Elasticsearch:将关系数据库中的数据提取到 Elasticsearch 集群中
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:将关系数据库中的数据提取到 Elasticsearch 集群中相关的知识,希望对你有一定的参考价值。
本指南介绍了如何使用 Logstash JDBC 输入插件通过 Logstash 将关系数据库中的数据提取到 Elasticsearch 集群中。 它演示了如何使用 Logstash 高效地复制记录并从关系数据库接收更新,然后将它们发送到 Elasticsearch 中。
此处提供的代码和方法已经过 mysql 测试。 他们应该也适用于其他关系数据库。
Logstash Java 数据库连接 (JDBC) 输入插件使你能够从许多流行的关系数据库(包括 MySQL 和 Postgres)中提取数据。 从概念上讲,JDBC 输入插件运行一个循环,该循环定期轮询关系数据库以查找自该循环的最后一次迭代以来插入或修改的记录。
在今天的展示中,我将使用最新的 Elastic Stack 8.5.0 来进行演示。
将关系数据库中的数据提取到 Elasticsearch 集群中
安装
Elastic Stack
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参阅我之前的文章:
在安装时,请参考最新的 Elastic Stack 8.x 的指南来进行安装。在默认的情况下,Elasticsearch 的访问是需要 HTTPS 的。
MySQL
对于本教程,你需要一个供 Logstash 读取的源 MySQL 实例。 MySQL Community Downloads 站点的 MySQL Community Server 部分提供了免费版本的 MySQL。我们可以通过如下的命令来登录 MySQL:
在上面我们需要输入用户 root 的密码进行登录。
下载 MySQL JDBC 驱动
Logstash JDBC 输入插件不包含任何数据库连接驱动程序。你需要用于关系数据库的 JDBC 驱动程序才能执行后面即将描述的步骤。从 MySQL 社区下载站点的 Connector/J 部分下载并解压缩 MySQL 的 JDBC 驱动程序。根据后续步骤的需要记下驱动程序的位置。

准备源 MySQL 数据库
