本笔记主要记录学习《机器学习》的总结体会。如有理解不到位的地方,欢迎大家指出,我会努力改正。
在学习《机器学习》时,我主要是通过Andrew Ng教授在mooc上提供的《Machine Learning》课程,不得不说Andrew Ng老师在讲授这门课程时,真的很用心,特别是编程练习,这门课真的很nice,在此谢谢Andrew Ng老师的付出。同时也谢过告知这个平台的小伙伴。本文在写的过程中,多有借鉴Andrew Ng教授在mooc提供的资料,再次感谢。
转载请注明出处:http://blog.csdn.net/u010278305
什么是机器学习?我认为机器学习就是,给定一定的信息(如一间房子的面子,一幅图片每个点的像素值等等),通过对这些信息进行“学习”,得出一个“学习模型“,这个模型可以在有该类型的信息输入时,输出我们感兴趣的结果。好比我们如果要进行手写数字的识别,已经给定了一些已知信息(一些图片和这些图片上的手写数字是多少),我们可以按以下步骤进行学习:
1、将这些图片每个点的像素值与每个图片的手写数字值输入”学习系统“。
2、通过”学习过程“,我们得到一个”学习模型“,这个模型可以在有新的手写数字的图片输入时,给出这张图片对应手写数字的合理估计。
什么是线性回归?我的理解就是,用一个线性函数对提供的已知数据进行拟合,最终得到一个线性函数,使这个函数满足我们的要求(如具有最小平方差,随后我们将定义一个代价函数,使这个目标量化),之后我们可以利用这个函数,对给定的输入进行预测(例如,给定房屋面积,我们预测这个房屋的价格)。如下图所示:
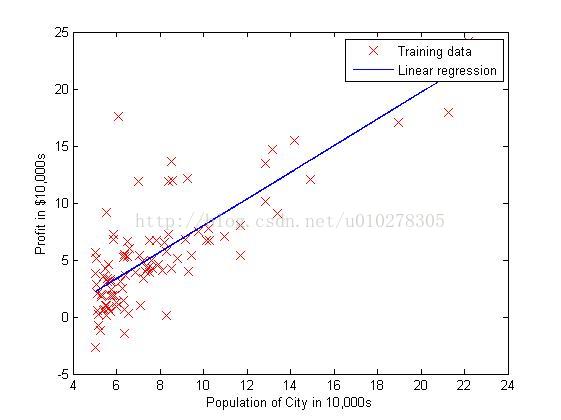
假设我们最终要的得到的假设函数具有如下形式:
![]()
其中,x是我们的输入,theta是我们要求得的参数。
代价函数如下:
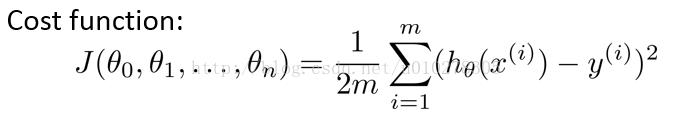
我们的目标是使得此代价函数具有最小值。
为此,我们还需要求得代价函数关于参量theta的导数,即梯度,具有如下形式:
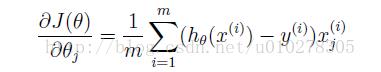
有了这些信息之后,我们就可以用梯度下降算法来求得theta参数。过程如下:
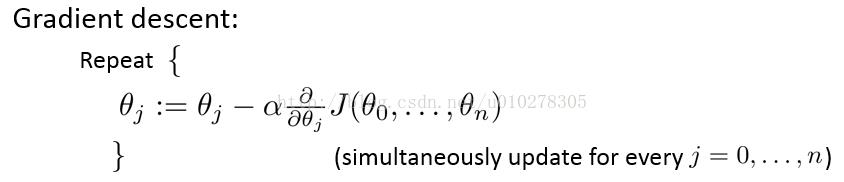
其实,为了求得theta参数,有更多更好的算法可以选择,我们可以通过调用matlab的fminunc函数实现,而我们只需求出代价与梯度,供该函数调用即可。
根据以上公式,我们给出代价函数的具体实现:
function J = computeCostMulti(X, y, theta) %COMPUTECOSTMULTI Compute cost for linear regression with multiple variables % J = COMPUTECOSTMULTI(X, y, theta) computes the cost of using theta as the % parameter for linear regression to fit the data points in X and y % Initialize some useful values m = length(y); % number of training examples % You need to return the following variables correctly J = 0; % Instructions: Compute the cost of a particular choice of theta % You should set J to the cost. hThetaX=X*theta; J=1/(2*m)*sum((hThetaX-y).^2); end
什么是逻辑回归?相比于线性回归,逻辑回归只会输出一些离散的特定值(例如判定一封邮件是否为垃圾邮件,输出只有0和1),而且对假设函数进行了处理,使得输出只在0和1之间。
假设函数如下:
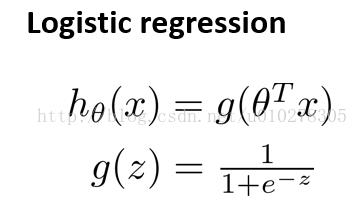
代价函数如下:
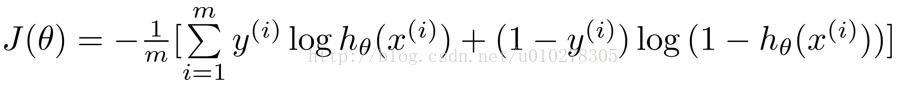
梯度函数如下,观察可知,形式与线性回归时一样:
有了这些信息,我们就可以通过fminunc求出最优的theta参数,我们只需给出代价与梯度的计算方式,代码如下:
