scrapy初探之爬取武sir首页博客
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy初探之爬取武sir首页博客相关的知识,希望对你有一定的参考价值。
一、爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
二、scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
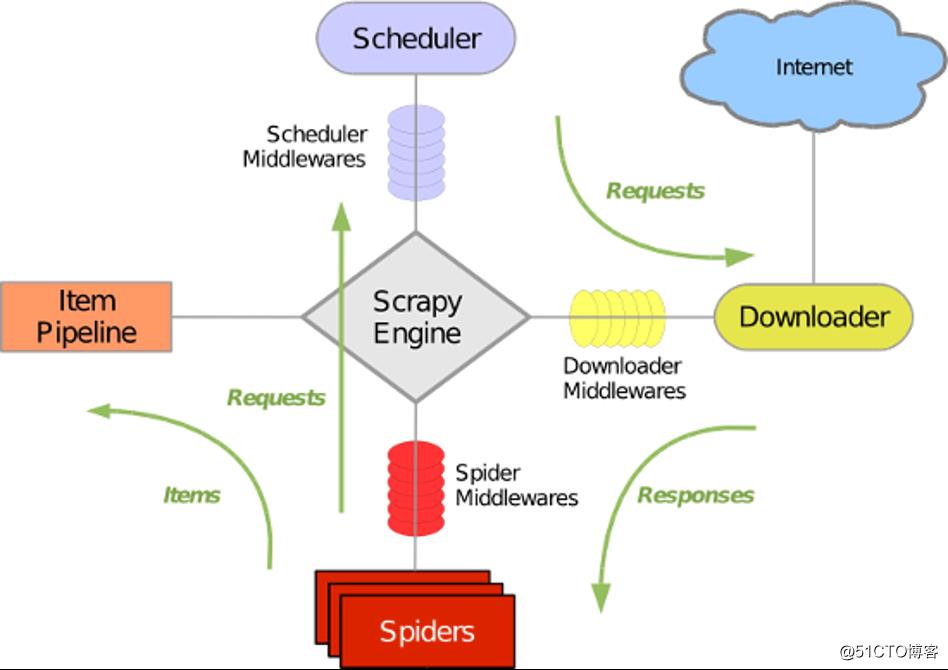
Scrapy主要包括了以下组件:
1、引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心)
2、调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
4、爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
5、项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6、下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7、 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
8、调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
三、scrapy实例
1、安装
在windows平台安装需要pywin32或64 的支持
Anaconda:一个python的大集合包,可安装爬虫相关的包
Anaconda下载地址:
http://continuum.io/downloads
安装过程中直接安装vscode,自行加入环境变量中
安装Scrapy:conda install scrapy
2、实例
1.创建项目(命令行cd至项目目录)
scrapy startproject cnblog
2.自动创建目录:
cnblog/
scrapy.cfg
cnblog/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py文件说明:
○ scrapy.cfg ?项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
○ items.py ? ?设置数据存储模板,用于结构化数据,如:Django的Model
○ pipelines ? ?数据处理行为,如:一般结构化的数据持久化
○ settings.py 配置文件,如:递归的层数、并发数,延迟下载等
○ spiders ? ? ?爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名3.定义要爬取的字段(item.py)
import scrapy
class CnblogItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#博客名
name = scrapy.Field()
#博客链接
data = scrapy.Field()
#博客日期
time = scrapy.Field()4.写爬虫
在spiders目录下创建cnblog.py文件
import scrapy
from cnblog.items import CnblogItem
class CNBlogSpidle(scrapy.Spider):
# 这是爬虫的名字,全局唯一
name = "cnblog"
