Java网络爬虫怎么实现?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java网络爬虫怎么实现?相关的知识,希望对你有一定的参考价值。
参考技术A 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。\\x0d\\x0a 传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。对于垂直搜索来说,聚焦爬虫,即有针对性地爬取特定主题网页的爬虫,更为适合。\\x0d\\x0a\\x0d\\x0a 以下是一个使用java实现的简单爬虫核心代码: \\x0d\\x0apublic void crawl() throws Throwable \\x0d\\x0a while (continueCrawling()) \\x0d\\x0a CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL \\x0d\\x0a if (url != null) \\x0d\\x0a printCrawlInfo(); \\x0d\\x0a String content = getContent(url); //获取URL的文本信息 \\x0d\\x0a \\x0d\\x0a //聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理 \\x0d\\x0a if (isContentRelevant(content, this.regexpSearchPattern)) \\x0d\\x0a saveContent(url, content); //保存网页至本地 \\x0d\\x0a \\x0d\\x0a //获取网页内容中的链接,并放入待爬取队列中 \\x0d\\x0a Collection urlStrings = extractUrls(content, url); \\x0d\\x0a addUrlsToUrlQueue(url, urlStrings); \\x0d\\x0a else \\x0d\\x0a System.out.println(url + " is not relevant ignoring ..."); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a //延时防止被对方屏蔽 \\x0d\\x0a Thread.sleep(this.delayBetweenUrls); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a closeOutputStream(); \\x0d\\x0a\\x0d\\x0aprivate CrawlerUrl getNextUrl() throws Throwable \\x0d\\x0a CrawlerUrl nextUrl = null; \\x0d\\x0a while ((nextUrl == null) && (!urlQueue.isEmpty())) \\x0d\\x0a CrawlerUrl crawlerUrl = this.urlQueue.remove(); \\x0d\\x0a //doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取 \\x0d\\x0a //isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap \\x0d\\x0a //isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免 \\x0d\\x0a if (doWeHavePermissionToVisit(crawlerUrl) \\x0d\\x0a && (!isUrlAlreadyVisited(crawlerUrl)) \\x0d\\x0a && isDepthAcceptable(crawlerUrl)) \\x0d\\x0a nextUrl = crawlerUrl; \\x0d\\x0a // System.out.println("Next url to be visited is " + nextUrl); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a return nextUrl; \\x0d\\x0a\\x0d\\x0aprivate String getContent(CrawlerUrl url) throws Throwable \\x0d\\x0a //HttpClient4.1的调用与之前的方式不同 \\x0d\\x0a HttpClient client = new DefaultHttpClient(); \\x0d\\x0a HttpGet httpGet = new HttpGet(url.getUrlString()); \\x0d\\x0a StringBuffer strBuf = new StringBuffer(); \\x0d\\x0a HttpResponse response = client.execute(httpGet); \\x0d\\x0a if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) \\x0d\\x0a HttpEntity entity = response.getEntity(); \\x0d\\x0a if (entity != null) \\x0d\\x0a BufferedReader reader = new BufferedReader( \\x0d\\x0a new InputStreamReader(entity.getContent(), "UTF-8")); \\x0d\\x0a String line = null; \\x0d\\x0a if (entity.getContentLength() > 0) \\x0d\\x0a strBuf = new StringBuffer((int) entity.getContentLength()); \\x0d\\x0a while ((line = reader.readLine()) != null) \\x0d\\x0a strBuf.append(line); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a if (entity != null) \\x0d\\x0a nsumeContent(); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a //将url标记为已访问 \\x0d\\x0a markUrlAsVisited(url); \\x0d\\x0a return strBuf.toString(); \\x0d\\x0a\\x0d\\x0apublic static boolean isContentRelevant(String content, \\x0d\\x0aPattern