我们来看一个简单的数据库,你将从中导入数据并将其发送到 Elasticsearch 集群中。 此示例使用带有时间戳记录的 MySQL 数据库。 时间戳使你能够轻松确定自最近一次数据传输到 Elasticsearch 以来数据库中发生了什么变化。
考虑数据库结构和设计
对于这个例子,让我们创建一个新的数据库 es_db 和表 es_table,作为我们的 Elasticsearch 数据的来源。
1)运行以下 SQL 语句以生成具有三个列表的新 MySQL 数据库:
CREATE DATABASE es_database;
USE es_database;
DROP TABLE IF EXISTS es_table;
CREATE TABLE es_table (
id BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY unique_id (id),
client_name VARCHAR(32) NOT NULL,
modification_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
让我们探讨一下这个 SQL 片段中的关键概念:
| 条目 | 描述 |
|---|---|
| es_table | 存储数据的表的名称。 |
| id | 记录的唯一标识符。 id 被定义为 PRIMARY KEY 和 UNIQUE KEY 来保证每个 id 在当前表中只出现一次。 这被转换为 _id 用于更新文档或将文档插入 Elasticsearch。 |
| client_name | 最终将被引入 Elasticsearch 的数据。 为简单起见,此示例仅包含一个数据字段。 |
| modification_time | 插入或最后更新记录的时间戳。 此外,你可以使用此时间戳来确定自上次数据传输到 Elasticsearch 以来发生了什么变化。 |
2)考虑如何处理删除以及如何将它们通知 Elasticsearch。 通常,删除一条记录会导致它立即从 MySQL 数据库中删除。 没有删除的记录。 Logstash 未检测到更改,因此该记录保留在 Elasticsearch 中。
有两种可能的方法来解决这个问题:
- 你可以在源数据库中使用 “软删除(soft deletes)”。 本质上,记录首先通过布尔标志标记为删除。 当前正在使用你的源数据库的其他程序必须在其查询中过滤掉 “软删除”。 “软删除” 被发送到 Elasticsearch,在那里可以处理它们。 之后,你的源数据库和 Elasticsearch 都必须删除这些 “软删除”。