# 这是爬虫开始干活的地址,必须是一个可迭代对象
start_urls = [‘http://www.cnblogs.com/wupeiqi/‘]
# 爬虫收到上面的地址后,就会发送requests请求,在收到服务器返回的内容后,就将内容传递给parse函数。在这里我们重写函数,达到我们想要的功能
def parse(self, response):
for line in response.xpath(‘//div[@class="day"]‘): #筛选首页中的博客
item = CnblogItem()
item[‘name‘] = line.xpath(‘.//div[@class="postTitle"]/a/text()‘).extract() #获取博客名
item[‘data‘] = line.xpath(‘.//a/@href‘).extract()[1] #获取url
item[‘time‘] = line.xpath(‘.//div[@class="dayTitle"]/a/text()‘).extract() #获取日期
yield item #将item返回Scrapy中Response可以直接使用Xpath来解析数据,更多Xpath语法详见:http://www.w3school.com.cn/xpath/xpath_syntax.asp
筛选规则需要通过分析html写出。
5.处理爬虫返回的数据(pipelines.py)
import os
import urllib.request
class CnblogPipeline(object):
def process_item(self, item, spider):
#用request模块获取爬来的地址的博客
html = urllib.request.urlopen(item[‘data‘]).read()
#文件名拼接(item对象为列表形式,取出其字符串)
file_name = os.path.join(‘D:\Temp‘,item[‘name‘][0]+‘.html‘)
#保存博客(爬取的内容为二进制,wb写入)
with open(file_name,‘wb‘) as f:
f.write(html)6.配置文件(settiings.py)
BOT_NAME = ‘cnblog‘
SPIDER_MODULES = [‘cnblog.spiders‘]
NEWSPIDER_MODULE = ‘cnblog.spiders‘
# 设置请求头部
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;",
‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘
}
# 不检测robots.txt文件(因为Scrapy遵循了robots规则,如果你想要获取的页面在robots中被禁止了,Scrapy是会忽略掉)
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
‘cnblog.pipelines.CnblogPipeline‘: 300,
}7.执行爬虫
C:UsersLENOVOPycharmProjectsfullstack>cd cnblog
C:UsersLENOVOPycharmProjectsfullstackcnblog>scrapy crawl cnblog --nolog8.结果输出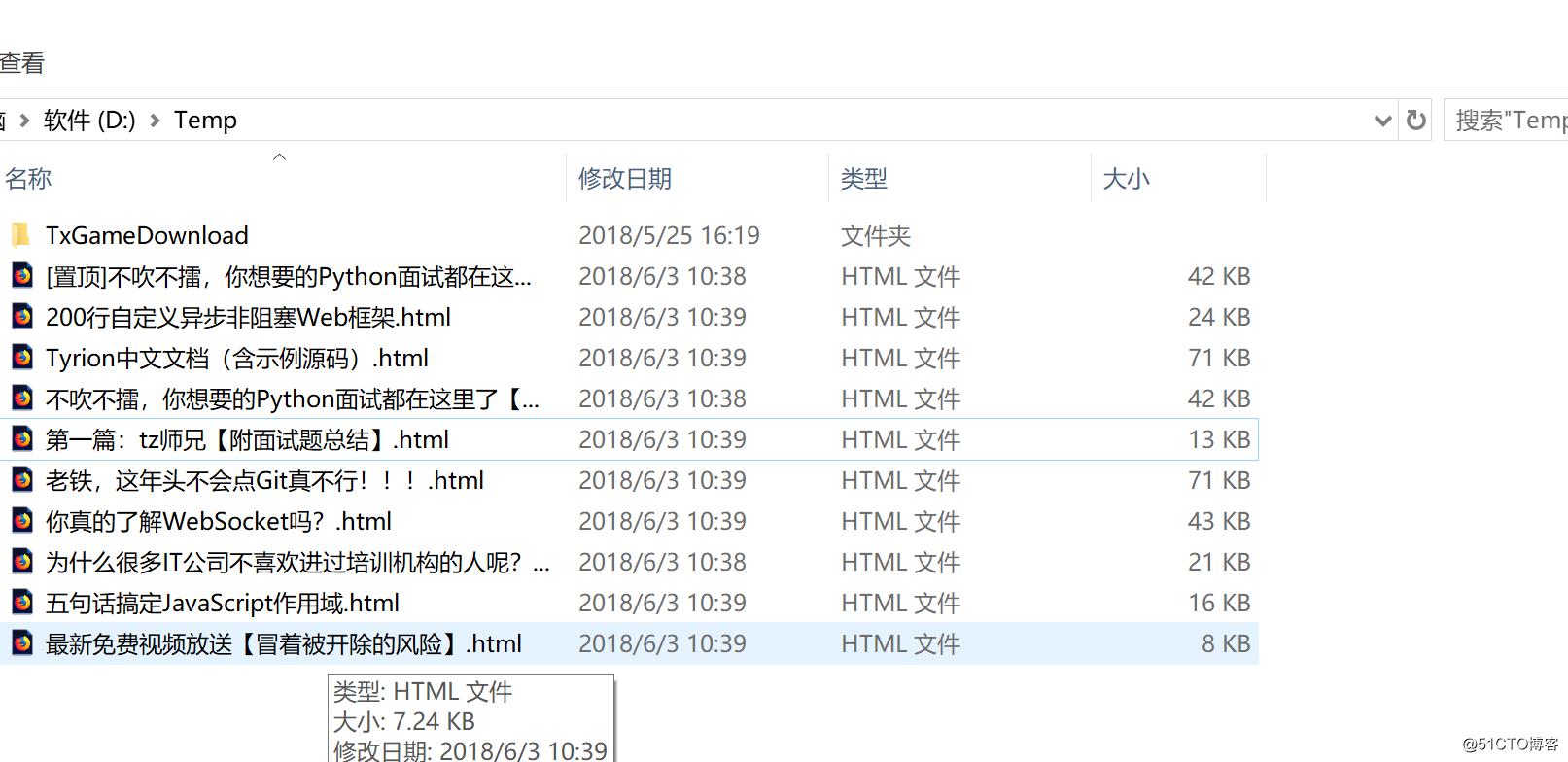
以上是关于scrapy初探之爬取武sir首页博客的主要内容,如果未能解决你的问题,请参考以下文章