regexpPattern) \\x0d\\x0a boolean retValue = false; \\x0d\\x0a if (content != null) \\x0d\\x0a //是否符合正则表达式的条件 \\x0d\\x0a Matcher m = regexpPattern.matcher(content.toLowerCase()); \\x0d\\x0a retValue = m.find(); \\x0d\\x0a \\x0d\\x0a return retValue; \\x0d\\x0a\\x0d\\x0apublic List extractUrls(String text, CrawlerUrl crawlerUrl) \\x0d\\x0a Map urlMap = new HashMap(); \\x0d\\x0a extractHttpUrls(urlMap, text); \\x0d\\x0a extractRelativeUrls(urlMap, text, crawlerUrl); \\x0d\\x0a return new ArrayList(urlMap.keySet()); \\x0d\\x0a \\x0d\\x0aprivate void extractHttpUrls(Map urlMap, String text) \\x0d\\x0a Matcher m = (text); \\x0d\\x0a while (m.find()) \\x0d\\x0a String url = m.group(); \\x0d\\x0a String[] terms = url.split("a href=\""); \\x0d\\x0a for (String term : terms) \\x0d\\x0a // System.out.println("Term = " + term); \\x0d\\x0a if (term.startsWith("http")) \\x0d\\x0a int index = term.indexOf("\""); \\x0d\\x0a if (index > 0) \\x0d\\x0a term = term.substring(0, index); \\x0d\\x0a \\x0d\\x0a urlMap.put(term, term); \\x0d\\x0a System.out.println("Hyperlink: " + term); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a \\x0d\\x0aprivate void extractRelativeUrls(Map urlMap, String text, \\x0d\\x0a CrawlerUrl crawlerUrl) \\x0d\\x0a Matcher m = relativeRegexp.matcher(text); \\x0d\\x0a URL textURL = crawlerUrl.getURL(); \\x0d\\x0a String host = textURL.getHost(); \\x0d\\x0a while (m.find()) \\x0d\\x0a String url = m.group(); \\x0d\\x0a String[] terms = url.split("a href=\""); \\x0d\\x0a for (String term : terms) \\x0d\\x0a if (term.startsWith("/")) \\x0d\\x0a int index = term.indexOf("\""); \\x0d\\x0a if (index > 0) \\x0d\\x0a term = term.substring(0, index); \\x0d\\x0a \\x0d\\x0a String s = //" + host + term; \\x0d\\x0a urlMap.put(s, s); \\x0d\\x0a System.out.println("Relative url: " + s); \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a \\x0d\\x0a\\x0d\\x0apublic static void main(String[] args) \\x0d\\x0a try \\x0d\\x0a String url = ""; \\x0d\\x0a Queue urlQueue = new LinkedList(); \\x0d\\x0a String regexp = "java"; \\x0d\\x0a urlQueue.add(new CrawlerUrl(url, 0)); \\x0d\\x0a NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L, \\x0d\\x0a regexp); \\x0d\\x0a // boolean allowCrawl = crawler.areWeAllowedToVisit(url); \\x0d\\x0a // System.out.println("Allowed to crawl: " + url + " " + \\x0d\\x0a // allowCrawl); \\x0d\\x0a crawler.crawl(); \\x0d\\x0a catch (Throwable t) \\x0d\\x0a System.out.println(t.toString()); \\x0d\\x0a t.printStackTrace(); \\x0d\\x0a \\x0d\\x0aJava实现网络爬虫
昨晚用自己写的网络爬虫程序从某网站了下载了三万多张图片,很是爽快,今天跟大家分享几点内容。
一、内容摘要
1:Java也可以实现网络爬虫
3:可以爬某网站的图片,动图以及压缩包
4:可以考虑用多线程加快下载速度
二、准备工作
1:安装Java JDK
3:安装Eclipse或其他编程环境
4:新建一个Java项目,导入Jsoup.jar
三、步骤
1:用Java.net包联上某个网址获得网页源代码
2:用Jsoup包解析和迭代源代码获得自己想要的最终图片网址
3:自己写一个下载的方法根据图片网址来下载图片至本地
四、程序实现及效果
例如针对下面的网页,我们可以所主区域中第一页到最后一页的所有高清图片都下载下来。
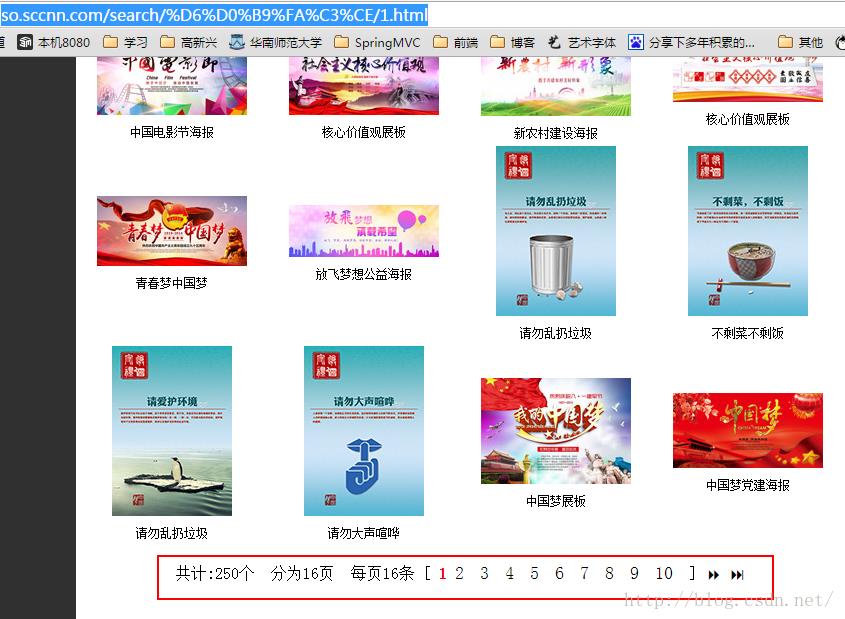
效果图:
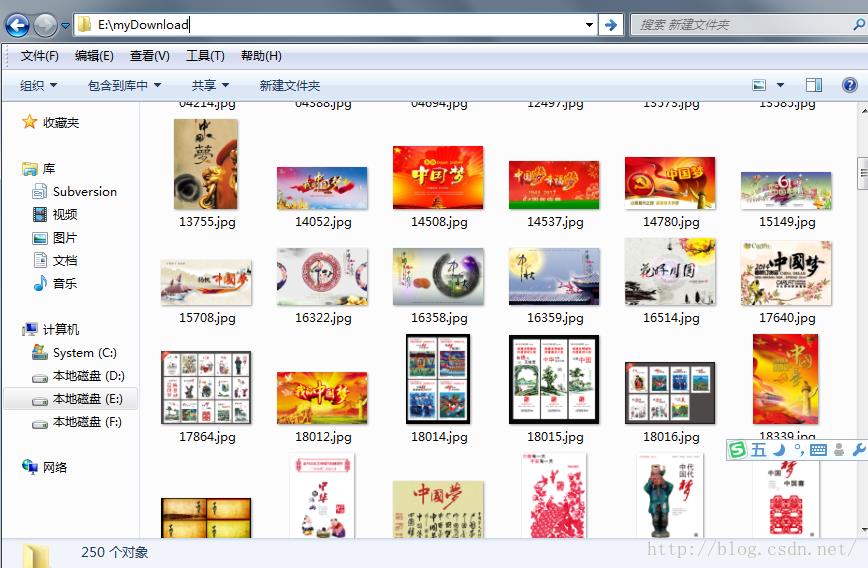
程序实现:
package com.kendy.spider;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class mySpider {
/**
* 联网,获取网页源代码,解析源代码
*/
public static String getHtmlFromUrl(String url,String encoding){
StringBuffer html = new StringBuffer();
InputStreamReader isr=null;
