关系数据库集群
Posted 海角在眼前
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关系数据库集群相关的知识,希望对你有一定的参考价值。
背景
当站点的规模不断膨胀,这给数据库带来巨大的查询压力,单单数据库性能优化已经是不够的,需对数据库进行伸缩扩展。有三种方式:
1、数据库主从
2、数据表分库(垂直分区)
3、数据分区(水平分区)
PS:事实上,很多大规模的站点基本上经历了从简单主从复制到垂直分区,再到水平分区的步骤。
数据库主从
几乎所有主流关系数据库都支持数据复制功能,可将主服务器数据复制到从服务器,这个功能可以对数据库进行简单扩展。在主从基础上,采用读写分离的方法将应用程序中对数据库的写操作指向主服务器(保证数据一致性),而将读操作指向从服务器。
为何有用?
大多数站点的数据库读操作要比写操作更密集,而且查询条件相对复杂,数据库能力大部分消耗在查询上。通过将大量读操作剥离出来,转移到更多的从服务器上实现水平扩展,是非常简单有效的。
mysql为例
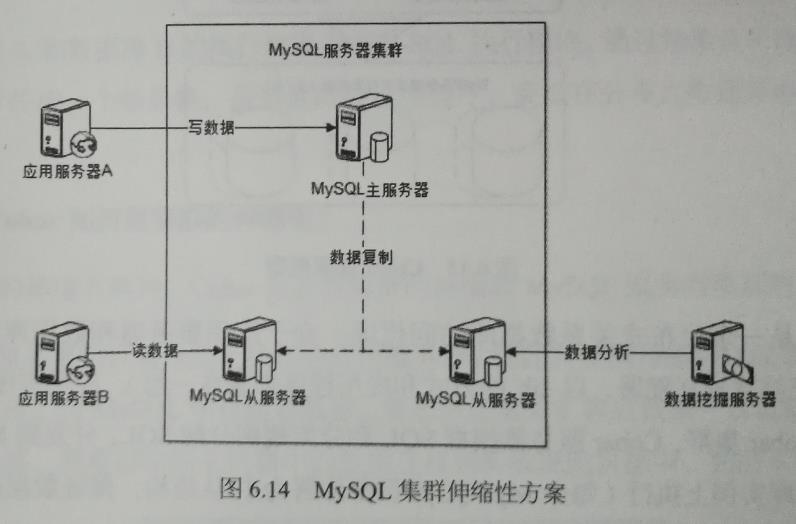
MySQL主从配置简单,只需做两点:
1、开启主服务器上的二进制日志(log-bin)。
2、在主服务器和从服务器上分别进行简单的配置和授权。
分发读操作方式:
应用程序本身不擅长分散读操作到多台从服务器上,可使用数据库反向代理来分发。MySQL可使用MySQL Proxy。
数据表分库(垂直分区)
对于某些写操作更加频繁的站点,主从方式的主服务器还是会成为瓶颈,从服务器的扩展并没带来好的效益。这时可以根据业务分割,将不同业务数据表部署在不同的数据库集群上,这就是数据表分库,也叫垂直分区。
制约
这种方式有个制约,跨库的表不能进行join操作,原本简单联合语句就能完成的,分库后需要一步步查询信息。但是,分库后的查询方式会更加容易保持相对稳定的开销。
例子,淘宝的用户和商品信息,将这两个数据表拆分成两个数据库。
数据分区(水平分区)
当数据表分库后,某一业务数据库(已经是很精细的业务)还是无法承受写操作压力时。这时可以考虑数据分区,将同一数据表中的数据通过特定算法进行分离,分别保存在不同数据表中,从而可以部署在不同的数据库服务器上。
PS:数据分区并不依赖特定的技术,更多是一种逻辑层面划分。
例子,Facebook的用户表,可以根据user_id的奇偶性将用户划分为两部分,分别存储到不同数据库服务器上。
参考文献
1、《构建高性能Web站点》
2、《大型网站技术架构》
以上是关于关系数据库集群的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:将关系数据库中的数据提取到 Elasticsearch 集群中