网络爬虫
Posted 流年醉影
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫相关的知识,希望对你有一定的参考价值。
网络爬虫
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件
爬虫的作用
• 做为通用搜索引擎网页收集器。(google,baidu)
• 做垂直搜索引擎.(找工作的搜索引擎: www.deepdo.com,数据来源于:www.51job.com , www.zhaoping.com , www.chinahr.com 等等)
• 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
• 偷窥,hacking,发垃圾邮件……(《google hack》….)
爬虫是搜索引擎的第一步也是最容易的一步
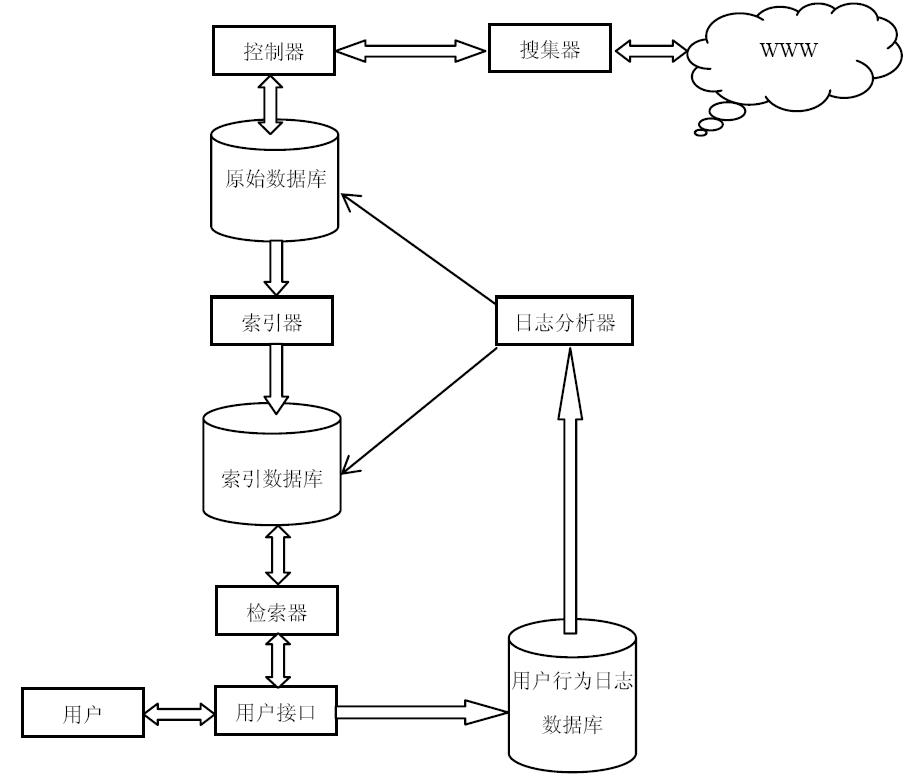
• 网页搜集 • 建立索引 • 查询排序
用什么语言写爬虫?
• C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
• 脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
• C#?(貌似信息管理的人比较喜欢的语言)
为什么最终选择Python?
• 跨平台,对Linux和windows都有不错的支持。
• 科学计算,数值拟合:Numpy,Scipy
• 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2
• 复杂网络:Networkx
• 统计:与R语言接口:Rpy
• 交互式终端
• 网站的快速开发?
以上是关于网络爬虫的主要内容,如果未能解决你的问题,请参考以下文章