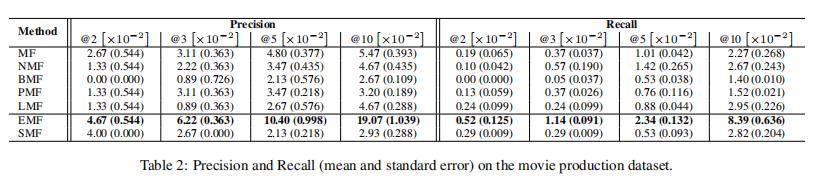
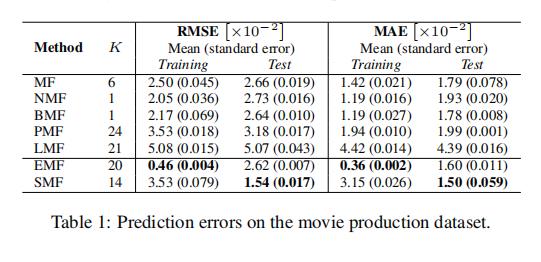
表 1 报告了该数据集上每种算法的预测误差。 精度和召回值列于表 2 中。
5.3 OTT 数据
我们的第二个应用程序包括在OTT设备上使用的应用程序,其目标是向客户推荐应用程序。 我们的 OTT 数据集包含任何用户对给定应用程序的查看次数。 该数据通过除以用户的最大观看次数映射到用户的观看率 ∈ [0, 1]。
与我们对 VFX 数据所做的类似,我们删除了观看人数少于 15 人的应用程序以及观看程序数少于 10 人的用户。 预处理后,我们剩下 934 个用户和 140 个应用程序和一个极其稀疏的矩阵(99.91%)。 表 3 和表 4 显示 K 分别等于 15 和 20 的精度和召回值。 由于空间限制,K = 10 的结果被省略,但遵循类似的模式。
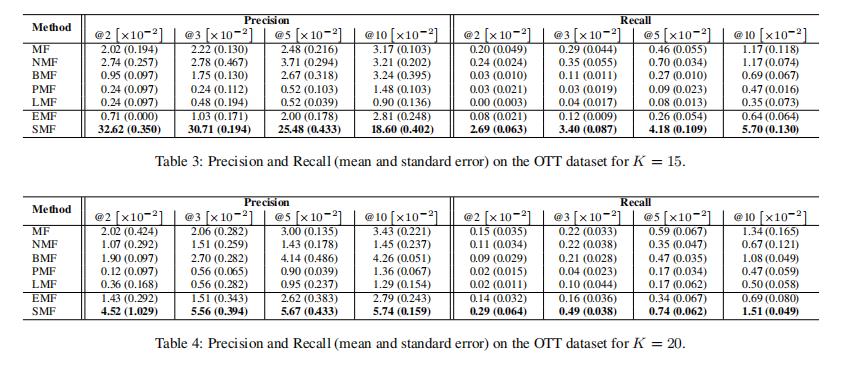
5.4 讨论
在我们的 VFX 数据中,SMF 实现了最低的预测误差,并且 EMF 在精度和召回率方面优于其他所有方法,其值是第二好的模型的三倍。 在这里,EMF 的假设与我们的 VFX 框架中的艺术家紧密匹配。
PMF 的最强点之一是它能够很好地为评分很少的用户进行泛化。 然而,在这里——每个用户的最大条目数仅为 7——我们看到 EMF 在预测准确性和推荐质量方面都优于 PMF。
以上是关于论文笔记:Matrix Completion in the Unit Hypercube via Structured Matrix Factorization的主要内容,如果未能解决你的问题,请参考以下文章