- 你可以定期清除基于数据库的 Elasticsearch 索引,然后使用新摄取的数据库内容刷新 Elasticsearch。
3)登录到你的 MySQL 服务器并将三个记录添加到你的新数据库:
use es_database
INSERT INTO es_table (id, client_name)
VALUES (1,"Targaryen"),
(2,"Lannister"),
(3,"Stark");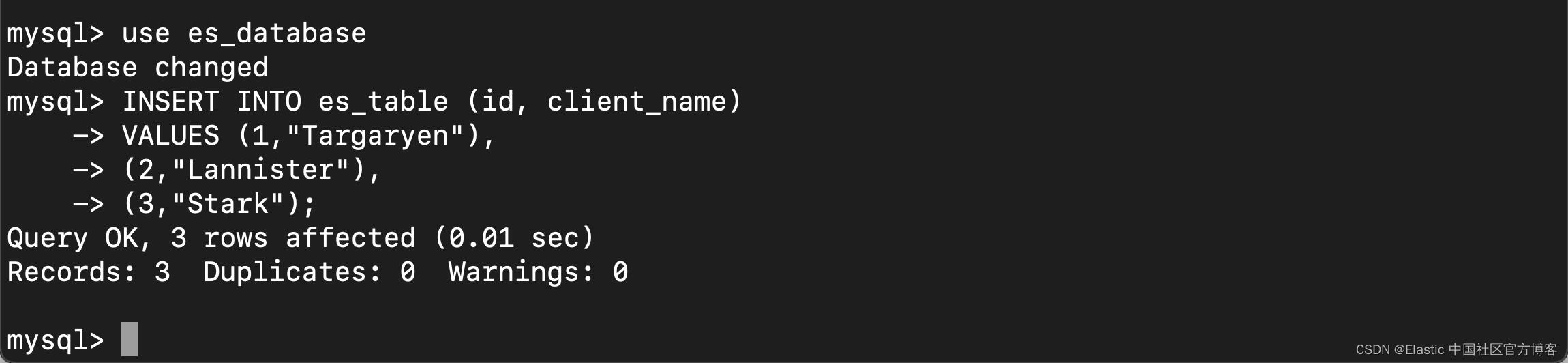
4) 使用 SQL 语句验证你的数据:
select * from es_table;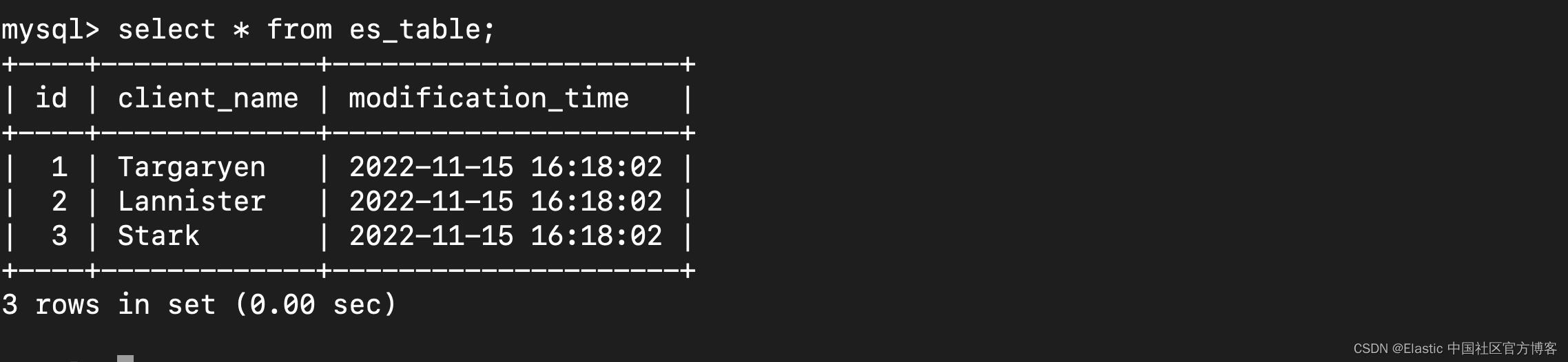
现在,让我们回到 Logstash 并将其配置为接收此数据。
使用 JDBC 输入插件配置 Logstash 管道
让我们设置一个示例 Logstash 输入管道,以从新的 JDBC 插件和 MySQL 数据库中获取数据。 除了 MySQL,你还可以从任何支持 JDBC 的数据库输入数据。
1)在 <localpath>/logstash-8.5.0/ 中,创建一个名为 jdbc.conf 的新文本文件。
2)将以下代码复制并粘贴到这个新的文本文件中。 此代码通过 JDBC 插件创建一个 Logstash 管道。
input
jdbc
jdbc_driver_library => "<driverpath>/mysql-connector-java-<versionNumber>.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => "<myusername>"
jdbc_password => "<mypassword>"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
filter
mutate
copy => "id" => "[@metadata][_id]"
remove_field => ["id", "@version", "unix_ts_in_secs"]
output
stdout codec => "rubydebug"
说明:
- 指定本地 JDBC 驱动程序 .jar 文件的完整路径(包括版本号)。 例如:jdbc_driver_library => "/usr/share/mysql/mysql-connector-java-8.0.24.jar"