function [J, grad] = costFunction(theta, X, y) %COSTFUNCTION Compute cost and gradient for logistic regression % J = COSTFUNCTION(theta, X, y) computes the cost of using theta as the % parameter for logistic regression and the gradient of the cost % w.r.t. to the parameters. % Initialize some useful values m = length(y); % number of training examples % You need to return the following variables correctly J = 0; grad = zeros(size(theta)); % Instructions: Compute the cost of a particular choice of theta. % You should set J to the cost. % Compute the partial derivatives and set grad to the partial % derivatives of the cost w.r.t. each parameter in theta % % Note: grad should have the same dimensions as theta % hThetaX=sigmoid(X * theta); J=1/m*sum(-y.*log(hThetaX)-(1-y).*log(1-hThetaX)); grad=(1/m*(hThetaX-y)\'*X)\'; end
其中,sigmod函数如下:
function g = sigmoid(z) %SIGMOID Compute sigmoid functoon % J = SIGMOID(z) computes the sigmoid of z. % You need to return the following variables correctly g = zeros(size(z)); % Instructions: Compute the sigmoid of each value of z (z can be a matrix, % vector or scalar). e=exp(1); g=1./(1+e.^-z); end
有时,会出现”过拟合“的情况,即求得的参数能够很好的拟合训练集中的数据,但在进行预测时,明显与趋势不符,好比下图所示:
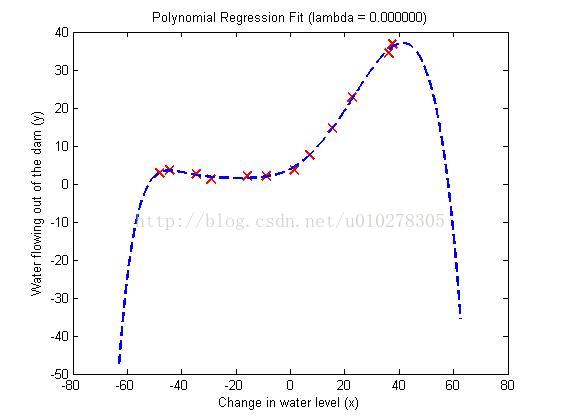
此时,我们需要进行正则化处理,对参数进行惩罚,使得除theta(1)之外的theta值均保持较小值。
进行正则化之后的代价函数如下:
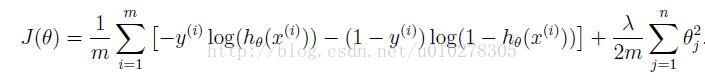
进行正则化之后的梯度如下:
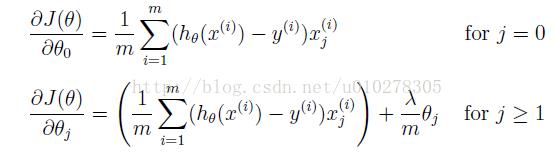
下面给出正则化之后的代价与梯度值得代码:
function [J, grad] = costFunctionReg(theta, X, y, lambda) %COSTFUNCTIONREG Compute cost and gradient for logistic regression with regularization % J = COSTFUNCTIONREG(theta, X, y, lambda) computes the cost of using % theta as the parameter for regularized logistic regression and the % gradient of the cost w.r.t. to the parameters. % Initialize some useful values m = length(y); % number of training examples % You need to return the following variables correctly J = 0; grad = zeros(size(theta)); % Instructions: Compute the cost of a particular choice of theta. % You should set J to the cost. % Compute the partial derivatives and set grad to the partial % derivatives of the cost w.r.t. each parameter in theta hThetaX=sigmoid(X * theta); theta(1)=0; J=1/m*sum(-y.*log(hThetaX)-(1-y).*log(1-hThetaX))+lambda/(2*m)*sum(theta.^2); grad=(1/m*(hThetaX-y)\'*X)\' + lambda/m*theta; end
对于线性回归,正则化的过程基本类似。
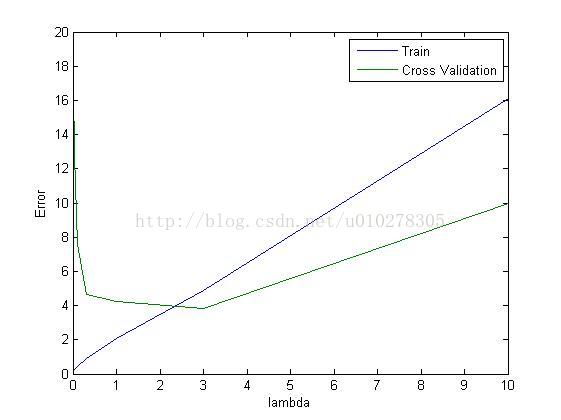
至于如何选择正则化时的常数lambda,我们可以将数据分为训练集、交叉验证集和测试集三部分,在不同lambda下,先用训练集求出参数theta,之后求出训练集与交叉验证集的代价,通过分析得出适合的lambda。如下图所示:
转载请注明出处:http://blog.csdn.net/u010278305