Python爬虫之爬取B站首页热门推荐视频
Posted 汤米先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之爬取B站首页热门推荐视频相关的知识,希望对你有一定的参考价值。
前言
众所周知,b站上有很多视频资源,非常诱人,但是这些视频又不好下载,于是我就琢磨着爬取了一下b站首页的热门推荐视频。原理
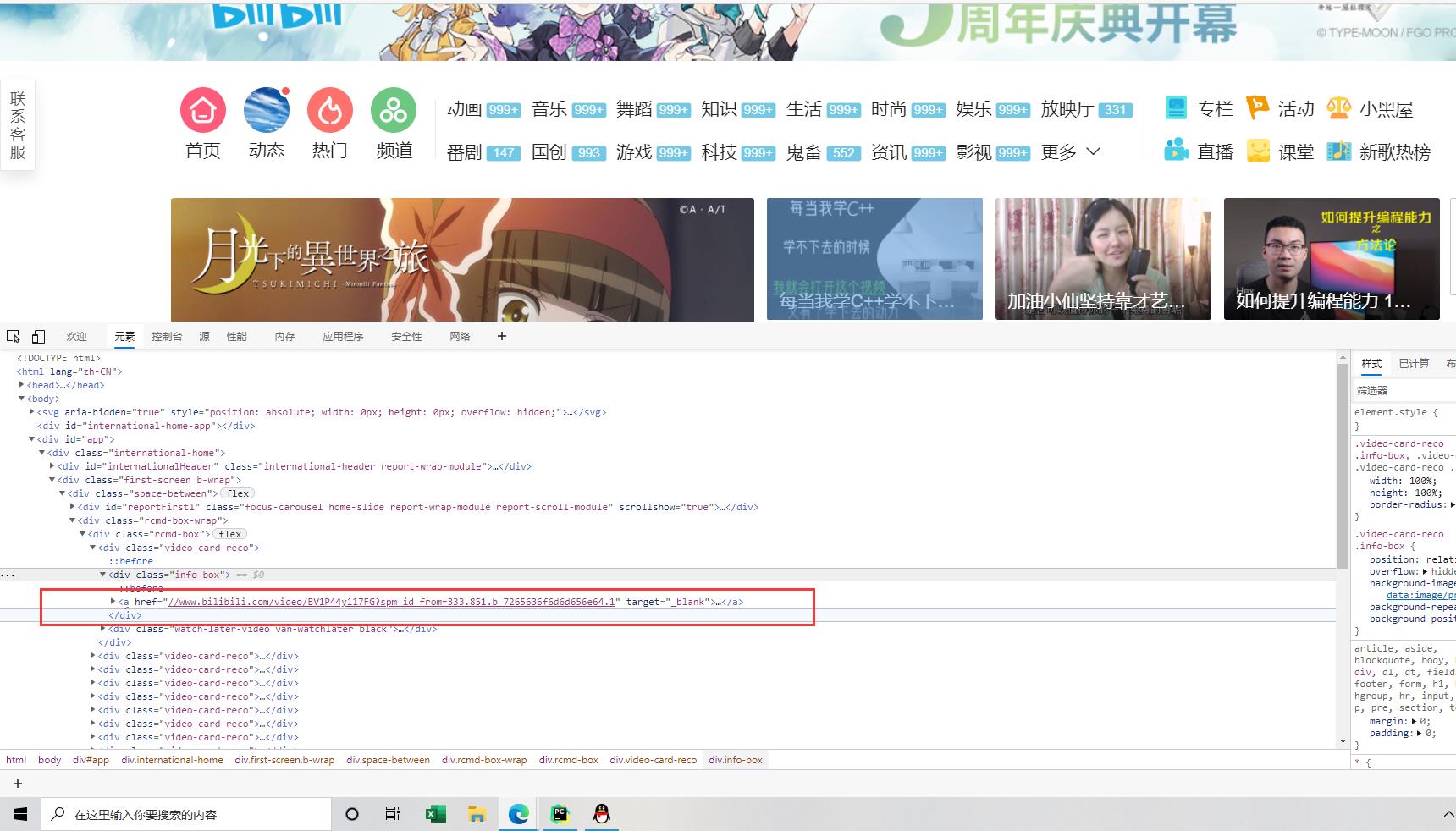
一.首先先找出推荐视频栏所在位置并找到各个视频的url
通过xpath解析定位
urls="https://www.bilibili.com/"
page_text= send_request(urls).text
tree = etree.html(page_text)
li_list= tree.xpath('//div[@class="rcmd-box"]/div')
for li in li_list:
detail_url= 'https:'+li.xpath('./div/a/@href')[0]
name = li.xpath('./div/a/div/p[1]/text()')[0]
二. 找到音频相关标签和url
找到类似的标签
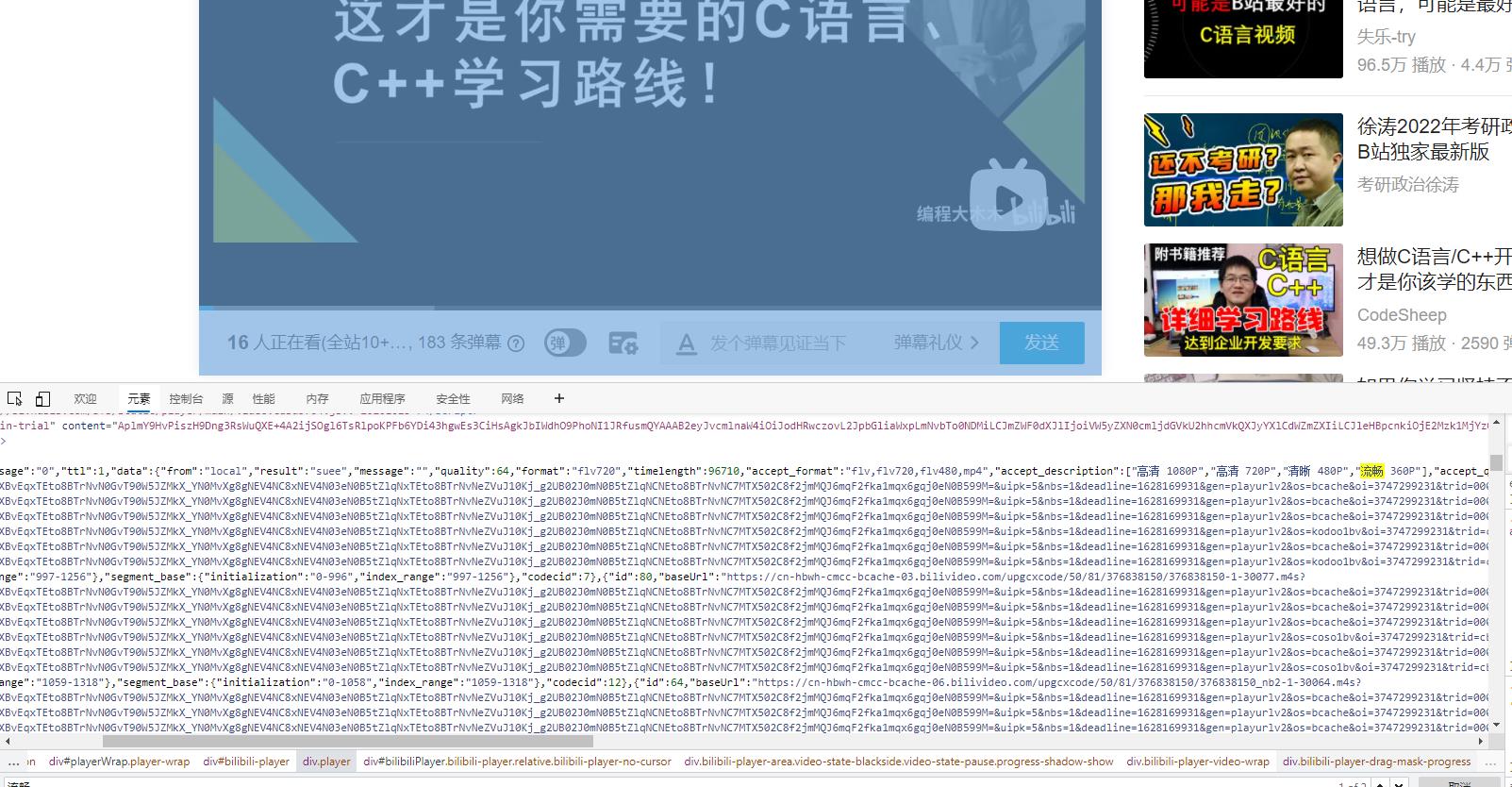
用正则解析写出音频对应的url
json_data = re.findall(r'<script>window.__playinfo__=(.*?)</script>', html_data)[0]
json_data = json.loads(json_data)
audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0]
video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0]
三. 进行UI伪装
网站又反爬虫机制,也就是UI检测,这里只有进行UI伪装进行反反爬虫操作才能爬取到音频内容
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"}
四. 音视频合并
由于音频和视频是分开下载的,所以要将他们合并到一起,这里需要用到ffmpeg插件。
os.rename(name + ".mp3","1.mp3")
os.rename(name + ".mp4","1.mp4")
subprocess.call("ffmpeg -i 1.mp4 -i 1.mp3 -c:v copy -c:a aac -strict experimental output.mp4", shell=True)
os.rename("output.mp4", name + ".mp4")
os.remove("1.mp3")
os.remove("1.mp4")
print("完成合并 " + name + "的视频!")