- 提供 MySQL 主机的 IP 地址或主机名和端口。 例如,jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/es_database"
- 提供您的 MySQL 凭据。 用户名和密码都必须用引号引起来。
注意:如果你使用的是 MariaDB(MySQL 的一个流行的开源社区分支),你需要做一些不同的事情:
- 代替 MySQL JDBC 驱动程序,下载并解压缩 MariaDB 的 JDBC 驱动程序。
- 替换 jdbc.conf 代码中的以下行,包括最后一行中的 ANSI_QUOTES 片段:
jdbc_driver_library => "<driverPath>/mariadb-java-client-<versionNumber>.jar" jdbc_driver_class => "org.mariadb.jdbc.Driver" jdbc_connection_string => "jdbc:mariadb://<mySQLHost>:3306/es_db?sessionVariables=sql_mode=ANSI_QUOTES"
以下是有关 Logstash 管道代码的一些其他详细信息:
| 条目 | 描述 |
|---|---|
| jdbc_driver_library | Logstash JDBC 插件未与 JDBC 驱动程序库一起打包。 必须使用 jdbc_driver_library 配置选项将 JDBC 驱动程序库显式传递到插件中。 |
| tracking_column | 此参数指定字段 unix_ts_in_secs,该字段跟踪 Logstash 从 MySQL 读取的最后一个文档,存储在磁盘上的 logstash_jdbc_last_run 中。 该参数确定 Logstash 在其轮询循环的下一次迭代中请求的文档的起始值。 存储在 logstash_jdbc_last_run 中的值可以在 SELECT 语句中作为 sql_last_value 访问。 |
| unix_ts_in_secs | 由 SELECT 语句生成的字段,其中包含 modification_time 作为标准 Unix 时间戳(自 epoch 以来的秒数)。 该字段由跟踪列引用。 Unix 时间戳用于跟踪进度而不是普通时间戳,因为普通时间戳可能会由于在 UMT 和本地时区之间正确来回转换的复杂性而导致错误。 |