BufferedReader buf=null;
String str = null;
try {
URL urlObj = new URL(url);
URLConnection con = urlObj.openConnection();
isr = new InputStreamReader(con.getInputStream(),encoding);
buf = new BufferedReader(isr);
while((str=buf.readLine()) != null){
html.append(str+"\\n");
}
//sop(html.toString());
} catch (Exception e) {
e.printStackTrace();
}finally{
if(isr != null){
try {
buf.close();
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return html.toString();
}
public static void download(String url,String path){
File file= null;
FileOutputStream fos=null;
String downloadName= url.substring(url.lastIndexOf("/")+1);
HttpURLConnection httpCon = null;
URLConnection con = null;
URL urlObj=null;
InputStream in =null;
byte[] size = new byte[1024];
int num=0;
try {
file = new File(path+downloadName);
// if(!file.exists()){
// file.mkdir();
// }
fos = new FileOutputStream(file);
if(url.startsWith("http")){
//下面这两句话有问题
urlObj = new URL(url);
con = urlObj.openConnection();
httpCon =(HttpURLConnection) con;
in = httpCon.getInputStream();
while((num=in.read(size)) != -1){
for(int i=0;i<num;i++)
fos.write(size[i]);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally{
try {
in.close();
fos.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void sop(Object obj){
System.out.println(obj);
}
public static void seperate(char c){
for(int x=0;x<100;x++){
System.out.print(c);
}
sop("");
}
/**
* @author kendy
* @version 1.0
*/
public static void main(String[] args) throws Exception{
int i=0;
String picUrl=null;
List<String> list = new ArrayList<>();
for(int x=11;x<=16;x++){
String url = "http://so.sccnn.com/search/%D6%D0%B9%FA%C3%CE/" +x+".html";
String encoding = "utf-8";
String html = getHtmlFromUrl(url,encoding);
Document doc = Jsoup.parse(html);
Elements elements = doc.select("table tbody tr td table tbody tr td table tbody tr td div[valign] a[href]"); //带有href属性的a元素
//Elements pngs = doc.select("img[src$=.png]");//扩展名为.png的图片
for(Element element : elements){
picUrl = element.attr("href");
if(picUrl.startsWith("http") && picUrl.endsWith("html")){
i++;
list.add(picUrl);
sop("网址"+i+": "+picUrl);
Document document = Jsoup.connect(picUrl).get();
Elements els = document.select("div.PhotoDiv div font img");
for(Element el : els){
String pictureUrl = el.attr("src");
System.out.println("------"+pictureUrl);
download(pictureUrl,"E:\\\\myDownload\\\\");
}
}
}
seperate('*');
}
sop(list.size());
}
/* public static void main(String[] args) {
int i=0;
String picUrl=null;
String url = "http://so.sccnn.com/";
String encoding = "utf-8";
String html = getHtmlFromUrl(url,encoding);
Document doc = Jsoup.parse(html);
Elements elements = doc.getElementsByTag("img");
for(Element element : elements){
picUrl = element.attr("src");
if(picUrl.startsWith("http") && picUrl.endsWith("jpg")){
i++;
sop("图片"+i+" -------------"+picUrl);
download(picUrl,"E:\\\\myDownload\\\\");
}
}
sop("结束。。。");
}*/
}1:自定义的getHtmlFromUrl()方法和Jsoup.pars()方法其实可以用Jsoup.connect(url).get()方法代替
2:访问http和https请求不同,可以对自定义的getHtmlFromUrl和download方法进行优化
3:可以考虑用多线程加快下载速度,即本类去实现Runnable接口,并重写run方法,在构造函数里面把起始页和结束页作为参数初始化本类。
以上是关于Java网络爬虫怎么实现?的主要内容,如果未能解决你的问题,请参考以下文章