完整代码
import requests
import re
import json
import os
import subprocess
from multiprocessing.dummy import Pool
from lxml import html
etree = html.etree
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36","referer": "https://message.bilibili.com/"
}
def send_request(url):
response = requests.get(url=url, headers=headers)
response.encodings=''
return response
#对下述url发起请求解析出视频详情页的url和视频名称
urls="https://www.bilibili.com/"
page_text= send_request(urls).text
tree = etree.HTML(page_text)
li_list= tree.xpath('//div[@class="rcmd-box"]/div')
#储存所有的视频连接
for li in li_list:
detail_url= 'https:'+li.xpath('./div/a/@href')[0]
name = li.xpath('./div/a/div/p[1]/text()')[0]
#对详情页的url发起请求
print(detail_url+name)
# detail_page_text = requests.get(url=detail_url,headers=headers).text
html_data = send_request(detail_url).text
#从详情页中解析出视频的url
json_data = re.findall(r'<script>window.__playinfo__=(.*?)</script>', html_data)[0]
json_data = json.loads(json_data)
audio_url = json_data["data"]["dash"]["audio"][0]["backupUrl"][0]
video_url = json_data["data"]["dash"]["video"][0]["backupUrl"][0]
audio_data = send_request(audio_url).content
video_data = send_request(video_url).content
with open(name + ".mp3", "wb") as f:
f.write(audio_data)
with open(name + ".mp4", "wb") as f:
f.write(video_data)
print(name, '下载成功!')
os.rename(name + ".mp3","1.mp3")
os.rename(name + ".mp4","1.mp4")
subprocess.call("ffmpeg -i 1.mp4 -i 1.mp3 -c:v copy -c:a aac -strict experimental output.mp4", shell=True)
os.rename("output.mp4", name + ".mp4")
os.remove("1.mp3")
os.remove("1.mp4")
print("完成合并 " + name + "的视频!")
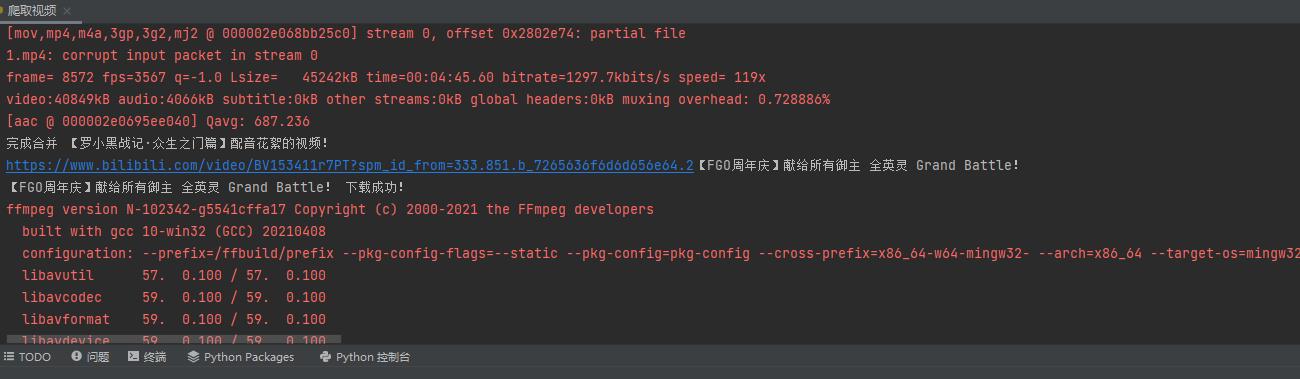
运行结果
红色部分不是报错,是音视频合并提示
后面还有视频,由于下载时间有点长,我终止了下载,只下了一个给大家看看样子。

以上是关于Python爬虫之爬取B站首页热门推荐视频的主要内容,如果未能解决你的问题,请参考以下文章