| sql_last_value | 这是一个包含 Logstash 轮询循环当前迭代起点的内置参数,它在 JDBC 输入配置的 SELECT 语句行中被引用。 此参数设置为从 .logstash_jdbc_last_run 中读取的 unix_ts_in_secs 的最新值。 该值是在 Logstash 轮询循环中执行的 MySQL 查询返回的文档的起点。 在查询中包含此变量可确保我们不会重新发送已存储在 Elasticsearch 中的数据。 |
| schedule | 这使用 cron 语法来指定 Logstash 应多久轮询一次 MySQL 以获取更改。 规范 */5 * * * * * 告诉 Logstash 每 5 秒联系 MySQL。 来自此插件的输入可以安排为根据特定时间表定期运行。 此调度语法由 rufus-scheduler 提供支持。 语法类似于 cron,带有一些特定于 Rufus 的扩展(例如,时区支持)。 |
| modification_time < NOW() | SELECT 的这一部分将在下一节中详细解释。 |
| filter | 在本节中,值 id 从 MySQL 记录复制到名为 _id 的元数据字段中,稍后在输出中引用该字段以确保每个文档都使用正确的 _id 值写入 Elasticsearch。 使用元数据字段可确保此临时值不会导致创建新字段。 id、@version 和 unix_ts_in_secs 字段也从文档中删除,因为它们不需要写入 Elasticsearch。 |
| output | 本节指定应使用 rubydebug 输出将每个文档写入标准输出以帮助调试。 |
请参照我之前的文章 “Logstash:把 MySQL 数据导入到 Elasticsearch 中”。我们需要把下载的 JDBC 驱动拷贝到如下的目录中:
$ pwd
/Users/liuxg/elastic/logstash-8.5.0
$ ls logstash-core/lib/jars/mysql-connector-j-8.0.31.jar
logstash-core/lib/jars/mysql-connector-j-8.0.31.jar根据我的情况,我的 jdbc.conf 的代码如下:
jdbc.conf
input
jdbc
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/es_database"
jdbc_user => "root"
jdbc_password => "1234"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
filter
mutate
copy => "id" => "[@metadata][_id]"
remove_field => ["id", "@version", "unix_ts_in_secs"]
output
stdout codec => "rubydebug"
3)使用新的 JDBC 配置文件启动 Logstash:
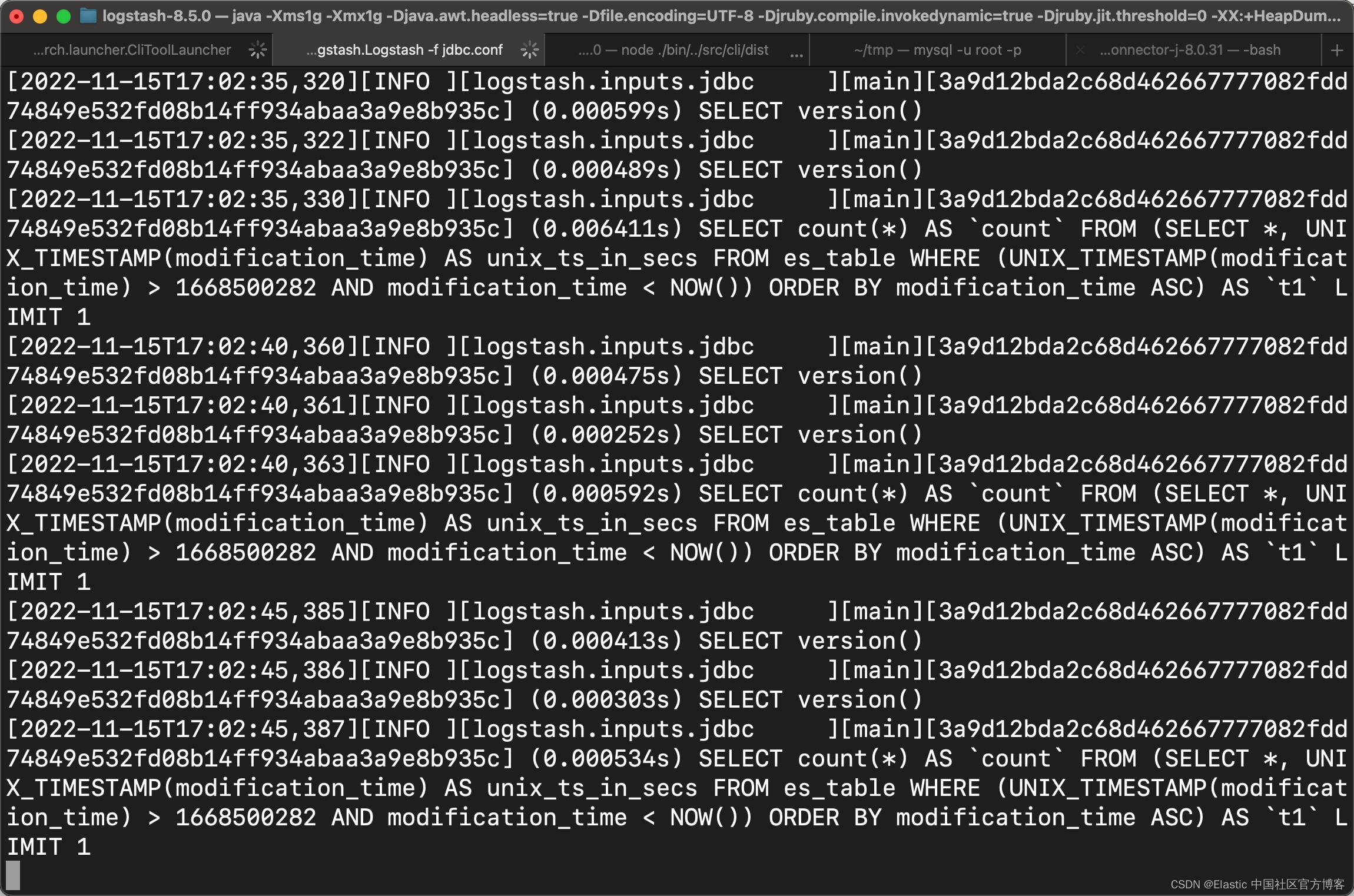
bin/logstash -f jdbc.confLogstash 通过标准输出 (stdout),你的命令行界面输出您的 MySQL 数据。 初始数据加载的结果应类似于以下内容:
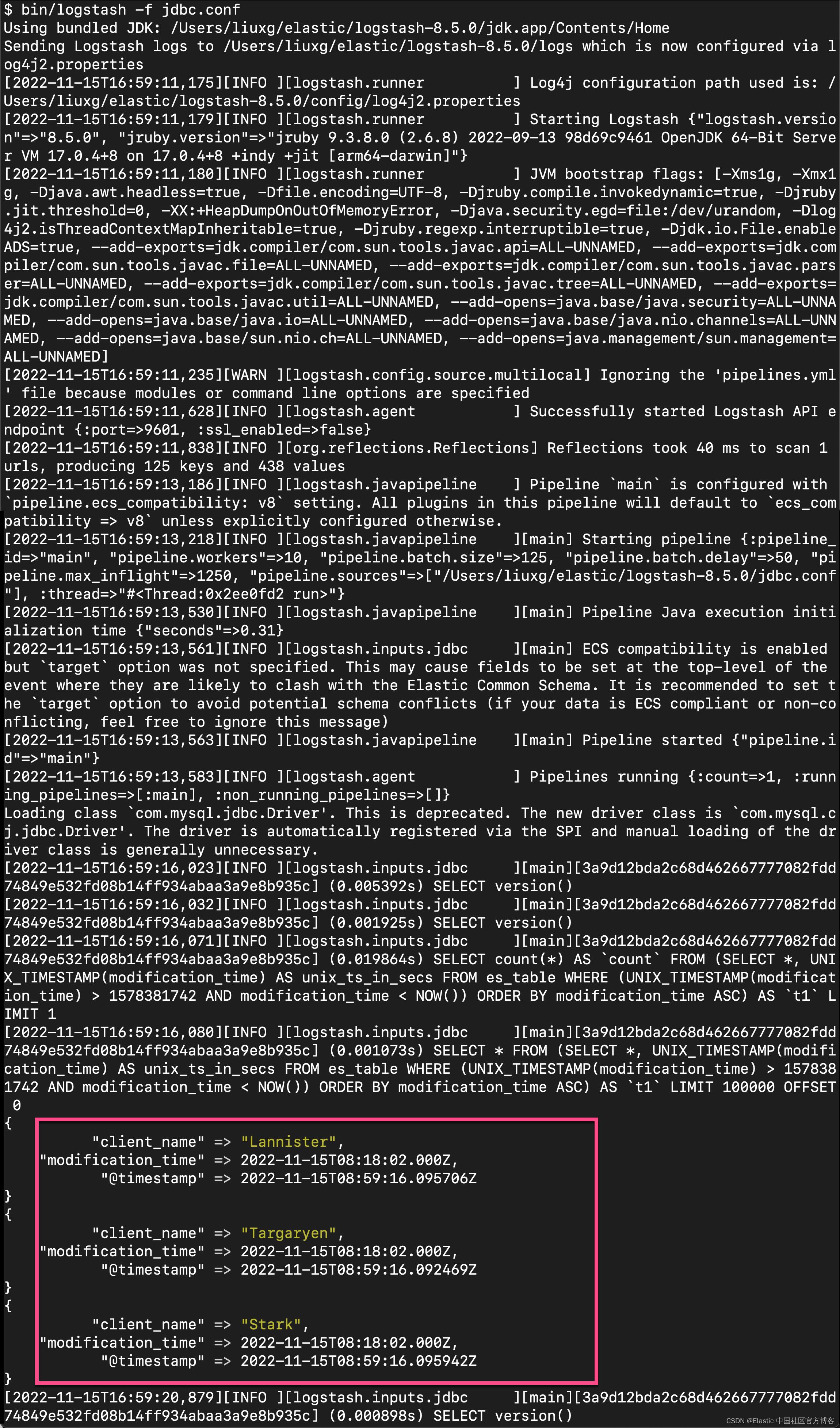
Logstash 结果会定期显示 SQL SELECT 语句,即使在 MySQL 数据库中没有任何新内容或修改内容时也是如此:
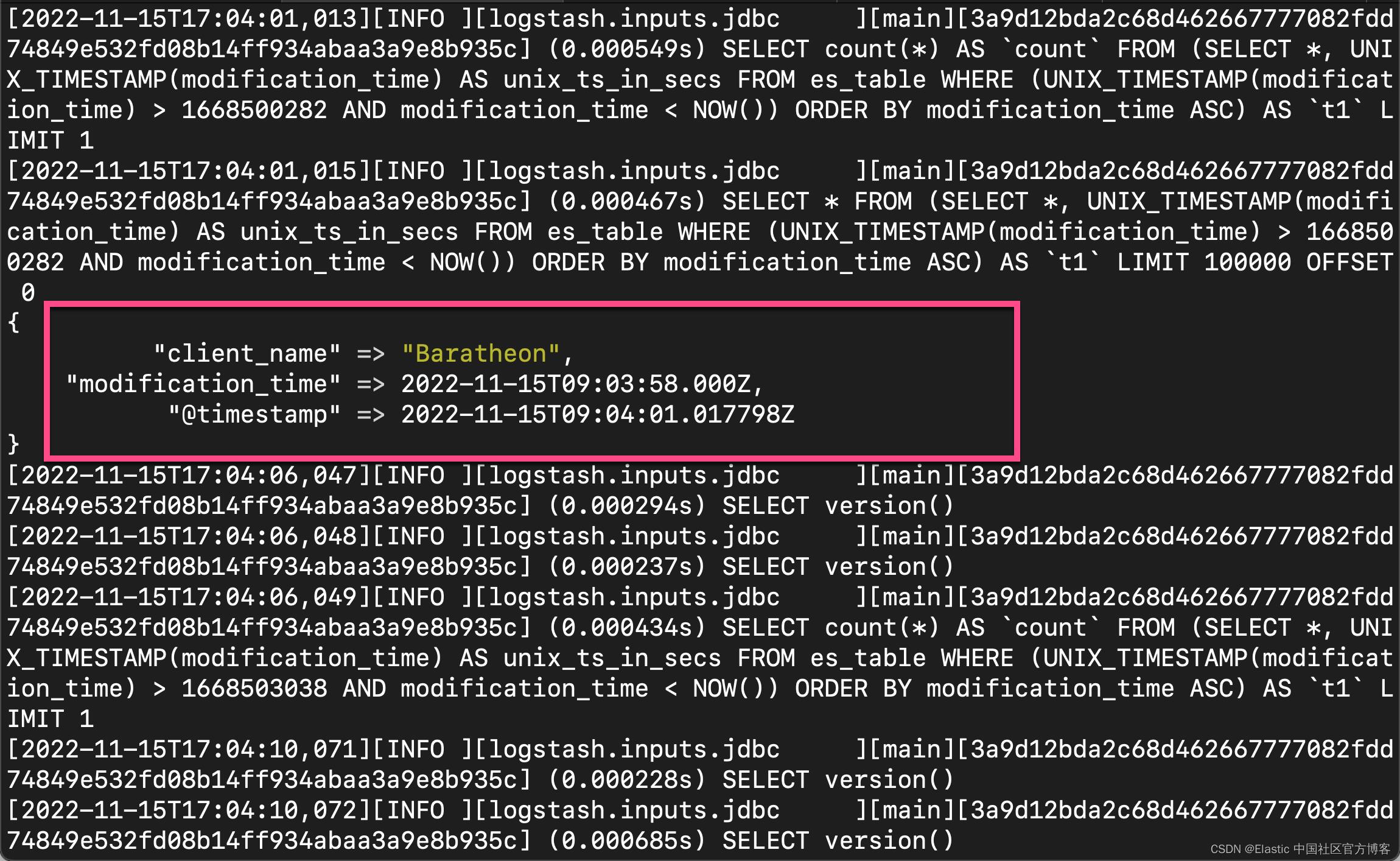
4)打开你的 MySQL 控制台。 让我们使用以下 SQL 语句将另一条记录插入该数据库:
use es_database
INSERT INTO es_table (id, client_name)
VALUES (4,"Baratheon");
切换回你的 Logstash 控制台。 Logstash 检测到新记录,控制台显示类似如下结果:
5)查看 Logstash 输出结果以确保你的数据看起来正确。 使用 CTRL+C 关闭 Logstash。
输出到 Elasticsearch
在本节中,我们配置 Logstash 以将 MySQL 数据发送到 Elasticsearch。 我们修改在使用 JDBC 输入插件配置 Logstash 管道部分中创建的配置文件,以便数据直接输出到 Elasticsearch。 我们启动 Logstash 发送数据,然后登录 Kibana 来验证数据。
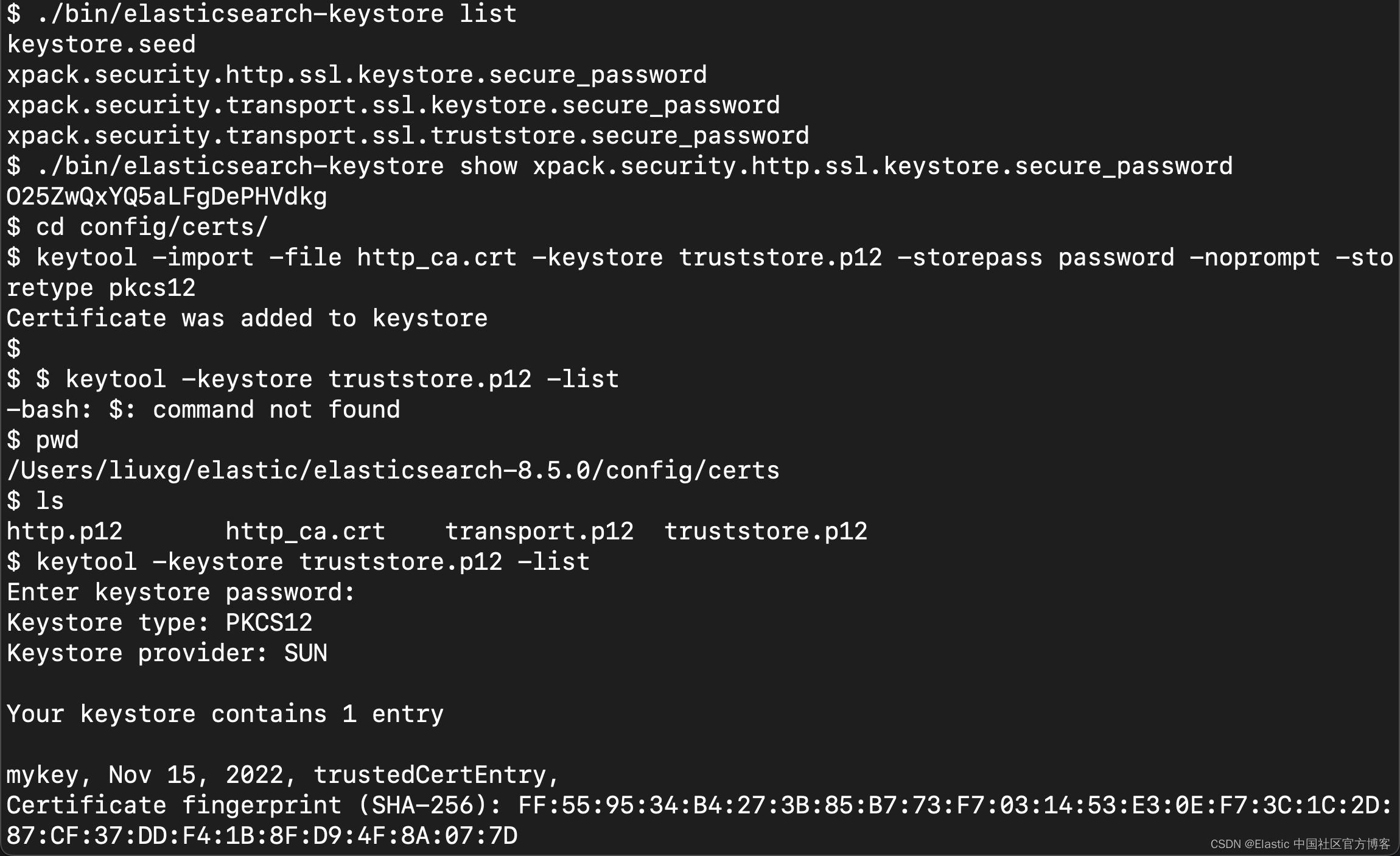
关于如何配置带有 HTTPS 连接的 Elasticsearch,请阅读我的文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。我们首先按照那篇文章中步骤生成一个 truststore.p12 证书:
1)打开 Logstash 文件夹下的 jdbc.conf 文件进行编辑。
2)用以下内容更新输出部分:
jdbc.conf
input
jdbc
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/es_database"
jdbc_user => "root"
jdbc_password => "1234"
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
filter
mutate
copy => "id" => "[@metadata][_id]"
remove_field => ["id", "@version", "unix_ts_in_secs"]
output
stdout codec => "rubydebug"
elasticsearch
hosts => ["https://localhost:9200"]
index => "data-%+YYYY.MM.dd"
user => "elastic"
password => "Hx_-Z6cnuT-T_LIqGJoV"
ssl_certificate_verification => true
truststore => "/Users/liuxg/elastic/elasticsearch-8.5.0/config/certs/truststore.p12"
truststore_password => "password"
当然你也可以选择使用 API key 来进行连接。详细步骤请参考文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。
3)现在,如果您只是像使用新输出一样重新启动 Logstash,则不会有 MySQL 数据发送到我们的 Elasticsearch 索引。
这是为什么呢?Logstash 保留了以前的 sql_last_value 时间戳,并看到从那时起 MySQL 数据库中没有发生新的更改。 因此,根据我们配置的 SQL 查询,没有新数据要发送到 Logstash。
解决方案:在 jdbc.conf 文件的 JDBC 输入部分添加 clean_run => true 作为新行。 当设置为 true 时,此参数会将 sql_last_value 重置回零。
input
jdbc
...
clean_run => true
...
在将 clean_run 设置为 true 运行一次 Logstash 后,你可以删除 clean_run 行,除非您希望在每次重新启动 Logstash 时再次发生重置行为。
4)打开命令行界面实例,转到您的 Logstash 安装路径,然后启动 Logstash:
bin/logstash -f jdbc.conf运行上面的命令后,Logstash 就会把数据传入到 Elasticsearch 中。

在 Kibana 中检查数据
我们在 Kibana 的 console 中打入如下的命令:
GET data-*/_search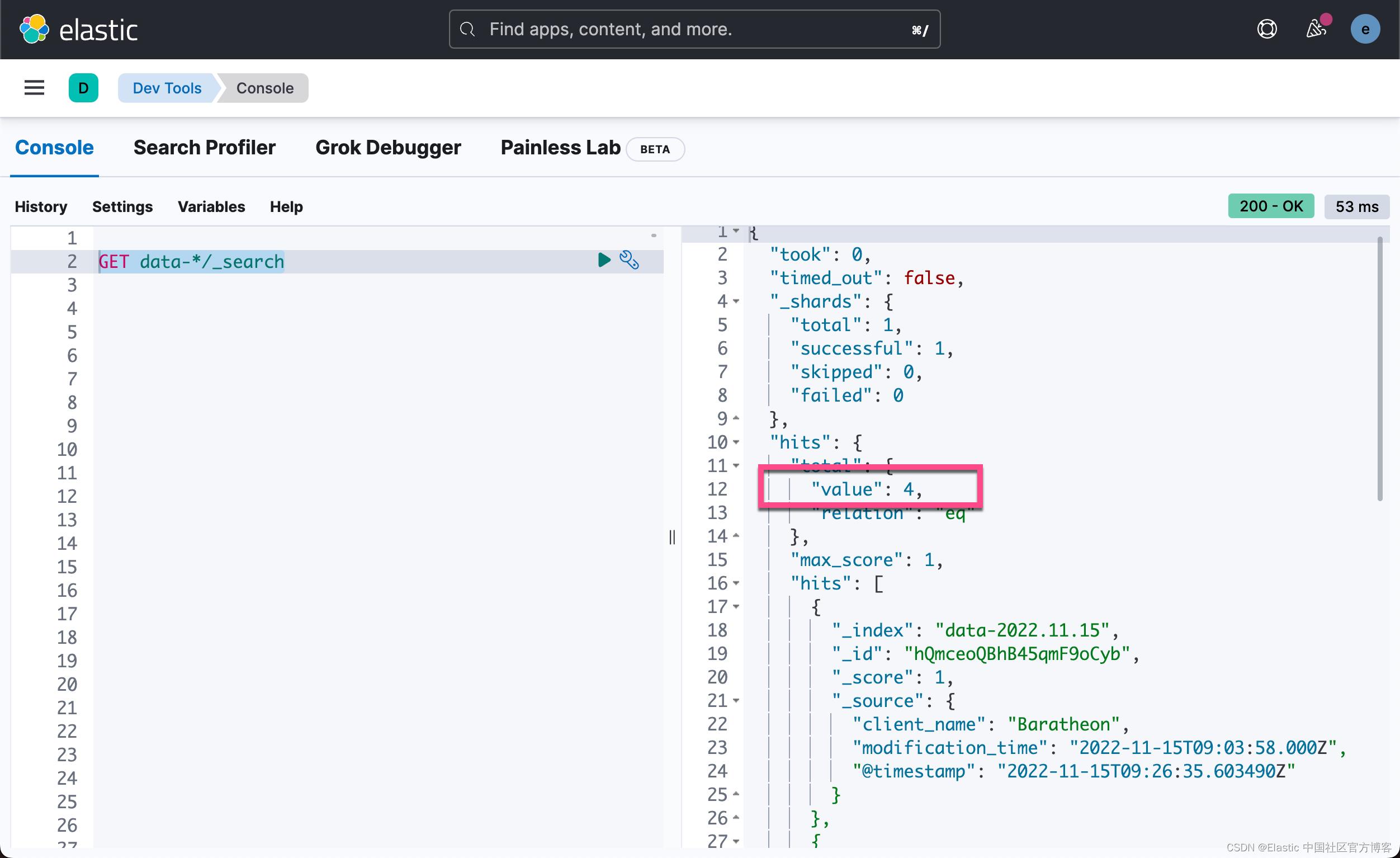
我们看到有四个数据已经被写入到 Elasticsearch 中了。
现在,你应该很好地了解如何配置 Logstash 以通过 JDBC 插件从关系数据库中获取数据。 你有一些设计注意事项来跟踪新的、修改的和删除的记录。 你应该具备开始试验自己的数据库和 Elasticsearch 所需的基础知识。
以上是关于Elasticsearch:将关系数据库中的数据提取到 Elasticsearch 集群中的主要内容,如果未能解决你的问题,请参考以下文章
NoSQL、ElasticSearch 甚至是老式的关系数据库?
Elasticsearch 缓存深度剖析:一次提高一种缓存的查询速度
将数据从PostgreSQL同步到Elasticsearch的经验总结
ElasticsearchElasticsearch 缓存深度剖析:一次提高一种缓存的查询速度